基于大数据和集成学习技术构建金融企业风险评估系统
2021-03-07高赫
高赫
(北京金融安全产业园 北京市 100005)
近年来,借助大数据、人工智能、云计算、区块链等新兴信息技术,我国金融科技(FinTech)创新呈爆发式增长,在国际也处于领先地位。与此同时,监管科技(RegTech)作为FinTech重要分支,也日益受到重视。监管科技是指借助信息技术手段,辅助监管机构提升效降本,同时对被监管机构合规工作提供支撑。2017年7月全国金融工作会议确定“服务实体经济、防控金融风险、深化金融改革”三大任务,强调健全风险监测预警和早期干预机制,加强金融基础设施的统筹监管和互联互通,推进金融业综合统计和监管信息共享,对监管机构的监管能力和手段提出更高要求。RegTech具备快速、精准、高效,以及可统筹、可规划、可持续等特性,与上述要求高度契合。本次研究,针对金融机构风险特点,基于其工商、司法、经营、关联方等数据,进行模块化、分层的有监督学习,构建包含800余项指标的金融企业风险评价体系,为监管机构对风险的有效研判提供决策依据。
1 金融企业风险概述
在互联网金融快速发展的背景下,网络小贷公司、虚拟货币交易所等归属于地方的非持牌金融机构和组织的风险加速暴露,非法集资、债务链条断裂等金融乱象及风险事件时有发生,区域性风险隐患突出,对监管机构的监管能力和手段提出更高要求。
随类金融业态不断发展,加大了地方金融监管的压力和难度,如小额贷款公司、融资担保公司、地方资产管理公司、融资租赁企业等地方性金融机构及非持牌机构,存在于“一行两会”体系之外,其经营活动及派生风险主要由地方监管部门负责管理和处置,其在金融风险防范和化解方面扮演的角色日益重要。要维护区域金融安全和经社会健康发展,做到“把防控金融风险放到更加重要的位置,牢牢守住不发生系统性风险的底线”,有必要构建以科技为支撑的金融监管体系,以技术监管技术,以技术赋能监管。
本次研究针对地方“7+4”类金融机构的潜在风险,建立评价体系,以期实现此类风险的预警和防范。
2 技术方案选择
构建金融企业风险评价体系涉及的主要技术包括:特征衍生、集成学习、词频-逆文档率(TF-IDF)算法及遗传算法。
首先基于公开的工商、行政、舆情、司法等数据,借助特征衍生及模块化集成学习技术,通过因子分析与聚类分析,生成800多条风险指标。随后,使用TF-IDF算法提取经营范围中涉金融业务关键字,筛选出16余万家注册地为北京的金融机构及类金融机构。最后,通过遗传算法进行模块权重学习,测算风险指数,形成较为完善的风险评价体系,实现对金融企业风险的量化评估及预警。
2.1 特征衍生
对于企业原始数据中部分无实际含义的特征,无法直接反映企业的深层信息。需要进行变换或组合,提升信息价值和数据质量。特征衍生(或特征构建)就是基于业务逻辑和既有数据,对原始特征加以重构以生成新特征的过程。[1]常见特征衍生方法包括:
2.1.1 基于统计指标
同类企业数据中的高维稀疏特征常具有同质性,可有针对性的构建统计类指标,量化其集中和离散程度。另外,某些特征具有取值区间敏感性,也可以针对该特征的不同取值构建其统计特征。
2.1.2 基于排序指标
某些特征的取值区间与企业风险程度顺序相关,可针对该特征的不同取值构建其排序特征。
2.1.3 基于特征含义
某些特征可通过具体业务相关联,可对特征进行组合,依据业务逻辑,并结合实际监管需求,创建新特征。
2.1.4 基于特征交叉
针对数值型特征,根据其含义及彼此关系,进行代数运算,可生成企业风险在更高维中的分布特征。
2.2 集成学习(Ensemble Learning)
其本质就是组合多个弱分类器,构造预测效果更好的强分类器,属于监督学习范畴。[2]集成学习的路径主要包括:
2.2.1 Bagging
即Bootstrap Aggregating的缩写。Bootstrap采用有放回的抽样,以得到统计量的分布以及置信区间。在Bagging方法中,基于bootstrap方法从整体数据集生成N个数据集,在每个数据集上学习出一个模型,各模型权重均等,综合N个模型的输出(投票)得到最终预测结果。随机森林(Random Forest)即是典型的Bagging方法。
2.2.2 Boosting
Boosting对基础模型采取差别对待,反复考验筛选出「精英」模型,赋予更多权重(投票),最后对所有模型输出进行加权得出结果。AdaBoost算法即是典型的Boosting方法。
2.2.3 Stacking
训练多个不同模型,并综合各模型的输出训练一个新模型,以该模型的输出为最终输出。实际操作中通常使用逻辑回归作为组合策略。
2.3 词频-逆文档率(TF-IDF)算法
TF-IDF常用于信息检索与文章关键词挖掘,评估某词对某文档集或语料库中某文档的重要程度,以剥离关键词,实现文本数据的清洗。字词的重要性与其在文档中出现频次成正比,与其在语料库中出现的频次成反比;如某罕见词在某篇文章中多次出现,则很可能能代表该文章特性,即需要抽取的关键词,在计算时应赋予较高权重,即逆文档频率。[3]
当获得TF(词频)和IDF(逆文档频率)后,两数值相乘,即得到某词的TF-IDF值。TF-IDF值越大,该词通常对文章重要性越高。将各词TF-IDF降序排列,排在最前的词,即为文章关键词。
2.4 遗传(Genetic Algorithm)算法
通过模拟遗传学机理及自然进化过程,即自动选择优良基因,淘汰劣势基因,实现最优解搜索。[4]遗传算法的一般步骤:
采用适应度函数,评估每条染色体所对应个体的适应度;
对适应度评估值升序排列,选出前列若干个体作为待选父种群(评估值越小越好);
从待选父种群中随机选择两个个体作为父方和母方;
将双方染色体进行交叉,产生两个后代(交叉概率);
对后代染色体进行变异(变异概率);
重复上述3,4,5步,直至新种群产生;
循环以上步骤,直至出现最优解。
3 ‘主体 + 事件 + 维度变换’的特征衍生方案
3.1 数据来源
本次研究的原始数据包括:新闻、论坛,微博、招聘等公开数据1.2亿条;专用接口读取的工商企业数据5000余万家;行业协会提供数据20余万条;违法举报记录8000余条;立案记录、经济犯罪嫌疑企业名单等6万余条,失信公告、判决书、执行公告等司法信息5.5亿条。
3.2 数据预处理
本次研究对数据的预处理分两个步骤:
(1)特征衍生:利用上述数据对本市金融机构进行评估,采用“主体+事件+维度变换”的特征衍生方法(见图1)。

图1:“主体+事件+维度变换”特征衍生
(2)特征选择。按照以下三种方式处理:
剔除高缺失特征:有高缺失值的特征将增加噪声和训练成本,设置缺失比例阈值α=60%,删除超过阈值的特征。
剔除常变量特征:常变量增加数据冗余性,且对训练效果贡献极低,设置方差阈值σ=0.22,剔除低于阈值的特征。
剔除高相关性特征:相关度较高的特征参与训练将增加训练成本,计算各特征间的相关系数(数值变量计算Pearson系数,序数变量计算Spearman秩系数),设置相关系数阈值ρ=0.9,相关系数绝对值超过阈值的仅保留其一。
最终保留近900项风险特征(见图2)。
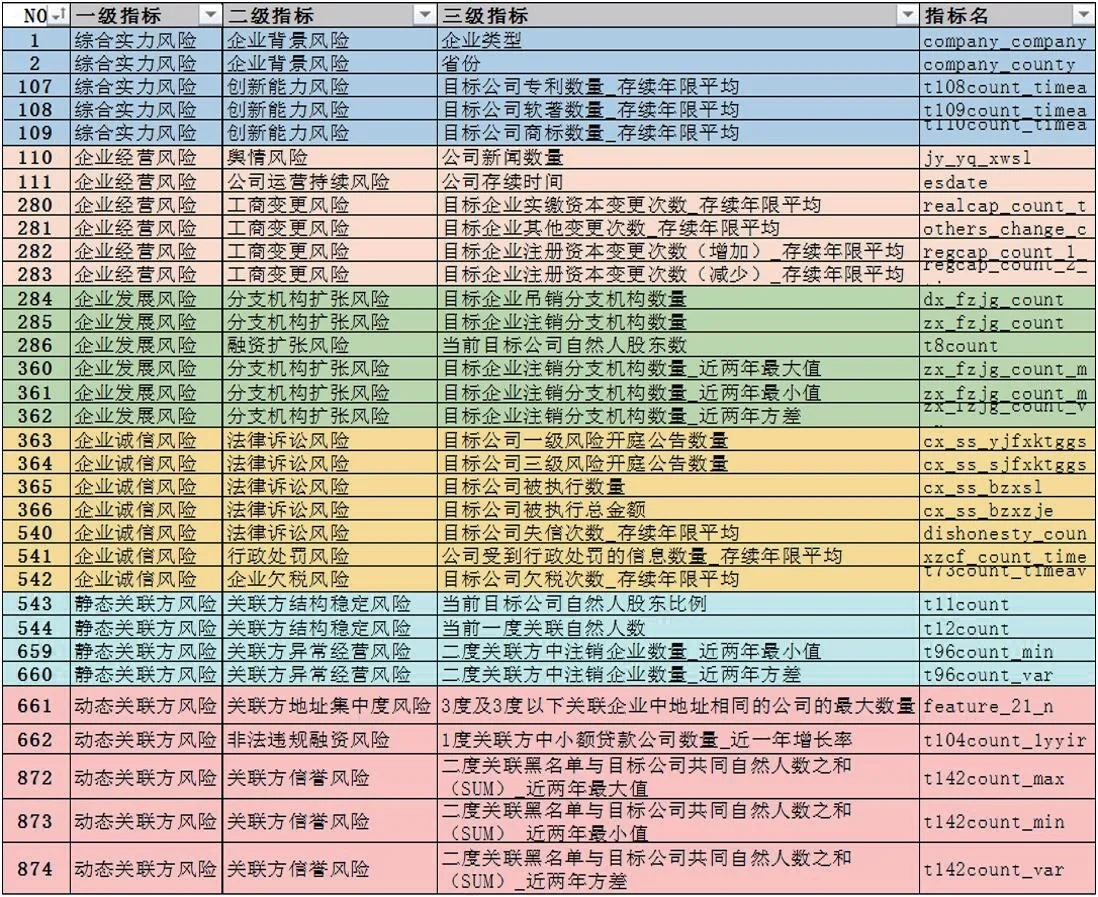
图2:经选择后的风险特征(部分)
4 风险指数-模块化集成学习技术
基于上述获得的风险特征项,进行模块化、层次化的集成学习,模型结构如图3所示。
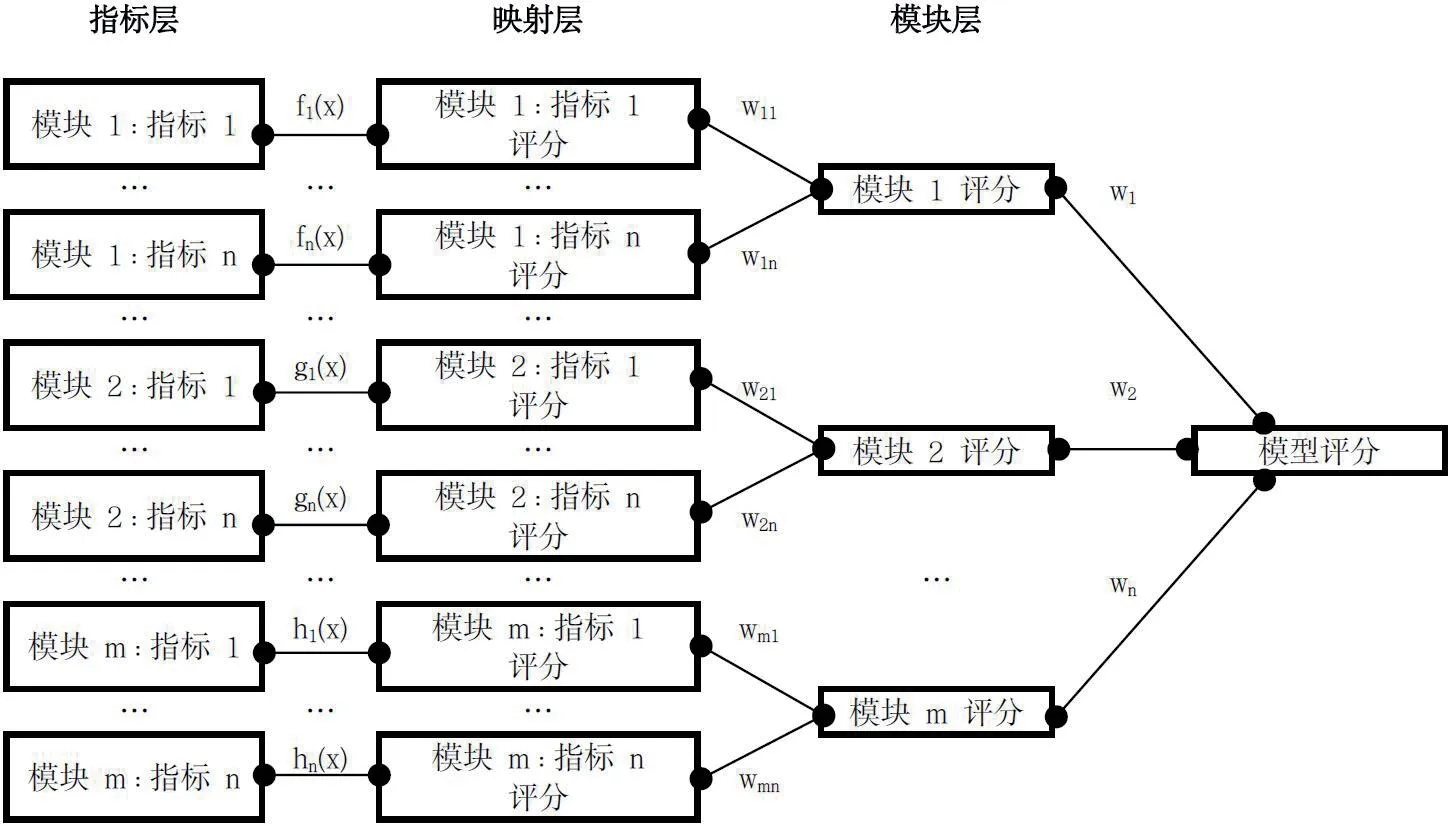
图3:模型结构图
5 TF-IDF算法实现企业分类
基于目标企业工商信息及经营信息,将本市金融机构分为网络借贷、小额贷款、私募股权、众筹、交易场所、融资租赁、典当、融资担保、金融仓储、金融租赁、金融资产交易等11个行业,即归属地方监管的“7+4”类机构。[5]
一方面,依据监管要求,按上述行业分类解析提取企业名称和经营范围中的关键词;另一方面,鉴于部分涉金融业务企业并未按规定申请经营许可,因此使用TF-IDF算法提取经营范围中的关键字,按如下公式计算关键词权重:

最终根据提取的企业名称和经营范围关键词,结合行业分类计算相关性,精准判定目标企业所属类型。
6 分类遗传算法学习模块权重
基于得到的金融机构类型,使用遗传算法赋予基础评价模块不同权重,搜索评价模块间最优组合权重,精准识别目标企业风险,并进行动态评估。
具体流程如下:
随机生成1500组基础评分模块,包括企业综合实力、行业特征、司法诚信、经营行为、关联方等特征,设定初始权重约束条件:最小权重不低于0.05,最大权重不超过0.3,总和为1;
对权重向量赋值,设定交叉概率0.5,变异概率0.25,迭代800次;
单次迭代均进行权重交叉及变异操作,并采用评价函数评估新权重,保留每轮迭代的最优权重,并通过‘轮盘赌’方式进行种群进化;
选择800次迭代最优解作为最终模块集成的权重组合,并使用该权重对该类金融机构进行风险测算。
7 总结
依托金融企业风险评价体系,可进一步实现对我市金融机构的实时监测预警,可视化呈现金融风险的地理分布和行业分布,对目标企业进行风险画像,协助监管机构有效排查属地金融风险,实现金融风险的常态监测。
