大数据财产
——概念析正、权利归属与保护路径
2021-03-05张弛
张 弛
(杭州师范大学 沈钧儒法学院,浙江 杭州 311121)
2013年,牛津大学的维克托·迈尔-舍恩伯格教授(Viktor Mayer-Schönberger)与《经济学人》杂志数据主编肯尼思·库克耶(Kenneth Cukier)共同著成《大数据时代:生活、工作与思维的大变革》(BigData:ARevolutionthatwilltransformhowwelive,workandthink)一书,宣告了“大数据时代”的来临,引发了全球范围内关于“大数据”问题的探讨和热议,因此,2013年也被称作“大数据元年”。[1]大数据被广泛应用于市场分析、商业咨询、广告投放、新闻传媒、政府公共服务、刑事司法与科学研究等各个领域,对社会生活的各个方面产生了极其深远的影响。与此同时,大数据本身所蕴含的巨大经济利益与商业价值亦引起了广泛关注,“数据资产”“大数据财产”等概念纷纷破茧而出。2015年4月14日,贵阳大数据交易所正式挂牌运营并完成首批大数据交易,标志着大数据正式作为一种商品在现实的市场平台上进行交易。然而,“大数据财产”的概念尚处于成形过程中,现行法律法规和司法解释并没有对“大数据”或“大数据财产”的法律性质作出明确规定,围绕“大数据是什么”“大数据是否属于法律意义上的财产”“大数据财产应当属于谁”等重要议题,不同观点各执一词、聚讼不断,给大数据财产的确权与保护造成了不小障碍。有鉴于此,本文拟从“大数据”和“大数据财产”的概念析正入手,结合大数据挖掘的一般流程,就“大数据财产”的基本内涵、权利归属与保护路径等基础性问题进行阐述,以期为今后的理论研究与实务探讨提供一套系统、明晰而准确的概念体系和话语标准。
一、“大数据”及“大数据财产”之理论聚讼
虽然很早就有学者提出数据是一种新的生产资料的观点,认为大数据是新财富,价值堪比“石油”。[2](PP.117-121)“大数据财产”(big data asset)[3]、“数据资产”(data asset)也成为学界和政府官方文件中颇为常见的术语。(1)2014年5月,美国发布了《大数据:抓住机遇,保存价值》,即《美国大数据白皮书》。白皮书指出:“政府机构根据开放程度已将数据资产(data assets)划分为三个种类:开放性、半开放性、非开放性,并且只能出版发行开放性密级的信息。”2013年10月31日,英国商务、创新和技能部发布《英国数据能力发展战略规划》,同《美国大数据白皮书》一样,《英国数据能力发展战略规划》中也使用了“data assets”一词。“大数据财产”或“数据资产”(data asset)一词正式被英美等国家的政府官方文件所承认。然而就目前而言,关于“大数据财产”的专门研究并不多见,鲜有学者对“大数据财产”本身的内涵、外延和表现形式进行界定,这一概念更多地被用于强调大数据所包含的经济属性和商业价值,成为“大数据”主题研究的下属论题。某些论者虽然使用了“大数据财产”的表达,但其研究主要还是立足于“大数据”本身的法律定位与理论研讨[4](PP.141-152),“大数据财产”作为一种法学研究对象的独立价值尚未引起学界的足够重视。有鉴于此,在对“大数据财产”的财产属性、权利归属与保护路径进行探讨之前,首先要解决的是研究对象的界定问题,即“什么是大数据财产”的问题。
由于“大数据财产”属于“大数据”主题研究的下属命题,并且这两个概念往往同时出现、相伴而生,故此,若要回答“什么是大数据财产”,首先需要澄清“大数据”本身的概念界定与本质属性问题,即“大数据是什么”的问题。遗憾的是,不仅“大数据财产”如雾里看花,“大数据”同样是一个定义模糊、争议不断的概念。关于“大数据”的内涵和本质,国内外理论界至少存在如下几种不同看法:
(一)大量数据(流)说
国内的一些学者将大数据界定为“大量”“海量”的数据或者数据流:大数据是指数据量巨大、通常认为数据量在10TB-1PB以上的,数量级是“太字节”(2^40)的,并且是高速、实时的数据流[5];“大数据是依确定目的而挖掘、处理的大量不特定主体的数字信息”[6](PP.30-37);大数据是指格式多样、规模和内容前所未有的大量数据,这些数据搜集自企业日常运作的各个环节,专业技术人员可以对他们进行高速分析[7]。
(二)数据集合说
与前者看法不同,数据集合说倾向于将大数据界定为一种静态的数据集合(Data sets)而非动态的数据流。该说认为,所谓大数据是指“由来源于异构数据源的结构化的、非结构化的与半结构化的数据所构成的数据集”[8];或者“用先进的数据储存、管理、分析和可视化技术进行处理的数据集合”[9](PP.1165-1188)。Kitchin认为,大数据应当是在尽可能详尽的宏大范围内(通常是涉及某一问题的全部相关领域)进行数据捕捉的、与研究对象具有本质性相关性的、得出精细决策的、索引式的同时兼具灵活性的数据集合。[10]齐爱民教授则认为,大数据是指在合理的时间内无法使用传统的软件、硬件和IT技术对其进行收集、分析和处理的数据集合。[11]
(三)动态技术说
动态技术说将大数据视为一种以海量的数据信息为对象的动态应用技术或进程。持此立场的学者认为:“‘大数据’的标签应当被用于描述一种关于数据是如何被捕捉、存储和加工的技术或趋势,而不是被定义为一种特定的产品。”[12](PP.21-39)“大数据是一个相当模糊的术语,它描述了一种新工具和技术的适用趋势,这类技术和工具是以在规模和大小上远超传统方法所能企及的大规模数字信息作为对象的。”[13]贵阳的大数据交易所将“大数据”界定为“对来源分散、数量巨大、格式多样的各类互联网数据进行采集、存储和关联分析,从而发现新知识、提升新能力、创造新价值的新型技术模式和服务业态”,该定义亦将大数据界定为一种全新的技术形态。
(四)商业智能说
还有学者将大数据视为一种商业智能(BI,Business intelligence)。(2)商业智能的概念在1996年由加特纳公司(Gartner Group)率先提出,加特纳将商业智能(BI)定义为:商业智能描述了一系列的概念和方法,通过应用基于事实的支持系统来辅助商业决策的制定。商业智能技术提供使企业迅速分析数据的技术和方法,包括收集、管理和分析数据,将这些数据转化为有用的信息,然后分发到企业各处。实用意义上的BI系统最早出现于宝洁这样的大型消费品制造商和像沃尔玛这样的零售商系统,其目的是分析历史销售数据以服务于下一步的商业决策,回答诸如“我们在某个地区卖出了多少钱”和“上个季度我们赚了多少利润”之类的问题。根据这一观点,大数据是传统商业智能技术在互联网时代的进化与演变。大数据分析扩大了BI的范围,传统的BI分析主要依靠驻留在公司内部数据库的集成和报告结构化数据;而在大数据时代,BI可以通过寻求从来源于互联网或客户移动设备等来自公司外部的半结构化和非结构化数据中提取价值,来拓展BI范围[9](PP.1165-1188)。麻省理工学院商学院教授埃里克·布伦乔尔森(Erik Brynjolfsson)和技术专家安德鲁·麦凯菲(Andrew McAfee)指出,大数据的本质是从海量数据中收集情报并将之转化为商业优势:“与之前的商业分析一样,大数据分析试图从数据中收集情报,并将其转化为商业优势,但大数据比以前使用的分析工具更为强大。”[14](PP.60-68)
(五)数据财产说/数据资产说
动态技术说、数据流说和数据集合说更倾向于从技术层面对大数据进行界定,并未突出大数据的经济价值与财产属性。随着大数据所蕴含的巨大商业价值日益凸显,越来越多的观点开始从经济角度对大数据进行定义,将大数据作为一种资产或者财产看待。(3)John Carlo Bertot, etc., “Big data, open government and e-government: Issues, policies and recommendations”, Information Polity: The International Journal of Government & Democracy in the Information Age, 19(1), 2014, pp.5-16; Prasanna Tambe, “Big Data Investment, Skills, and Firm Value”, Management Science, 60(6), 2014, pp. 1452-1469; Robert K. Perrons, Jesse W. Jensen, “Data as an asset: What the oil and gas sector can learn from other industries about ‘Big Data’”, Energy Policy, 31, 2015, pp.117-121.例如,阿里巴巴集团的大数据平台“阿里云”的创设宗旨之一即在于“将数据变成生产资料和企业资产”。 “大数据是以云技术为依托实施的数据处理,通过对海量数据的集成共享和交叉复用而形成的信息资产。”[15]“大数据具有财产性应该是最没争议的问题,因为从学理研究、大数据开发利用和数据交易实践,以及政策性文件规定中都能得出这个结论。”[16]正是在“数据资产说”“数据财产说”等观点思潮的催动下,“大数据财产”的概念正在日渐成形。
通过梳理与“大数据是什么”有关的理论争议,可以发现国内外学界在大数据本质的认识上存在较大分歧,产生了包括动态技术说、数据集合说、数据流说、数据资产说与商业智能说在内的多种见解。之所以形成这种百家争鸣的格局,并不是由于某一种观点或见解存在偏差,而是在于不同的论者在不同的学科语境下、从不同的研究视角出发对“大数据”这一内涵包罗极广的概念进行定义。正如澳大利亚学者珍妮特(Janet Chan)所指出的那样:“对‘大数据’进行定义并不是一个直截了当的过程;大数据可能被描述为一种容量和类型、一种存储数据的能力和进程或者一种分析系统,也可以被描述成市场环节的一环或者某种社会和文化现象,定义取决于不同的技术应用方向和平台而呈现出多样性。”[12](PP.21-39)实际上,“大数据”应当被理解为一类概念而非一个概念,是动态技术与海量数据的结合,兼具技术属性与社会经济属性;大数据具有技术、资源、应用等多个层次的含义,是新资源、新工具和新应用的结合体。[17](PP.1-2)“大数据”恰如一个变幻无方的多面骰子,从不同的研究视角出发,可以对“大数据”的定义作出各种不同的解释,用任何一个侧面来指代整个“大数据”的概念都是有失偏颇的,势必陷入管窥蠡测、盲人摸象的认知困境。
为了更好地厘清大数据的属性与本质,进一步回答大数据财产的内涵和范围问题,下文将对大数据挖掘过程的各个环节依次进行剖析,由此框定“大数据”和“大数据财产”的内涵、外延及概念范围,并对“大数据财产”的权利归属与保护路径等问题做进一步解答。
二、数据挖掘与大数据的概念解析
对“大数据”和“大数据财产”等基本概念的界定离不开对大数据挖掘过程的解析。大数据挖掘(Big Data Mining),又称大数据分析(Big Data Analytics),是指从海量数据中发掘具有实践应用价值的知识模型的过程。[18](PP.917-928)大数据的价值是通过数据挖掘实现的,只有通过大数据挖掘,才能在海量数据中发现那些隐藏的、有价值的信息,大数据所蕴含的经济利益与商业价值方能得以体现。[19](PP.81-90)综合国内外相关学者的研究情况,可以将大数据挖掘的一般过程划分为如下几个步骤:
(一)数据收集
进行大数据挖掘的前提是海量的数据收集工作。数据收集的来源主要包括用户、企业以及第三方数据提供商。被收集的数据来源广泛、形式多样,既包括各类静态的数据库,也包括各种形式的动态数据流;既包括文本、图表、数据库等结构化数据(structured data),也包括位置信息、网上浏览痕迹和个人健康数据等非结构化数据(unstructured data)。(4)Doug Laney, “3D data management: controlling data volume, velocity, and variety”, META Group Research Note, 6, 2001; See at: Stefan Debortoli, Oliver Müller, Jan vom Brocke, “Comparing Business Intelligence and Big Data Skills A Text Mining Study Using Job Advertisements”, Business & information Systems Engineering, 5, 2015, pp.290-300.从这个意义上说,所谓的“数据流说”和“数据集合说”均是对“大数据来源”所下的定义。在数据采集阶段,“大数据”表现为体量巨大、来源多样的动态数据流与静态数据,既包括大量组织化、结构化的静态数据库,也包括海量的非结构化数据。这一阶段的“大数据”可以被称为“来源意义上的大数据”,也即大数据处理的对象。实践中通常将那些已经被数据采集者收集完成但是尚未进行处理的数据称作“底层数据”。[16]具体说来,作为大数据收集和挖掘对象的底层数据,主要包括如下几类:
1.公民个人信息数据,包括生日、年龄、性别、手机号码、身份证号码等直接体现公民个人信息的各类数据。包含公民个人信息的可识别数据是数据收集阶段最具价值的数据,很多数据甚至无需经过挖掘处理即可直接使用,因此也成为各类合法或者非法的数据收集者最为青睐的大数据来源。合法的数据收集者通过采用各类“接受或离开”的格式合同尽可能多地获取具有可识别性的用户的个人数据[20],进行未经许可的二次利用与定向强制推销;而非法的数据收集者则会将其掌握的个人数据售卖获利,甚至利用非法收集到的个人数据实施诈骗[21]。有鉴于此,《刑法》与《网络安全法》均对公民个人信息进行了专门的保护。
2.不具有可识别性的结构化数据。除了能够直接用于商业目的的手机号码、身份信息、财务数据等可识别性数据,与个人信息无关的结构化数据也具有收集和挖掘的价值。对生产设备维护的记录数据有利于提升机器和其他设备的使用寿命;从企业管理系统获取的出货量和进货量大数据有助于提升产品和服务的流动周期;而对员工管理系统中长期积累的各类数据进行分析挖掘,有利于制定更好的、更具竞争力的考评标准与薪酬方案,由此留住更多有能力的员工。[22](PP.1-34)又如,通过智能电表收集用户的用电量等数据虽然并不涉及个人信息,但是不同的电子设备都有自己独特的特征,例如热水器、电脑和LED等的耗电量完全不同,所以能源的使用情况能够暴露出诸如一个人日常习惯、医疗条件,由此可以有针对性地制定销售方案,推销产品或服务。[23](PP.196-197)对于有需求的企业和数据利用者来说,几乎所有储存在静态数据库中的结构化数据都是有收集价值的,这些数据的总量极为庞大,依照现有的技术手段无法完全对其进行分析和处理,以至于部分学者将“大数据”理解为传统的储存方法和分析技术无法处理的过于庞大和复杂的数据集[24](PP.290-300),这便是“数据流说”“数据集合说”的由来。
3.行为痕迹。在前互联网时代,数据收集的主要对象是储存在计算机系统中的各类结构化静态数据;而到了大数据时代,非结构化数据取代结构化的静态数据成为互联网数据的主体[25],大量的非结构化数据、半结构化数据成为大数据挖掘者们争相收集的主要目标。其中,最受关注的是以Cookies为代表的用户行为痕迹数据。Cookies是让网站服务器把少量数据储存到客户端的硬盘或内存,或是从客户端的硬盘读取数据的一种技术,包含相当的用户信息,相当于确定网站中用户的身份证,其存在形式与一般意义上理解的“电脑缓存”近似。[6](PP.30-37)通过对Cookies等用户行为痕迹的分析可以获取用户访问网站、作息时间等信息,为精准广告的投放提供参照。[21]在现实生活中,Cookies还会被一些游走于灰色地带的企业倒卖交易[26],由此成为各类合法的或者非法的数据利用者重点收集的对象。除了Cookies以外,其他类型的用户行为痕迹也为各类数据收集者所收集,例如近年来层出不穷的“键盘记录器”病毒能够记录一定时间内用户键盘的输入记录,甚至可以记录鼠标的行为轨迹,犯罪分子可以通过对这些数据的挖掘分析来窃取受害人的QQ、邮箱、网银的账户、密码。[27]在大数据时代,信息源自数据,而数据则来源于用户的行为留痕[20],以Cookies为代表的互联网行为痕迹等非结构化数据正在成为数据利用者重点收集的对象。
4.地理位置信息。除了用户在互联网上形成的行为痕迹,人们在现实空间中的地理位置数据也成为大数据收集的重要目标。地理位置数据蕴含着巨大的挖掘价值,已成为各方竭力收集、抢夺的对象,谷歌地图、百度地图、高德地图等电子地图APP以及大众点评、美团外卖、饿了么等生活服务APP均无时无刻不在搜集人们的地理位置信息;iPhone手机本身就是一个“移动间谍”,一直在用户不知情的情况下收集用户的位置信息传回给公司。很多手机应用、互联网游戏以及终端设备无论有无必要,均要求使用者授权其获取地理位置信息的权限,借此获取用户的实时位置信息。[23](PP.116-117)地理位置信息是一种被广泛收集和使用的非结构化数据。
5.个人健康数据。包含个人身体健康情况的各类数据是另一种被广泛收集的非结构化数据。国外的Asthmapolis公司将一个传感器绑定到哮喘病人的呼吸器上,通过GPS定位搜集这些信息,由此判断环境因素(如附近的农作物)对哮喘的影响。Basis公司用腕带测量佩戴者的心率和皮肤导电率,依次来测试他们所承受的压力。佐治亚理工学院的Robert Delano和Brain Parise开发了一款名为iTrem的应用程序,用手机内置的测振仪来检测人体的震颤情况,以期实现对帕金森与其他神经性系统疾病的预防。[23](PP.123-124)在国内,互联网巨头们也纷纷通过各类可穿戴设备(如小米手环、华为手表等)与应用程序(“阿里体育”、“微信运动”等)收集用户的各类健康、运动数据。以健康数据为窃取对象的刑事案件在实践中也有出现。(5)参见“乐某某、王某非法获取计算机信息系统数据案”,上海市黄浦区人民法院(2014)黄浦刑初字第106号判决书;上海市第二中级人民法院(2014)沪二中刑终字第229号判决书。
6.其他非结构化数据。数据收集者对非结构化数据的收集并不仅限于前述几种典型种类,一些更加生僻少见的非结构化数据也可能成为大数据收集的目标。例如,2011年,国外的一些研究者通过对来自84个国家240余万人情绪数据的收集,得出了不同文化背景的人每天、每周的心情都是遵循着相似变化模式的规律,“情绪数据”也成为大数据收集的对象。[28](PP.60-65)在2015年的大众点评诉百度不正当竞争案中,百度收集了大众点评用户的点评数据,将之直接标注至百度地图上。(6)参见上海市高级人民法院(2016)沪73民终第242号判决书;上海市浦东新区人民法院(2015)浦民三(知)初字第528号判决书。诸如此类的案例可以得知,不仅储存在数据库中的结构化数据可以成为大数据收集的对象,形态多样的海量非结构化数据也会成为数据收集的目标,是“数据流说”“数据集合说”等观点的实践根基。
综上,在数据收集阶段,作为大数据挖掘来源的海量数据既包括个人信息等结构化数据,同时也包括种类繁多的非结构化数据。在来源意义上,“大数据”一词应当被理解为“来源于异构数据源的结构化的、非结构化的与半结构化数据所构成的数据集合与数据流”。[8]
(二)数据清洗
如前所述,虽然手机号码、年龄、职业、家庭住址等个人信息数据具有极高的挖掘价值,但是由于其包含了公民的个人隐私,一旦被泄露或者被非法使用便会对公民的人身和财产安全造成巨大威胁,故此受到法律的严密保护。在我国司法实践中,企业对未经匿名化处理的个人信息数据的权利是不被承认的。[29]有鉴于此,对于包含用户个人信息的可识别化数据,必须经过匿名化处理之后才能使用,这一过程被称作“数据清洗”或者“数据脱敏”。在采用匿名化等脱敏技术后,用户个人信息数据所带有的人身性、隐私性被消除,而基于采集、记录技术而获取数据的数据控制者获得了对其收集的数据进行使用和处分的权利。[20]实践中,在大数据市场进行交易的数据往往是经过清洗后的数据,贵阳大数据交易中心中交易的“大数据资产”便是经过匿名化清洗后的数据,不直接交易底层数据。[30](PP.61-66)日本富士通公司建立的大数据交易平台“Data plaza”所交易的数据也是清洗后的非底层数据,包括购物网站的购物记录、智能手机的位置信息等个人数据和其他类型数据。[16]
(三)数据处理
在对不包含公民个人信息的数据收集完毕,或者对包含公民个人信息的数据进行匿名化清洗后,大数据挖掘者便开始对大数据进行分析和挖掘。大数据挖掘主要是通过知识模型(knowledge patterns)和学习模型(Learning models)实现的。究其原理,大数据挖掘是一个基于海量数据构建学习模型,再将学习模型部署后反复学习的过程,大致包括如下步骤:
1.数据集成。数据集成主要包括如下三个步骤:一是提取特征,确定挖掘的对象与范围,根据拟挖掘数据的类型和性质,采用各种统计方法确定大数据挖掘的频域(Frequency-domain feature)和时域(Time-domain feature)特征,以此来确定大数据挖掘的范围;完成特征提取后的第二步是数据转化,通过对数据的处理,将各种非结构化和半结构化的原始数据流转换成为可供挖掘的结构化数据格式;第三步则是减少维度,大数据集通常包含了成千上万的维度(即数据表中的属性/列),分析如此庞大的数据集将会非常困难。因此,需要采用维度减少的方法来限制数据集,以产生大数据分析的高相关数据集。[31](PP.14-26)
2.形成知识模型。在对数据进行集成处理并进行格式化之后,接下来最为关键的一步就是生成知识模型,而知识模型是通过学习模型的不断重复计算、学习获取的。所谓学习模型,是指基于机器学习理论和统计理论,研究现有的数据性质,并且识别和预测未知数据和行为的模型。学习模型是通过训练数据集生产的,这些数据集包含与未来数据相似的特征。学习模型本身的质量与学习过程的训练量决定了大数据系统所产生的知识模型的质量与准确性。一旦生成并经过评估,学习模型就会被部署在企业应用程序中,通过学习逐渐生成可以用于大数据预测的知识模型。
3.部署和监控。经过长期的学习与海量的计算,学习模型就会被转化为具有实际应用价值的知识模型,可以自行对今后的某些事件作出大数据预测并对相关事务作出处理。至此,大数据挖掘的工作即告完成,大数据也由分析、处理阶段转向实际应用阶段。
在数据处理阶段,“大数据”更多地表现为一种短时间内迅速进行海量计算、处理巨量数据的动态技术,这便是“动态技术说”的主要依据;此外,在大数据挖掘过程中起到关键作用的学习模型与知识模型显然是一种非常典型的商业智能(BI)工具,故此也可以将“大数据”理解为一种新兴的商业智能(BI)工具。
(四)数据应用
经过数据收集、数据清洗、数据处理等步骤,数据利用者可以通过大数据挖掘得到最终的应用阶段的大数据产品。鉴于行业性质、商业目的、数据规模等诸多方面的差异,最终的数据挖掘结果与应用方式也千差万别,无法以列举的方式穷尽所有的大数据应用形式。不过,以下三类大数据产品的应用在实践中颇具普遍性:
1.通信媒介应用(CCM,Communication Media)。CCM应用主要是将大数据分析后得出的商业智能模型实际应用于信息发送、通讯交流等业务,是一种应用最为广泛的大数据产品。最典型的CCM即精准营销与个性化广告推送:在百度搜索育儿知识之后右下角会经常弹出推销婴幼儿用品的广告;在视频网站观看视频后手机会收到视频周边的推送;从事学术研究的人会收到大量的论文发表、会议邀请的垃圾邮件。诸如此类均属CCM的范畴。掌握海量用户个人信息、行为痕迹、网页浏览记录的数据收集者通过对这些数据的深入挖掘,得出目标客户的兴趣、爱好、购物需求,继而通过短信、网页广告、页面推荐等方式向其精准推销相应的产品或服务,由此在降低广告成本的同时大幅提升营销效果,给广告主和营销者带来巨额商业利益。[32]
2. 客户关系管理(CRM,Customer Relationship Management)。CRM是指企业为了拓展销量、提升市场竞争力,利用互联网技术加强与顾客的联系,向顾客提供某些个性化的身份管理服务,从而吸引新客源,将已有客源转化为忠实客户的管理模式。传统上的会员卡、VIP等服务模式都属于CRM工具的范畴。在大数据时代,商家会在交易过程中获取大量的客户身份信息与行为痕迹数据,通过对客户的“数字画像”,可以准确地根据CRM数据对特定用户进行差别化处理,借此追求利润的最大化。CRM应用的正面案例包括常见的“生日祝福”邮件,生日、年龄、星座折扣,积分奖励系统等。而商家不当运用CRM数据的负面教材则更为著名,在实践中通常被称作“大数据杀熟”。据报道,在某些旅行预订平台、网约车平台和电影票平台预订服务和产品时,老客户的价格要远高于新注册的用户。[33]支付宝推出“扫码得红包”活动时,新用户扫码得到的红包数额很大,而经常使用支付宝的用户往往只能扫到1角到2角的微量金额;又如,在爱奇艺、QQ、优酷等主流APP充值会员时,使用苹果手机充值的客户要比使用安卓手机的客户额外多收数十元的费用[34],这些营销现象之所以出现,其背后均得益于CRM数据的应用。
3.地理位置服务(LBS,Location Based Services)。如运动轨迹、滴滴打车、地图定位、附近的人、微信位置分享等。在数据收集阶段所采集的地理位置是一种非结构化数据,并不能直接使用,通过大数据挖掘,可以将这些地理位置数据转化为结构化的LBS数据,并与用户的地理定位需求结合起来,提供多样化的位置信息服务。[6](PP.30-37)实践中已经出现了以LBS数据作为犯罪对象的刑事案件。2016年7月,实时公交查询APP“车来了”以非法手段侵入深圳谷米科技公司后台,窃取了该公司安装在4万余辆公交车上的GPS定位数据,深圳市南山区人民法院一审判决“车来了”创始人兼CEO邵凌霜犯非法窃取计算机信息系统数据罪,罚金10万元,判处有期徒刑3年、缓期4年执行。[35]
除了前述三种应用层面的大数据,还有其他多种形式的大数据产品,例如“Farecast”“飞常准”“车来了”等航班、大巴预测APP所使用的班次时间数据即属此类。在这个层面上,大数据可以通过商业应用产生巨大效益,大数据的经济价值得以凸显,将“大数据”定义为一种财产或资产的主张便由此而来。(7)John Carlo Bertot, etc., “Big data, open government and e-government: Issues, policies and recommendations”, Information Polity: The International Journal of Government & Democracy in the Information Age, 19(1), 2014, pp.5-16; Prasanna Tambe, “Big Data Investment, Skills, and Firm Value”, Management Science, 60(6), 2014, pp. 1452-1469; Robert K. Perrons, Jesse W. Jensen, “Data as an asset: What the oil and gas sector can learn from other industries about ‘Big Data’”, Energy Policy, 31, 2015, pp.117-121.
三、“大数据”与“大数据财产”之概念勘正
通过对大数据挖掘流程的梳理可以得知,“大数据”应当被理解为一组综合性的概念集合而不是某一种单独的技术、数据或财产:在数据收集阶段,“大数据”表现为海量的结构化或非机构化数据,可以称之为“大数据来源”;在数据挖掘阶段,“大数据”则表现为通过数据集成、学习模型与知识模型等商业智能技术,将海量的非结构化、半结构化数据快速地转化为可供应用的结构化数据集合,这些进行大数据分析和大数据挖掘的智能技术模型构成大数据挖掘的工具即“大数据模型”;而在数据应用阶段,“大数据”则表现为CCM数据、CRM数据和LBS数据等数据挖掘的产品,通过商业应用转化为经济利益,使大数据的价值得以实现,这些“大数据产品”也是大数据价值链上不可或缺的重要一环。
基于以上认识,可以对“大数据”的概念内涵和外延进行界定:作为本文研究对象的“大数据”,是指大数据收集、挖掘过程中的对象、工具与结果的统称,包括大数据来源、大数据模型和大数据产品。围绕“大数据是什么”的诸多争议学说,无非是“大数据”这一综合性概念在数据挖掘不同阶段的具体表现形式:“数据流说”和“数据集合说”是对数据收集阶段的大数据来源的描述;“动态技术说”和“商业智能说”代指学习模型和知识模型等大数据挖掘工具;而“数据资产说”/“数据财产说”则强调了经过收集、清洗的底层数据以及经过挖掘之后形成的大数据产品中所蕴含的巨大经济价值。

表1 大数据在不同阶段的表现形式
如前所述,“大数据”是一组综合性的概念集合,包括大数据来源、收集和清洗后的数据、大数据模型及大数据产品等不同表现形式。“大数据财产”作为“大数据”的下属概念,意味着并不是所有的大数据表现形式都可以被认定为法律意义上的“财产”继而被冠之以“大数据财产”之名。只有符合法律的规定,具备“财产”概念的全部构成要件的大数据表现形式,才是值得财产法保护的“大数据财产”。那么,在前述几种大数据表现形式中,哪些可以被归入“大数据财产”的概念范畴之中呢?
笔者认为,欲使“大数据财产”成为一种名副其实的财产类型而不仅仅是一种宣示性的概念,必须使之完全满足立法上关于“财产”特征的全部要求。一般认为,法律意义上的“财产”必须同时满足管理可能性、转移可能性和客观价值性三个基本特征。[36](P.932)以此为标尺,可以对大数据挖掘过程中的大数据表现形式逐一进行检视。
首先,未经收集的大数据来源不属于法律意义上的“财产”。尽管大数据收集者可以通过网络爬虫工具、旁路采集数据和数据监听工具从数据生产者和其他数据源收集数据,但大数据来源显然具有管理和转移的可能性。[6](PP.30-37)应当指出的是,存在于广阔互联网空间内的各种零散的结构化数据、半结构化数据和非结构化数据,并不具备客观的经济价值。之所以得出这种结论,涉及到大数据的价值性来源问题。
对此,有学者认为,大数据的经济价值来源于海量的单个数据,虽然“大数据”具有极高的价值,但是这是通过其巨大的容量性(Volume)特征实现的,单个数据的价值密度极低。[37]也就是说,作为数据收集对象的大数据来源本身就是具有经济价值的,数据收集者只不过是通过数据的收集活动将这些零散的经济价值富集在一起而已。
应当指出,上述观点在大数据的价值来源问题上出现了一定的认识偏差。大数据的价值并不是通过大量单个数据价值的简单相加获取的,而是通过数据的集群累积效应产生的,单一、零散的数据信息不具有财产属性,不能被视为“财产”。这就好比单独的一只鞋子、一根筷子或者一粒盐、一粒沙、一枚石子是无法作为商品出售的,鞋子和筷子必须成双出售,而盐、沙子和石子的使用价值和交换价值必须通过集群效应方能产生。与此同理,大数据最为核心的特征也是“以量取胜”,组成大数据的每一个零散数据的价值,必须经过数据收集达到一定的数量层级并且依托合理的数据分析方得体现。[38]这种原理用公式表示则体现为:大数据的价值(V),并不是如公式1所示由一些微量价值的零散数据简单叠加而成,而是必须借诸海量数据的集群效应与累积效应方可实现(公式2),V≠V’。
公式1假想的大数据价值产生公式
1+1+1……+1+1+1+1=V’
公式2大数据价值产生公式
0+0+0……+0+0+0+0→V
大数据的价值必须借助海量数据的集群效应方得体现,单一、零散的数据不具有财产属性,这一原理意味着当我们对大数据是否属于“财产”的问题进行分析时,应当注意区分作为大数据收集对象的零散数据与经过大数据收集者收集集成之后的数据。前者不具有财产属性与经济价值,更多地体现出被收集者的人格利益与隐私权,而后者可以用于大数据的商业开发,体现出巨大的财产利益与商业价值。[38]前者可以是结构化数据、也可以是非结构化数据,而经过收集的大数据必须以结构化数据的形式存在。前者是基于数据生产者的自身行为(如提交资料、登记信息、点赞、评论、浏览网页等)而自发产生的;而后者则是由数据收集者有意记录、收集而形成的大数据商品。[39]
存在于互联网上的海量零散数据并不具有为社会所认可的客观价值性,相比之下,那些经过收集的数据,目前已经形成了比较固定的大数据交易平台,其交易价格也已形成较为固定的标准(8)目前国内的大数据交易平台主要包括三类:一是以贵阳大数据交易所为代表的交易所平台;二是中关村数海大数据交易平台为代表的产业联盟性质交易平台;三是以数据堂为代表的专注于互联网综合数据交易和服务平台。其中贵阳大数据交易中心交易的是经过清洗后的数据,中关村数海数据交易中心交易的是底层数据和清洗后的数据,而数据堂等数据商出售的是自己搜集的结构化数据。以上三者交易的均是经数据收集者收集的结构化数据,并不是用户直接产生的数据。参见高完成《数据确权与交易规则研究》,《西安交通大学学报(社会科学版)》,2018年第3期。,经过收集和清洗的数据所具有的客观价值也得到了社会的普遍认可,没有太大争议[16]。简言之,作为大数据来源的海量数据并不能被称为“大数据财产”,只有经过收集或清洗的海量数据方始具备成为“财产”的可能性。
其次,作为大数据挖掘工具的知识模型和学习模型不属于“大数据财产”之范畴。如前所述,转移可能性是财产概念的必备特征之一,无法被转移占有的客体(如技术、劳动、服务等)即便具备一定的客观经济价值也不能被视为法律意义上的“财产”。从这个意义上讲,在大数据挖掘中发挥关键性作用的学习模型以及经过学习模型反复地机器学习所形成的智能化知识模型,本质上是一种专属于特定大数据挖掘者的数据处理工具,是一种包含着数据挖掘者智慧的程序架构,无法脱离数据挖掘者的大数据处理系统而单独存在,因而不具有转移可能性,不属于法律意义上的“财产”,也不能被称为“大数据财产”。
最后,可以在市场上直接进行交易的CCM数据、CRM数据和LBS数据等大数据产品是一类典型的“大数据财产”。国内日渐繁荣的大数据产品交易市场证明大数据产品同时具有占有、转移的可能性以及为市场所普遍认可的客观经济价值,完全可以被认定为法律意义上的“财产”。此外,根据《刑法》第92条第1项之规定,“生产资料”属于法律意义上的“财产”类型,而在新的时代背景下,大数据业已成为一种重要的生产资料,不仅催生了包括数据探矿、数据服务等在内的一系列以数据为生产原料的全新产业,甚至对现有的生产关系与经济运作模式产生了革命性的影响。(9)国务院在《促进大数据发展行动纲要》(国发[2015]第50号文)中指出:“大数据推动社会生产要素的网络化共享、集约化整合、协作化开发和高效化利用,改变了传统的生产方式和经济运行机制,可显著提升经济运行水平和效率,大数据持续激发商业模式创新,不断催生新业态,已成为互联网等新兴领域促进业务创新增值、提升企业核心价值的重要驱动力”,并且明确要求要“大力培育互联网金融、数据服务、数据探矿、数据化学、数据材料、数据制药等新业态,提升相关产业大数据资源的采集获取和分析利用能力,充分发掘数据资源支撑创新的潜力。”可见,大数据作为一种全新的生产资料已经得到了国家层面的认可和重视。有鉴于此,各类可以在市场或其他交易平台上交易的大数据产品,完全应当被纳入“大数据财产”的概念范畴之中。
通过对大数据来源、大数据模型和大数据产品的财产性分析,可以得知并不是所有的大数据表现形式都属于法律意义上的“财产”。只有那些同时具备管理可能性、转移可能性和客观价值性的大数据表现形式才能被称作真正意义上的“大数据财产”。具体言之,所谓“大数据财产”,是指同时满足以下两个基本条件的大数据表现形式:
其一,必须是经过合法途径收集的底层数据、清洗后的匿名化数据或者经过挖掘之后形成的大数据产品;
其二,必须能够在大数据交易平台或者其他市场上进行交易。
未经收集、转化的零散数据,作为数据收集、挖掘工具的大数据模型,以及那些虽然经过数据收集或者数据挖掘,但是不能够在市场上自由交易的大数据产品不属于法律意义上“财产”,亦应被排除于“大数据财产”的概念范畴之外。

表2 “大数据财产”的概念范畴
四、大数据财产之权利归属
在对“大数据财产”的基本范畴进行厘清后,接下来需要探讨的是“大数据财产”的权利归属问题,也即“大数据财产”及其承载的财产权利究竟属于何者的问题。对此,学界有三种不同主张:
(一)归属于数据生产者的立场
持此立场的观点认为,大数据作为一种新型的生产资料,应当在法律上专设一种财产类型即数据财产加以保护,权利的出发点应当是人而非物,因此生产数据的自然人即互联网用户应当拥有优先性的权利,法律应当承认用户个人对数据财产排他性的所有权。[40](PP.49-55)肖冬梅教授运用法经济学方法对将大数据财产权分别授予政府、数据控制者(数据商主体)与数据生产者之后的价值效果进行分析,认为只有将大数据财产授予数据生产者才是大数据权利归属的最优路径选择;同时指出,大数据财产不应该划归为公共财产或公共资源,凡是将非自有的数据用于各类商业活动,使用者均应当给数据生产者支付相应的对价,而不能无偿使用。当个人数据被其他主体使用时,数据主体有权要求使用者支付对价;当用户的数据交易给数据收集者、控制者之后,后者亦不得将原始数据公之于众,由此确保数据生产者的权利。[26](PP.69-75)
(二)归属于数据控制者的立场
与此截然对立的是将大数据财产归属于数据控制者(数据的收集者、处理者、挖掘者)的立场。该立场认为将大数据财产归属于数据生产者(用户)的主张忽视了数据控制者在大数据收集、处理、应用过程中的正当权利,使得数据控制者在每次获取、收集数据时均需要与用户进行议价,由此产生了巨大的交易成本,不利于数字经济的发展。[41](PP.131-135)大数据应当是数据控制人的财产,是信息资产的重要类型。如果将大数据财产归属于数据主体,或者作为数据主体和大数据控制人的共有财产,势必导致权利主体的混乱,大数据交易法律关系无法建立,大数据财产的经济价值也将无法实现。[16](PP.29-43)
(三)归属于公共财产的立场
除了作为数据生产者或数据控制者的私人财产,还有观点主张将大数据财产归属为一种公共财产,由政府负责管理。浙江省经济信息中心副主任、信用中心主任王宁江认为,可以由使用大数据从事营利活动的企业和平台按照固定的金额或者比例,把使用费用划拨到政府指定部门或者公共事业基金名下,这部分基金将用于公共服务事业。[42](P.44)有学者将经过挖掘的、处于应用阶段的大数据财产界定为公共财物,主张参照土地所有权制度将这一公产交由政府管理,由此防范大数据市场的各类市场失灵现象。[6](PP.30-37)
笔者认为,大数据财产应当归属于大数据的收集者、挖掘者和利用者,即数据控制者。前文中已经指出,作为大数据来源的海量零散数据本身并不具有经济价值,大数据的财产价值来源于大数据挖掘者的收集、挖掘活动。迈尔-舍恩伯格指出,在前大数据时代,一旦数据的基本用途得以实现,该数据便已经达到其利用目的,数据的价值便已经被提取完毕;而在大数据时代,数据就像是一个神奇的钻石矿,在其首要价值被挖掘之后仍然能够源源不断地产生价值。大数据的主要价值,就体现在对数据的收集、重组与二次利用上。[23](PP.135-136)举例来说,消费者在搜索引擎中输入的关键词信息,其首要价值体现在满足消费者的搜索需求上,搜索行为一经完成,消费者对该条数据的使用价值便已提取完毕,对于消费者而言该关键词便不再具有价值。但是,搜索引擎的运营商通过对全网用户的海量搜索信息的大数据挖掘,能够从中提炼出大量有价值的信息,并最终通过CCM、CRM与LBS等大数据产品应用于消费者或者直接出售,将大数据产品转化为直接的商业利益。
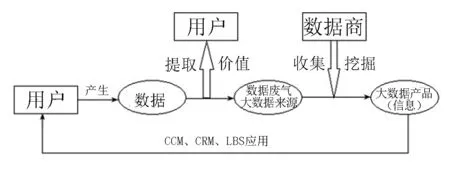
图1 大数据价值创造的流程
在这一过程中,数据挖掘者对已被用户提取过首要价值的数据(即所谓的“数据废气”)所进行的收集、挖掘与再利用,是价值创造的关键环节,也是大数据财产性的根源之所在。用户虽然是数据的产生者,是数据的主要来源,但是并不是“大数据财产”的创造者。用户对于数据所享有的利益,早在数据被首次利用时便已被其提取完毕,一旦数据满足了用户的需求(如检索关键词、提交资料、关注微信号、登录游戏等),其价值便被用户所提取,从而形成“数据废气”,除涉及隐私或公民个人信息等人身利益外,数据的生产者不再对其产生的数据享有任何财产利益。“创造价值的并不是数据本身,也不是个人,更确切地说,价值的创造是通过对数据的收集、处理和管理获得的。”[3] “大数据财产”应当归属于它的创造者,即作为数据收集者和挖掘者的数据商。这就好比用石头制作的雕像其财产权应当归属于雕刻家,而非石头的所有人;用黏土烧制的陶器属于烧陶者所有,而非产出黏土的土地的所有人;价值连城的油画当然是画家拥有的财产,并不属于画布厂、颜料厂和制笔厂中的任何一方。正如苏今博士所指出的那样,数据本身并不具有财产权利赋权的正当性,数据之所以成为财产主要是基于数据控制者通过大数据挖掘等技术手段将数据“关系化”为信息,在这一过程中数据的价值得到了添附,使“数据”变成“大数据”,据此成为数据赋权的基础。劳动赋权理论是将大数据财产归属于数据控制者的理论基础。“在促进数据开放的同时,对能够提升数据价值的市场主体赋予一定的财产性补偿是大数据时代平衡公私利益的唯一途径。”[43]
一言以蔽之,财富应当属于其创造者。大数据的收集者、挖掘者和控制者,才是大数据财产的真正归属。
五、大数据财产的保护路径之探讨
前文主要就“大数据”和“大数据财产”的概念范围及权利归属等问题进行了探讨。如上所述,“大数据财产”是大数据收集、挖掘、应用过程中具有管理可能性、客观经济价值和转移可能性的大数据表现形式,包括经过收集的大数据来源、清洗过的匿名化数据和能够用于商业应用的大数据产品,大数据财产的权利应当归属于大数据价值的创造者即大数据的收集者和挖掘者。接下来需要探讨的是如何对大数据财产及其权利人进行保护的问题,也即大数据财产保护的路径选择问题。对此,学界存在如下几种不同主张:
(一)物权保护路径
鉴于大数据的财产属性正在获得社会的普遍认可,主张依照物权制度对大数据财产加以保护的呼声也随之高涨。有学者指出,对大数据财产采取债权保护路径将会带来显著的负外部性后果,形成数据壁垒,导致数据垄断和不正当竞争的产生;而知识产权制度的登记与公示程序势必大大降低数据流通的速度,对大数据交易和开发形成阻碍。相比之下,若将大数据财产解释为一种无体物,则直接可以融入现有的物权法律体系,从而更容易被立法者接受,需要克服的制度阻碍最小。物权的占有、使用、收益、处分四大权能恰巧对应大数据的收集、储存、挖掘、利用和交易等流程,将大数据财产作为一种“物”进行保护并不存在任何法律或者事实上的障碍。[6](PP.30-37)依照物权化的保护路径,虽然以互联网数据与传统现实物理社会的财产存在形式差异,却具备传统财产的实质内容[44],故此对于侵犯大数据财产的行为可以依照财产犯罪的有关规定处理。
(二)债权保护路径
若依照物权保护路径将“大数据财产”视为一种“物”,则大数据交易合同便属买卖合同,买卖双方就大数据财产这一标的交易其所有权。对此持不同见解的观点认为,权利人对大数据的请求权并非物权而是一种债权,大数据交易合同应当是一种数据服务合同而非买卖合同。买方通过支付对价,获得要求大数据服务商提供大数据服务的请求权,大数据交易应当被视为一种服务提供行为继而适用服务合同而非买卖合同的相关规定。[45]根据债权保护路径的立场,所谓“大数据财产”归根结底是一种服务而非财物,侵害大数据财产的行为不应以财产犯罪论处。
(三)知识产权路径
虽然大数据具有财产性,可以被视为一种“财产”,但是大数据财产毕竟不同于传统的物理性财产。传统的物理性财产一般是排他的、独占性的,并且在使用之后其价值会发生贬损,无法被更新。[46](PP.1-19)而大数据财产并不会因使用消耗而减少其本身的价值,不管大数据财产被如何重复使用,该大数据财产仍然能够保持原状。[47]这一特征使部分学者对大数据财产的物权保护路径产生质疑,并主张引入知识产权的保护规则以契合大数据财产的非独占性、非损耗性特征。龙卫球教授认为,在大数据法律关系中,对于数据经营者(企业)应分别配置大数据资产权与大数据经营权,其中大数据资产权与工业知识产权有一定的相似性。[37]另有学者指出,虽然大数据财产与传统的著作权保护客体在形式上存在较大差异,但在财产性利益等方面保持了高度的相通性。因而,对于该类作品的知识产权保护在刑事法领域理应有所评价。[48]至于具体的保护路径,不同主张之间则存在些许差异:有观点主张,应当以是否具有独创性作为标准,将独创性的大数据信息纳入著作权法进行保护,不具有独创性的则适用反不正当竞争法进行保护。[49]而一些实务界人士则认为,对于有独创性的大数据财产和数据集合产生著作权,不具有独创性的数据库可以产生邻接权,二者均应纳入知识产权法的保护范围。[50]另有观点则主张不论是否具有独创性,均应以邻接权来对大数据财产进行保护。[51]
(四)新型权利路径
物权、债权与知识产权的保护路径均立足于当前的法律规定,试图将“大数据财产”纳入已有的权利保护体系之中,借此减少这一新的财产类型对现有制度体系的冲击,降低新设立法的成本。当然,也有不少学者认为大数据财产作为一种全新类型的财产,与现有的权利制度难以兼容,故此需要通过创设新的立法对大数据财产予以专门化的保护。“大数据作为一种财产客体,应当在财产权体系中进行定位。但通过其与物权客体、债权客体以及知识产权客体的辨析,在理论上很难将大数据栖身于传统财产权的体系之中。那么就必须针对这种新类型的客体重新进行定位,应当确立新的大数据权利类型。”[45]持新型权利路径的学者认为,与大数据财产有关的权利具有被列入法律权利清单的资格,主张先分别在民法和行政法中将其明确为一项区别于其他权利的新兴权利,在经过民法和行政法的实践检验和立法修正后,可以进一步将此种权利确立为宪法上的一项基本权利。[52]在刑法领域,应当对现有的网络法益进行扩容,对互联网犯罪的行为内容进行重组并对定罪量刑体系进行重构,尽快在刑法中确立“大数据法益”[53],在此基础上增设“非法获取网络数据罪”“非法获取数据罪”等罪名,最终形成完整的大数据罪名体系。[5]
(五)技术保护路径
另有学者对当前学界存在的对数据权益保护过度化之趋势进行了批判,认为“将刑法作为社会管理法,是法治无能的表现”[54],主张立法特别是刑法应当保持谦抑,尽量避免介入大数据的开发、利用、流通和交易之中,大数据作为一种全新的技术趋向,应当通过技术手段加以保护,法律保护不应过度介入、越俎代庖,通过技术自身能够施加有效保护的法益不应求助于刑法。在大数据财产保护的路径选择上,应当坚持法律规制下的技术主导型保护模式,技术保护优位于法律保护。[55]
对于以上几种观点,笔者认为,首先,纯粹的技术保护路径并不可取。在互联网时代,技术保护手段在多数情况下是颇显乏力的,以大数据背景下公民个人隐私的保护为例,虽然可以通过匿名化手段对原始数据中的身份信息、隐私信息与敏感信息进行清洗或模糊化处理,但是非法的数据挖掘者仍然可以通过数据组合以及互联网上海量的公开数据对已经清洗过的数据进行重新识别,轻易绕开匿名化等技术性保护措施。迈尔-舍恩伯格在《大数据时代》一书中提到一个非常著名的实例:2006年,美国在线(AOL)从65.7万用户的2000万条搜索查询记录形成的数据库中(这些数据库是经过精心的匿名化处理的,用户的名称和地址等个人信息都使用了特殊的数字符号进行替代),凭借“60岁单身男性”“有益健康的茶叶”“利尔本的园丁”等几条搜索信息,确定代号为4417749的用户是佐治亚州利尔本一名62岁的寡妇Thelma Arnold。找到这位妇女后,老人惊叹道:“天呐!我真的没想到一直有人在监视我的私人生活。”[23](P.198)哈佛大学的一项研究则显示,对于经过匿名化处理的数据,仅凭一个人的年龄、性别和邮政编码这三条信息就可以结合其他公开的网络数据库识别出此人87%的个人信息。[11]长期从事反匿名问题(即通过技术手段从匿名化数据中挖掘出用户的真实身份)研究的科罗拉多大学法学院欧姆·保罗(Ohm Paul)教授认为,针对当前的反匿名行为,现在还没有很好的技术手段加以防范。[56](P.1702)诚如美国加州大学戴维斯分校的伊丽莎白·E·乔伊教授所言:“以技术手段解决犯罪问题并不是民主政策的终极目标。”[57](PP.35-68)正是由于技术保护路径存在现实的局限性,虽然当下各个公司、企业、政府部门业已通过杀毒软件、内网安全系统以及专业的互联网安保服务等技术手段对本单位的系统数据层层设防,刑法仍然设置了非法侵入计算机信息系统罪、非法获取计算机信息系统数据和非法控制计算机信息系统罪等罪名对各种数据法益施以法律保护。由此可见,仅凭技术保护措施,在大数据时代根本无法实现对各种法益的有效保护,对大数据财产采取纯粹的技术保护路径并不可取。
其次,新型权利类型的专门化保护路径同样值得商榷。鉴于新设立法的周期长、成本高,且会对法律本身的稳定性与权威性造成负面影响,因此每当出现新问题时,主流观点往往倾向于通过法律解释实现对社会发展的回应,尽量避免对法律的修改与创设。例如,陈兴良教授指出:“既然信仰法律,就不要随意批评法律,不要随意主张修改法律,而应当对法律进行合理的解释,将‘不理想’的法律条文解释为‘理想’的法律规定。”[58](P.7)张明楷教授亦指出,修改、增设法律的成本太高,远不及解释法律简便,批判法律本身的做法不利于维护法律的权威性,即使通过批判提出了新的立法建议,也未必能够及时解决司法实践中的现实性问题。[59](P.24)鉴于当前大数据法益的保护需求远未达到必须通过创设专门法律进行保护的程度,在穷尽现有的民事、行政和刑事救济途径之前,不宜频繁地改动或增设相关的立法规定,新型权利说所倡导的专门化立法的保护路径实无必要。
再者,债权保护路径的主张混淆了大数据服务与大数据财产之间的区别。诚然,当前有很多企业通过签订协议的方式向咨询机构或者专业的大数据服务公司购买包括数据挖掘、商业咨询、可视化展示在内的各类数据服务,但是单纯的数据服务模式并不能概括大数据财产的全部利用方式。在大数据时代,数据越来越多地被当作一种独立的商品参与交易,而不仅仅是提供数据服务的工具。例如,美国四大机票预订系统之一的ITASoftware为Farecast公司进行预测,提供其所需要的原始数据,而它自己并不提供航班和票价预测服务;西班牙电话公司(Telefonica of Spain)也创立了独立的子公司Telefonica Digital Insights,专门向各种数据零售商和其他买家出售其收集的匿名化用户位置信息。[23](PP.162-163)在世界各地,从事大数据财产交易的平台和企业如雨后春笋般涌现。美国的Hitwise公司通过与一些互联网公司合作,将其掌握的大数据财产转卖给其他有需要的公司,从中赚取差价,而Hitwise本身并不提供数据挖掘与分析服务;2008年冰岛成立的DataMarket向人们提供其他机构(联合国、世界银行、欧盟统计局)的免费数据集,靠倒卖商业供应商(如市场研究公司)的大数据来获利;2013年4月,日本建立了自己的大数据交易市场“Data Plaza”,Data Plaza 交易的数据为清洗后的非底层数据,包括购物网站的购物记录、智能手机的位置信息等个人数据和其他类型数据。[16]有些互联网公司甚至会将自己记录、掌握的大数据来源雪藏起来,拒绝与他人共享。[23](PP.169-172)如果将大数据财产的利用与开发仅仅视为一种单纯的服务形式,就会忽略大数据财产所具有的独立商业价值,不利于保护大数据财产的持有者、销售者和独占者的权利,无法对围绕大数据产业形成的多种类型的法律关系形成周延的保护。有鉴于此,债权的保护路径应当被否定。
最后,根据现行立法的相关规定,大数据财产并不能被纳入知识产权概念范畴之中。作为一种数据集合,大数据财产显然不属于商业标识,因此无法作为商标权对其进行保护,而根据《专利法》第2条的规定,专利法保护的对象仅限于发明、实用新型和外观设计,大数据财产也难列其中,因此多数学者主张将大数据上附着的财产权利作为一种著作权或者邻接权加以保护。(10)参见龙卫球《数据新型财产权构建及其体系研究》,《政法论坛》,2017年第4期;王渊、黄道丽、杨松儒《数据权的权利性质及其归属研究》,《科技管理研究》,2017年第5期;秦珂《大数据法律保护摭谈》,《图书馆学研究》,2015年第12期;芮文彪、李国泉、杨馥宇《数据信息的知识产权保护模式探析》,《电子知识产权》,2015年第4期。根据《著作权法》第3条以及刑法第217条的规定,著作权的权利对象必须是“作品”。因此,大数据财产能否适用知识产权路径进行保护的关键,在于“大数据财产”能否被认定为法律意义上的“作品”。在《著作权法》第3条列举的9种“作品”类型之中,与大数据财产最为接近的概念为第(8)项“计算机软件”。(11)根据《著作权法》第3条的规定,作品,包括以下列形式创作的文学、艺术和自然科学、社会科学、工程技术等作品:(1)文字作品;(2)口述作品;(3)音乐、戏剧、曲艺、舞蹈、杂技艺术作品;(4)美术、建筑作品;(5)摄影作品;(6)电影作品和以类似摄制电影的方法创作的作品;(7)工程设计图、产品设计图、地图、示意图等图形作品和模型作品;(8)计算机软件;(9)法律、行政法规规定的其他作品。若能将大数据财产解释为“计算机软件”,则可以将侵犯大数据财产的行为认定为侵犯著作权罪;反之则不能。那么,“大数据财产”是否属于著作权法意义上的“计算机软件”呢?答案是否定的。根据国务院《计算机软件保护条例》的规定,“计算机软件”特指计算机程序及其有关文档。(12)参见《计算机软件保护条例》第2条。计算机程序是一种代码化的指令序列,而文档则特指程序的说明书、流程图和相关的文字资料等(13)参见《计算机软件保护条例》第3条规定,计算机程序“是指为了得到某种结果而可以由计算机等具有信息处理能力的装置执行的代码化指令序列,或者可以被自动转换成代码化指令序列的符号化指令序列或者符号化语句序列”。文档“是指用来描述程序的内容、组成、设计、功能规格、开发情况、测试结果及使用方法的文字资料和图表等,如程序设计说明书、流程图、用户手册等”。,作为程序处理对象的各类静态数据和互联网数据本身并不在“计算机软件”的概念范畴之中。可见,著作权法中规定的“计算机软件”作品专指计算机程序以及程序附属文档,并不包括作为程序处理对象的数据。具体到大数据挖掘流程中,学习模型以及基于学习模型而形成的知识模型应属于计算机程序,而收集后的底层数据、清洗后的匿名化数据以及挖掘后的大数据产品均不属于“计算机程序”之范畴。申言之,以数据为载体的大数据财产并不属于“计算机软件”,亦不属于著作权法意义上的“作品”,故此对大数据财产不能适用知识产权路径加以保护。
综上所述,对于大数据财产而言,债权、技术或知识产权的保护路径囿于各自的特征或制度局限性,很难对所有类型的大数据财产施以全方位的保护;而将大数据财产作为一种新型权利的专门化保护路径则面临着高昂的立法成本,并且会对法律体系的稳定性造成一定影响;因此,将大数据财产视为一种“物”纳入现行法律体系的物权保护路径更为可取。具体说来,物权的保护路径至少存在三个方面的优势。其一,物权的保护路径突出了大数据作为一种财产的独立意义,更有利于维护大数据收集者和大数据挖掘者的权利。若将大数据财产仅仅视为一种服务合同约定的债权来加以保护,也就意味着那些没有数据服务合同基础的大数据财产将被排斥于法律保护的范围之外,由大数据挖掘者自行收集、挖掘的大数据财产将处于巨大的风险之中。至于纯粹的技术保护路径对大数据财产的保护则更加孱弱,只要行为人掌握一定的技术手段即可肆意对大数据财产进行侵害而无需承担任何法律责任。相比之下,物权的保护路径能够对大数据财产给予更加有力的保护。其二,从交易与流转方式来看,大数据财产能与现有的物权制度进行有效的衔接,需要克服的制度成本较小,不仅物权的占有、使用、收益和处分等权能能够与大数据财产的存储、挖掘、应用、交易等活动一一对应[6](PP.30-37),并且大数据财产往往通过大数据交易中心或者平台进行交易,可以比照物权的登记公示制度提升交易的安全性与可信度,从而强化对大数据财产权利人的保护。其三,作为一种新型的生产资料,大数据财产同时具备管理可能性、客观价值性与转移可能性,符合《刑法》第92条第1项之规定,完全可以被认定为刑法意义上的“财产”。故而将之进一步认定为民法意义上的“物”并且适用物权保护路径,符合法秩序统一原则的要求。对此,有学者指出,我国刑法中“财产”的概念与民法和物权法中的财产概念具有一定的渊源关系,民法体系中物的概念对于刑法中“财产”“财物”等概念的构建颇具参考意义。[60](PP.79-88)虽然大数据财产与物理空间中的财产存在形式上的差异,却具备传统财产的实质内容[44],依照物权路径对大数据财产进行规制和保护是当前背景下的最优选择。
