基于MD5指纹的网页内容去重机制
2021-03-07丁桥宋晓骏余思莹
丁桥 宋晓骏 余思莹
(中国电信股份有限公司上海分公司信息网络部 上海市 200085)
1 引言
用户规模持续增长,下沉市场用户加快拓展。随着网络提速降费的推进和智能手机终端的推广,互联网内容大幅增加。而与此同时,某些不法分子也开始利用网络来传播色情、诈骗、赌博等不良信息,由此造成的信息安全问题。根据“谁主管谁负责,谁审批谁负责,谁经营谁负责,谁接入谁负责”原则,电信运营商在大力发展业务的同时,也感受到前所未有的来自信息安全方面的压力。信息内容安全主要针对网站网页进行爬虫采集,通过关键字过滤,结合语义智能分析、人工识别等方式,鉴别出有害的内容,进而采取网页删除、IP封堵等方式下线有害内容,维护互联网健康的环境。本文主要关注在网站网页爬虫采集阶段,如何采用网页内容去重技术,快速比对出已经处理入库的安全网页和需要后续处理的“新”网页,去除大量爬取来的重复网页,降低后续处理量,提高不良信息的监测和处理效率。
2 技术原理
2.1 分布式爬虫
本文针对采集的网页数量庞大(亿级),单个的爬虫无法完成,因此爬虫必须基于分布式架构。通过建立分布式爬虫,提高爬虫覆盖面,提升网页获取速度,同时提高爬取质量,为不良信息监测提供覆盖面广泛,时效性高,具有一定深度的数据。
为提高爬虫效率,保证数据获取的时效性。爬虫模块的构建是分布式多爬虫共享队列的主题爬虫。主要特点如下:
分布式爬虫:为了提高爬虫的并发及稳定性,将建设分布式爬虫抓取系统,主要包括以下功能,爬取策略的设计,增量爬取,请求去重,爬虫防屏蔽中间件,网页非200状态处理,爬虫下载异常处理和数据存储。
结构化采集技术:对非结构化的网页数据在采集的时候进行结构化的信息抽取和数据存储,以满足多维度的信息挖掘和统计需要。
定时监控:可根据需求进行定时监控,实际应用中拟实现小时级的采集更新。
反爬策略应对:目前不少网站都运用了反爬虫技术来阻止外来访客进行高频大量的数据爬取,这给数据爬取带来了不小的困难。针对各种可能存在的反爬策略,可通过cookie池,模拟点击,逆向JS等来预防应对。
2.2 网页去重
爬虫爬取采集到的大量网页中,会有很多重复数据,因此需要设计去重算法,针对海量千万级的数据进行高效的合并去重。如何快速全面发现这些重复信息.快速准确地去重这些内容上相同或相似的网页已经成为快速识别有害网页的关键技术之一。
根据网页内容的匹配程度、颗粒度特点分为:URL去重、内容去重、网页去重三个级别。
URL去重是针对同一来源的舆情数据进行去重,去除已经爬取过的URL,避免重复爬取影响爬虫效率,以及冗余数据产生。
内容去重是指有些热点舆情具有集中程度高的特点,热点新闻的重复率远高于其他内容,由于人们对这些信息的关注,致使互联网上各网站争相转载,尤其是新近发布的热点信息,时间集中程度高,其内容和结构高度一致,因此对舆情内容的去重依据标题及正文级别两个级别,对标题使用较为宽松的相似度计算方法,对输入的文本进行分词,去除没有意义的通用词和高频词,对标题相似的文档再进行内容相似度的计算。
网页去重是通过技术手段对已处理的网页进行标注,后续的网页的处理过程中通过对标注进行快速比对,就可以避免网页重复处理,从而提高有害网页的识别速度。目前常用技术手段是通过hash编码等文本向数字串映射方式以方便后续的特征存储以及特征比较.起到减少存储空间,加快比较速度的作用。每个网页都采用hash函数编码(比如MD5),这样只要编码相同就说明网页完全相同[1]。
本文主要描述网页去重的实现。网页去重的带来的好处有以下两点:
(1)能大幅提升爬虫爬取网页的效率,对于相同网页不需要重复判断其内容是否是属于有害信息。
(2)能够节省一部分存储空间,进而可以利用这部分空间来存放更多的有效网页内容,同时也提高了爬虫数据的质量[2][3]。
2.3 MD5指纹
MD5信息摘要算法是一种流行的散列算法标准,它是为任何文件,不管其大小格式,都提取出128位的摘要信息,形成数字“指纹”。这样的“指纹”可以用于密码管理、电子签名、垃圾邮件筛选等各种用途。MD5是128bit的散列码,其安全性还是能得到保障的。具有相同散列码的两个网页需要2的64次方数量级的操作,所以对于网页来说,通过采用MD5算法对网页进行计算,得到的MD5值作为网页的“独一无二”的标志是可行的。再通过对MD5值进行快速地比对和筛选,就等于对网页进行快速地比对和筛选,大幅提高网页的去重比对能力[4][5]。
2.4 Redis集群
Redis是目前流行的NoSQL数据库之一,包含多种数据结构、支持网络、基于内存、可选持久化的键值对存储数据库。应用场景包括高频读、低频写的缓存系统、消息队列系统、社交网络和实时系统。Redis 是目前公认的速度最快的基于内存的键值对数据库,可作为临时数据的缓存区,可以充分利用内存的高速读写能力大大提高网页比对速度。因本文需要的比对网页数量巨大,所以需要采用Redis集群来进行处理,
3 实施方法
Redis集群在识别过程中存储两部分MD5指纹数据:一是比对程序判定为正常图片的 MD5指纹,二是比对程序判定为正常文本的 MD5指纹。比对程序接收到爬虫上传的压缩包,解压后再进行Redis过滤,提取文本、图片的 MD5依次在上述的Redis数据库中查询。如果能查到一样的MD5值,按照队列的标识对文本、图片进行相应去重处理,并刷新库中数据的有效时间。完成 Redis过滤后再进行模型识别,对识别为非重复的文本、图片 MD5指纹再进行入库。
另外比对程序会单独开一个线程来对 Redis 中的MD5指纹数据有效性进行检测,目前缓存数据的时间是一个月,对距离当前检查时间超过一个月的数据记录进行删除。采用该措施主要是为了避免Redis存储的MD5指纹数据长期不清理,导致数据量过大,从而影响到新进的MD5指纹和数据库中存储的MD5指纹之间的比对效率。
3.1 具体流程
本流程已经经过实际的软件开发实现全部的功能,完成了网页内容去重,获得数据比对效率的提升,具体步骤如下:
(1)建立爬虫任务后爬虫模块对目标页面进行数据爬取,爬虫将记录爬取数据的压缩包下载保存。
(2)比对程序解压爬取的压缩包,并提取新增爬取的页面及图片。
(3)比对程序将提取的页面和图片与Redis库中记录的存量MD5指纹数据进行比对,判断新增页面和图片是否有历史记录。
(4)如与Redis库中的MD5指纹库比对重复,则该新增爬取内容有历史记录,无需再进行不良信息内容的识别,直接读取其历史研判结果。历史研判结果为不良信息的直接生成处置任务进行人工审核及处置,研判结果为正常内容则直接过滤丢弃。
(5)如与Redis库中的MD5指纹库比对没有重复,则所爬取的内容为新增爬取内容,提取记录其MD5指纹。对其进行不良信息内容识别,研判为不良信息的页面内容则生成处置流程进行人工审核,研判为正常页面内容则流程结束。
不论新增爬取内容的研判结果是否为不良内容,都应记录研判结果并与其MD5指纹关联,成为新的存量内容识别结果库,并增量更新进RedisMD5指纹库中。网页去重流程图如图1所示。
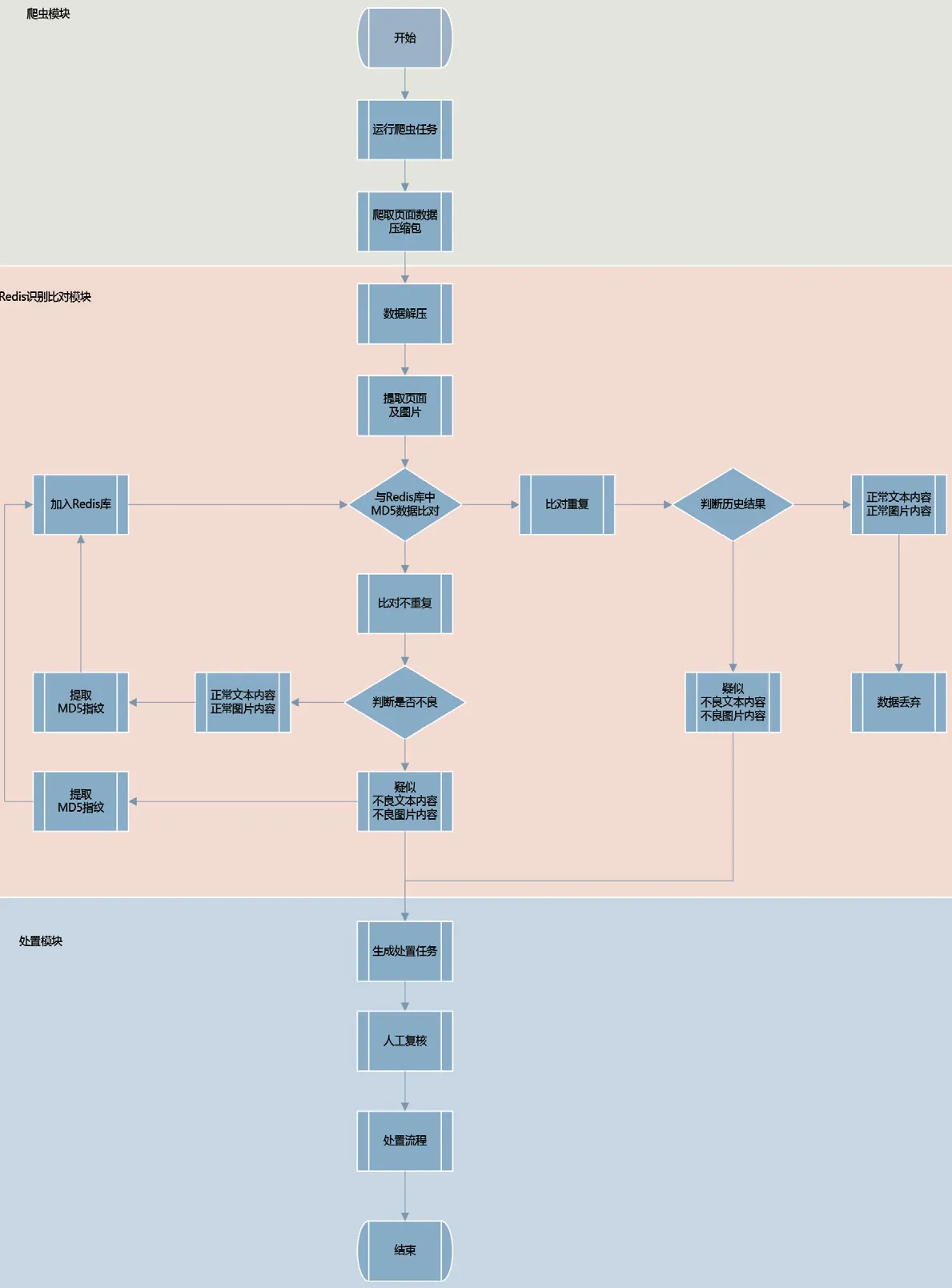
图1:网页去重流程图
4 使用效果
本文通过存量安全MD5指纹库库结合Redis集群多线程识别,可借助Redis集群实现海量网页的独立去重,避免单机内存不足的尴尬。同时增加了Redis集群识别缓存功能,当识别引擎对爬虫爬取的文件进行识别时,将识别为正常的页面生成一个MD5指纹并录入到Redis集群,当循环任务中重复爬取到同个页面时,识别引擎优先比对Redis集群中存有的MD5指纹。对MD5指纹未变更的页面直接判定为安全页面,不再进行后续特征识别,提升系统识别效率20倍以上。
