基于Faster R-CNN的缝隙检测与提取算法
2021-03-08肖创柏柏鳗晏
肖创柏,柏鳗晏,禹 晶
(北京工业大学信息学部,北京 100124)
缝隙影响着建筑安全以及工业产品质量,因此,缝隙检测在维护建筑安全以及保证工业产品质量中起着关键性的作用. 在建筑的质量检测以及日常维护中,需要检测是否有威胁建筑安全的裂缝存在,因此,工程队会进行定期的安全排查并完成修复;在焊接工件的过程中,是否准确检测到预留焊缝将决定工件是否符合相关工艺的预留焊接标准以及焊接后产品的使用寿命. 因此,在建筑业和工业等领域对缝隙检测尤为重视.
目测检测法是缝隙表面尺寸测量中常用的方法,其优点在于操作简单并且灵活性强,但是目测检测过程中工作人员易受到工作量大、工作环境差等客观因素以及认知差异等主观因素的影响,导致检测结果准确率不高且该方法实时性差、效率低、劳动强度大,难以保证检测结果的规范性、客观性和科学性.
目标检测旨在对图像中的目标进行分类和定位. 传统的目标检测方法首先使用不同尺寸的滑动窗口在图像中遍历生成候选区域,然后利用特征提取算法对各个候选区域进行特征提取,最后通过特定的分类器实现分类决策. 但是,传统方法采用手工设计特征,检测的鲁棒性不高且采用滑动窗口策略生成的候选区域存在大量冗余,会影响后处理的效率以及准确率,因此,研究自动、准确、快速的缝隙目标检测方法已经成为当今研究的趋势. 可形变组件模型(deformoble part model)是一种经典的目标检测算法,通过描述每一部分和部分间的位置关系来表示物体,普遍应用于行人目标检测以及车辆目标检测. 文献[1]提出了一种基于混合多尺度可变部件模型的目标检测算法,在方向梯度直方图(histogram of oriented gradient,HoG)特征和支撑向量机(support vector machine,SVM)分类器的基础上构建了多尺度形变组件模型,将物体表示为多个组成部件,用部件间的关系来描述物体.
随着深度学习的快速发展,深度学习广泛应用于目标检测领域. 多层卷积神经网络(convolutional neural network,CNN)能够自适应地对输入的数据进行特征学习并对学习的特征进行分类或识别,基于CNN的目标检测主要分为三大类,即基于回归的网络模型,如YOLO[2]、SSD[3];基于候选区域生成的网络模型,如R-CNN[4]、Fast R-CNN[5]、Faster R-CNN[6];基于搜索的网络模型,如Attention-Net[7]. 由于深度学习模拟了人类的视觉感知系统,规避了手工设计特征的弱点且具有非线性和高度并行的优点,因此,具有广泛的应用.
深度学习也逐渐地应用于缝隙目标检测的研究中. Zhang等[8]提出了基于CNN对路面裂缝进行分类的方法,该方法证明CNN学习的特征优于手工设计特征,并且分类准确率更高. Cha等[9]指出由于输入图像在通过CNN训练后尺寸缩小,图像空间边缘的裂缝难以识别为正样本,为了解决这个问题,提出了采用2次滑动窗口技术检测图像中任意位置的裂缝,该方法比Canny和Sobel等传统边缘检测算法具有更优的鲁棒性,并且降低了噪声和分类错误. Silva等[10]提出了一种基于VGG16[11]的混凝土表面裂缝检测模型,证实了深度学习在目标检测中的性能. 李良福等[12]提出了一种基于深度学习的桥梁裂缝检测方法,该方法将桥梁裂缝图像切分为小的图像块,利用卷积神经网络对所有图像块进行分类,将其分为桥梁裂缝和桥梁背景两类,通过分类实现目标的检测. 刘美菊等[13]提出了一种软硬件结合的V型钢板焊缝检测方法,利用卷积神经网络对激光在V型焊缝形成的折线中心点进行识别,损失函数为预测点与标注坐标的欧氏距离. 该方法通过对网络参数和特征的压缩,缓解复杂网络用于简单角点检测带来的计算量过大的问题. 朱苏雅等[14]利用深度卷积神经网络模型U-Net[15]从背景中分割出裂缝,利用最小生成树算法实现裂缝的连接,最后,使用骨架算法和八方向搜索法实现裂缝宽度的测量. Yang等[16]提出了一种基于特征金字塔与层次增益网络(feature pyramid and hierarchical boosting network,FPHBN)的道路裂缝分割方法,通过特征金字塔融合上下文信息,通过层次结构重新从错分样本学习参数.
区域卷积神经网络(region-based convolutional neural network,R-CNN)系列方法首先生成候选区域,利用深度卷积神经网络对生成的候选区域提取特征,将提取出的特征输入分类器,从而实现分类和定位. 本文以缝隙目标为研究对象,提出了一种基于Faster R-CNN的缝隙检测与提取算法,该算法分为缝隙检测与缝隙提取2个阶段,缝隙检测的目的是定位缝隙图像中的缝隙目标边框,而缝隙提取是在检测出缝隙目标边界框后,从缝隙目标边框中提取出缝隙目标. 在缝隙检测阶段中,在Faster R-CNN的目标检测框架下,选取ImageNet数据集上预训练的VGG16模型作为特征提取网络,调整了网络模型使其适应具有小尺寸结构的缝隙目标,在VGG16预训练模型上利用铁轨裂缝图像数据集进一步训练网络参数,通过对缝隙检测网络的训练确定缝隙目标检测的最优超参数,得到缝隙目标边框. 在缝隙提取阶段中,通过数学形态学算法实现缝隙提取,首先利用自适应阈值法将缝隙目标分割出来,然后通过闭运算连接缝隙目标断裂部分,并使用连通分量标记法去除孤立的前景噪声,最后通过细化操作得到单像素宽缝隙目标,统计其像素数即可获得缝隙目标的长度值. 实验结果表明,本文提出的提取算法可准确且完整地提取出待检测缝隙图像中的缝隙目标.
1 方法概述
本文提出的缝隙提取算法分为2个阶段,如图1所示. 在缝隙检测阶段,利用Faster R-CNN得到缝隙目标边框;在缝隙提取阶段,利用数学形态学算法提取到缝隙目标并计算其长度值.

图1 本文算法的流程Fig.1 Pipeline of the proposed method
缝隙检测阶段中,使用Faster R-CNN检测框架进行缝隙检测,由于待检测的缝隙目标具有小尺寸结构的特点,在特征提取过程中容易失去其细节信息,因此,本文选取VGG16网络作为特征提取网络生成待检测缝隙图像的全局特征图,该网络仅使用3×3的卷积核,在相同感受域的条件下,提升了网络深度的同时减少了参数量,降低因卷积运算导致的缝隙目标细节丢失. 在ImageNet数据集预训练的VGG16模型上,使用缝隙图像训练集进行训练,并通过对缝隙检测网络的训练确定网络最优的超参数.
缝隙提取阶段通过二值化、去噪以及细化等操作,从缝隙目标边框中提取出缝隙目标. 首先,利用自适应二值化算法从背景中分割出缝隙目标,生成一幅二值图像. 二值化的过程通常会产生孤立的前景噪声和目标断裂,然后,通过断裂连接和去噪获得一幅干净完整的缝隙目标二值图像. 进一步对缝隙目标进行细化操作,得到单像素宽的缝隙目标. 最后,通过计算其像素点的个数,则可以得到缝隙目标的长度值.
2 缝隙检测
利用深度卷积神经网络的特征学习能力实现缝隙检测,即在缝隙图像数据集上对深度卷积网络进行训练,使得深度卷积网络学习缝隙目标的特征,从而具备检测缝隙目标的能力. 缝隙检测的目的是从复杂的背景中定位缝隙目标的边框.
本文使用Faster R-CNN作为缝隙检测的网络框架,使用VGG16作为缝隙目标的特征提取网络. 目标检测分为单阶段检测和两阶段检测2种,其中两阶段检测的性能更高,并且在两阶段网络中,Faster R-CNN利用候选区域生成网络(region proposal network,RPN)结构生成并筛选出了最可能包含目标的候选区域. 特征提取网络常用的是深层网络模型(例如 ResNet)和浅层网络模型(例如 VGG16),但是深层网络模型的结构较深,在小样本数据集上容易过拟合且用于提取小尺寸结构的缝隙目标特征时,更多的池化操作会使小目标丢失细节信息,因此,本文选用浅层网络VGG16作为特征提取网络.
Faster R-CNN网络模型利用RPN网络生成缝隙图像中的缝隙目标候选区域,然后筛选这些候选区域,最终通过二分类识别出缝隙目标候选区域,并通过边框回归确定缝隙目标边框,实现缝隙目标定位. 本文提出的缝隙检测阶段如图2所示,使用本文特征提取网络中conv5_3层的输出作为全局特征图,利用RPN网络通过锚点机制在全局特征图上生成多个不同尺度的候选区域,将候选区域分为缝隙类和背景类;分别获得每个候选区域为缝隙类和背景类的置信度,置信度最高的类别则标记为该候选区域的类别,并计算候选区域为缝隙类的回归损失,同时对候选区域的位置进行修正,并且为了避免同一个缝隙目标上存在冗余的候选区域,通过非极大值抑制算法对同一目标上的候选区域进行筛选,并将筛选出的候选区域输入感兴趣区域池化层中,使用候选区域对全局特征图进行裁剪,通过双线性插值将裁剪出的特征图缩放为14×14的固定尺寸,并通过最大池化操作将其缩小为7×7的尺寸;最后2个全连接层的作用是确定目标区域的类别,计算候选区域分别属于目标和背景分类概率,将其划分为概率更大的类别并再次通过边框回归对缝隙目标边框进行微调. 本文使用的缝隙图像中的缝隙目标属于小尺寸结构,因此,本文调整了网络模型,将原Faster R-CNN网络中RPN网络的锚点尺度128×128、256×256和512×512分别调整为64×64、128×128和256×256,调整后的锚点尺度更适合缝隙目标的检测.
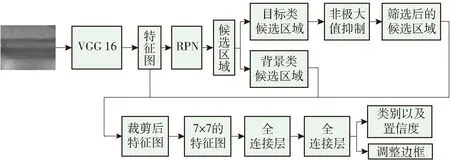
图2 基于Faster R-CNN的缝隙检测Fig.2 Crack detection based on faster R-CNN
VGG16的网络结构由13个卷积层、5个池化层、3个全连接层和1个Softmax层组成. 其中13个卷积层分为5组,分别是C1、C2、C3、C4和C5,5个池化层分别是P1、P2、P3、P4和P5. 其中:C1和C2各包含2个3×3卷积核且步长为1的卷积层,分别是conv1_1、conv1_2、conv2_1和conv2_2;C3、C4和C5各包含3个3×3卷积核且步长为1的卷积层,分别是conv3_1、conv3_2、conv3_3、conv4_1、conv4_2、conv4_3、conv5_1、conv5_2和conv5_3,5个池化层均采用池化窗口为2、步长为2的最大池化操作.
在VGG16的基础上,本文提出了适用于缝隙目标检测的特征提取网络. 首先,删除了VGG16的全连接层和Softmax层作为特征提取网络,然后为了降低池化层对小尺寸结构目标的影响,删除了P1、P2和P5池化层,并通过将conv1_2和conv2_2两个卷积层的步长设置为2实现下采样,最后为了保留更多的局部信息,将P3和P4的最大池化操作替换为平均池化操作,图3显示了本文使用的特征提取网络.

图3 特征提取网络Fig.3 Feature extraction network
其次,网络的学习性能和效果与超参数的设置有关,正则项系数、动量、基础学习率、批数据、学习率调整倍数、学习率调整步长和最大迭代次数是检测网络学习过程中重要的超参数,决定了网络模型的检测准确率.
本文在损失函数中加入网络参数的高斯正则项,其作用是避免参数出现过大的值. 正则项系数的作用是平衡交叉熵损失函数与高斯正则项的比重,正则项系数越大,对参数的抑制越大;反之,对参数的抑制也就越小. 本文采用动量参数梯度下降法更新参数,参数的更新可表示为
(1)
式中:v为动量,其初始值为0;m为动量系数;L为损失函数;θ为网络参数;η为学习率. 动量系数是决定参数更新的超参数,在学习率较小的时候,较大的动量能够加速收敛速度;在学习率较大的时候,较小的动量则可以减小收敛时的振荡幅度.
使用训练集中的一部分样本对模型进行一次反向传播的参数更新,称为一批数据;使用训练集的全部数据对模型进行一次完整训练,称为一代训练. 设定合理的批数据决定了网络训练的收敛效果,在显卡内存允许的范围之内批数据的量越大,梯度下降的方向越准确,在一定程度上可以减小损失值的振荡以及一代训练所需的迭代次数,在处理相同数据量的情况下加快收敛速度,但如果批数据的量过大,则容易陷入局部最优值;反之,当批数据的量较小时,批处理时输入的样本随机性更大,导致损失不易收敛.
学习率的作用是控制网络参数沿梯度方向的前进速度,当学习率的值设置过小时,权重更新速度降低,因此,收敛速度降低,从而增加了训练的时间;但是,如果学习率的值设置过大,会产生振荡,难以下降到最优值. 使用一批数据对模型进行一次参数更新的过程,称为一次训练. 本文的学习率采用等间隔下降策略调整的方式,每隔τ次训练,学习率降低为原来γ倍. 这里,τ表示学习率调整周期;γ表示学习率调整倍数. 最大迭代次数与学习率的设置有关,当取值过小时,会在学习率过高时停止训练,此时损失值可能还未收敛;反之,当取值过大时,学习率降为0之后,又会导致无效训练.
本文利用实际的铁轨裂缝数据集训练缝隙检测网络参数并确定最优的超参数,最后实现缝隙检测,得到缝隙目标区域.
3 缝隙提取
缝隙提取阶段是在缝隙检测阶段获得缝隙目标边框后,利用二值图像形态学算法从缝隙目标区域中提取出缝隙目标,主要包括二值化、去噪及细化等步骤.
本文利用自适应阈值法将缝隙目标区域中的缝隙目标分割出来,得到缝隙目标区域的二值图像. 图4(a)为一幅缝隙目标区域的灰度图像,通过自适应阈值法得到其二值图像,如图4(b)所示. 由于缝隙目标与背景存在部分特征相似的区域,所以导致缝隙目标区域二值图像中的缝隙目标出现狭窄的断裂. 为了使得缝隙目标连通,本文利用闭运算操作桥接缝隙目标的断裂部分,在保留原缝隙目标面积不变的条件下平滑缝隙目标边界. 对图4(b)所示二值图像使用3×3的方形结构元素进行闭运算操作,图4(c)为闭运算结果. 从图中可以看出,闭运算桥接了缝隙目标的断裂部分. 然后,本文使用连通分量标记法去除背景噪声,首先提取二值图像中所有的连通区域,然后计算各个连通区域中的像素数,最终将像素数小于阈值的连通区域中的像素赋值为0,实现移除孤立的前景噪声,图4 (d)为提取出的缝隙目标.

图4 缝隙提取Fig.4 Crack extraction
为了便于计算缝隙目标的长度,有必要对提取出的缝隙目标进行细化,但是由于闭运算时膨胀导致小噪声扩张与缝隙目标连接产生毛刺,这会影响细化结果,因此,先对二值图像进行去毛刺操作. 图4(e)为缝隙目标去毛刺后的结果,从而提取出干净的缝隙目标,其具有缝隙目标的原始物理特征. 最后通过细化操作获得单像素宽的缝隙目标,如图4(f)所示. 通过统计单像素缝隙目标像素点的个数可计算缝隙目标的长度值.
4 实验结果与分析
4.1 实验设置
本文算法是基于深度学习Caffe开源框架实现的,使用Python以及Matlab语言开发. 本文实验均是在单频为3.40 GHz的酷睿i7- 6800K的CPU,32.0 GB内存的工作站上实现,并使用单块NVIDIA GeForce GTX1080Ti的GPU实现加速.
本文分别在铁轨裂缝图像数据集[17]和5个具有像素级标注的道路裂缝数据集CRACK500[16]、Cracktree200[18]、CFD[19]、GAPs384[16]和AEL[16]上验证本文算法的性能.
为了防止网络参数过大导致网络过拟合,本文将正则项系数取值为0.001,增加了对网络参数的抑制. 本文采用的是最小批量梯度下降法更新权重,其优势在于利用小批图像寻找最速梯度,同时减少了一代训练的迭代次数,因此,本文设定批数据为2幅图像,每幅图像保留512个感兴趣区域. 学习率η的初始值设置为6.25×10-4,学习率调整倍数γ取值为0.6,并设置每迭代1 500次进行一次学习率的调整. 由于学习率的初始值设置较大,会存在损失值振荡的现象,为了防止训练振荡并提升检测准确率,设置动量系数m为0.99. 本文将最大迭代次数设置为12 000,在学习率降为0时停止迭代,避免无效训练.
4.2 在铁轨裂缝数据集上的实验
本文使用铁轨裂缝图像数据集计算缝隙检测指标并与文献[1]的算法进行比较. 本文所使用铁轨裂缝图像数据集由2 533幅图像构成,随机选取2 026幅图像作为训练集,其余507幅图像作为测试集. 由于部分图像中背景与缝隙目标的特征区别不够明显,不利于检测网络区分缝隙目标与背景,所以不将此类图像加入训练集中. 铁轨裂缝图像数据集如图5所示,包括具有明显缝隙目标特征的图像(见图5(a))、背景干扰图像(见图5(b))和不具有明显缝隙目标特征的图像(见图5(c)).

图5 铁轨裂缝数据集图像样例Fig.5 Samples from the railroad crack dataset
在检测网络训练前,对铁轨裂缝训练集中的图像进行预处理,首先将图像归一化为1 400×1 200像素,然后将完整标注的数据集转化为标准的VOC格式,最后在铁轨裂缝图像数据集与预训练模型上对缝隙检测网络进行训练与测试.
将本文的算法与文献[1]的算法进行比较,在铁轨裂缝数据集上分别训练文献[1]的算法和本文的检测网络,文献[1]的结果由作者提供的程序在相同的训练集上运行得到. 为了验证本文缝隙检测阶段的准确率,选用平均准确率作为评价指标. 计算平均准确率首先需要获得检测算法在整个测试集上的查准率和查全率.
候选区域为缝隙类的置信度高于阈值时,检测为目标,否则检测为背景. 查准率定义为正确检测的目标占检测总数的比例,即
(2)
式中:TP为正确检测为目标的数量;FP为实际为背景、错误检测为目标的数量;TP与FP之和为检测为目标的总数.
漏检指的是目标错误检测为背景,查全率定义为正确检测的目标占实际目标总数的比例,即
(3)
式中:FN为实际为目标、错误检测为背景的数量;TP与FN之和为实际目标的总数,根据TP可以计算出FN.
不同的置信度阈值会改变查全率与查准率的值,为了衡量缝隙检测阶段在测试集上对缝隙目标的识别能力,计算不同的阈值下在测试集上的查全率和查准率,得到P-R曲线(如图6所示). 图6(a)为文献[1]的算法在缝隙测试集上得到的测试结果;图6(b)为本文算法在缝隙测试集上得到的测试结果. 从图中可见,文献[1]的算法随着查全率的增大,查准率下降很快且其值不高,而本文算法在查全率增大时,能够保证一定的查准率,相比较而言,本文算法在铁轨裂缝数据集上的查全率和查准率高于文献[1]的算法.

图6 本文算法和文献[1]的算法在铁轨裂缝 测试集上的P-R曲线比较Fig.6 Comparison of the proposed method with Ref. [1] on the railroad crack testing dataset in terms of P-R curves
本文采用11点法计算平均准确率,设置11个不同的查全率阈值T,查找当查全率值高于这11个给定的阈值时查准率的最大值PT,计算其平均值得到平均准确率
(4)


表1 本文算法与文献[1]的算法在铁轨裂缝测试集上的平均准确率查全率R和查准率P比较
图7显示了本文算法在部分铁轨缝隙图像上的提取结果. 图7(a)为部分待检测缝隙图像,图7(b)显示了检测出的缝隙目标边框. 从图中可以看出,虽然用于测试的待检测缝隙图像中存在背景干扰,但是不会影响对缝隙目标的检测,仍能检测出完整的缝隙目标. 图7(c)显示了完整的缝隙目标区域,从中提取出的缝隙目标如图7(d)所示;图7(e)为细化的缝隙目标,计算其像素点个数,即缝隙目标的长度值.

图7 本文算法在铁轨裂缝数据集上的结果Fig.7 Results of the proposed method on the railroad crack dataset
图8显示了缝隙检测网络的训练曲线,每20次迭代计算1次平均损失值. 图8(a)为随着迭代次数增加的学习率更新曲线;图8(b)为损失值的下降曲线. 从图中可以看出,在缝隙检测网络进行端到端的迭代训练时,训练损失值不断下降且趋于稳定,这表明缝隙检测网络的训练是收敛的.

图8 本文算法在铁轨裂缝训练集上的训练曲线Fig.8 Training curves of the proposed method on the railroad crack training dataset
4.3 在道路裂缝数据集上的实验
本文使用具有像素级标注的5个道路裂缝数据集计算缝隙提取指标,并与FPHBN算法[16]进行比较. 本文所使用的5个道路裂缝数据集中,CRACK500数据集是目前最大的具有像素级标注的公开裂缝数据集,由500幅分辨率为2 000×1 500像素的裂缝图像构成,其中250幅图像用作训练集,200幅图像作为测试集,50幅图像作为验证集. Cracktree200共包含206幅具有像素级标注的800×600像素的裂缝图像. CFD数据集由118幅480×320像素的路面裂缝图像组成的具有像素级标注的数据集. GAPs384数据集共有509幅具有像素级标注的640×540像素的裂缝图像. AEL数据集共包含38幅800×600像素具有像素级标注的裂缝图像.
为了定量评价本文算法对缝隙目标提取的准确率,本文使用F1-score和平均交并比(average inter-section over union,AIU)[16]作为评价指标,将本文的算法与FPHBN算法和全卷积网络(fully convo-lutional network,FCN)算法[20]进行比较. FPHBN算法是一种基于上下文信息融合的道路裂缝图像检测方法,其测试结果由作者直接提供;FCN算法是一种基于全卷积网络的图像语义分割方法,其测试结果是由作者提供的程序运行得到. 为了比较的公平性,本文的算法和FCN算法在道路裂缝数据集上的设置与FPHBN算法一致,在CRACK500训练集上训练本文的算法,在CRACK500测试集上计算缝隙提取指标,并且为了验证算法的泛化能力,分别在Cracktree200、CFD、GAPs384和AEL数据集上测试算法的性能.
F1-score是一个度量查全率和查准率的综合指标,即
(5)
式中常数2的作用是使查全率和查准率为1时F1-score的值为1. 从式(5)可以看出,若查全率或查准率中任有一个值较小都会导致F1-score的指标值降低. 本文使用最优数据集尺度[21](optimal dataset scale,ODS)和最优图像尺度[21](optimal image scale,OIS)两种方法搜索最优阈值计算F1-score的最大值. 最优数据集尺度指的是在整个测试集上确定唯一最优的阈值,而最优图像尺度则是在每幅图像上选择一个最优的阈值,本文分别计算了2种阈值搜索方法下F1-score达到的最大值.
平均交并比RAIU是缝隙目标提取性能的度量值,计算正确提取的目标像素数(提取结果与真值交集的像素数)与正确提取的目标、错误提取的目标和错误提取的背景像素数之和(并集)的比值,即
(6)
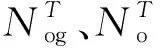
表2显示了FPHBN算法、FCN算法和本文算法在CRACK500测试集的Cracktree200、CFD、GAPs384、AEL数据集上采用最优数据集尺度和最优图像尺度上的F1-score和RAIU. 从表中可知:本文算法在CRACK500测试集上,利用最优数据集尺度方法得到的F1-score指标高于FPHBN算法的5.1%,高于FCN算法的32.1%;利用最优图像尺度方法得到的F1-score指标高于FPHBN算法的2.1%,高于FCN算法的31.9%;RAIU指标高于FCN算法的0.9%. 这表明本文算法在CRACK500测试集上具有较好的缝隙提取性能. 为了验证本文算法的泛化能力,分别在Cracktree200、CFD、GAPs384和AEL数据集上进行比较. 从表2中的结果可以看出:本文算法在Cracktree200数据集上通过最优数据集尺度方法的F1-score指标高于FPHBN算法的14.9%,高于FCN算法的43.0%;通过最优图像尺度方法的F1-score指标高于FPHBN算法的8.8%,高于FCN算法的43.0%;RAIU指标高于FPHBN算法的8.4%,高于FCN算法的9.0%. 在CFD数据集上,本文算法基于最优数据集尺度方法得到的F1-score指标高于FPHBN算法的4.9%,高于FCN算法的36.9%;基于最优图像尺度方法得到的F1-score指标高于FPHBN算法的2.8%,高于FCN算法的36.9%;RAIU指标高于FPHBN算法的18.2%,高于FCN算法的24.0%. 本文算法在GAPs384数据集上采用最优数据集尺度方法得到的F1-score指标高于FPHBN算法的28.2%,高于FCN算法的41.2%;采用最优图像尺度方法得到的F1-score指标高于FPHBN算法的27.3%,高于FCN算法的41.4%;RAIU高于FPHBN算法的12.3%,高于FCN算法的16.9%. 实验结果表明本文算法在Cracktree200、CFD和GAPs384数据集上提取的缝隙比FPHBN和FCN方法更加准确、完整,并且在具有光照以及背景噪声等干扰的GAPs384数据集上,本文算法具有更好的泛化能力. 本文算法在AEL数据集上的RAIU高于FPHBN算法的16.3%,高于FCN算法的19.1%,通过最优数据集尺度方法得到的F1-score指标高于FCN算法的27.5%;通过最优图像尺度方法得到的F1-score指标高于FCN算法的27.6%. 因此,在AEL数据集上本文算法能够提取出更完整的缝隙目标.
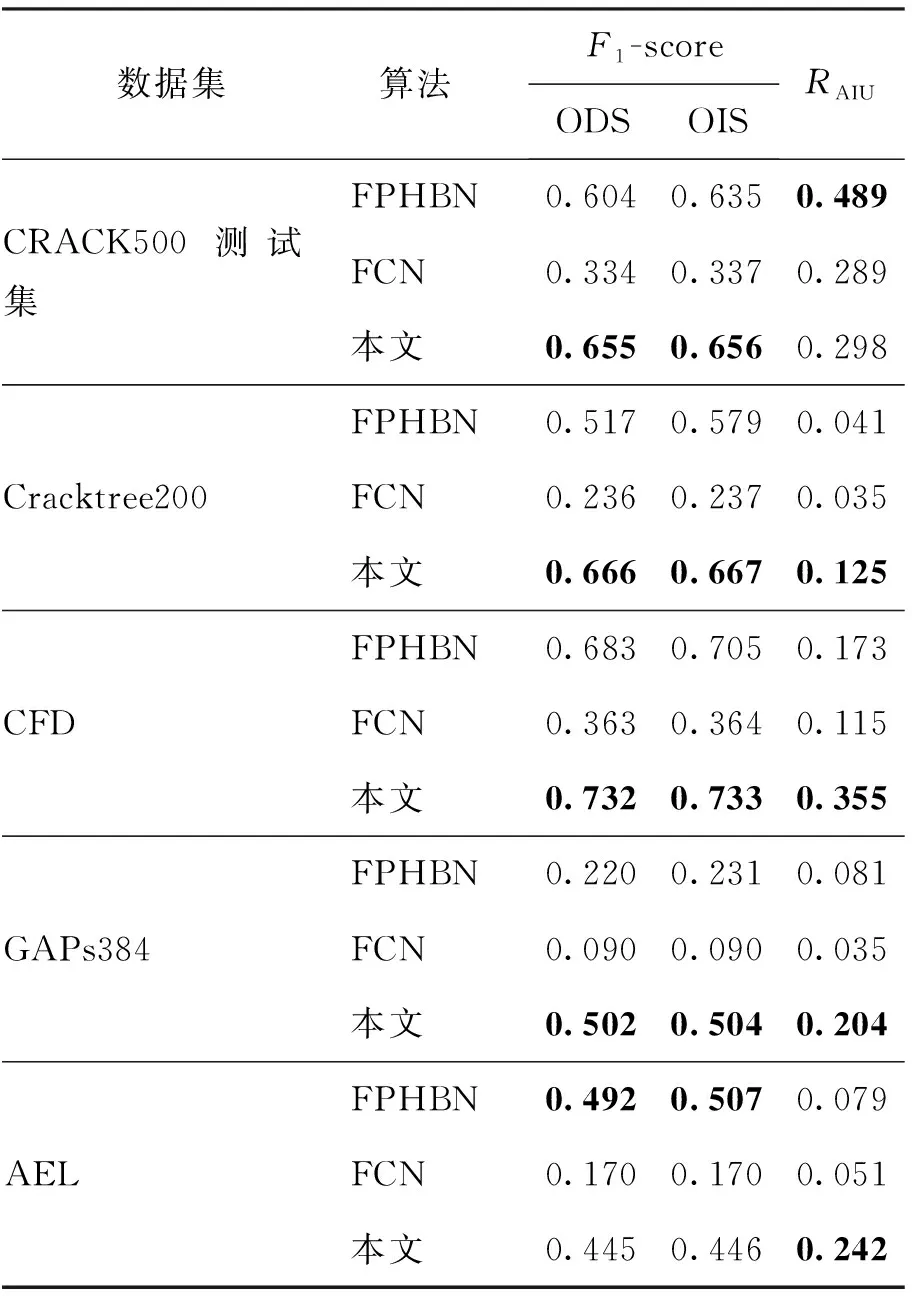
表2 本文算法与FPHBN算法在道路裂缝数据集上基于ODS、OIS的F1-score和RAIU的比较
图9显示了在CRACK500、Cracktree200、CFD、GAPs384和AEL五个数据集的部分图像上本文算法与FPHBN算法的定性测试结果,FPHBN的定性结果由作者提供. 5个数据集中的部分待提取图像如图9(a)所示;图9(b)是数据集提供的像素级标注的真值图像;图9(c)显示了FPHBN算法的缝隙提取结果;图9(d)显示的是FCN算法的缝隙提取结果;图9(e)为本文算法的缝隙检测结果;图9(f)显示了本文算法的缝隙提取结果. 从图中可以看出,对于CFD数据集的待测图像,FPHBN未提取出左上角的缝隙,FCN提取的缝隙目标失去了缝隙的原始特征,而本文算法提取出了边缘清楚的缝隙目标;对于AEL和Cracktree200数据集的待测图像,FPHBN提取的缝隙目标边缘模糊,FCN没有完整提取出缝隙目标,但是本文算法不仅可以完整提取出缝隙目标,而且还能保留缝隙目标的原始特征;对于GAPs384数据集的待测图像,FPHBN算法和FCN算法均受到了图像右侧噪声的干扰,因此,在分割结果中的噪声更大,本文算法受到右侧噪声的影响较少. 综上所述,FPHBN提取出的缝隙目标边缘模糊,而且失去了缝隙原始特征,FCN的提取结果虽然边缘清晰,但是没有正确提取小尺寸结构的缝隙目标,而本文算法能够提取到更加完整的缝隙目标,并且缝隙目标的边缘清晰.

图9 本文算法和FPHBN算法在道路裂缝数据集上的定性比较Fig.9 Visual comparison of the proposed method and the FPHBN method on the road crack dataset
4.4 池化参数分析
缝隙目标是具有小尺寸结构的目标,在特征提取进行下采样的过程中,容易因为池化而丢失其特征信息,所以会对网络的检测能力产生一定的影响. 本文为了检验池化参数对缝隙目标检测的影响,对特征提取阶段网络的池化层进行了参数分析.
本文在VGG16特征提取网络的P1、P2、P3和P4四个池化层上设计了3个实验,分别是删除池化层、修改池化方式和删除部分池化层的同时修改部分池化方式. 表3给出了池化参数分析得到的测试结果. 从表3中的测试结果来看,使用原VGG16网络作为特征提取网络时,在测试集上的平均准确率为0.600 3,而本文提出的3种池化参数修改方式均优于原VGG16网络. 首先,原VGG16网络每组卷积层后均使用的是最大池化操作,本文修改了池化方式,将P2层的最大池化修改为平均池化,在测试集上的平均准确率为0.626 7,相比较使用原VGG16网络作为特征提取网络在平均准确率上提升了2.64%. 实验结果表明,在小尺寸结构缝隙目标上,相比较最大池化操作,平均池化方式在缝隙目标检测中能够保留更多的局部信息. 其次,因为最大池化操作可以由更大步长的卷积层代替[22],所以本文删除了池化层,利用步长为2的卷积层实现下采样操作,当删除P1层并修改conv1_2的步长为2时,在测试集上的平均准确率达到0.627 0. 实验结果表明,通过删除池化层并修改卷积层步长代替下采样操作,对于缝隙检测准确率的提升效果是显著的,可以减少因最大池化操作带来的细节特征信息丢失. 最后,基于以上2个实验结论,本文提出了在删除部分池化层的同时更改部分池化层的池化方式,在删除了P1和P2,更改conv1_2和conv2_2的步长为2,并修改P3和P4的最大池化为平均池化时,在测试集上的平均准确率达到0.638 7,相比较前2种池化参数,平均准确率分别提升了1.20%和1.17%,并且比使用原VGG16网络的池化参数在平均准确率上提升了3.84%.

表3 不同的池化层参数对应的平均准确率
从池化参数实验分析的结果可知,原VGG16网络的最大池化操作会导致小尺寸结构的目标失去更多的局部信息,造成小尺度缝隙目标更多细节特征信息的丢失,因此,本文提出的特征提取网络更适用于检测缝隙目标.
5 结论
1) 本文提出了一种基于Faster R-CNN的缝隙检测与提取算法,通过缝隙检测阶段和缝隙提取阶段实现提取缝隙图像中的缝隙目标. 基于Faster R-CNN的缝隙检测阶段首先选取了适用于缝隙目标检测的预训练模型,其次调整了RPN网络,并根据实际应用调整了正则项系数、基础学习率、动量、批数据等网络超参数,最后通过对缝隙目标区域的分析,利用形态学算法实现了提取出具有原始物理特征的缝隙目标,通过细化缝隙目标,统计其像素值可计算出缝隙目标的长度值.
2) 实验结果表明,在铁轨裂缝图像数据集上,本文提出的缝隙提取算法的平均准确率达到63.87%;在CRACK500道路裂缝测试集上,本文提出的缝隙提取算法在最优数据集尺度上F1-score指标可以达到65.5%,在最优图像尺度上的F1-score指标可以达到65.6%,RAIU可以达到29.8%,并且本文提出的缝隙提取算法具有较强的泛化能力.
3) 目前,本文使用的数据集规模较小且数据集的样本数量与样本的复杂度不匹配,因此,在未来的工作中将增加训练样本数据集,并研究针对复杂小样本的检测方法,进一步实现检测准确率的提升.
