基于改进模糊K-means算法的大数据处理方法
2021-03-07王天皓
王天皓
(宜昌市大数据中心 湖北省宜昌市 443000)
随着互联网时代的飞速发展,我国逐渐进入信息化、数据化的时代,人们可以在海量的数据信息中精准地找到自己所需要的内容。近年来,大数据的兴起,使人们搜寻信息更加容易,大数据可以将人们的需求瞬间得到,进而提高搜索效率[1]。比如,在学习过程中,有一些词语不懂,打开搜索界面,就能看见想要搜索的词语,提高检索效率[2]。但是随着大数据的产生速度加快,大数据的处理方法逐渐跟不上大数据的产生脚步,出现了数据处理效果变差、数据处理时间滞后的现象。因此,本文设计了基于改进模糊K-means算法的大数据处理方法。首先采集大数据,得出大数据的处理现状;其次制定改建算法的相关流程,得出改进算法的相似度量;进而计算大数据处理方法的相似度,消除精准度误差。基于以上方法设计,旨在提高大数据处理效果,为互联网事业作出贡献。
1 大数据处理方法设计
改进模糊K-means算法是一种数据聚类处理算法,可以通过数据采集、计算等步骤得出大数据的相似度,从而消除MAE的误差。大数据处理步骤如图1所示。

图1:大数据处理流程
1.1 建立大数据采集模块
近年来,社交数据信息快速发展,各种业务都在使用大数据,随着大数据的兴起,各个领域的搜索范围、规模、速度都有非常显著地提升[3]。因此大数据的处理方法亟待改进,本文设计的大数据处理方法,以建立大数据采集模块为基础,涵盖了社会生活和生产的许多领域,包括支付信息、商业信息、交流记录等。与传统的处理方法不同,本文设计的大数据采集模块,处理数据这种信息资源时,需要经过采集、分析、提炼等操作,最终生成对人们有用的数据信息。此外,数据采集的过程是通过大数据,从海量信息资源中发现规律,并进行分析,将有价值的信息,透过人们的需求展现出来[4]。
传统大数据处理方法中,大数据采集模块是对采集到的数据进行分析、整合,继而得出相应数据信息,但是在处理过程缺乏明确的目标,进而导致大数据处理效果不佳[5]。本文摒弃以上缺点,从大量不完整、模糊和随机的数据信息中识别出有效信息,并根据这些信息作出决策。本文设计的数据采集过程包括:确定采集的目标、准备数据采集、采集数据、分析结果等四个步骤,以上步骤都是为了处理大数据而执行的。本文通过对采集到的数据进行分析,可以有效地减少资源浪费,大大提高大数据处理的质量和效率。
1.2 绘制改进模糊K-means算法流程图
大数据处理方法除了上文中建立的大数据采集模块以外,本文将设计改进模糊K_means算法的流程。本文在改进算法过程中,对原算法进行估计,得出处理大数据的连续输出效率。为了提高大数据处理效率,将原算法中结果数量不确定的因素抛弃,利用分类技术代表大数据的输出结果,使大数据处理结果更加清晰[6]。此外,在改进算法中,评价技术可以说是分类技术的前期工作。首先利用评价技术得到连续未知量的数值,然后利用分类技术对结果进行处理[7]。通过对分类技术或评价技术进行模拟,并应用于大数据的处理,在分类技术中,包括了预测功能,使其可以预测不同类型的信息资源。利用关联规则,将大数据采集中的各个相互关联的词语作出整合,有助于人们同时识别。K-means算法不适用于不连续的大数据,处理效果不佳,本文将改进此项缺陷,使其适用于任何大数据的处理场景。另外,K-means算法的缺点还包括计算过程依赖初始化设定,且对噪声点过于敏感,用于大数据处理用于出现干扰,因此,使用改进后的K-means算法进行大数据处理更加理想。
如图2所示,为改进模糊K-means算法流程图。
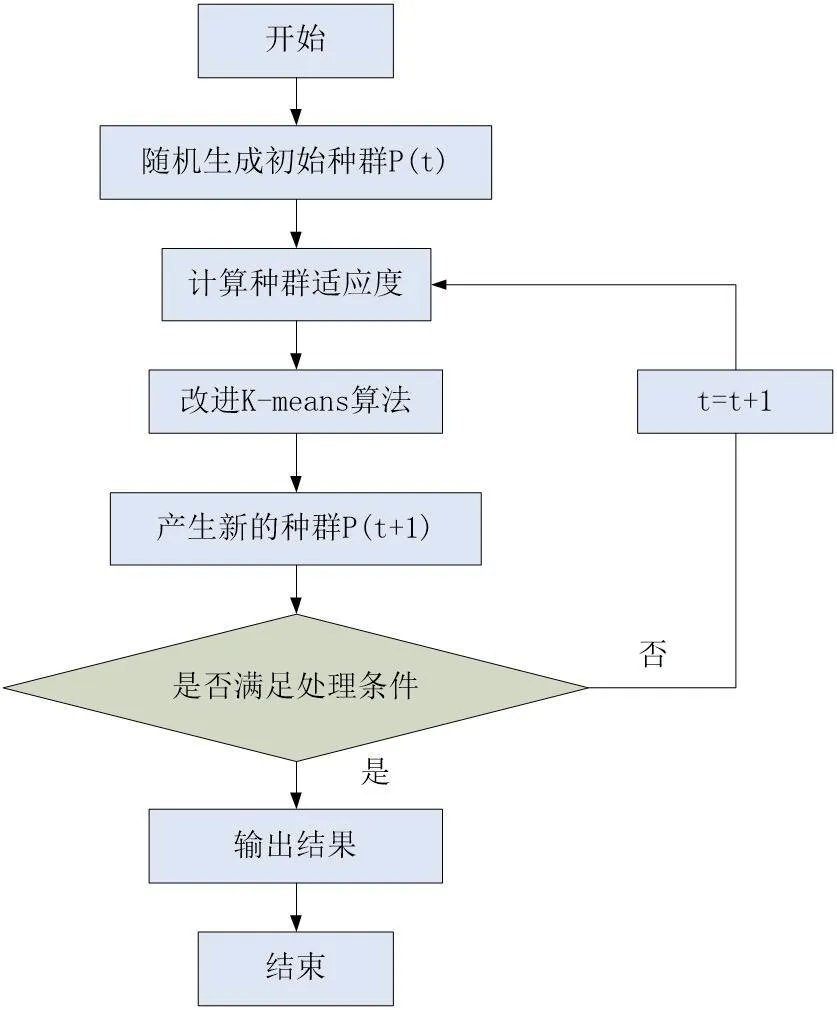
图2:改进模糊K-means算法流程图
如图2所示,使用K-means算法大数据是随机生成的,处理起来较为繁琐,并且现如今,使用大数据的一般为年轻人,数据流量较大,所以本文利用模糊密度的技术,改进K-means算法。改进后的K-means算法可以实现大数据集的处理,伸缩性较强,且处理效率较高,其理论依据为,密度越高,数据处理效果越好,进而得出大数据处理的最优结果。因此,本文改进的模糊K-means算法有两个步骤,其一,计算两个大数据间的密度,公式如下:

其二,根据密度公式,强化模糊系数,公式如下:
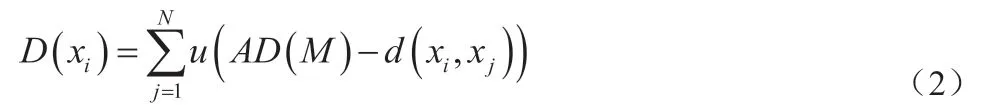
式(2)中,D(xi)为大数据周围密度,当周围密度较小时,则表示为大数据处理相似;M、N、u均为改进算法的模糊系数。基于此项流程,得到改进K-means模糊算法。
1.3 基于改进算法计算大数据处理方法相似度
根据上文中,得到的改进K-means模糊算法,本文件计算大数据处理方法的相似度。本文中计算相似度基于改进算法的基础,利用过滤算法进行计算。过滤算法是将相似的大数据,通过过滤协同达成用户的需求,将相近的词语或指标作为MAE值展现,利用MAE值得出用户的目标需求[8]。传统算法在计算大数据相似度方面存在不足,产生这些不足的主要原因是,相似度计算不准确,MAE值相差较多。本文提出了一种基于灰色邻近相关分析模型,此模型中,利用余弦相似性,根据空间夹角作为相似度的衡量标准,夹角越小,相似性越大,大数据内容就值得推荐。以数据A、B为例,公式如下:
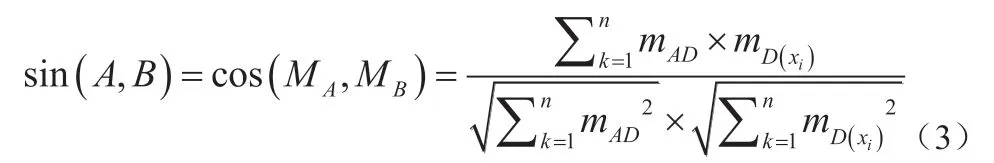
式(3)中,sin(A,B)为大数据A与大数据S之间的夹角;cos(MA,MB)为sin(A,B)的对应cos值;k、m、n均为相似度系数,为数据A的MAE值;为数据B的MAE值。从以上得出的数据相似度计算过程,使用数据之间的相似度量来衡量数据的相似性,充分利用了用户对数据的历史搜索功能,对用户的数据信息分类有很好的效果,让用户可以更准确地找到目标需求。同时,每个用户的历史信息均可以为其他用户提供有效的信息,形成一个良性循环。保证大数据的处理质量。鉴于已知数据集明确了分类,原始数据集将进一步遵循灰色理论,从而实现大数据的更优处理,本文将利用阈值对大数据进行分类。当已知的分类情况和阈值不同时,可以对改进算法得到的结果进行比较研究,消除基本误差,明确特定阈值下可获得的最高准确率。
2 实验分析
本文利用仿真实验,利用改进模糊K_means算法的MAE值进行计算,并将改进模糊K_means算法与传统算法下的大数据处理方法作对比,验证本文设计的大数据处理方法的有效性。
2.1 实验准备
本次实验采用精度度量方法,计算MAE值,当得出的MAE值与实际值偏离程度越小,算法的精准度就越高,也就是说大数据处理方法的处理效果越好。MAE计算公式如下:

式(4)中,MAE为偏离差值,S为大数据处理项目总数,利用此公式,计算两种处理方法的MAE值,验证本文设计的处理方法精准度情况。
实验样本数据为“脏数据”,第一,数据杂乱,数据来源于不同的应用程序或系统平台,包含文件数据和数据库等,没有统一的数据格式和定义,结构混乱;第二,数据重复,以同一条件在不同系统提取数据,所获取的数据会有许多重复的现象,数据冗余严重;第三,数据不完整,数据有采集到提取极易出现数据丢失的现象,可能是由于数据格式不兼容或原始数据不全等原因造成的。使用“脏数据”进行实验,更能体现大数据处理方法的有效性,样本数据类别如表1所示。

表1:样本数据类别
2.2 实验结果
随机选取10组大数据,利用传统处理方法与本文设计的处理方法对比,结果如表2所示。

表2:两种处理方法MAE值对比
如表2所示,10组大数据均为随机选取,利用公式(4),计算得出传统方法与本文设计方法的MAE值,表1中,传统大数据处理方法的MAE值,与实际MAE值相差±0.000200,差值较大,处理的精准度有随之下降,因此大数据处理效果差;本文设计的大数据处理方法的MAE值,与实际MAE值差额仅在±0.000001,甚至在04组大数据中,差值为0,整体差值较小,处理大数据的精准度较高,因此大数据处理效果更佳,符合本次实验目的。
3 结束语
近年来,互联网技术发展迅速,我国正处于信息化时代,大数据的兴起令人们的搜索方式变得更加简单,因此大数据的处理方法成为亟待改进的问题。本文从建立大数据采集模块、绘制改进算法流程、计算大数据相似度等三方面,研究了基于改进模糊K-means算法的大数据处理方法。保证大数据处理方法的精准度,进而提高大数据处理效果。
