EMD-LSTM模型对金融时间序列的预测
2021-03-09姚洪刚沐年国
姚洪刚,沐年国
上海理工大学 管理学院,上海200093
金融市场的预测一直是受到广泛关注的问题,无论是决策者还是投资者,都期望能够把握金融市场的动向寻求利益最大化。然而,金融时间序列由于市场行为机制的复杂性而具有高噪声以及非平稳非线性的特点,这些都为金融时间序列的预测增加了难度。
传统的时间序列分析模型受限于固定的模型框架以及较为严格的假设条件,往往不能对复杂的金融时间序列数据做出准确的预测。而基于深度学习的时间序列分析方法更注重对于数据本身的驱动,通过使用激活函数能够处理非线性的问题,因此可以更好地应对“非理想化”的时间序列数据,得到更为准确的预测结果。近年来,一些机器学习方法诸如支持向量机[1-2]以及人工神经网络[3-4]被应用于分析时间序列,并取得了不错的效果。随着深度学习的发展,一类专门用来处理序列的循环神经网络及其变种LSTM模型被提出[5],LSTM在多个领域中取得巨大成功[6-8],并开始成为从深度学习角度处理金融时间序列的主要方法[9-10]。
基于深度学习衍生出多种预测金融时间序列的改进方案,从金融序列高噪声这一角度而产生的一类做法是通过对序列去噪[11-12]或平滑处理[13]以降低金融时间序列的噪声或波动性,从而提升深度学习方法的预测性能。但是这类做法均是一次性将所有序列进行平滑或小波去噪,然后再将其划分训练集和测试集输入模型,这就造成了训练过程中使用到测试集的信息,因此使用滑动窗口的多步处理代替一次处理更符合实际情况。
虽然小波变换在去噪方面使用十分普遍,但小波函数以及分解层数的选择却是一个问题,尤其是在按滑动窗口分解时,不同时间段可能需要不同的设定。Huang等[14]提出经验模态分解方法,通过一定规则对序列进行分解,相较于小波分解,EMD具有自适应性,能够避免小波分解的设定问题。目前关于LSTM结合EMD的应用多是通过EMD分解得到的不同频率分布的多个序列分别输入LSTM,再利用集成的思想建立模型[15-16]。这里同样是一次分解处理的原因,由于训练过程中使用到测试集的信息,无法有效说明模型的效果。
针对以上问题,提出基于EMD滑动窗口去噪结合LSTM网络的金融时间序列预测模型。通过对原始序列按一定大小的时间窗口进行EMD分解,使用阈值法对分解后的高频序列去噪,再对所有序列重构输入LSTM,从而提升模型的预测性能。
1 方法与模型
1.1 EMD方法
经验模态分解(EMD)作为一种处理非平稳非线性序列十分有效的方法,克服了小波分解的基函数需要设定的问题,具有自适应性。本质上,EMD是一个平稳化过程,通过一种固定模式将序列分离出不同尺度的平稳波动项以及一个残差趋势项,其中每一个波动项被称之为本征模态函数(IMF)。IMF分量的确定需要满足两个条件:
(1)该分量的极值点和过零点的数目必须相等或最多相差一个。
(2)对于每一个时间点,由该分量局部极大值点通过三次样条插值形成的上包络线和局部极小值点形成的下包络线的平均值为零,即两条包络线关于时间轴局部对称。
EMD的具体分解方法[14,17]如下:
(1)确定待分解序列X(t)所有局部极大值和极小值点,使用三次样条插值连接所有局部极大值点形成上包络线u0(t),同样将所有局部极小值点形成下包络线l0(t)。

(3)判断h1(t)是否满足IMF的条件,如果满足,则h1(t)为第一个IMF,否则对h1(t)依照X(t)做同样的处理。对得到新的分量h2(t)=h1(t)-m1(t),做同样的判断和处理,直到hk(t)满足IMF条件或者达到停止标准,停止标准如下:
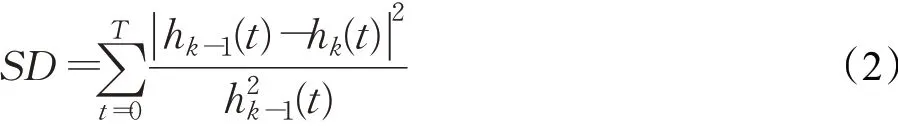
当SD小于某一特定值即达到停止标准,其中特定值一般在之间选取。至此得到第一个IMF分量imf1。
(4)将剩余分量r1=X(t)-imf1作为新的待分解序列并重复以上步骤,直到分量imfn或剩余分量rn小于预定值或者剩余分量rn变成单调函数时结束。此时:

至此,对于原始序列X(t)的分解完成。IMF分量imfk随着k的增加而频率降低,即先分解出的IMF分量是原始序列的高频部分,也是含噪较高的部分;剩余分量rn即为反映原始序列趋势的趋势项。
1.2 EMD去噪
EMD的去噪思路是对IMF中含噪较高的高频分量进行去噪处理。确定高频分量和低频分量需要计算IMF能量[17]:

其中,imfkt表示IMF分量imfk在t时刻的值,T为序列长度。高频IMF分量能量较低,低频IMF分量能量较高,IMF能量在高频分量和低频分量之间存在一个突变过程,确定突变点即可确定高频分量的范围。突变点可由以下方式估计[18]:

即遍历每一IMF能量作为突变点K,其中使R(K)达到最大的点即为突变点K0。
确定突变点K0后,对imf1∼imfK0分别进行去噪处理,得到去噪后的分量imf′1∼imf′K0。将去噪后的高频分量与低频分量以及趋势项重构,得到原始序列X(t)去噪后的序列X′(t):
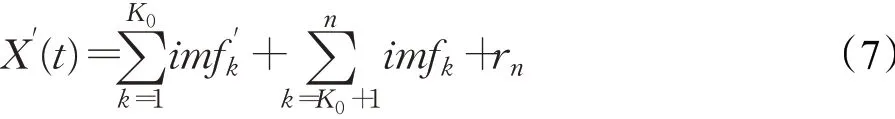
本文采用阈值法[17-18]去噪,公式如下:

1.3 LSTM原理与结构
循环神经网络(RNN)的网络层接受当前时刻的输入xt以及上一个时刻的网络状态ht-1,得到当前时刻的网络状态ht并作为下一时刻的输入。循环神经网络关注历史因素的影响使其适合处理时间序列问题,其工作原理如下:

式(9)表示状态更新过程,式(10)表示预测输出过程。其中xt为t时刻的输入特征,ht为t时刻的状态向量,ot为t时刻的输出。循环神经网络更新状态向量常常使用:

激活函数σ多为tanh函数。
由于标准RNN的结构过于简单,常常无法长期保存有效信息,即短时记忆问题。为了有效延长这种短时记忆,提出了LSTM网络[5]。相较于标准的RNN,LSTM在保留了状态向量ht的基础上,增加了一个记忆状态向量ct,同时引入门控机制,通过门控(遗忘门、输入门、输出门)来控制序列信息的遗忘与更新。
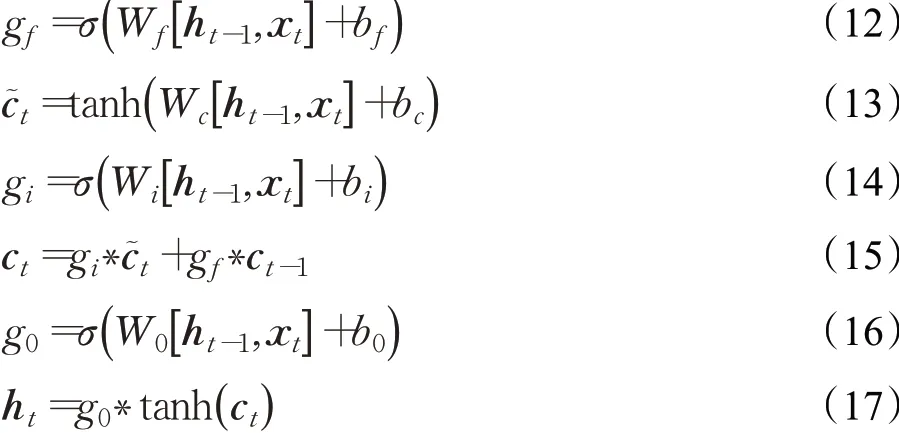
LSTM网络结构如图1所示,状态的更新规则如式(12)~(17)所示。式(12)表示遗忘门过程,用于控制t-1时刻的记忆状态向量ct-1进入t时刻LSTM单元的量gf∗ct-1。因此激活函数σ一般使用Sigmoid函数,保证gf的取值范围在0~1之间,当gf=1时,LSTM单元接受ct-1的所有信息;当gf=0时,LSTM单元完全忽略ct-1的所有信息。式(13)、(14)表示输入门过程,式(13)用于控制t-1时刻的状态ht-1和t时刻的输入xt通过非线性变换得到新的输入向量式(14)用于控制进入t时刻LSTM单元的量同样使用Sigmoid激活函数,当gi=1时,LSTM单元完全接受新输入c˜t,当gi=0时,LSTM不接受新输入c˜t。式(15)表示t时刻LSTM单元记忆状态向量ct的更新方式。式(16)、(17)表示输出门过程,这里对ct通过tanh激活函数进行转换,门控g0用于控制记忆状态向量ct生成输出向量ht的量由于所以输出向量
1.4 EMD-LSTM模型
基于以上讨论,提出一种利用EMD滑动窗口去噪结合LSTM网络的金融时间序列预测模型:EMD-LSTM模型,如图2。
考虑到对整体序列一次性直接去噪,利用了大量的未来数据,这在实际情况下是无法实现的,选择使用固定大小的滑动窗口对序列按单位时间步提取去噪。设定时间窗口大小为n,窗口移动的步长为1,提取的第一组序列为对该序列使用自适应的EMD去噪方法,得到第一组去噪序列移动一个时间步,继续提取第二组序列,去噪得到继续移动时间步并做去噪处理,直到整个序列取完为止。
假设利用过去m个时间步的值预测当前值,其中m≤n。使用去噪后的序列作为LSTM的输入,则输入为每组去噪序列的最后m个去噪数据构成的序列:

2 实证分析
2.1 数据说明与预处理
实证数据取自上证指数,上证指数反映了上海证券交易所上市的所有股票价格的变动情况,其变动趋势在一定程度上能够反映中国宏观经济的走势。实证的预测目标是上证指数的收盘价,收盘价作为交易所每一个交易日的最后一笔交易价格,既是当日行情的标准,又是下一个交易日的开盘价的依据,具有重要的意义。实证选择的输入特征为上证指数的收盘价、最高价、最低价、开盘价、涨跌幅、成交量以及成交金额。对于一些短期技术指标,因其均由收盘价的线性或非线性变换而得到,而LSTM模型本身就具有不错的特征提取能力,所以不予考虑,只以交易数据的7个指标作为输入。以2010年到2017年共8年的日度交易数据作为训练集训练模型,以2018年到2019年共2年的日度交易数据作为测试集评估模型。
为了克服特征序列之间不同量纲的影响,提升模型精度,并提高迭代求解的收敛速度,在训练模型之前选择以训练集的序列数据的最大值和最小值对所有的特征序列以及目标序列做归一化处理:
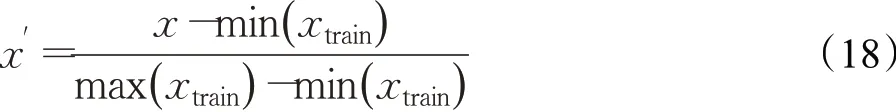
其中,x为所有原始数据,xtrain为训练集数据,x′为所有归一化后的数据。
将归一化后的数据输入模型,模型变成对归一化后的收盘价的预测,因此需再将最终输出的结果进行反归一化处理即得到最终的预测结果。
2.2 衡量指标
为了对比EMD-LSTM模型与标准LSTM的预测效果,从三个角度选取衡量指标。平均绝对百分误差(MAPE)用于衡量模型预测结果与真实值之间的相对偏差;可决系数(R2)用于衡量模型的拟合优度;同时考虑金融时间序列在方向上的预测具有重要意义,使用方向正确率(DA)衡量模型在序列方向上的预测效果。三个衡量指标计算公式如下:
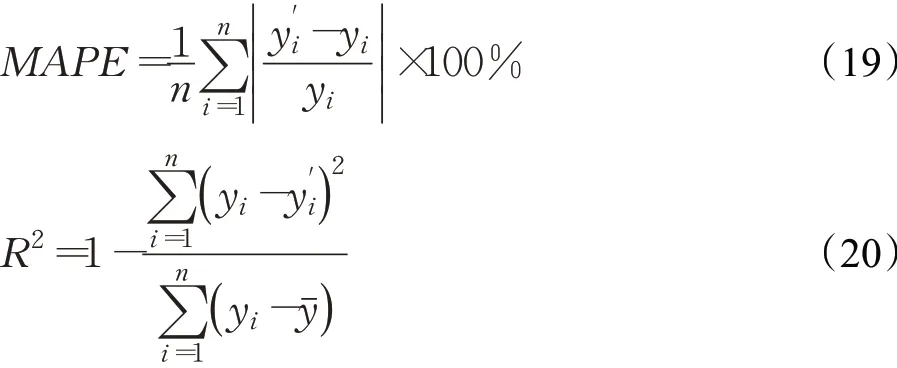
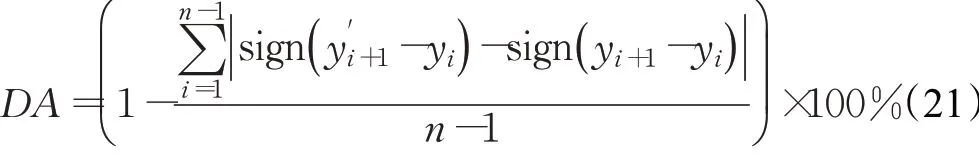
其中,n为测试集序列长度,yi为收盘价的真实值,y′i为收盘价的预测值,yˉ为测试集收盘价均值。
2.3 实证结果
设定LSTM输入序列时间步为10,即以过去10个交易日数据预测下一个交易日收盘价。设定去噪窗口大小∈[15,30,60,120,240],通过网格搜索,去噪窗口大小为120个时间步时,模型效果最好。选择两种方式对序列滑动窗口去噪:一种是前文介绍的EMD阈值去噪,另一种是直接将EMD得到的趋势项简单作为去噪结果。将两种处理方式得到的结果分别输入LSTM模型,比较两种去噪处理方式的差异。
对于LSTM网络结构的设定如下:由于特征维度为7,两层LSTM相对于一层LSTM,预测性能并没有提升,反而增加了模型复杂度,因此只使用一层LSTM。隐藏层神经元个数为4,在LSTM输出层后加入一层线性网络得到最终输出。批处理大小为128(每训练128组样本迭代更新一次参数);训练次数为200次(将所有训练集样本完整训练200次);以归一化后的收盘价的预测值和真实值的均方误差MSE作为损失函数,并加入L2正则化;使用Adam优化算法更新参数。
对于标准LSTM和文献[15-16]所使用的EMDLSTM模型以及本文提出的两种不同去噪处理的EMDLSTM模型在测试集的预测效果如表1。

表1 模型效果比较
表1 给出了四种模型的衡量指标,其中EMDLSTM_1代表文献[15-16]所使用的EMD-LSTM模型,其针对一次分解的每一个本征模态函数分别做预测,再将所有结果相加得到最终预测;EMD-LSTM_2代表直接使用EMD得到的趋势项作为去噪结果的EMDLSTM模型;EMD-LSTM_3代表使用EMD阈值去噪法的EMD-LSTM模型。结果显示,两种去噪处理的EMDLSTM模型相对于标准LSTM模型,预测效果均有提升,特别是使用阈值去噪的EMD-LSTM模型无论是预测精度还是预测方向上均是性能最优的。直接使用趋势项的EMD-LSTM虽然相较于其他两个模型预测效果稍好,但不如阈值去噪的EMD-LSTM,可能是因为趋势项虽然包含了序列的大部分信息且噪声极少,但却缺失了存在于本征模态函数分量中的一些有用信息。而文献[15-16]所使用的EMD-LSTM模型在方向上的预测较好,但在预测精度上表现不理想,在其训练过程中,发现LSTM在噪声较高的前几个本征模态函数上的表现不佳,显然高噪声的因素影响了LSTM的预测效果。
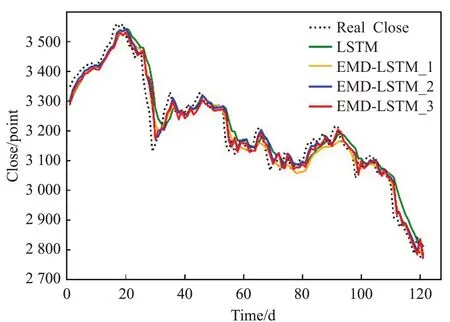
图3 2018年上半年预测结果
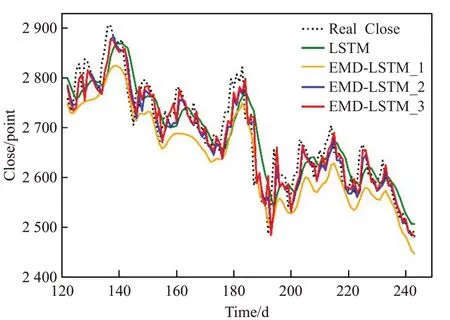
图4 2018年下半年预测结果
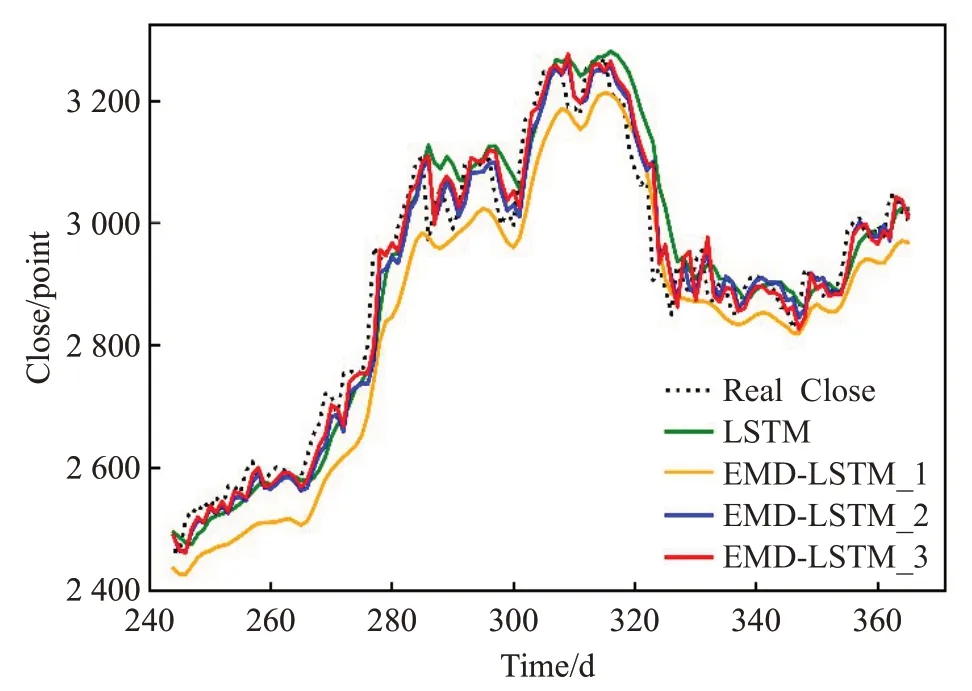
图5 2019年上半年预测结果
为了更直观地表现四种模型的预测差异,将测试集共两年的收盘价预测结果分为图3~6展示,每张图为半年的预测结果。其中黑色虚线代表真实收盘价,绿色实线代表标准LSTM模型的收盘价预测,橙色实线代表文献[15-16]所使用的EMD-LSTM收盘价预测,蓝色实线代表直接使用趋势项作为去噪结果的EMD-LSTM收盘价预测,红色实线代表使用阈值法去噪的EMD-LSTM收盘价预测。由图可知,四种模型的预测结果与收盘价的真实趋势基本相同,却没有哪一个模型能够解决时间序列预测普遍存在的滞后性问题。通过对比四种模型的预测结果与真实值处于相同趋势的位置,可以发现,阈值去噪的EMD-LSTM模型在同一个趋势的极大多数情况下距离真实值最近,直接使用趋势项作为去噪结果的EMD-LSTM次之。可以认为EMD-LSTM模型相比于标准的LSTM减轻了一定的滞后性,保留更多有用信息的阈值去噪EMD-LSTM表现最好。
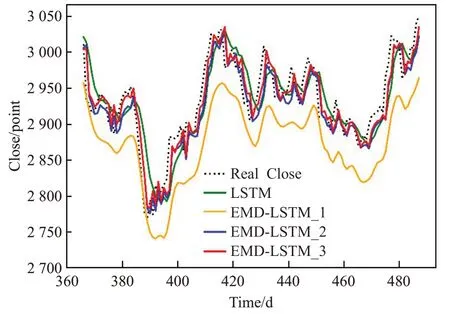
图6 2019年下半年预测结果
3 结束语
本文利用EMD去噪方法设计了滑动窗口去噪结合LSTM网络的金融时间序列的预测模型:EMD-LSTM。实证结果表明滑动窗口EMD去噪的引入,提升了LSTM的预测性能,无论是预测精度还是预测方向上均有一定的提升。EMD-LSTM通过滑动窗口以及EMD的自适应性,克服了一次性分解和去噪的不合理性以及小波基的选择问题,具有一定的优势。虽然仍然没有解决时间序列预测的滞后性问题,但对预测结果的分析可以看出,EMD-LSTM相对于标准LSTM缓解了一定的滞后性问题,尤其是使用保留更多有效信息的阈值去噪,效果最好。因此如果可以找到基于EMD更好的去噪方法,也许EMD-LSTM的预测性能以及滞后性都将得到更好的解决。
