深度强化学习应用于电力系统控制研究综述
2021-03-07宋鹏飞杨宁崔承刚闫南奚培锋
宋鹏飞,杨宁,崔承刚,闫南,奚培锋
(1.上海电力大学,上海200090;2.上海市智能电网需求响应重点实验室,上海200333)
0 引言
电力系统是一个包含发电、输变电、用电等环节的综合系统,是现代社会的重要基础设施。电力系统故障(部分或完全停电)会导致巨大的经济损失[1]。2003年8月14号,美国和加拿大电力系统部分地区停电造成的经济损失高达100亿美元。此外,未来将会有更多的服务设备依赖于电力(例如新能源汽车、交通运输等系统)。因此保障电力系统的稳定运行至关重要。
随着不可再生能源的不断消耗和国家推进高效清洁能源体系结构的建设,以风能和太阳能为主的分布式能源通过电力电子变换器接入到电力系统,降低了系统的惯性,对系统的稳定运行产生了冲击[2]。因此需要寻求先进的控制技术,来确保从发电源头到最终用户端电力传输的可靠性,并防止或减少系统的停电现象,避免巨大的经济损失和社会后果。
逐渐完善的通信基础设施和强大计算能力的控制设备为实施高级的控制方案提供了可能性。控制工程、计算机科学、大数据、应用数学等理论的发展为控制系统设计提供了更多的高级控制算法。近年来,深度强化学习在电力系统控制与决策方面的应用研究已得到各界人士的认可,2018年国家电网正式发文成立人工智能应用研究所。
机器学习可以分为监督学习、无监督学习和强化学习。不同于监督学习和无监督学习,强化学习是一种自监督的学习方式:智能体一方面基于动作和奖励数据进行训练,并优化行动策略;另一方面自主地与环境互动,观测所需状态并获取反馈[3]。传统的强化学习只能解决序列决策问题,无法适用电力系统的复杂性和不确定性。深度神经网络与强化学习结合突破了这一限制,为电力系统控制与决策问题提供了新的方案。
1 强化学习原理
1.1 强化学习
强化学习是一种无模型并且和环境反复交互的学习方法,主要是通过智能体在对应的环境中不断地试错来寻找最优策略,其过程可以用马尔科夫决策过程表示[4]。其中最经典的强化学习算法是基于值函数的Q算法,智能体评估执行动作之后所得奖励的大小指导自己的更新方向,经过自我不断优化逐渐逼近最优值。强化学习过程如图1。

图1 强化学习原理图
首先智能体从环境中识别自己所处的当前状态St,之后选择动作at,环境反馈奖励rt+1,并进入下一个状态S’。智能体根据获得奖惩回报的大小来更新策略。强化学习最终目标是找到最优策略p*,使智能体在任意过程都可以获得最大的长期累积回报。
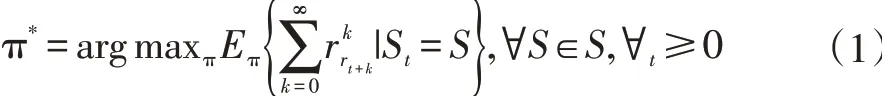
其中γ是折扣因子,决定了时间回报尺度,π是策略,S是状态空间。
在大多数电力系统控制问题中,状态空间是无限的。通常采用状态空间离散化技术将状态空间划分为有限数量区域[5]。因此可以将电力系统控制序列问题定义成马尔科夫决策过程。从而在离散的空间中搜索最优策略,得到最大值函数Q。Q函数的公式为:

1.2 深度强化学习
深度强化学习(Deep Reinforcement Learning,DRL)的兴起和发展与深度学习研究的深入和突破紧密相关,尤其是深度神经网络(Deep Neural Networks,DNNs)。DNNs的引入使得RL能够扩展到具有高维状态和行为空间的决策问题。图2展示了DRL的一般框架。

图2 DRL一般框架
DRL算法根据不同的特征方式有基于价值函数、基于控制策略和基于模型等多种分类方法[6]。最具有代表性的基于价值函数的DRL算法是DeepMind公司提出深度Q网络算法(Deep Q-Network,DQN)[7]。以此为基础,研究人员对DQN做了不同的改进:解决过估计问题的Double DQN、高效学习的Prioritized Replay DQN和将环境价值和动作价值解耦的Dueling DQN。最流行的基于控制策略的DRL是深度确定性策略算法(Deep Deterministic Policy Gradient,DDPG),该算法借鉴了DQN和AC的优点,能够高效地解决具有连续动作空间的任务。
2 电力系统智能体结构框架
电力系统控制问题可以描述成一个马尔科夫决策过程,针对不同的任务观测所需状态并设置特定的动作空间,用获得的数据集进行训练优化,从而达到所期望的运行效果。
文献[8]提出一种未来可能应用于实际场景的电力系统智能体决策结构框图。它定义了学习和决策两个模块。学习模块是典型的RL,而决策模块是贪婪智能体用学习模块中所获得知识进行控制。这样,智能体同时利用了仿真数据和实际数据,又避免了与系统直接交互,并且贪婪智能体还可以实时更新学习模块获得的策略,以确保系统的稳定运行。其控制框架如图3。

图3 电力系统智能体决策框图
3 系统正常运行状态控制
电力系统在不同运行状态下面临着许多控制问题。DyLiacco等人提出了一种被广泛接受的电力系统运行状态分类方法[9]。他们定义的五种运行状态如图4所示。

图4 电力系统运行状态图
图中E是等式约束,代表系统发电负荷需求平衡;I是不等式约束,代表系统物理设备的限制(通常根据系统组件可以承受而不会造成任何损坏的电流和电压幅度、有功、无功和视在功率来定义),符号“~”是违反。本文将根据此框架来综述DRL应用于电力系统控制与决策方面的概况。
3.1 系统正常运行状态控制
在正常运行状态下,电力系统各功率需求达到平衡,系统设备均在额定范围内工作。此时,除了维持系统正常运行,还要调节系统各设备出力,在保证发电质量的同时,让电力系统有一定的扰动承受能力,从而实现电力系统的安全、经济运行。本节下面将从设备装置、子系统、微电网三方面介绍基于DRL的控制决策。
(1)设备装置控制
在继电器保护控制方面,文献[10]将继电器保护控制公式化为多智能体RL问题,提出了一种新颖的多智能体嵌套RL方案,通过设置继电器控制逻辑来区分发电量大、运行条件差的配电系统和故障运行状况。该策略在故障率、对运行条件变化的鲁棒性和响应速度方面远远优于传统的基于阈值的继电保护策略。
为了使可再生能源的高效率发电,文献[11]提出一种基于在线RL的变速风能转换系统(Wind Energy Conversion Systems,WECS)智能最大功率点跟踪(Maxi⁃mum Power Point Tracking,MPPT)的方法。该策略不需了解风力涡轮机参数和风速信息,通过学习MPP获得最佳转子转速-输出功率曲线,然后应用于WECS。文献[12]针对永磁同步发电机的变速风能转换系统(WECS),提出将人工神经网络ANN与RL结合起来学习转子速度和永磁同步电机输出的最佳功率关系。此方法不仅易于实现,而且可以再次激活以适应系统的变化。文献[13]提出用可变泄漏最小均方算法来生成光伏逆变器基准,将RL算法用于MPPT和滑动模式方法来生成开关信号。MPPT采用Q学习算法设计,用于在不同太阳光照条件下的太阳能电池板最大功率跟踪。文献[14]在OpenAI Gym平台上对DDPG、IGDDPG和TD3三种RL控制策略在不同温度和太阳辐照度条件下进行性能测试,仿真结果表明DRL方案能够实时监测光照和温度条件变化,快速调整自身策略以保证发电功率最大。文献[15]是在局部阴影条件下基于DRL检测MPP。同等条件下,相比于传统跟踪方法,DQN方法和DDPG方法有更快速的追踪效果。但是,该方案的局限性在于所提出的方法不能始终检测到全局MPP,将来还需进一步提高基于DRL的方法的跟踪能力。
(2)子系统控制
针对非马尔科夫环境下自动发电控制(Automatic Generation Control,AGC)火电厂的长时间延迟控制回路问题,文献[16]提出一种多步Q(l)的随机最优松弛AGC方案。该AGC策略可通过在线调整松弛因子来优化CPS合规性和降低控制成本。文献[17]提出一种终身学习AGC方案,该方案将风电场、光伏电站、电动汽车集成为用于AGC的广域虚拟发电厂,从而加快系统响应速度,并减少了需求功率不匹配时的成本。而且还引入了模仿学习提高智能体学习效率,实现在线优化。文献[18]提出了一种基于DRL的AGC参数拟合的数据驱动方法,通过建立ACG驱动电网模型,用DQN参数拟合来评估不同风力穿透率和斜率下的AGC性能。文献[19]为应对可再生能源的不确定性,提出了一种基于DRL的负荷频率控制(Load-Frequency Control,LFC)。该方案通过DRL和连续动作搜索来离线优化LFC策略,并采用在线控制,其中特征提取采用层叠式去噪编码器。
确保电网电压始终保持在额定范围内是电网安全运行的必要条件。文献[20]提出一种基于DRL自主电压控制策略,智能体根据监控与数据采集或相量测量单元实时测量检测到的当前系统状况,对电网进行及时有效控制。在随机条件下进行测试,DQN和DDPG智能体仅使用一个控制决策就可以分别达到预期目标的91.25%和99.92%。文献[21]提出双时间尺度DRL控制电网电压方法,其中慢时间尺度从使用DRL的数据中学习最优电容器设置,快时间尺度利用精确或近似的网格模型,再根据慢时间尺度的学习部署找到逆变器的最佳设置点,从而实现快速调压控制。
(3)微电网控制
分布式能源的飞速发展对控制方案有了更高的要求。文献[22]提出采用RL对包含光伏系统和柴油发电机的混合储能系统(HESS)进行在线最优控制,以改善HESS的瞬态性能。该方案使用了两种神经网络:其一进行非线性动力学的学习,另一种通过在线学习来控制系统的最佳输入。并且通过评估确定了此方法的有效性。文献[23]提出一种微电网系统并网模式下的自适应智能功率控制方法,该控制系统包含神经模糊控制器和模糊智能体控制器。模糊评论智能体采用基于神经动力学编程的RL算法。通过模糊智能体产生的评估或增强信号和误差的反向传播,在线调整神经模糊控制器的输出层权重。与传统的PI控制相比,该控制器瞬态响应时间显著减少,功率振荡得以消除,并且实现了快速收敛。
3.2 系统恢复控制
电力系统在运行过程中,遇到严重的扰动,可能会使某些设备超出正常运行范围。这时需经过有效的调节措施,使系统恢复到正常状态。文献[24]基于描述级联故障的现实潮流模型,用Q算法对大规模电力系统级联故障寻找总线最优恢复序列,实验证明在恢复性能方面优于基准启发式恢复策略。文献[25]使用由下而上的多智能体分层控制,当系统发生故障时,下层智能体首先定位故障并使之隔离,上层智能体在下层智能体的协助下对系统重组和恢复。
文献[26]提出在电力系统网络受到攻击时,用DDPG算法来确定最佳重合闸时间。在模拟环境中,受到网络攻击的电力系统,通过数值积分方法获得电力系统的状态,通过暂态能量函数来评估恢复性能。在训练完成之后,通过更多的场景测试验证方案的适应性,并且与DQN的效果相比较,DDPG算法能更迅速且更具连续性的生成最优恢复操作,从而减轻级联中断的潜在风险。
3.3 系统紧急控制
当系统遇到严重故障时,会造成系统电压或者频率低于极限值,设备也可能进入超负荷运行状态。这时系统会触发报警信号进入紧急状态,紧急控制一般被认为是电力系统最后的安全保护,调度人员应采取灵活的方案,使系统恢复到警戒状态然后再到正常状态。文献[27]开发了RL电力系统测试平台并对自己所提出的DRL紧急控制方案进行评估。在DQN模型训练好之后,在不同的场景对发动机动态制动和低压减载进行测试,仿真实验证明DRL方案在紧急状态下对系统的调节比MPC和Q算法有更好的自适应性和耐用性。文献[28]使用电机无功、电机角度等多维属性数据对DRL进行训练,此方案让负责选择动作和计算值函数的双重Q网络与获得运行环境奖励值和动作奖励值的竞争Q网络相结合,通过比较两种网络的Q值大小来选择切机策略。
3.4 系统预防控制
预防控制是将实时测量系统的运行值与额定值进行比较,利用所得信息对系统进行安全监视。当信息表明系统不够安全,则提前采取切换负荷、调整安全装置等措施,保证系统的稳定运行。文献[29]提出通过RL来防止智能电网出现连锁故障。智能体经过系统训练之后,可以通过实时调节发动机的输出功率来缓解线路阻塞,防止在N-1和N-1-1紧急情况下连续发生线路中断和停电。在IEEE 118总线系统上测试表明,此方法能在不切断负载的情况下,持续保证独立电网或者复杂系统的平稳运行。此外,该方法还可以使系统平稳地进入无过载的新状态,且不会因突然变化(例如,负载减少的情况)对系统施加压力。
文献[30]为了预防电力系统大规模连续扰动,提出了深林深度强化学习算法(Deep Forest Reinforcement Learning,DFRL),DFRL Q值和动作集被分割用来降低数据维度,深层森林被用来预测下一个系统状态,多个辅助RL通过学习系统的特性从而对大型互联电力系统AGC单元发送指令,与传统的方法相比,DFRL性能最优。
综上可知,DRL大多数控制方案都是针对系统的正常运行状态下决策问题,其他方面的涉及相对较少。随着DRL多智能分步控制、嵌入特定专家知识等领域的发展,DRL将逐步给出电力系统各种控制问题的最优解。
4 结语
到目前为止,DRL控制决策已经应用于电力系统的各个场景,几乎覆盖电力系统的每一个技术方向。据不完全统计,相关领域已经有数百篇文章发表,但由于相关数据获取难度高、缺乏系统方法等原因,落地应用成果较少,还有待于各行业人员研究开发,最终实现DRL在电力系统的实际应用。
数字化的兴起,促进了可用数据的增加,推动整个电力系统进入“智能电网时代”;电动汽车、分布式发电、新型负载、电力电子设备的大量接入增加了网络物理系统的复杂性。DRL对决策问题普遍的适用性有望对电力系统来实现最优控制。未来对电力系统安全DRL、微电网分层多任务DRL控制、大规模区域输配电DRL控制、智能楼宇、嵌入领域特定知识等方面的研究,对推进电力系统智能自主自动化控制具有重要意义。
