基于奖励引导的六足机器人自主步态学习
2021-03-08朱晓庆冉登宇钱义肇王明超
朱晓庆,陈 璐,冉登宇,钱义肇,王明超,别 桐
(1.北京工业大学信息学部,北京 100124; 2.北京工业大学樊恭烋荣誉学院,北京 100124)
一直以来,多足机器人都是自主机器人的重要研究方向之一,并且研究热度不断上升[1-3]. 四足机器人小巧灵活,但行走稳定性较差. 八足机器人虽具有较高稳定性,但步态控制复杂. 六足机器人是典型的多足机器人[4],根据其自身的结构特点,可以在保持较大承载能力和运动灵活性的同时获得稳定的行进步态,非常适合在复杂地况作业[5],在科研、探险和工程勘测等方面有较大的发展潜力[6],例如:外太空攀登、野外探测[7]、极端条件操作[8]等. 因而,六足自主机器人的控制具有极高的研究价值及广泛的应用前景.
为解决多足机器人步态控制难题,目前专家学者在结构方面做了很多工作,解决此问题的方向大概分为2类:一类是腿部结构. HITCR- Ⅱ、ATHLETE等机器人的腿部结构通过关节进行耦合,灵活度高,但对驱动控件的精度及控制算法的复杂度有较高要求;rhex的半圆形单足简化结构与控制算法,可以实现在复杂地形上的高效行走,但其腿部设计导致其容易发生应力集中的现象,可通过提高材料性能或结构进行改进. 另一类是机体结构设计. 目前,BigDog、Atlas等高灵活性多足机器人的机体设计多使用连杆结构,使其具有更高的稳定性及步态的协调性[9].
针对多足机器人步态学习的控制难题,国内外常见的步态生成算法是优化算法和强化学习[10-12]. Zhang等[13]针对六足机器人提出一种基于分布式局部规则网络的步态生成算法,具有较好的鲁棒性和稳定性,但因其步幅、步序受环境制约,步态收敛性欠佳,难以与生物步态的节律性行为特征相吻合[14]. Santos等[15]基于 CPG 原理的步态规划算法可实现运动节律的动态调整,但其环境适应能力较差,且难以实现步态模式的平滑转换[14]. 目前,虽然毛勇等[16]通过强化学习对连续状态进行离散化处理实现机器人的步态生成,但行走本身就是连续化问题,使用离散化的学习方法存在离散间隔难以控制的缺点,过大的间隔会造成信息丢失,控制精度降低,过小的间隔则因为状态个数的指数型增长而造成“维数灾难”问题.
本文在Sutton等[17]的研究基础上,利用行动器- 评判器(actor-critic,AC)网络实现机器人连续空间下的在线步态学习,用于解决机器人在未知环境下进行技能学习的难题,以提高机器人自主控制系统的灵活性和鲁棒性.
1 六足机器人设计
1.1 腿部设计
现有多足机器人腿部结构多样,如美国东北大学研制的Lobster[18]等多足机器人,腿部仿照蜘蛛,以多个离散点的形式依靠地面进行支撑. 这样的设计可以增加机器人行走时的稳定性,但因为需要精确控制各关节使之能够配合行走,加大了控制难度. 波士顿动力研制的Rhex[19]六足机器人则采用半圆形柔性腿的设计,该单自由度的腿部结构有利于抑制机器运动时本体在垂直方向的波动,使所需要的驱动力矩和能量都有所减小. 本文的六足机器人腿部设计借鉴Rhex模型,在此基础上采用三层不完全叠加的弹簧钢片设计,见图1,可有效避免应力集中导致的中心部位形变甚至断裂,见图2,提高腿部的稳定性与负载能力.

图1 三层钢堆叠腿部结构Fig.1 Three layers of leaf spring

图2 腿部受力对比Fig.2 Force analysis of the legs
1.2 传动机构设计
自然界中“六足纲”昆虫步行时,一般不是六足同时直线前进,而是将3对足分成2组,以三角形支架结构交替前行. 目前,大部分六足机器人采用仿昆虫的结构,6条腿分布在身体的两侧,通常右侧前腿、左侧中腿、右侧后腿为一组,左侧前腿、右侧中腿、左侧后腿为另一组. 当一组支撑地面形成稳定的三角支撑结构,同时另外一组快速抬腿、前摆、落地并形成新的三角架支撑,如此交替进行,这种行走方式的效率更高,行进速度更快. 本文基于该步态,借助机械式同步传动机构构建六足机器人模型. 传动机构由2组相同的定轴轮系组成,每组定轴轮系由1个电动机驱动,带动3条腿同步转动,见图3. 第1组定轴轮系带动六足机器人的右前、左中、右后3条腿,实现组内3条腿的完全同步,第2组定轴轮系由另一电机驱动,带动其余3条腿. 至此,六足机器人的6条腿被以机械方式约束为2组腿,组内完全同步,组间通过配合进行行走.
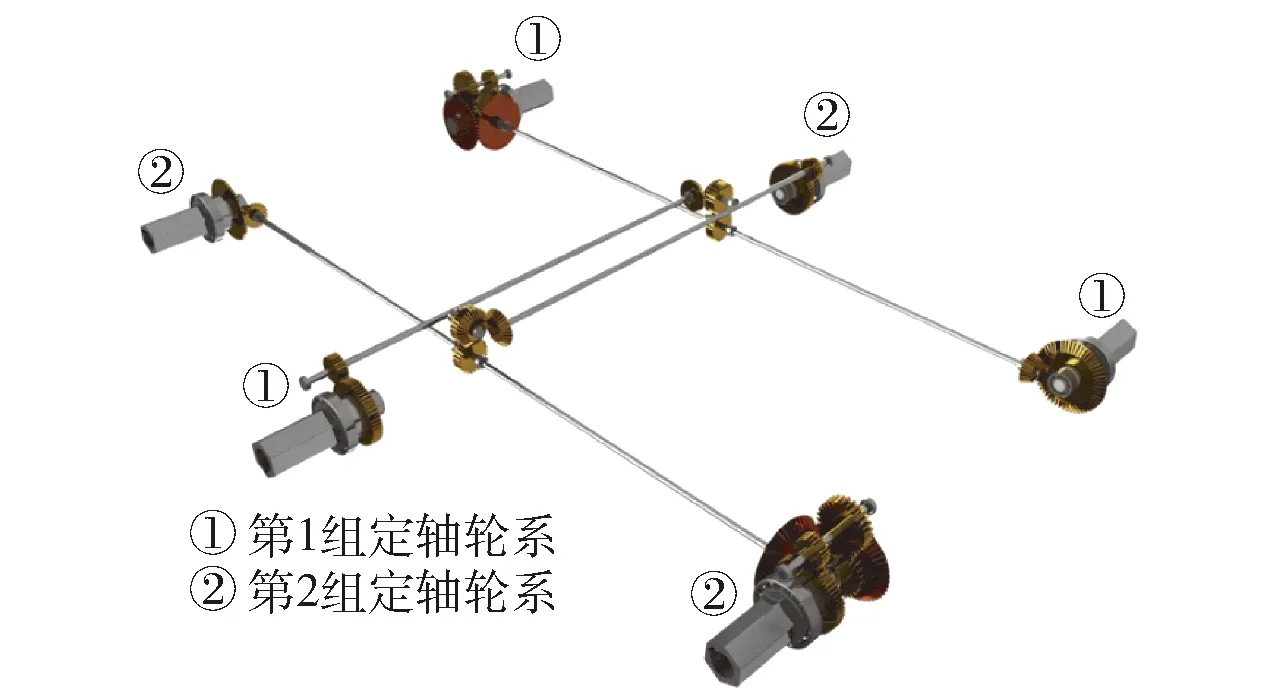
图3 机械式同步传动机构Fig.3 Transmission mechanism
本文设计完成的六足机器人外观渲染见图4,实物见图5.

图4 外观渲染图Fig.4 Overview of the robot

图5 实物图Fig.5 Physical model
2 基于AC算法的神经网络控制器设计
2.1 网络结构
AC算法采用人工神经网络(artificial neural networks,ANN)作为动作网络,采用卷积神经网络(convolution neural networks,CNN)作为评价网络,建立神经网络的基本结构. 为了提高AC算法的时间信度分配能力和学习效率,Sutton等[17]提出可以n步备份的适合度轨迹e(t),在CNN中采用时间差分学习TD(λ),来更新网络参数并记录当前的动作轨迹. 将TD误差沿当前路径反向传播,无须显式记录机器人的行动路径即可在兼顾机器人一段时间内的动作、状态情况下更新网络,提高评价函数的精确度和强化学习系统的预报能力. 网络结构见图6.

图6 网络结构图Fig.6 Network structure diagram
CNN根据评价函数和强化信号,利用值函数逼近的方法进行更新,评价函数V(t)更新为
V(t)=V(t-1)+lcδ(t-1)e(t-1)
(1)
式中:δ(t)=V(t)-[V(t-1)-r(t)]为时间差分误差;lc为CNN时间因子;r(t)为奖惩函数;e(t)为适合度轨迹.
(2)
式中:γ为折扣因子,表示近期回报预测和远期回报预测的重要程度;λ为迹衰减系数;s为当前状态;st为行动策略.
ANN利用确定性策略梯度下降方法更新权值,其权值更新公式为

(3)
式中:la为ANN的时间因子;μ(t)为动作策略.
2.2 奖惩函数设计
对于智能体来说,评价行为的好坏往往由多个指标或因素来决定,但由于奖惩函数的评价指标中存在相互制约问题,这些评价指标往往不能同时达到最优. 在实际情况中,强化学习算法收敛的结果往往是不可控的,很难迅速、准确地收敛到预期指标. 为克服以上不足,本文提出了一种奖励引导机制.
在机器人行走过程中,其机身的平均速度和机身稳定度是衡量机器人步态优劣的重要评价指标. 但是对于某些机器人来说,如六足机器人,速度和稳定度2个评价指标相互制约,即机身稳定时机器人不能以最快速度前进,在前进速度较快时机身很难保持稳定,二者无法同时达到最优情况. 此时若奖惩函数仅有0和-1两个值,由于速度和稳定度2种指标满足条件后都会给予奖励,就可能出现“奖励黑客”的情况.
机身平均速度与机器人的行走距离呈线性函数关系,归一化的平均速度计算公式为
(4)
式中:N为一段时间T中的步数;vmax为机器人行进速度的最大潜力值;v(i)为第i步时机器人的瞬时速度;n为当前的步数.
在训练机器人行走的过程中机器人的步态是从杂乱逐渐收敛成稳定的,所以只能计算机器人行走的阶段性稳定度. 对于机器人的行走步态来说,稳定度与机器人重心高度成函数关系. 在神经网络的训练过程中,稳定度不仅应该和当前时刻重心高度有关,还应该与之前平均重心高度有关. 归一化稳定度的计算公式为
=
(5)
式中:h(i)为第i步时机器人重心的高度;为从当前步往前看N步(或前n步)的高度值平均.
为此,本文在奖惩函数r(n)中引入权重指数p,q,从而引导算法的收敛方向,表达式为
r(n)=p(1-(n))+q(n)
(6)
式中:权重指数p+q=-1,且p,q∈[-1,0].
自然界中许多现象是很复杂的,如动物的步态学习,但其本质是简单的,只需简单形式化即可. 也就是说,通过最少个数的原始概念和原始元素的使用来达到目的——在世界图像中尽可能地寻求逻辑的统一,即逻辑元素最少. 基于简单性原理,将机器人的整个技能学习过程评价为两部分:先判断学习成功与否,然后判断再学习过程有无进步. 基于这4种组合,按照等分原则将[-1.0]区间进行等分,以完成奖惩函数进行四级的划分如下:
若-1≤r(t)≤a,则r(t)=-1;
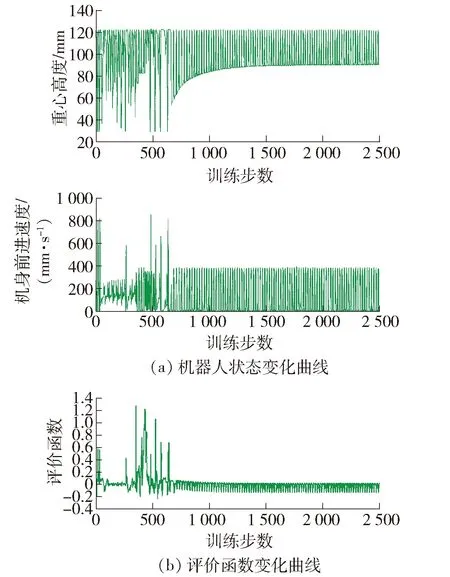
若a 若b 若c 式中:a、b、c为阈值,且按照等分区间原则,a=-0.75,b=-0.5,c=-0.25. 在Inventor中建立六足机器人的机械模型,然后在ADAMS中对该模型施加约束和驱动. 将ADAMS的输入状态变量设置为机器人控制量,即每组腿转速v1(m/s)、v2(m/s),输出为描述机器人状态的状态量:重心高度h(m),机身速度v(m/s),每组腿的位置θ1(°),θ2(°)等. 由于训练样本需要强化学习系统不断地与环境交互而顺序产生,因此利用ADAMS运动仿真平台提供的机器人机身状态量作为与环境交互产生的训练样本,将该样本作为MATLAB神经网络的输入,并将神经网络训练输出的动作作为控制ADAMS模型输入. 至此,基于ADAMS动力学平台的MATLAB控制算法平台得以实现. 将六足机器人在未知环境中自主学习运动步态作为控制目标,在改进型AC算法训练实验中,动作网络ANN采用3层神经网络结构N3[4,20,2],输入为机器人的4个状态量(h,v,θ1,θ2),输出为机器人的控制量,即2组腿的控制速度(v1,v2). 评价网络CNN同样采用3层神经网络结构N3[6,20,1],输入为机器人的4个状态量以及ANN输出的2个控制量,CNN的输出为评价函数V(t). ANN与CNN神经网络权值的初始值均在[-1,1]之间随机选取,机器人的状态数据每0.1 s测量1次. 机器人以站立状态为初始状态开始实验. 在步态训练实验中,机器人跌倒(机身稳定度小于阈值)即认为失败,并根据当前状态通过奖惩函数计算应有的惩罚力度,更新权值后中止本次实验. 重新复位为初始状态后开始下一次实验,此时网络权值在之前的基础上继续更新. 如果机器人在学习过程中连续多次无明显进步或出现退步,则将机器人复位,并把权值重新设为一定范围内的随机值. 如果机器人的其中一次实验保持2 000步,且没有出现惩罚,则认为机器人已经学会在该环境下的行走步态,训练结束. 在爬越障碍物的实验中,将机器人放置在障碍物之前,用相同的算法训练机器人. 但由于实验目标变为翻越障碍物,因此需要改变神经网络的奖惩函数中的目标变量变为机器人能否在规定时间内越过障碍. 为了训练出机器人在较快速度下的行走步态,将机身平均速度作为主评价指标,式(6)中参数被设置为p=-0.85,q=-0.15,使用tanh激活函数,神经网络采用梯度下降法更新. 机器人在训练过程中的状态量、评价函数的变化曲线如图7(a)(b)所示. 神经网络经过大约400步的训练后,描述机身的状态量从最初始无序变化逐渐收敛为有序的周期变化. 从收敛后的步态来看,虽然每组腿的转动速度在1周之内是不同的,但2组腿在着地时的支撑点在较小的范围内变化. 这种交替式的三角步态具有较高的前进速度,平均速度可达0.204 m/s,但收敛后重心高度的变化值达到0.074 m,稳定性较差. 图7 机身平均速度为主评价指标时机器人仿真曲线Fig.7 Simulation curve of the robot with the average speed of the fuselage as the main evaluation index 为了训练机器人在平稳状态下的行走步态,现将机身稳定度作为主评价指数,将式(6)中参数设置为p=-0.15,q=-0.85,使用tanh激活函数,神经网络采用梯度下降法更新. 机器人在训练过程中的状态量、评价函数的变化曲线如图8(a)(b)所示. 神经网络经过大约1 000步的训练后收敛. 从收敛后的步态来看,与上述结果不同的是,机器人并没有收敛至交替步态,而是呈现出一组腿支撑、一组腿旋转的步态. 在这种步态下,机器人的重心高度变化相对较小,仅有0.031 m,具有良好的稳定性,但机身平均速度较低,仅为0.118 m/s. 图8 机身稳定度为主评价指标时机器人仿真曲线Fig.8 Simulation curve of the robot with the fuselage stability as the main evaluation index 综合图7、8两组实验结果可知,在不同的奖励引导条件下,通过训练,机器人收敛于2种不同的行走步态. 图9给出了2种不同评价指标下的机器人高度收敛结果,其中棕色曲线h1表示主评价指标为稳定度情况下机器人重心高度的收敛结果曲线,此时机器人学习到一组腿支撑不动,另外一组腿以恒定速度运动的步态,类似于人类“拄拐”前进;红色曲线表示主评价h2指标为机身速度情况下机器人重心高度的收敛结果曲线,此时机器人学习到三角步态,2组腿以最大速度配合奔跑,类似猎豹等动物高速奔跑时步态. 图9 2种评价指标下机身高度变化曲线Fig.9 Curves of fuselage height under two evaluation indexes 机器人的越障行为实际上是机器人适应非结构化地形的过程,如果机器人能够以某种步态通过几种典型的障碍,如斜坡、台阶、壕沟、楼梯等,则可以通过这些步态的有效组合达到适应非结构化地形的目的. 通过仿真测试机器人能否翻越这几种典型地形,即可验证本机器人自主学习算法在非结构化地形上的有效性. 由于文章篇幅的限制,下文将只对最有代表性的翻越木块和爬越楼梯这2个地形的实验结果进行详细分析. 图10为机器人学习翻越高为125.0 mm、长1 000.0 mm的物块时的实验过程,图11为机器人在该过程中机身的高度变化曲线. 图12为机器人学习爬越四阶高为100.0 mm、长600.0 mm的台阶时的实验过程. 实验结果表明,机器人能够在这种算法下收敛到翻越障碍物的步态. 通过上述不同的非结构化地形实验结果可知,神经网络控制器有很好的泛化能力和环境适应性. 图10 机器人在仿真环境下翻越障碍物Fig.10 Robot crossing obstacles in simulation environment 图11 机器人爬木块时机身高度变化曲线Fig.11 Curve of fuselage height when robot climbing wood block 图12 机器人在仿真环境下爬越台阶Fig.12 Robot climbing steps in simulation environment 1) 本文基于机械式步态同步六足机器人模型,可实现1组内3条腿的完全同步,而在未知环境中2组腿之间配合可以由强化学习算法训练习得. 2) 本文基于AC算法,提出了一种新型奖励引导机制,该机制应用于存在相互制约的多评价指标强化学习模型. 当六足机器人分别在以速度和稳定度为主评价指标的条件下进行实验时,呈现出三角步态和支撑行走这2种不同收敛结果,可见该算法能够根据不同主评价指标习得对应的、不同需求下的最优步态. 3) 基于奖励引导机制的自主步态学习算法具有收敛速度快、环境适应性强的优点. 在升级物理样机控制器性能后,后续将开展实物技能学习实验,以进一步验证算法有效性. 对于六足机器人的步态自主学习问题,未来对于六足分立式控制的步态算法有待进一步研究. 考虑到奖惩引导机制具有很好的收敛效果及学习引导性,可以进一步深化奖励引导机制的应用.3 实验结果与讨论
3.1 六足机器人技能学习实验平台搭建
3.2 实验设计
3.3 步态训练结果分析


3.4 非结构化地形实验结果



4 结论
