基于深度学习的经典目标检测方法的研究
2021-03-07宋昆伟宫义山
宋昆伟 宫义山
(沈阳工业大学 辽宁省沈阳市 110870)
1 引言
随着研究的深入,近来几年深度学习的目标检测算法发展迅速,出现了许多非常优秀的算法[1]。通过实现与研究不同的检测算法,分析不同算法之间的差异与共同点,研究检测算法的不足之处,从而得出算法可以提升检测性能的可能改进的地方,更加深刻的了解深度学习各种算法的原理以及深度学习的本质[2]。
目前目标检测算法主要分为一步法(one-stage)[3]与二步法(two-stage)[4],其中二步法是需要首先产生候选目标框,再进行物体的分类,主要代表算法为FasterR-CNN[5]。而一步法是直接在卷积网络中进行物体的识别与位置标记,主要代表算法为YOLO[6]、SSD[7]。
2 Faster R-CNN目标检测模型
为了更好地进行检测,本论文对该算法的网络骨架以及ROI池化层进行了些许修改[8]。
如图1所示,Faster R-CNN主要由网络骨架层、RPN层、ROI池化以及分类和回归层四个部分组成
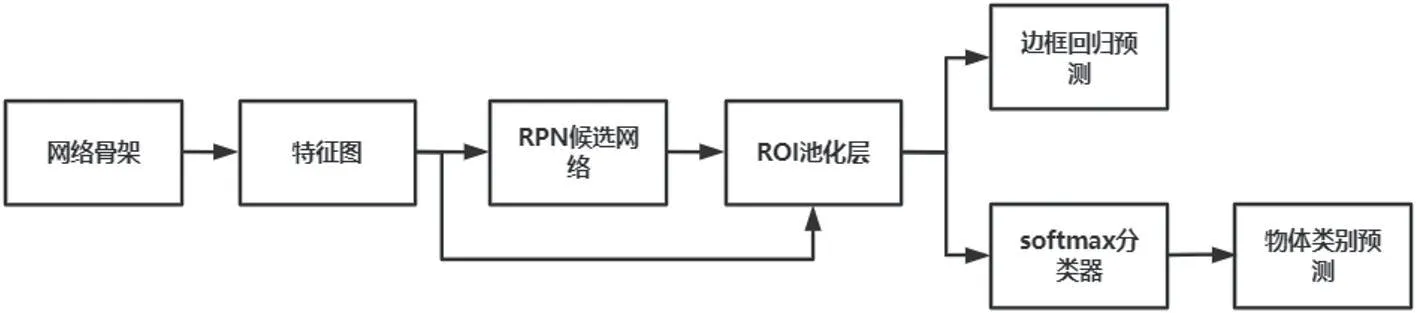
图1:FasterR-CNN的网络结构图
2.1 网络骨架BackBone—Resnet[9]
网络骨架的选择对于算法的性能有着深刻的影响,随着网络骨架的发展,原本的VGG网络模型性能方面已经有明显的落后了,所以本文选择了Resnet网络作为网络骨架。Resnet的主要特点就是提出了残差网络作为网络的基本模块。所以需要构造该网络,主要解决的是不同残差网络模块的构造[10]。
2.2 ROI池化层
RoIPooling的作用是将前面计算得出的512个不同尺度的Boundingbox归一化至相同的大小,使其可以直接进入后续的卷积层继续处理。
与ROI Pooling相比,本文采用的ROI Align可以解决ROIPooling有时会遇到特征图无法被整除的问题,因此具有明显的优势。其原因在于ROI Align会使用双线性内插的方法在不规则大小的特征图当中寻找极值,提高了算法整体效率。
3 YOLOv3目标检测模型
3.1 网络骨架DarkNet-53
为了进一步提升YOLO的检测速度,作者设计了DarkNet-53网络骨架,其结构如图2所示。其中DBL表示卷积、批量归一化(Batch Normalization,BN)以及ReLU三个层的组合,DBL是DarkNet网络的基本部件。Res代表了残差结构模块。Concat是指上采样后的特征拼接操作。
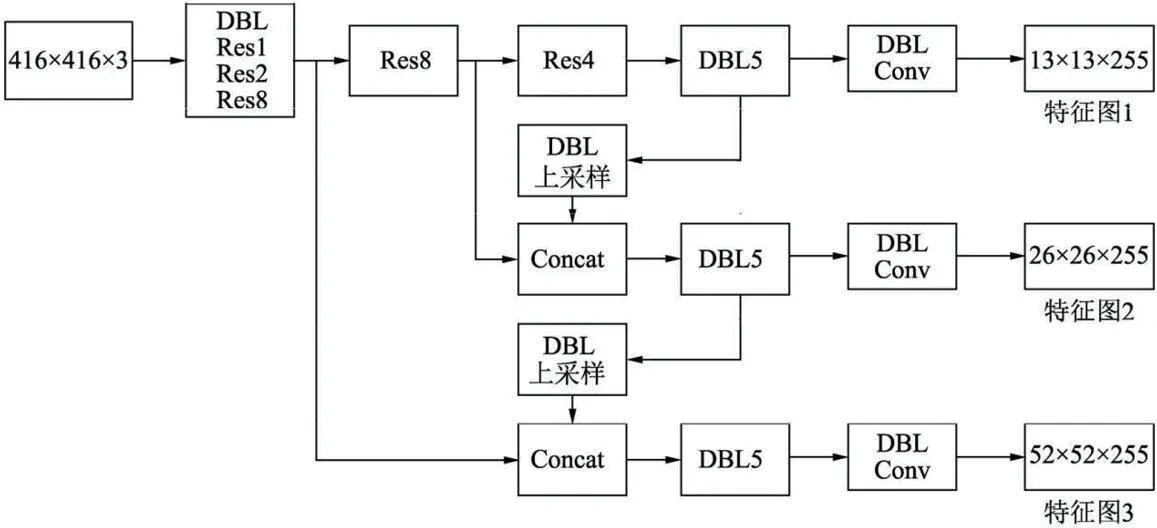
图2:DarkNet-53网络的结构图
该网络骨架由YOLOv2的DarkNet-19与Resnet组合修改而来,它大量采用了Resnet中的残差连接,加深了网络结构,并缓解了梯度消失的问题。而且该网络放弃了池化层,而是使用步长为2的卷积核来进行对特征图的尺寸缩小,从而保留更多的特征信息。
3.2 多尺度特征识别
YOLOv3输出的特征图分为3个尺度,分别为13*13、26*26、52*52,对于每一个尺度的特征图,对特征图中的每一个点都采用了3个不同形状的预选框(Anchor),用于检测不同尺度的物体。相比YOLOv2,YOLOv3的预测框有三种尺度,而且预测框数量增加了10多倍,所以在检测的准确率以及小物体检测性能上较YOLOv2有了较大的提升。
3.3 Loss函数
YOLOv3的Loss函数由三个部分组成:预测边框bbox带来的误差lbox;置信度obj带来的误差lobj;类别class带来的误差lcls。如式(1)所示:

4 实验
4.1 实验介绍
由于Yolov3与Faster R-CNN都分别是一部法与二步法中的经典算法,所以为了得出两种算法的在检测实际物体时的具体表现与它们性能上的差异,本文使用不同的数据集以及不同的网络架构对两种算法进行对照试验。本次实验一共比对了三个数据集:voc2007数据集、COCO数据集以及自制的T-MASK口罩数据集该数据集收集了1874张戴口罩或不戴口罩的人脸面部图像,按照VOC数据集格式制作,分为mask、face、wrong_mask三类,用以检测被识别者是否正确佩戴口罩。
4.2 实验过程与结果
对于VOC2007数据集,Faster R-CNN 与YOLOv3的学习率都取0.001,批次为2,Loss函数优化器采用SGD。其训练结果如表1所示。

表1:VOC2007数据集下YOLOv3与FasterR-CNN的性能表现对比
对于COCO数据集,FasterR-CNN与YOLOv3的学习率取0.01,批次取2,Loss函数优化器采用SGD。其训练结果如表2所示。

表2:COCO数据集下YOLOv3与FasterR-CNN的性能表现对比
对于T_MASK口罩数据集,FasterR-CNN与YOLOv3的学习率取0.01,批次取1,Loss函数优化器采用SGD。其训练结果如表3所示。

表3:T-MASK数据集下YOLOv3与FasterR-CNN的性能表现对比
4.3 实验改进
从表3可以看出,两种算法对wrong_mask类样本的检测并不理想,YOLOv3算法对是否佩戴口罩检测效果不理想。在对测试结果进行分析后,发现由以下几个原因导致:
(1)worng_mask类别的数据训练难度大,且样本之间无明显共同特征,导致预测边框与类别都难以拟合。
(2)YOLOv3为通用检测算法,先验框的尺度不一,存在一定的改进空间
(3)T-MSAK口罩数据集中的样本多为中小目标,中小目标为主要检测对象,因此应加强对中小目标的训练。
为了更好地进行数据检测,将YOLOv3中的先验框从每个检测尺度3个增加到每个尺度4个,再使用K-means聚类算法对先验框进行聚类操作,最终得到12个适合口罩识别的先验框:(12×12),(24×23),……,(373×366)。
由图3可知,数据集中小物体与中物体检测目标偏多,故在损失函数中对比例系数box_loss_casle进行放大,将其放大为原来的1.2倍,如式(2)所示:

图3:复杂场景口罩训练效果对比左:YOLOv3;右:FasterR-CNN

由于比例系数的变化使得损失函数中的lbox发生了变化,为了平衡各种损失函数所占据的权重,在计算最终损失函数Loss时,对lobj与lcls进行加权处理,如式(3)所示:
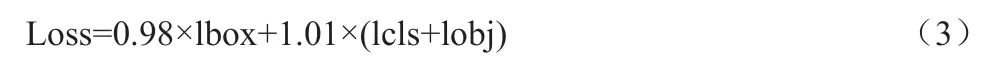
将类别从3个类别改为mask和face2个类别(除去wrong_mask类),同时对图像进行翻转、缩放、图像滤波等方式进行增强后。其训练结果如表4所示。

表4:调整后T-MASK数据集下YOLOv3与FasterR-CNN的性能表现对比a
4.4 实验结果分析
在VOC 2007数据集上,YOLOv3的mAP为74.0,略优于FasterR-CNN的72.3。对于难度更大的COCO数据集,,FasterRCNN的检测精度要高于YOLOv3,但在mAP75检测上,FasterRCNN的得分要高一些。
对于T-MASK口罩数据集,在对模型进行改进并将wrong_mask类样本去除后,YOLOv3与Faster R-CNN 的mAP较之前分别提升了14.4%与10.9%。
在训练方面,YOLOv3模型收敛较快,对于预测框的拟合较好,但检测置信度较低。FasterR-CNN模型检测置信度较高,但模型收敛较慢,且迭代过多产生过拟合。在检测方面,FasterR-CNN的检测精度与置信度都要高于YOLOv3,同时很少出现漏检情况。复杂场景口罩训练效果对比如图3所示。
5 结语
YOLOv3算法具有较优秀的实时性与检测精度,在较为简单的检测场景能有优异的表现,对小物体有较好的检查性能,适合运用于对实时性要求较高但场景较为简单的场景中。
FasterR-CNN算法在简单场景中的精确度与YOLOv3相当,但在相当复杂的环境中,较YOLOv3有更好的表现以及更高的可靠程度。但实时性方面,其检测速度远低于YOLOv3,但相较上一代算法Fast R-CNN已有了大幅提升。该算法的出现意味着:在保证精度的同时提升检测速度这一思想是可行的。同时,FasterR-CNN还可以通过各种改进来进一步提升自己的检测精度。所以FasterRCNN较为适用于对实时性要求较低,但精度要求较高的场景,同时也适合用来学习与研究。
目前深度学习虽然有较好的表现,但对于目标检测,其训练仍需要进行监督学习,越复杂的模型就越难以训练,不具备人类如此强大的学习能力。在某一领域训练得出的模型,在不同但相似领域下便无法使用,鲁棒性太低,没有对物体检测训练的泛化能力。这些问题都还待我们以后进行进一步的研究。
