长短期记忆模型在低频数据预测中的应用
——以新冠肺炎疫情对北京市社会消费品零售总额的影响测算为例
2021-03-06贺菁伟杨东谕
贺菁伟 杨东谕
(1.北京市统计应用研究所,北京 100054;2.北京市商业经济调查总队,北京 100054)
一、引言
新冠肺炎疫情发生以来,经济社会各领域均受到较大冲击。以消费领域为例,2020年1—8月,北京市社零额同比下降14.1%。其中,2020年1—3月,北京市社零额规模缩减明显,同比下降21.5%;2020年4月以来,伴随北京市复工复产的逐步推进和疫情防控形势稳中向好,社零额降幅持续收窄,但恢复过程较为缓慢。
鉴于疫情滞后影响仍然存在,科学构建预测模型评估疫情对消费品市场的影响显得尤为重要。本文利用北京市社零额月度数据,引入3个影响社零额的变量,即常住人口规模、城镇居民人均可支配收入和居民消费价格指数,测算疫情对北京市社零额的影响程度和作用时滞,为后疫情时期支持北京市消费市场发展、促进消费潜力释放提供数据支撑。同时,通过深入分析单变量模型和多变量模型之间的适用性,为时间序列数据的预测分析提供可借鉴思路。
二、文献综述
(一)疫情对经济社会影响的研究
关于疫情对经济社会造成的影响,国内很多学者都进行过相关研究。如朱迎波等(2003)利用双变量ARIMA模型,结合SARS疫情发生后人们的心理发展变化曲线,研究三类心理发展变化情况下疫情对中国入境旅游人数的影响;孙玉环(2006)重点探讨ARMA模型在预测SARS对中国入境旅游外汇收入影响上的作用,并与传统的“同期比”法进行对比,结果表明,ARMA模型充分考虑了时间序列自身的发展趋势,在测算重大突发事件的影响时比“同期比”法更准确客观。
(二)社会消费品零售总额预测方法研究
时间序列分析方法是预测社零额的主要方法,包括自回归协整移动平均模型(ARIMA)、考虑季节影响的ARIMA乘积模型、灰色模型(GM)等。其中,张华初等(2006)使用1978—2004年的月度全国社零额数据,构建了同时考虑时序滞后和季节影响的ARIMA乘积模型,并将2005年全国社零额月度实际值用于模型的预测检验;李庭辉等(2012)引入城镇居民家庭人均可支配收入为自变量,使用经过季节调整的ARIMAX模型对2002年第一季度至2011年第二季度的社零额数据进行拟合分析,以拟合相对误差为依据对社零额统计质量进行评估;王志坚等(2014)对我国1953—2010年社零额年度数据进行ARMA建模,并用该模型预测未来五年社零额的变化情况。
(三)LSTM模型应用研究
长短期记忆模型(LSTM)是一种改进的循环神经网络模型(RNN),能够记住更长周期的信息,并且规避了RNN中梯度爆炸和梯度消失的问题,近年来在自然语言处理、文本分析等领域有较好的应用。同时,相关研究显示,LSTM在预测领域表现出较强的对时序数据的处理能力。赵军豪等(2018)以微博数据为切入点,提出了融合情感分析和深度学习的多变量预测模型(SA-LSTM),结果表明,SA-LSTM的预测精度显著高于ARIMA、LR、反向传播(BP)神经网络以及单变量LSTM模型;吴翌琳等(2020)应用传统时间序列模型和神经网络模型,对基于某社交新闻类App的日广告收入数据进行互联网企业广告收入预测研究,结果表明,基于时间序列和神经网络构建的组合模型对低频数据预测有较强的有效性和适用性。
三、数据来源和预测模型
(一)基础数据来源及数据处理
结合已有研究和统计实践,本文认为影响社零额的因素主要有以下几个方面:
一是人口因素。人是消费的主体和直接参与者,人的衣食住行必然与消费市场相连,直接或间接影响社零额。通常来说,城市人口越多,其消费需求越旺盛,社零额也会随之增加。同时,人口的结构性变动也会影响社零额规模,主要体现在在总人口规模相似的前提下,城镇化率高的地区,其社零额通常大于城镇化率低的地区,即城镇居民的消费能力普遍强于农村居民。
二是居民消费水平因素。居民消费水平的变化直接影响社零额,伴随居民收入的增加和生活水平的提高,人们对美好生活的追求推动消费结构升级,改善型、高端型消费需求持续涌现,拉动社零额不断增长。
三是价格因素。消费市场产业链较长,价格传导特点明显,即上中下游任一环节的价格变化,都会影响最终消费品的定价,进而影响社零额。
基于上述分析,我们以北京市统计局官网公布的数据为基础,重点选取3个影响社零额的变量,即常住人口规模、城镇居民人均可支配收入和居民消费价格指数,以月度为单位(2008年1月—2019年12月)构建各指标时间序列数据。
由于各指标统计频率不尽相同,本文对4个变量数据分别进行处理:(1)根据公布的2005—2008年社零额1月和2月数据①根据国家统计局制度方法调整,2009年起,1—2月社会消费品零售总额指标按累计进行统计。,分别计算社零额1月和2月平均占比情况,并根据统计经验,将2009—2019年社零额1—2月累计数据换算成月度数据;(2)采用差值法,按月均增速变化对常住人口规模进行增补,形成月度数据;(3)根据公布的2005—2007年城镇居民可支配收入月度数据②根据国家统计局制度方法调整,2008年起,居民收支数据按季度统计。,分别计算各月城镇居民可支配收入平均占比(本年),将2008—2019年城镇居民可支配收入的季度数据和月度累计数据换算成月度数据;(4)将居民消费价格指数进行定基处理。
(二)模型预测方法
1.LSTM模型
LSTM是一种改进的循环神经网络模型(RNN)。RNN模型因为可能发生梯度消失现象所以只能短期记忆。LSTM在每个序列索引t时刻向前传播的信息除了和RNN一样的ht外,还多了一个细胞状态Ct,并通过遗忘门、输入门和输出门三种门控状态来控制传输状态,可以记住需要长时间记忆的信息,忘记不重要的信息。LSTM结构及表达式如下:
(1)遗忘门
遗忘门决定从细胞状态中丢弃的信息。表达式为:

(2)输入门
输入门决定加入细胞状态中的新信息。表达式为:


(3)输出门
输出门确定最终的输出值。表达式为:

其中,ft表示需要记忆的信息比例;σ表示sigmoid激活函数;W与b分别表示权重与偏置;ht-1表示上一序列的输出;xt表示本序列输入;it表示需要更新的信息比例;表示更新的细胞信息;Ct-1表示上一序列的细胞状态;Ct表示本序列的细胞状态;ot表示需要输出的信息比例;ht表示本序列的输出。
2.SARIMA模型
SARIMA模型在ARIMA模型的基础上增加了对季节性因素的预测,加入季节性自回归、季节性移动平均和季节差分算子,转换为SARIMA(p,d,q)×(P,D,Q)S模型,其表达式为:
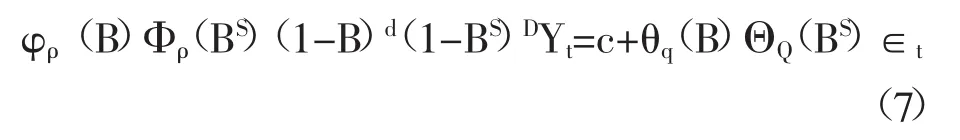
其中,Yt为在时刻t下待预测的时间序列观测值;S为季节周期长度(月度数据S=12);c为常量;∈t为残差序列;B表示延迟或滞后算子,是原始时间序列观测值Xt滞后k个周期的符号化体现;φρ(B)表示p阶自回归算子;θq(B)表示q阶移动平均算子;(1-B)d表示d阶差分得到的非季节性平稳序列;Φρ(BS)表示P阶季节性自回归算子;ΘQ(BS)表示Q阶季节性移动平均算子;(1-BS)D表示D阶季节差分得到的季节性平稳序列。
(三)模型评价指标选择
我们选取均方根误差(RMSE)和平均绝对百分比误差(MAPE)两个评价指标度量模型的预测能力。其中,RMSE偏向于呈现模型整体的预测效果,常用于机器学习模型预测结果衡量的标准,值越小表示预测效果越好。但由于社零额数据量级较大,而测试集数据样本较小,因此本文利用MAPE指标(值越小表示预测效果越好),通过计算误差在真实值中的占比情况,比较不同模型的预测准确性,进一步分析各模型预测效果。
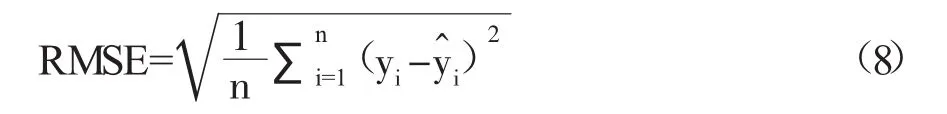

其中,yi是第i个测试样本的真实值,是第i个测试样本的预测值,n代表测试样本数量。
四、实证结果与分析
本文通过建立单变量SARIMA模型、单变量LSTM模型和多变量LSTM模型预测社零额。其中,单变量SARIMA模型、单变量LSTM模型只考虑社零额的时间序列数据;多变量LSTM模型引入影响社零额的3个变量,对社零额进行预测。
(一)SARIMA模型预测
基于R语言,选取2008年1月—2019年12月的社零额数据,其中,利用2008年1月—2018年12月社零额建立SARIMA模型,取2019年1—12月社零额作为测试集。第一步,通过ADF单位根检验对原始序列进行平稳化处理,初步确定模型的差分d=1,季节性差分D=1。第二步,绘制平稳化序列的ACF和PACF图,初步确定p、q、P、Q的取值范围。第三步,采用低阶到高阶逐步实验的方法,根据AIC准则检验和Ljung-Box检验,确定拟合度最优模型SARIMA(1,1,1)×(0,1,0)12,预测出 2019年 1—12月社零额。
(二)LSTM模型预测
1.单变量LSTM模型预测。基于Python语言,利用单变量LSTM模型进行预测,选取2008年1月—2019年12月的社零额数据。第一步对数据进行归一化处理。第二步取2008年1月—2018年12月的社零额数据作为训练集,取2019年1—12月的社零额数据作为测试集。由于LSTM具有记忆功能,本文在构建模型时将时间阶数设置为12,即认为每一时期的社零额与它前面12期(即1年)的社零额是相关的。故我们令模型的输出变量yt为每一时期t的社零额数据,令模型的输入变量Xt为它前面相邻12期的社零额数据,进而预测出单变量LSTM模型中2019年1—12月社零额。
2.多变量LSTM模型预测。对多变量LSTM模型,选择2008年1月—2019年12月的社零额、常住人口规模、城镇居民人均可支配收入和居民消费价格指数数据。建模步骤与单变量LSTM模型基本一致,其中,令模型的输出变量yt为每一时期t的社零额数据,令模型的输入变量Xt为它前面相邻12期的社零额、常住人口规模、城镇居民人均可支配收入和居民消费价格指数数据。由于该模型引入了影响社零额的3个变量,我们先将3个变量2008年1月—2018年12月的数据作为训练集,分别建立单变量LSTM模型,预测出3个变量2019年1—12月的值,进而预测多变量LSTM模型中2019年1—12月的社零额。
(三)模型预测效果对比分析
利用模型评价指标,通过对模型效果的预测进行比对(见表1),可以得出如下结论:
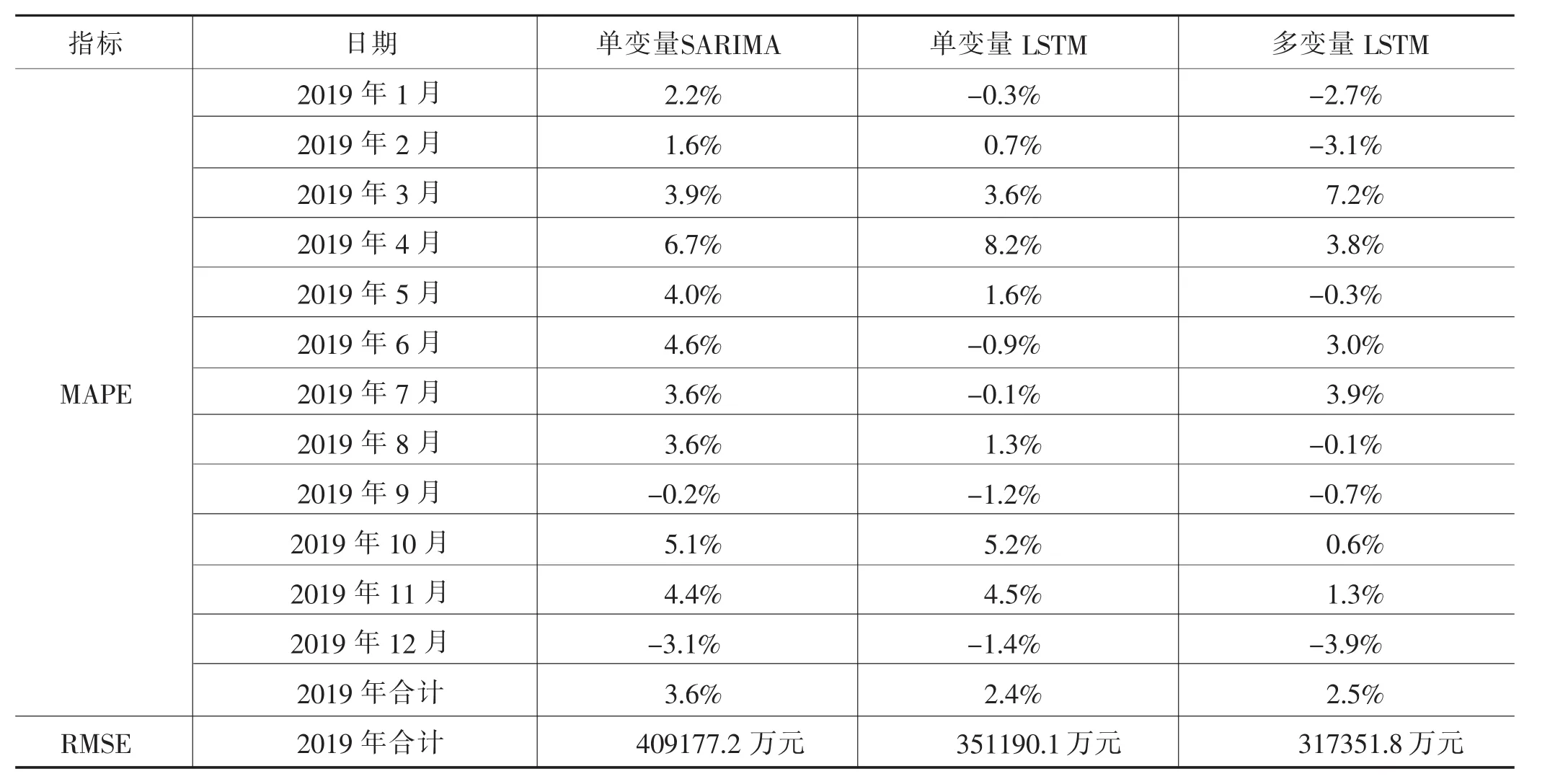
表1 各模型预测效果对比
1.LSTM模型的预测效果好于SARIMA模型。单变量LSTM模型的RMSE指标值小于单变量SARIMA模型,即单变量LSTM模型在精准性和稳定性上优于单变量SARIMA模型。同时,单变量LSTM模型MAPE指标值更小,可以得出,基于本文数据建立的单变量LSTM模型效果好于单变量SARIMA模型,即在数据颗粒度较粗、数据量较小的情况下,LSTM模型仍能显示出较好的预测效果。
2.多变量模型优于单变量模型。单变量和多变量LSTM模型的MAPE指标值相近,多变量LSTM模型RMSE指标值小于单变量LSTM模型,可以得出,基于本文数据建立的多变量LSTM模型在测试集上的预测效果好于单变量LSTM模型,引入的3个变量对社零额均有显著影响。
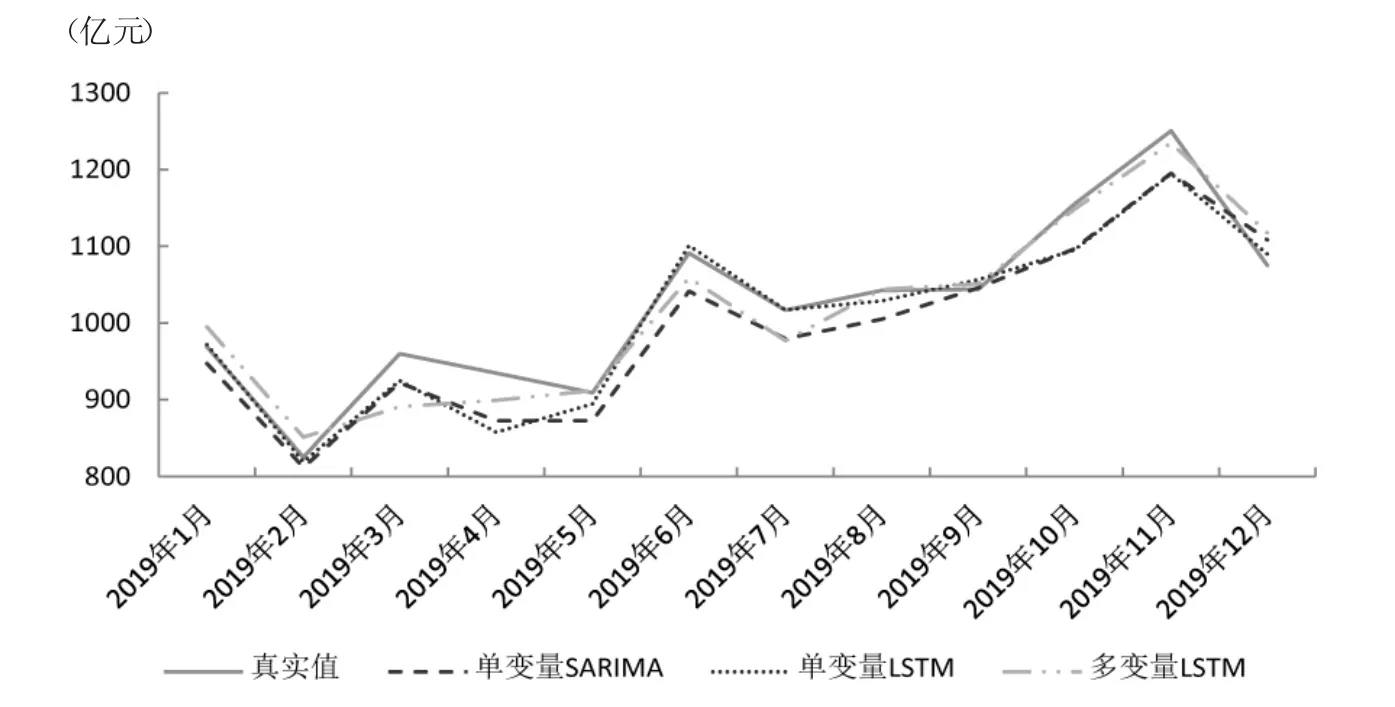
附图 模型预测效果对比图
五、基于多变量LSTM模型的社零额预测分析
结合模型预测对比分析结果,我们利用多变量LSTM模型,预测非新冠肺炎疫情影响下2020年北京市社零额月度变化情况,探讨新冠肺炎疫情对北京市社零额的影响。
国家统计局根据第四次全国经济普查数据结果对全国及各省、自治区、直辖市2019年社会消费品零售总额进行了修订,本文根据2019年公布的社零额数据和2020年社零额同比增速情况,对2020年社零额实际值进行调整。
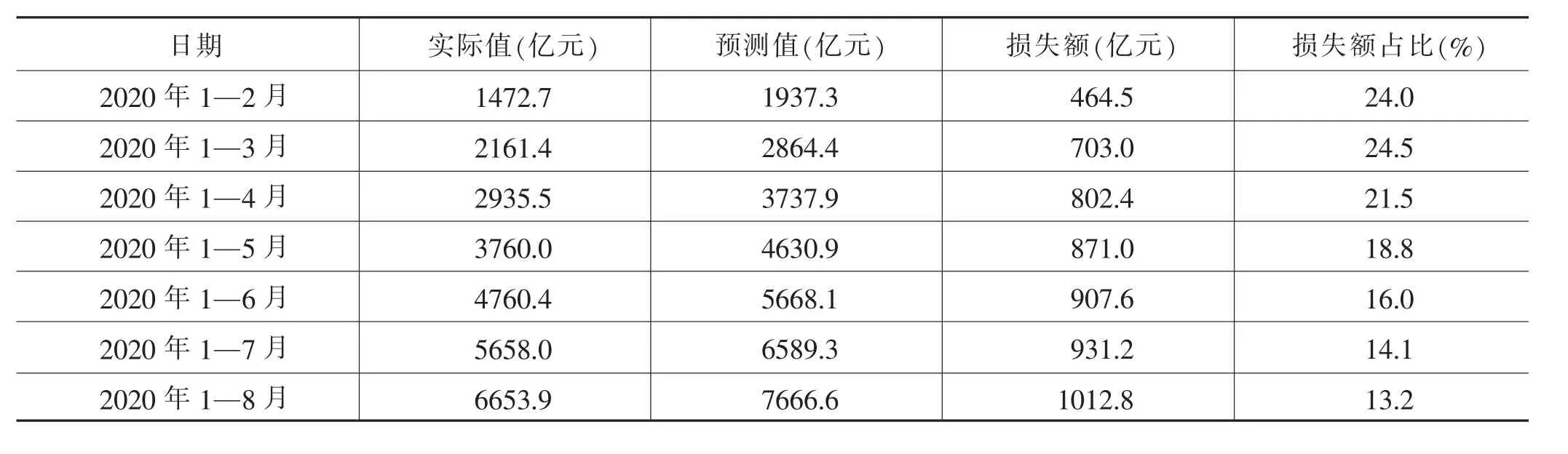
表2 2020年北京市社零额实际值与预测值比较
受新冠肺炎疫情影响,2020年1—8月,北京市社零额累计损失1012.8亿元。其中,在疫情暴发初期,即较为严重的一季度,北京市社零额累计损失703亿元,占累计总损失额的69.4%。随着全国疫情防控形势持续向好、北京市复工复产稳步推进、各类促消费政策有序出台等,2020年二季度以来,北京市社零额损失额逐月减少。2020年1—8月,北京市社零额实际值较预测值降低13.2%,降幅较2020年一季度收窄11.3个百分点。
六、结论与启示
本文以社零额指标为例,通过传统时间序列模型(SARIMA)和神经网络模型(LSTM),预测新冠肺炎疫情对北京市社零额的影响。在模型构建上,引入多维变量,建立多变量LSTM模型。模型预测结果显示,基于本文建立的时间序列数据,LSTM模型可以发挥神经网络优势,预测效果优于SARIMA模型。多变量LSTM模型的预测效果优于单变量LSTM模型,且引入的3个变量对社零额有显著影响。最后,利用拟合度较好的多变量LSTM模型,对2020年北京市社零额排除新冠肺炎疫情影响进行预测,结果表明,疫情对北京市社零额的负面影响逐渐减弱。
长短期记忆模型在处理复杂数据的应用效果普遍优于传统时间序列模型,但在处理低频率数据上较难体现其优势。本文引入多维变量,通过优化调整模型参数,证明了长短期记忆模型在处理传统时间序列数据方面仍可发挥较好的预测效果,为提升传统统计模型预测的准确性提供了经验。
