基于深度学习的名画识别模型设计与应用
2021-03-07杨波陶浩朱剑林李航高
杨波 陶浩 朱剑林 李航高
(中南民族大学计算机科学学院 湖北省武汉市 430074)
1 引言
深度学习中的图像识别技术一直是现代技术研发的前沿技术[1],现代社会生活的方方面面几乎都有它的身影,有着良好的应用前景。将深度学习应用在图像识别领域,最早可以追溯到1989年,加拿大教授 Yann Le Cun与其小组成员提出卷积神经网络并将其应用于图像识别领域。当时,卷积神经网络在小规模的图像数据集上拥有着最好的成绩,但受限于当时的技术水平,之后很长一段时间卷积神经网络都没有得到进一步发展[2]。直到2012年10月,加拿大教授 Hinton与自己的小组成员在Image Net竞赛中应用了卷积神经网络技术,使卷积神经网络在图像识别领域有了实质性的突破,这次之后,卷积神经网络模型能够识別和理解一般的自然图片的内容[3]。
在国内,也有许多将深度学习应用于图像识别方面的研究。如,中国水产科学研究院东海水产研究所的崔雪森与其小组成员将深度学习应用于微藻种类图像的识别,成功证实了深度学习方法可以有效鉴定微藻种类[4];西安石油大学的硕士研究生张文乐研究深度学习应用于交通路标的识别,并成功优化深度学习模型,提高了识别准确率[5]。
本研究针对名画识别,设计与建立基于卷积神经网络模型,设计与实现了基于Android的应用系统。
2 图像预处理
图像预处理主要是使用每张原图生成其随机样本,其中翻转样本3张、随机仿射透视变换样本5张、随机旋转样本5张、随机仿射透视变换加旋转样本5张,对原图进行形变的样本数(加上原图)总计19;然后以形变样本与25张背景图进行位置和alpha通道都随机的叠加合成,叠加合成的样本数总计有475;每张原图的样本数总计有494。而原图数总计有135,所有原图样本数合计有570076。
2.1 获取图片路径
为了方便读取图片以及保存生成的样本,需要架构一个合适的文件目录结构来存放图片。本文所选择的文件目录结构为“[图片文件总文件夹]/[每张原图文件夹(与原图文件同名)]/[原图文件]”。本文是通过自动脚本实现对1000张原图移入文件目录结构下。
2.2 镜像翻转
在Python中通过调用OpenCV中的flip()实现图像镜像翻转,使用函数将原图依次变换并保存后,其效果图如图1所示。
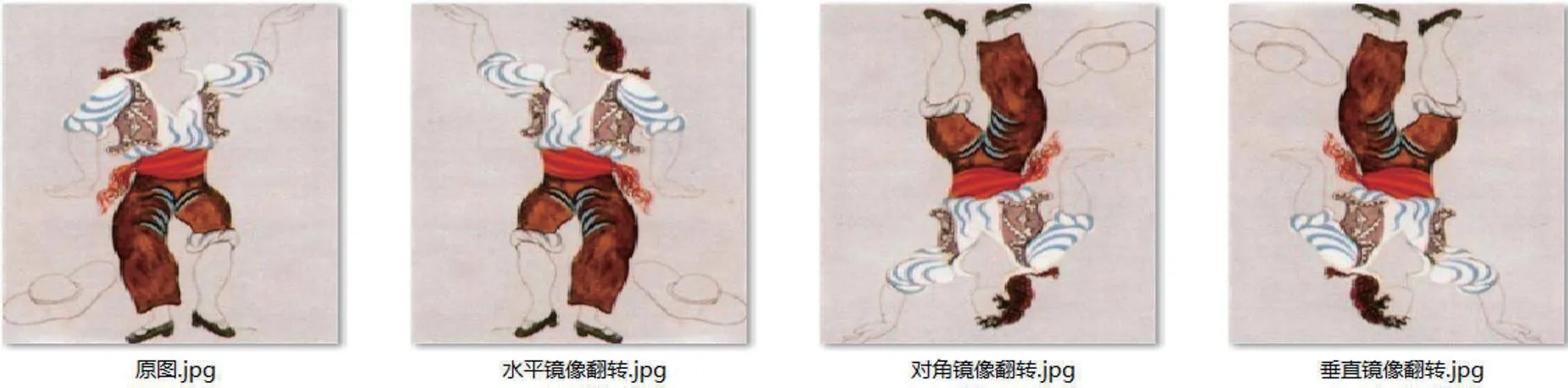
图1:镜像翻转图样
2.3 仿射变换
本文中使用仿射变换主要是应用在图像的错切操作。首先需要在图像的二维坐标(以左上角的顶点为原点,横向向左为横坐标的正方向,竖直向下为纵坐标的正方向)上取三个不在一条直线上的坐标点,将其存放在二维数组中;然后确定三个坐标点变换后的位置,一一对应存放在二维数组中。本文通过调用OpenCV的getAffineTransform函数获取整个图像的变换矩阵M;最后通过OpenCV的warpAffine函数获取到变换后的图像数据。最终效果图如图2。

图2:仿射变换图样
2.4 透视变换
本文中,使用透视变换主要是为了调整原图的立体倾斜角度,为了使生成的样本更贴近生活中拍出的照片(并不是完全与相机面平行)。通过OpenCV的getPerspectiveTransform函数获取变换矩阵M,然后通过OpenCV的warpPerspective函数获取变换之后的图像数据,其结果如图3。

图3:透视变换图样
3 数据处理
3.1 数据预处理
由于图片数量大,故需要预先将图像数据进行分割处理成计算机能读取的大小,经过测试,先将图片数据进行压缩为128×128的大小,然后分割为5份,每份中有100张每张原图的样本数据(除了最后一份,494%100=94,最后一份只有94张每张原图的样本数据),总计每份中有样本数13500。采用HDF5格式,不仅能降低存储空间,读取和操作也比较迅速,故本使用HDF5格式保存图像数据。本文在每个原图文件夹中读取100个样本,使用OpenCV中的imdecode方法,将读取的数据保存到HDF5格式文件中。
3.2 线程池生成文件
由于生成HDF5文件也是互不干涉,通过多线程技术实现每个线程读取每个原图文件夹中的不同的100个样本。故本文在此处使用线程池,需要传入每个线程读取的样本位置,以保证不会重复读取数据。
3.3 独热编码
由于分类结果并不是连续的数值特征,在模型训练时其并不方便计算,所以需要将分类结果转换为独热编码,使其变为连续的数值特征,这样可以更贴合机器学习算法,方便在模型训练时进行计算[6]。独热编码主要是通过0和1来表示分类状态。在本文中,先通过numpy库的eye函数,生成135×135(原图数量)的单位矩阵数组,然后通过字典生成式,将名称列表与单位矩阵数组每行一一对应绑定,这样即可完成分类结果与独热编码的绑定。
4 模型设计与模型训练
4.1 模型设计
VGG网络模型是卷积神经网络经典模型中的一种,其最主要的特征便是VGG块:将复数个卷积核窗口大小为3×3、向右和向下步长为1的卷积层与单个池化窗口为2×2、向右和向下步长为2的池化层组合。其中卷积层要保证输入的特征图的大小不变,池化层使输入的特征图大小减半。
本文结合实际应用需求,将VGG模型进行简化,其VGG块主要由一个卷积层和一个池化层组成,然后使用了三个VGG块、一个全连接层块组成整个网络模型,其中在卷积输出使用的ReLU激活函数;每个VGG块和全连接层块之后会增加一个dropout层来抑制部分神经元(即权值)参与运算(本文设置50%的神经元不参与运算,这样可以减少运算量),防止模型过拟合。其网络结构如图4和图5所示。

图4:本文所用卷积神经网络模型结构图

图5:本文所用卷积神经网络模型的TensorFlow计算图结构图
4.2 模型训练
本文的数据集有两种,一种是原始图像样本66690份,另一种是将图像数据提取为数组形式并压缩保存的纯数字数据样本5份。实际操作中,由于硬件方面的限制,主要使用的是后一种数据集,选取前4份作为训练集,后1份作为样本测试集,如图6所示。

图6:训练集文件和具有复杂生活背景图的样本测试集文件
将VGG块数分别设为2、3、4,然后都进行100轮(4份数据全部训练一遍记为1轮)训练后,然后以剩下的1份作为测试集,来测试对比模型优劣。因为VGG块为4时,特征图大小就已经为8×8,如果再加一个VGG块并不能取得更好的效果,故只选取VGG块为2、3、4的样例进行对比。而由于硬件和时间限制,本文暂时只能取训练100轮对比。
经过对比,选取了最合适的网络模型后,将这个网络模型进行重复训练,在训练过程中,模型训练3000轮之后,模型识别精确度约55%。
5 模型应用
5.1 基于Python和Android的系统设计实现
在Python中开发基于Android的APP比较便捷,需要调用Python的APP开发库kivy。
使用kivy库开发APP时,还可使用kv描述文档设置各模块的参数和动作来进行更简洁的APP开发。
获取图片主要有两种方式,一种可以通过文件选择器直接在设备内存中获取,另一种就是通过调用摄像头拍照获取。通过文件选择器直接在设备内存中获取图片,主要用到了kivy库中的FileChooser模块。使用该模块的FileChooserIconView子模块,可以以小视图的方式浏览文件夹。然后当用户选择文件时,可以获取改文件的完整路径,后台就可根据该路径读取图片数据。
调用摄像头拍照获取,主要是用到了kivy库中的核心模块Camera,使用该模块即可直接调用摄像头,然后通过截图摄像头内的画面,达到拍照的效果。
5.2 图片识别功能
该功能访问本地文件,将数据输入已训练好的模型然后获取输出结果。这一步的实现,需要用到TensorFlow库中的train模块的import_meta_graph函数,通过meta文件加载已训练好的模型结构与参数。然后使用TensorFlow中的get_default_graph获取已加载的模型。获取到模型后,要获取输入节点和输出节点,就需要通过get_tensor_by_name来获取节点,获取到对应的节点后,就可以传入数据并进行预测输出。结果如图7所示。

图7:识别图片结果对比
5.3 信息展示功能
改主要是将预测的结果处理后展示在信息显示界面。识别图片功能预测输出的是独热编码,而信息展示功能首先读取num_name.npy文件获取保存的字典格式信息(字典中,独热编码作为键,与独热编码对应的图像名称作为值),再通过预测的独热编码在字典中获取其对应的图像名称,然后读取info.npy文件获取键值分别为图像名称与图像介绍信息的字典格式信息,最后在字典中通过图像名称获取对应的图像介绍信息。结果如图8所示。
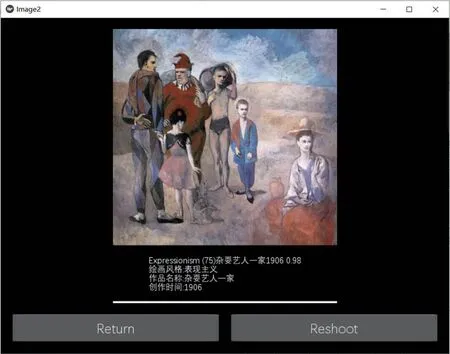
图8:信息展示界面
实际应用时,为了保证结果能更好的满足用户需求,需要在实际应用时做一些额外的处理以扩大预测的结果集。首先将用户需要识别的图片复制为100份,再将100份数据使用已训练好的模型进行识别预测,然后统计其识别结果中每种结果出现的频率,取其频率出现最高的五种结果,最后将结果与其对应的图像展示在信息显示界面,其流程如图9所示,实验结果如图10。

图9:用户输入到结果展示处理过程
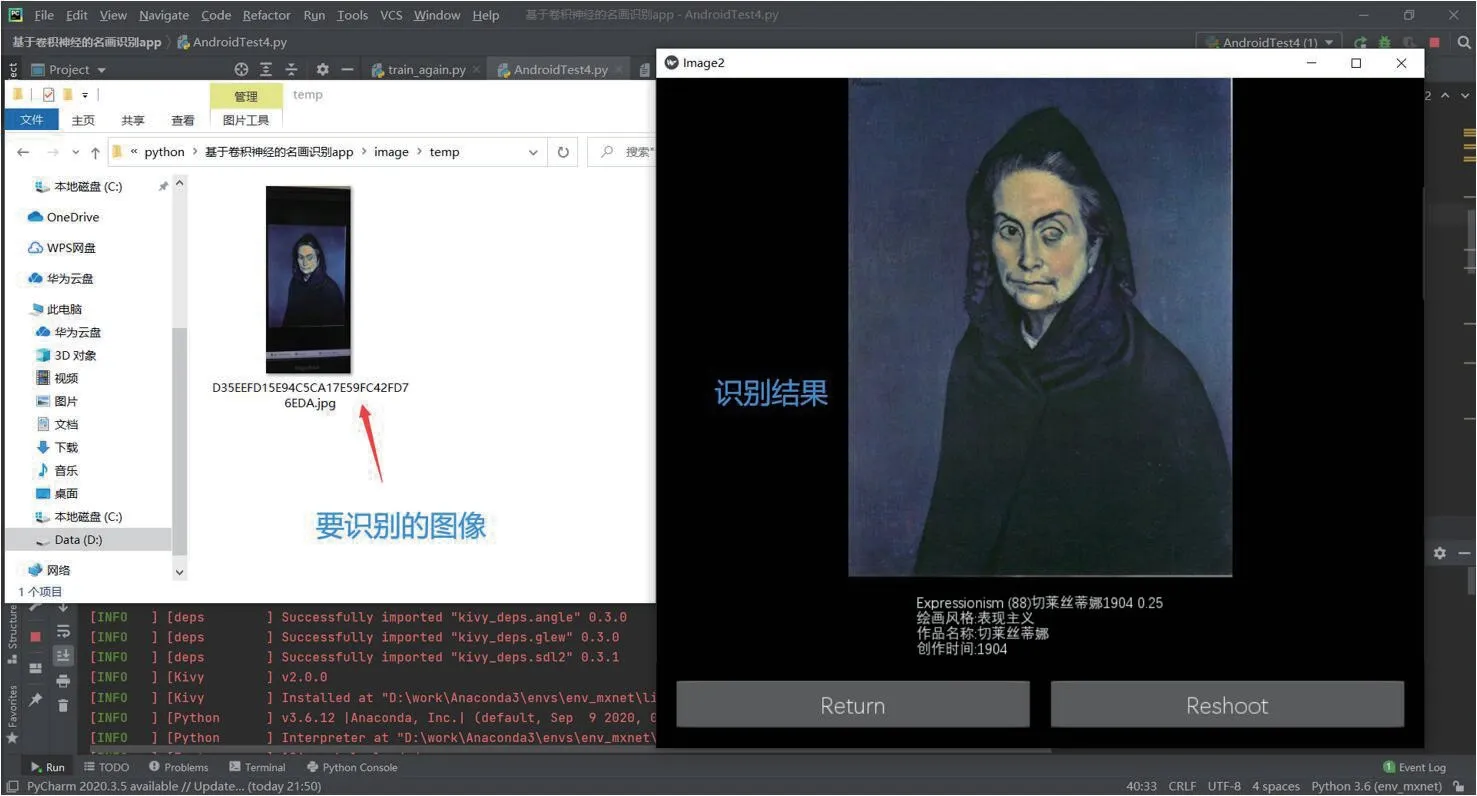
图10:实际应用识别结果
6 结语
本文设计了一套基于卷积神经网络VGG模型的名画识别系统,实现了图像获取、图像识别、信息展示等功能。在实际应用中,对识别结果进行对比,发现要提高识别结果的准确度,对拍照要求比较高,例如不能倾斜太严重、目标图像不能占整幅图像的比重太小等。分析其原因:
(1)模型训练还不够完美,还需要更多更广泛的样本来训练模型;
(2)抽象画的特征十分复杂,生活背景图对其识别的干扰很大。这还需要之后进一步的探索。
