基于改进Yolov4-Tiny网络的安全帽监测系统
2021-03-07丛玉华何啸朱惠娟朱娴
丛玉华 何啸 朱惠娟 朱娴
(南京理工大学紫金学院 江苏省南京市 210023)
1 引言
随着经济建设的快速发展,我国的基础设施建设及工业化进程不断加快,在这一背景下,生产作业中出现的事故逐渐增多。绝大多数情况下未佩戴或不正确佩戴安全帽是极常见的违规行为。为保障施工人员的自身安全,避免一些不必要的意外事故,一些必要的监测措施是不可或缺的。一般情况下,施工现场普遍范围较广且情况复杂,人员走动也十分不规律,因此仅靠有限的巡查人员很难去实现全方面的及时性的安全监测。目前,仅有少数施工场所或生产车间配备智能化视频监测系统,但识别准确率低、视频传输实时性差。为此,通过人工智能方法设计安全帽监测系统,通过视频监控信息识别出未佩戴安全帽者,并进行警示。
2 系统功能设计
安全帽监测系统基本功能为:通过生产现场视频采集设备将视频流传输给图像处理计算机,图像处理部分负责对视频流进行图像分析进而实现人头部的安全帽识别,如果识别出有人未佩戴安全帽则通过输出设备进行语音及文本形式警示。具体功能如图1所示。
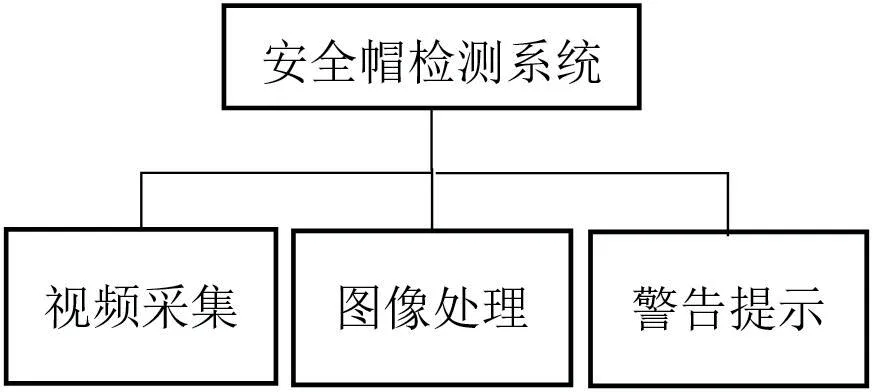
图1:安全帽监测系统功能框图
2.1 视频采集
视频采集是系统的基础功能,该功能能够从外部环境采集视频,向图像处理模块输入视频流。
2.2 图像处理
图像处理分为图像识别和图像标注两部分。图像识别是本系统的核心功能,该功能的检测效果将会直接决定系统的性能,这一功能的实现是整个系统完整性的关键。图像识别功能能够实现对佩戴安全帽或不佩戴安全帽人员的检测。图像标注是对图像识别功能的补充。在完成图像识别后,进行图像标注有助于监控人员对未佩戴安全帽人员的监管。
2.3 警告提示
警告提示是系统的辅助功能,该功能能够对出现在监控画面中的未佩戴安全帽人员进行警告,提示该人员佩戴安全帽。
3 安全帽识别算法网络
在人工智能算法中,Yolov4-Tiny精简了特征提取网络,使模型的复杂度和训练参数大大减少[1]。生产过程中需使用轻量级网络来提高实时性,因此Yolov4-Tiny更适合安全帽识别。目前,用于安全帽识别检测的人工智能方法有:李天宇等的高精度的卷积神经网络安全帽检测方法[2],蒋润熙等的以Yolov5为基础的面向轻量化网络的安全帽检测算法[3],孙国栋等融合自注意力机制改进Faster R-CNN的安全帽佩戴检测方法[4]。因此下面将结合安全帽识别场景将基于轻量化网络Yolov4-Tiny网络并进行改进实现对安全帽的高精度识别。
3.1 Yolov4-Tiny网络
Yolov4-Tiny目标检测网络是基于CNN构建的网络,主要由三部分组成:Backbone部分为主干特征网络CSPDarknet53-Tiny,Neck部分为加强特征提取网络FPN,Predict部分输出两个有效特征层Head[5]。Yolov4-Tiny网络结构如图2所示。
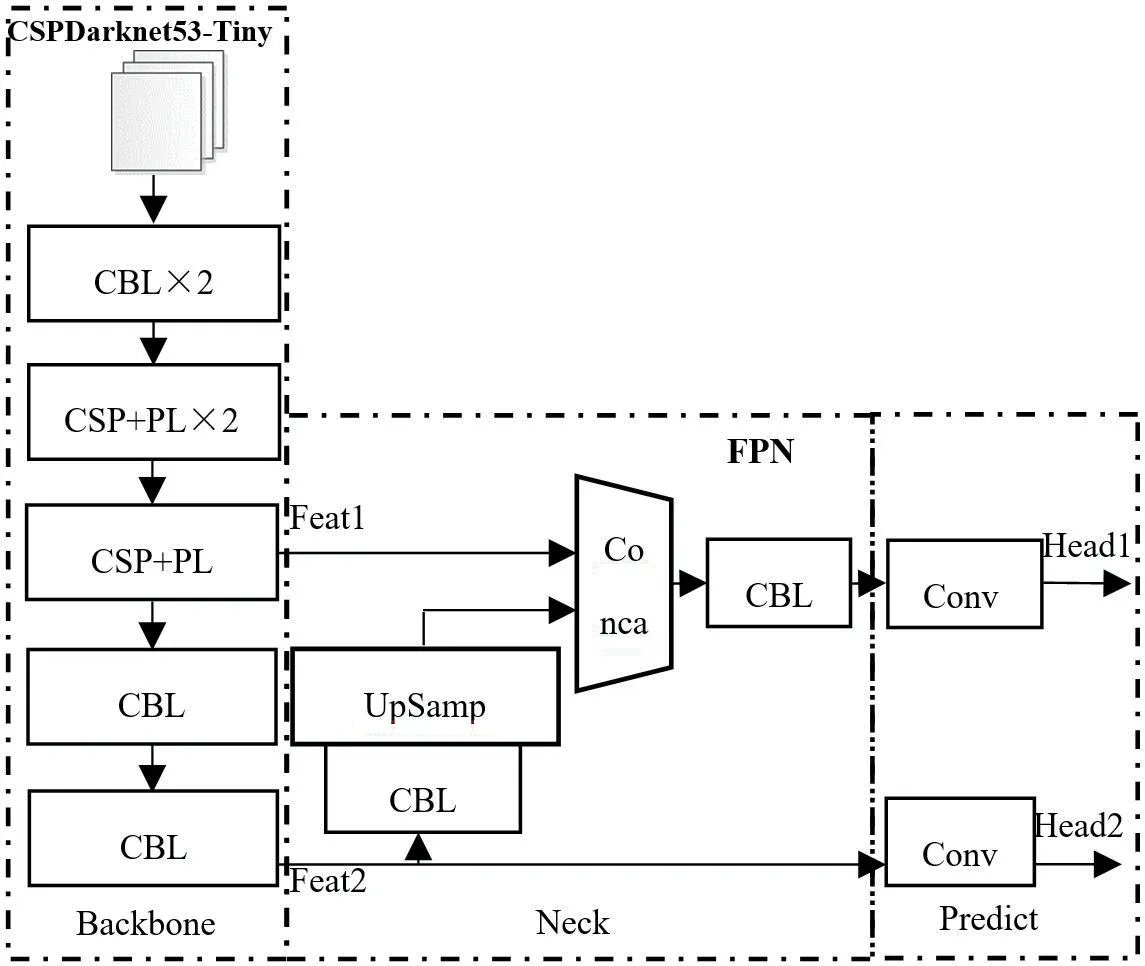
图2:Yolov4-Tiny网络结构
3.1.1 主干网络CSPDarknet53-Tiny
Yolov4-Tiny的主干网络有两个基本部分构成,分别是CBL层(Conv+BN+LeakyReLU)和CSP(CrossStage Partial)层。CBL层包括卷积运算Conv、批标准化处理BN(Batch Normalization)、Leaky ReLU函数激活。CBL层在每一次卷积之前进行L2正则化,完成卷积后进行标准化与Leaky ReLU激活。L2正则化目的是控制模型复杂度、减小过拟合。卷积层主要被用来提取目标特征。批标准化本质就是利用优化方差大小和均值位置,使得新的分布更切合数据的真实分布,保证模型的非线性表达能力。激活函数Leaky ReLU,即带泄露线性整流函数,是在人工神经网络的神经元上运行的函数,该函数输出对负值输入有很小的坡度。CSP层为残差模块,是在CBL结构基础上引入残差结构,如图3所示,Rt1和Rt2为两个残差边。
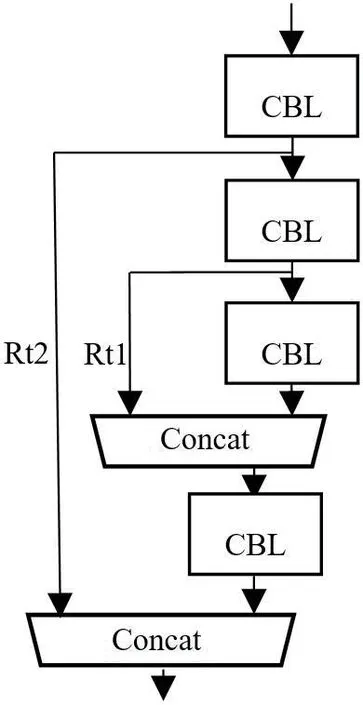
图3:CSP结构
3.1.2 加强特征提取网络FPN
FPN(Feature Pyramid Networks)特征金字塔网络,是一种利用常规CNN模型来高效提取图片中各维度特征的方法。FPN通过利用常规CNN模型内部从底向上各个层对同一大小图片不同维度的特征表达结构,将缩小或扩大后的不同维度图片作为输入生成反映不同维度信息的特征组合,能有效地表达出图片之上的各种维度特征,是一种加强主干网络CNN特征表达的方法[6]。在Yolov4-Tiny中,FPN预测输出采用两层结构如图4所示。
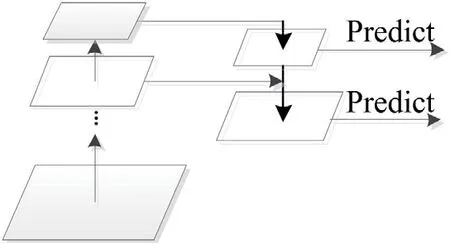
图4:FPN网络结构
3.1.3 网络输出
Yolov4-Tiny的特征输出层融合了网络Head输出,Loss计算和预测结果解析。特征输出是在特征利用部分,YOLOv4-Tiny提取多特征层进行目标检测。Loss损失为首先将预测框跟真实框做IOU计算,忽略IOU小于阈值的部分预测框,将保留的部分首先做CIOU计算获得坐标损失。预测结果分析是将每个网格点加上它对应的横坐标和纵坐标,加后的结果是预测框的中心,再利用先验框的高、宽计算出预测框的长和宽得到预测框位置。最后根据得到的预测框位置进行得分排序与非极大抑制筛选获得最后预测结果。
3.2 引入注意力机制的Yolov4-Tiny网络
3.2.1 注意力机制
基于卷积块的注意力机制 CBAM(Convolutional Block Attention Module)[7]是一种用于前馈卷积神经网络的轻量级通用模块,可以无缝集成到任何CNN架构中,开销可以忽略不计,并且可以和基础CNN一起进行端到端训练。CBAM有两个顺序的子模块:通道注意力模块CAM(Channel Attention Module)和空间注意力模块SAM(Spatial Attention Module),如图5所示,Input Feature经过了通道注意力CAM的特征图与空间注意力SAM相乘,最终得到经过调整的特征图Refined Feature。
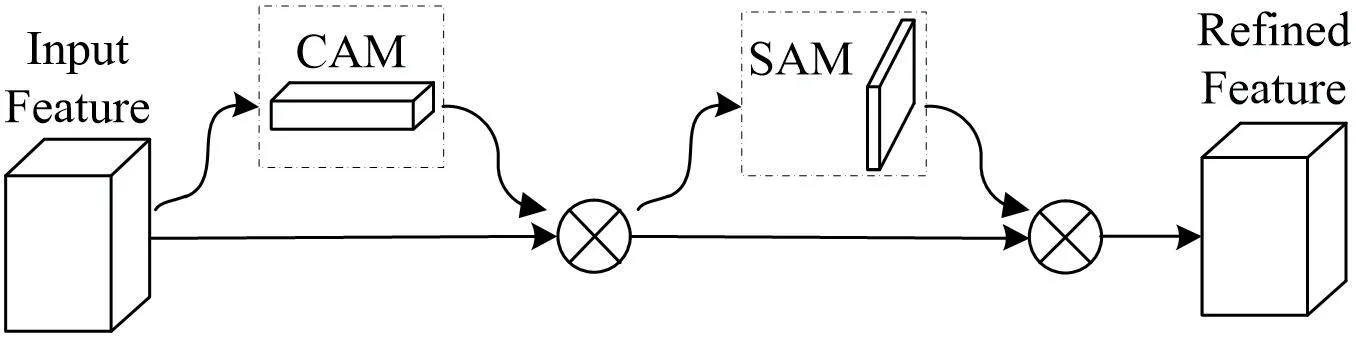
图5:CBAM模块结构
CAM主要是关注对最终预测起决定性作用的通道特征。对Input Feature先在每一个通道的特征图上进行全局平均池化(AvgPool)和全局最大池化(MaxPool),得到两个通道特征。然后将这两个通道特征送入一个多层感知机(MLP)中,这个多层感知机由两个共享权重的全连接层组成,通过这个全连接层得到相应的输出(Channel Attention Feature)。CAM具体结构如图6所示。

图6:CAM模块结构
SAM主要是关注对最终预测起到决定性作用的位置信息。在通道维度Channel Attention Feature上进行最大池化和平均池化,得到两个空间特征。然后将这两个特征在通道维度拼接,经过一个卷积层(Conv)后得到空间注意力(Spatial Attention Feature)。SAM具体结构如图7所示。
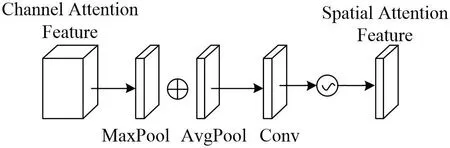
图7:SAM模块结构
3.2.2 引入注意力机制的改进方法
CBAM模块目的是提高特征提取精度,为保证全面性,此处将其应用于主干网络每次特征输出之前。因此需要在每个CSP残差结构上嵌入CBAM模块,具体如图8所示。
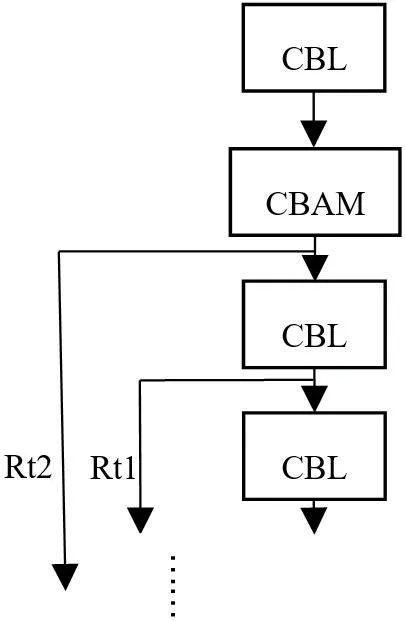
图8:引入CBAM的CSP结构
4 算法性能测试及系统功能实现
4.1 实验数据集与数据预处理
4.1.1 实验数据集
实验数据集采用VOC2028安全帽数据集。数据集图片共7582张,其中训练集6823张,测试集760张。
4.1.2 数据预处理
由于数据集中的图片大小不一,因此在训练前统一处理为416×416的大小。同时,进行网络训练时使用Mosaic数据增强方法来增加样本的多样性。每次读取四张图片,对每张图片进行尺寸缩小、随机水平翻转、随机色域变换(色调、饱和度、明度变换),再拼接成一张416×416大小的图片上,作为输入的训练数据,并修改相对应的XML标签数据。
4.2 实验参数
4.2.1 性能参数
Precision和Recall:Precision为精确度是分类器认为是正样本且分类正确的部分占所有分类器认为是正样本的部分的比例,也被称为查准率。Recall为召回率是分类器认为是正样本且分类正确的部分占所有正样本的比例,也被成为查全率。
AP与mAP:AP(Average Precious)平均精度,以Recall值为横轴,Precision值为纵轴,就可以得到PR曲线,这条线下面的面积就是被测的类别的AP值。而mAP就是所有类的平均AP值。
FPS :FPS (Frame Per Second)即每秒可以处理的图片数量。用来评估目标检测速度。
4.2.2 软硬件参数
实验过程中软硬件参数如表1所示。另CUDA版本为10.1。

表1:环境参数
4.3 实验结果及分析
4.3.1 性能测试结果
下面对两种网络结构来进行性能测试:Yolov4-Tiny网络和加入注意力机制的Yolov4-Tiny+CBAM网络,测试结果如图9所示。
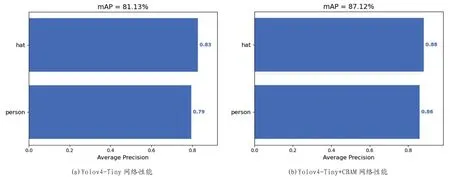
图9:网络性能测试结果
两种网络结构的模型大小、精度和速度数据对比如表2所示。
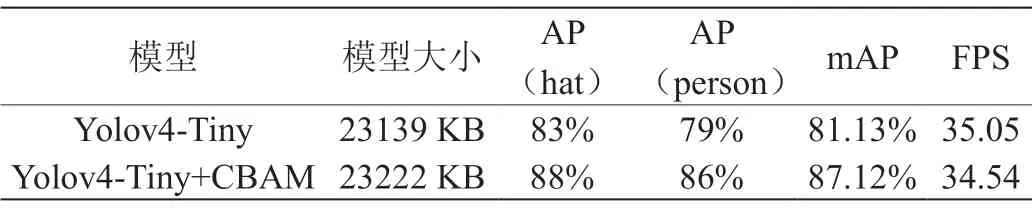
表2:网络性能数据对比表
由图9和表2可得,加入注意力机制CBAM的Yolov4-Tiny+CBAM网络模型大小接近Yolov4-Tiny,在保持速度基础上,精确度比Yolov4-Tiny提高了7.4%。
4.3.2 可视化测试结果
针对两种网络,在单目标和多目标,简单背景和复杂背景情况下进行测试,结果如图10、11所示。单目标识别时,后者标注框更准确;多目标时,检测识别率后者更高。可见Yolov4-Tiny+CBAM网络检测效果明显优于Yolov4-Tiny网络。

图10:Yolov4-Tiny识别效果

图11:Yolov4-Tiny+CBAM识别效果
4.4 系统功能实现
4.4.1 图像采集
图像采集功能是由视频采集输入模块完成的。系统中使用的监控设备是HP Wide Vision HD,使用USB串口总线标准进行输入和输出,能够对监控区域进行低延时、高画质地监控,其数据传输格式能够输入进图像处理模块并完成处理。使用设备如图12所示。

图12:摄像头设备
4.4.2 图像处理
图像识别与图像标注功能在图像处理平台进行了整合,系统能够实现对采集视频流的处理。为测试系统对各类环境的鲁棒性,对室内与室外不同的环境情况进行了针对性测试,测试表明系统在识别正确率方面是能够满足系统的设计要求的。室内外检测结果如图13中(a)和(b)所示。

图13:系统室内与室外环境检测结果
图13(a)中佩戴人员1,未佩戴人员3,准确率100%。图13(b)中佩戴人员2,未佩戴人员0,准确率100%。通过对两种不同环境的功能测试,表明本系统对环境变化的适性是较强的,可以达到系统功能要求。
4.4.3 警告提示
警告提示作为系统的辅助功能,在系统开始监测时,记录画面中人员佩戴安全帽情况。要求在检测到画面中存在有未佩戴安全帽人员时进行语音提示。系统监控界面如图14所示。
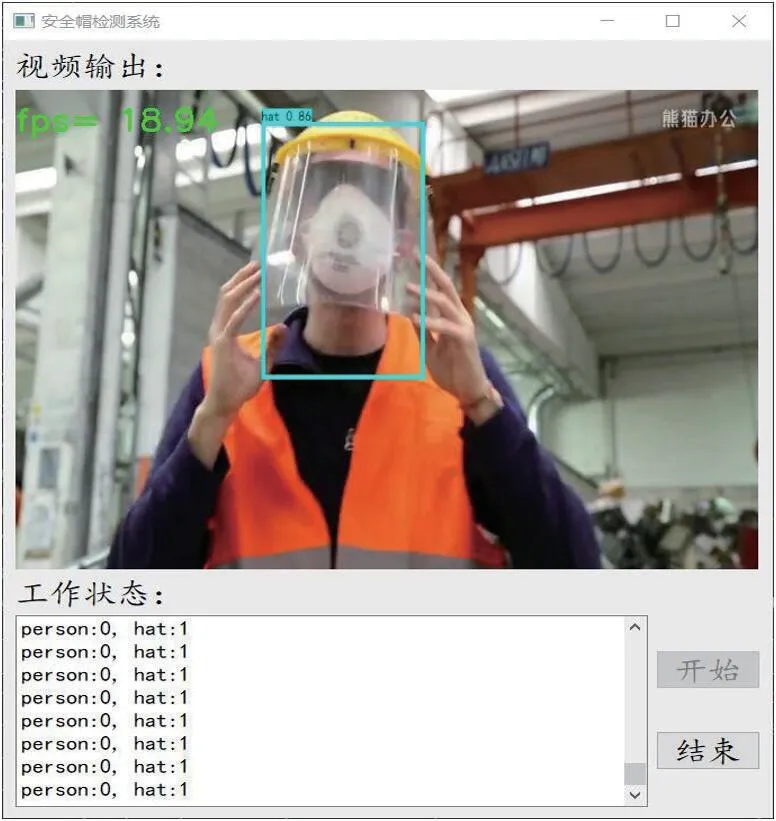
图14:系统监控界面
5 总结
本文设计了一套安全帽监测系统,实现功能包括视频采集、图像处理和警告提示。针对关键的图像处理模块基于轻量级Yolov4-tiny网络并引入注意力机制实现安全帽识别,注意力机制主要置于Yolov4-tiny的主干网络部分。算法性能的测试结果能够说明安全帽识别算法改进的有效性,系统功能测试结果表明系统实现的完整性和实用性。后续将优化神经网络结构,提出精度提升幅度更大的改进算法,并继续完善安全帽监测系统的各模块功能。
