面向格基密码体制的高效硬件实现研究综述*
2021-03-03何诗洋李凤华
何诗洋, 李 晖, 李凤华,3
1. 大数据安全教育部工程研究中心, 西安 710126
2. 西安电子科技大学网络与信息安全学院, 西安 710126
3. 中国科学院信息工程研究所, 北京 100093
1 引言
随着人类计算能力的迅速提升, 特别是量子计算机的不断突破(如中国科技大学潘建伟科研团队构建量子计算原型机“九章”[1]等), 基于大质因数分解、离散对数困难问题的传统密码体制, 如公钥加密、数字签名、密钥交换等方案的安全性都将面临巨大威胁和挑战[2]. 这种威胁和挑战一方面体现在计算能力增强导致暴力破解成功率提升, 另一方面, 量子计算机和量子算法[3,4]能够在多项式时间内解决传统密码体制依赖的困难问题.
面对这一严峻形势, 研究后量子密码(post-quantum cryptography, PQC) 显得极为紧迫和重要. 目前, 能够抵抗量子攻击的主流密码体制有[5]: 基于编码的密码体制(code-base cryptography)、基于哈希函数的密码体制(hash-based cryptography)、基于格的密码体制(lattice-based cryptography)、多变量密码体制(multivariate cryptography) 等.
相较于其他后量子密码体制, 基于格的密码体制具有明显优势. 主要体现在: 第一, Ajtai 等人[6,7]证明了格中某些平均情况下的困难问题与NP 困难问题的难度等价, 具有较强的安全性[8]. 第二, 基于格的密码体制不仅能够应用于传统的安全场景如哈希函数[9]、公钥加密[10]、数字签名[11]、密钥交换[12]等, 而且还具有良好的同态特性[13–15]. 第三, 基于格的密码体制主要涉及矩阵向量之间的运算, 易于计算和实现. 第四, 基于格的密码体制与硬件实现相结合, 可部署场景广泛, 既可应用于资源丰富的平台, 如云平台、服务器平台; 也可应用于资源受限的平台, 如穿戴医疗、移动设备等, 为它们提供强力的安全保障[16,17].
美国国家标准与技术研究院(National Institute of Standards and Technology, NIST) 自2016 年12月开始面向全球公开征集并制定后量子密码算法[18], 包括公钥密码(密钥交换) 算法、数字签名等. 截止2017 年12 月, 共收到76 份提交的后量子密码算法申请, 经过第一轮筛选, 共有69 个后量子密码算法晋级下一轮候选[19]. 2019 年1 月, NIST 进一步精选了26 个后量子密码算法进入第二轮候选[20]. 在前两轮中, 基于格理论的后量子密码算法占比约38% 和46%. 2020 年7 月, NIST 经过综合对比筛选了包括CLASSIC MCELIECE、CRYSTALS-KYBER、NTRU、SABER 等4 个公钥密码(密钥交换) 算法与CRYSTALS-DILITHIUM、FALCON、RAINBOW 等3 个数字签名算法进入第三轮[21]. 在这4 个公钥密码(密钥交换) 算法中, CRYSTALS-KYBER、NTRU、SABER 等3 个算法都是基于格理论的密码算法, 而在数字签名的3 个算法中, CRYSTALS-DILITHIUM、FALCON 等2 个算法是基于格理论的密码算法. 在所有候选算法中, 基于格理论的后量子密码算法在数量上占优.
基于格理论的后量子密码体制易于硬件高效实现, 主要原因如下: 第一, 基于理想格构造的格基密码体制涉及大量多项式计算, 在硬件上多项式运算可以使用高效快速算法, 如快速傅里叶变换(fast Fourier transform, FFT) 和数论变换(number theoretic transform, NTT) 算法, 在硬件上实现快速算法能够极大提高格基密码方案的吞吐量. 在文献[22] 中, 同样使用硬件, 实现格基数字签名不但比实现RSA 签名速度更快而且资源消耗更少. 在文献[23] 中, 在同等安全等级下, 硬件实现格基公钥加密速度比ECC、RSA 快一个数量级, 而且资源消耗更少. 第二, 与软件相比, 硬件具有高效并行处理这一独特优势, 能够快速处理密码算法中的复杂计算, 吞吐量高. 在文献[9] 中, 采用全并行架构实现基于格的哈希函数算法, 吞吐量能够达到0.6 GB/s, 约是软件实现的16 倍. 第三, 出色的权衡性能. 硬件实现可以根据使用场景的不同, 在性能、资源消耗、功耗等方面进行权衡, 使格基密码方案既可以部署在资源丰富的平台如服务器平台、云平台等; 也可以部署在资源受限的平台如物联网平台、穿戴医疗平台、移动设备平台等.
目前, 面向格基密码体制的高效硬件实现是当前研究的热点, 有大量的研究成果和文献, 但是缺乏系统性的总结和比较. 本文简要介绍了格的基本概念以及格上的困难问题; 探讨了格基密码体制的主要优势以及其在公钥加密、数字签名、密钥交换等方面的应用价值; 在硬件实现格基密码的模块设计架构中, 本文针对离散高斯采样器、多项式乘法器这两大主要模块的主流优化技术和实现方法进行了调研、总结和比较; 在硬件实现格基密码的整体架构中, 本文围绕格基密码在不同场景下的应用、不同的硬件优化目的(面向性能/面向资源) 等方面, 详细分析和对比了当前先进的设计理念和优化技术; 最后, 本文从安全性、灵活性、资源消耗、吞吐量等角度, 将格基密码体制在硬件上的实现情况与其它实现方法进行对比分析, 充分展现其在实际应用中的高效性和实用性, 为后量子密码体制标准的制定以及后续格基密码体制在实践、应用等方面的优化和改进提供重要参考.
本文的剩余部分结构如下, 第2 节重点介绍格的基础知识, 格上的困难问题以及基于格的公钥加密、数字签名、密钥交换方案在硬件中实现现状; 第3 节重点介绍格基密码方案硬件实现中的重要组成模块离散高斯采样器, 归纳和对比拒绝采样算法、Ziggurat 采样算法、积累分布表(cumulative distribution table, CDT) 采样算法、伯努利采样算法、Knuth-Yao 采样算法、二项采样算法等在硬件应用中的特点和优劣; 第4 节重点介绍格基密码方案硬件实现中的重要组成模块多项式乘法器, 讨论了Schoolbook multiplication 算法和NTT 算法在不同应用场景和优化模式下的性能和资源消耗情况; 第5 节重点介绍了基于格的公钥加密、数字签名、密钥交换方案在不同优化模式、应用场景下的架构设计, 并分析它们的性能表现、资源消耗等; 第6 节对全文进行了简要总结.
2 基础知识
本节主要介绍格上的相关定义、困难问题以及硬件实现格基密码体制的现状, 以下是本文用到的主要符号定义.

2.1 格的定义
设ν1,ν2,··· ,νn ∈Rm为一组线性无关向量, 格L是由向量ν1,ν2,··· ,νn的线性组合构成的向量集合, 即:L={a1ν1+a2ν2+···+anνn:a1,a2,··· ,an ∈Z}. 任意一组可以生成格的线性无关向量称为格的基, 基中的向量个数称为格的维数.
2.2 循环格
向量v=(ν1,ν2,··· ,νn)T的一次循环记为rot(v)=(νn,ν1,··· ,νn-1)T, 若对格L和∀v ∈L, 都有rot(v)∈L, 则格L是循环格. 2002 年, Micciancio[24]首次提出了循环格的概念, 主要目的是用于缓解格基密码体制中密钥尺寸过大、运算效率较低等问题.
2.3 理想格
理想格是所有格向量的集合构成某种环的一个理想. 设环R=Zq[X]/f(X), 其中f(X) =Xn+fn-1Xn-1+···+f0∈Z[X], 且f(X) 是n阶首一不可约多项式. 相较于循环格, 理想格可以通过选择适当的f(X) 来控制格向量的长度, 在格基密码体制中常用的f(X) 为:Xn+1, 其中n为2 的幂.在环Zq[X]/(Xn+1) 上构造的理想格是目前实现硬件快速算法的最佳选择. 2006 年, Lyubashevsky 和Micciancio[25]首次提出理想格的概念, 理想格能够有效降低格基密码中密钥的空间占用, 利于构造基于格的密码方案; 同时理想格对内具有乘法封闭性, 对外具有乘法吸收性, 这种优势还有利于构造全同态加密方案.
2.4 格上的困难问题
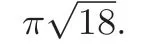
格上困难问题的主要形式是找出满足某种最小特征的格向量,最经典的格难题是最短向量问题(SVP)和最近向量问题(CVP)[27]. Ajtai 等人[6,7]证明了最短向量问题(SVP) 在随机归约下是NP 困难问题,随后CVP 问题也被证明是NP 困难问题. 如表1 所示,围绕这两个格上的经典难题,学者进行了充分研究,通过问题规约等方法提出了一些新的格上的近似困难问题(更加利于密码方案的构造),如LWE(RLWE)、SIS (RSIS) 问题等. 目前, 大多数格基密码体制的安全保障都是基于LWE (RLWE)、SIS (RSIS) 困难问题[25,28,29].

表1 格上的困难问题Table 1 Lattice problem
2.5 硬件实现格基密码体制现状
2005 年,Regev 等人[30]提出LWE 问题,并将解决该问题的困难程度规约到最坏情况下的格难题,同时给出了基于LWE 问题的公钥加密方案. 以此为基础, 随后很多学者相继提出了该方案的改进型[31,32],进一步提升了格基公钥加密方案的效率和安全性. 由于基于LWE 问题设计的密码方案产生的密钥和密文膨胀开销过大(达到兆字节级), 计算效率低, 很难在实际中应用. Lindner 和Peikert[33]基于理想格的思想, 提出了环上的LWE 问题, 并给出了基于RLWE 问题的格基公钥加密方案, 该方案的密钥和密文尺寸与基于LWE 问题的方案相比, 下降为原来的1/n, 在硬件实现中极大降低了内存资源占用. 不仅如此, 在理想格结构上, 硬件实现还可以部署快速算法如FFT、NTT 等, 进一步提高运算效率.
在格基数字签名方面. 早期的格基数字签名基于公钥密码方案修正而来, 缺乏安全证明, 比如NTRU数字签名[34,35]提出不久后, 就被Nguyen 和Regev[36]破解. 直到2008 年, 第一个可证明安全的格基数字签名由Gentry 等人[37]提出, 但是该方案产生的密钥尺寸过大, 达到兆字节级, 效率很低. 随后,Lyubashevsky[38,39]基于RSIS 问题构造了一个较为成熟的签名方案, 降低了密钥和签名尺寸. 以此为基础, Güneysu 等人[22]、Pöppelmann 等人[11]结合硬件特点, 构造了新的格基签名方案, 进一步降低密钥和签名尺寸, 提升了签名效率.
在格基密钥交换方面. 格基密钥交换主要是基于协商或加密两种方法实现[40]. Ding 等人[41]提出了第一个基于协商的格基密钥交换方案, 随后, 大量的基于协商的格基密钥交换方案被学者提出,如Frodo[42]、BCNS[43]、NewHope[12]、Kyber[44]等. 基于加密的格基密钥交换方案有NewHope-Simple[12], 与前者相比基于加密的方案比基于协商的方案占用更多带宽[45].
3 格基密码在硬件实现中的采样器模块
采样在格基密码方案中扮演着重要角色, 它不仅关系到整个格密码方案的安全性, 而且它的运行效率直接影响整个密码方案的性能. 在格基密码方案中, 采样通常来自均匀分布或离散高斯分布. 其中离散高斯采样在格基密码方案中应用最为广泛且具有众多优势, 主要体现在, 利用离散高斯采样能够有效减小格基密码方案中密文、签名的尺寸, 通过在明文上加减离散高斯采样噪声来隐藏或恢复明文. 同样离散高斯采样也是硬件实现中的难点[46], 它的实现较为复杂, 主要体现在高精度的计算要求、大量随机数和大尺寸查找表的需求以及高质量统计距离的要求等, 迄今为止没有任何计算可以获得完美的离散高斯分布, 因此采样器在设计的过程中要兼顾安全性、效率、资源消耗等因素, 使实际采样精度与离散高斯分布尽可能相近. 除此之外, 在离散高斯采样器实现的过程中还要考虑到时钟循环信息泄漏的情况, 敌手会利用时钟循环泄漏的信息对采样器进行攻击, 从而影响整个格基密码方案的安全性[47]. NIST 在公开征求加密和签名的方案中明确强调, 方案中所采用的离散高斯采样器必须能够抵抗边信道攻击(side-channel analysis,SCA)[48]. 通常我们使用具有固定时钟循环消耗的采样器和随机洗牌采样器[49]应对边信道攻击.
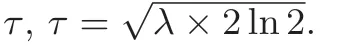

3.1 拒绝采样
拒绝采样算法首先从x ∈{-τσ,··· ,τσ}中均匀随机采样, 随后采样值x以概率exp(-x2/2σ2) 被接收. 拒绝采样算法简单直观, 不需要预计算积累分布存储表, 它是第一个被提出用于格基密码方案的离散高斯采样算法[37]. 由于拒绝采样算法需要消耗大量硬件资源去计算e 的幂函数, 同时还涉及浮点数的运算, 而且拒绝率高, 采样成功率低, 所以拒绝采样在格基密码的硬件实现中很少直接使用. 在软件实现中, Norman 等人[10]采用了文献[37] 中的拒绝采样算法, 采样成功率仅有20%. 作者还利用了Devroye等人[52]提出的优化拒绝采样算法, 使采样成功接收率提高至85.2%, 每产生108个采样所消耗的时间由75 秒降至19 秒.
3.2 Ziggurat 采样
Ziggurat 采样一开始主要用于连续型高斯采样[53], Buchman 等人[54]对该采样进行了改进, 并应用于离散高斯采样中. Ziggurat 采样首先生成多个自上而下面积相等的相邻矩形, 以y轴为矩形的左边, 矩形的右下角在高斯分布函数上, 并将该矩形右下角的坐标(xi,yi) 存入数据表中. 采样时, 在多个矩形中均匀随机采样, 随后在被采样的矩形中继续随机均匀采样得到采样值x, 如果x的值小于等于相邻上方矩形右下角横坐标的值, 直接接收, 否则计算e 的幂函数决定是否接收(与拒绝采样原理类似). 由于绝大部分采样值小于上方相邻矩阵的横坐标, 无需计算e 的幂函数进行比较, 可以直接接收, 相比于普通的拒绝采样算法, 极大地提高了采样接收率, 进而提升了采样效率. 在硬件实现方面, 与其他采样算法相比,Ziggurat 采样算法资源消耗大, 采样速度低, 产生合适的矩形采样需要大量乘法迭代等复杂运算[55], 在面向硬件实现的实际应用中并不常见.
3.3 积累分布表采样
积累分布表采样由Peikert[56]首次提出, 该采样算法需要提前计算离散高斯分布Pz ∈Pr(x≤z;x ←Dσ), 并将计算好的Pz存入积累分布表中, 由于该分布关于y轴对称, 取z ∈[0,τδ], 可节省一半存储空间, 一般需要的存储空间约为τσλbits. 采样时, 以λbits 的精度从y ∈[0,1) 中均匀随机采样(在硬件实现中,y使用小数的二进制表示), 从b ∈{0,1}中均匀随机采样, 得到采样y,b后, 使用比较器, 在积累分布表中查找y ∈[Pz-1,Pz], 取出对应的z, 输出采样值(-1)bz完成采样. 积累分布表采样算法避免了e 的幂函数和浮点数运算, 提高了计算效率, 但是由于引入了积累分布表, 需要耗费大量存储空间进行存储.

3.4 伯努利采样
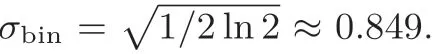
3.5 Knuth-Yao 采样
Knuth-Yao 采样算法[59]基于离散分布生成树(discrete distribution generating, DDG), 在概率矩阵中采用二叉树随机游走的方式完成采样. 其中概率矩阵是由分布概率P1,P2,··· ,Pn和精度系数λ组成的二进制矩阵. 离散分布生成树根据概率矩阵生成, 它包含2 种节点, 分别是内部节点(internal node)和末端节点(terminal node), 内部节点下有2 个子节点, 末端节点下没有子节点. 在概率矩阵中, 每一列的非零元素个数等于末端节点数, 零元素个数等于内部节点数. 进行采样时, 从离散分布生成树树顶部开始随机向下面2 个子节点游走, 当走到内部节点时继续随机游走, 当走到末端节点时停止游走, 并输出采样结果. 从信息论角度分析, 该方案近乎完美, 它需要的随机输入bits 只比分布的熵大2, 可以用较少的随机bits 输入完成离散高斯采样, 该方案适用于高精度采样. Roy 等人[60]首次利用硬件构造Knuth-Yao采样器, 作者针对离散分布生成树的结构进行了优化, 在采样前, 并不存储整个离散分布生成树, 而是在采样过程中, 利用观察节点和最右边内部节点的距离d实时构建当前层的树结构, 这样做可以节省计算资源和存储开销. 在概率矩阵存储方面, 概率矩阵按列存储, 且只存储每一列中不同的元素, 通过优化存取算法降低内存消耗. 针对概率矩阵读取扫描, 作者提出了两种优化方案, 分别是基于省略跳过的扫描方法和基于窗口的扫描方法, 两者都可以提升扫描效率, 前者需要增加额外的存储空间和移位器, 后者需要增加额外的乘法器. 该方案在Virtex-5 上实现, 每完成一次采样平均需要约5 个随机bits 和17 个时钟循环.随后Roy 等人[49]进一步优化了Knuth-Yao 采样器, 在面向资源节约型的硬件设计中, 作者通过约减只读存储器(read only memory, ROM) 的位宽和扫描寄存器来降低资源消耗, 与文献[60] 相比减少17 个SLICEs 消耗; 在面向性能提升的硬件设计中, 作者利用专用的查找表存储随机bits 的初始位与采样点的映射关系, 将采样所需的时钟循环次数由平均17 次降低为平均约2.5 次, 大幅度提升采样性能; 在面向采样器安全性的硬件设计中, 由于Knuth-Yao 算法在随机游走时, 时钟循环消耗不固定, 容易受到边信道攻击, 作者采用随机洗牌法去除采样中的时钟循环信息, 保证采样器安全.
3.6 二项采样
二项采样算法的硬件实现相对简单, 首先从均匀分布中随机获取两个k-bits 的向量, 随后计算两个向量的汉明距离并做差, 所获得的采样值即服从二项分布. 在一些格基密码方案中, 如NewHope 等, 已经开始使用二项分布(k= 2σ2) 替代离散高斯分布(exp(-x2/2σ2)). 文献[12] 指出, 这样的采样分布替代不仅不会严重影响密码系统的安全性, 使用二项分布采样还具有避免e 幂函数的计算、不需要存储表避免内存占用、时钟循环消耗固定能够抵抗边信道攻击等优势. 由于k= 2σ2, 二项采样不适用于对标准差要求较大的格基密码方案, 例如数字签名方案等. Oder 等人[61]在设计的二项采样器硬件架构中使用Trivium PRNG[11]随机数生成器, 每个时钟循环可获得1 个随机bit, 当二项分布k= 16 时, 完成一次采样需要33 个时钟循环.
普通拒绝采样器原理简单直观, 易于实现, 由于涉及到复杂运算(e 的幂函数), 且拒绝率高等劣势, 在硬件实现中很少直接使用. Ziggurat 采样器在拒绝采样的基础上进行了优化, 大幅度减少了e 的幂函数计算(但并没有消除), 提高了采样成功率, 但是该算法资源消耗大, 采样速率低, 在硬件实现中也并不多见. 根据表2 不难看出, 积累分布表采样器能有效避免e 幂函数复杂计算, 采样速度快, 但是由于引入了积累分布表, 增加了随机存取存储器(random access memory, RAM) 消耗. 在面向窄带离散高斯分布采样中, Pöppelmann[23]、Du 等人[57]对积累分布表采样器进行优化, 综合考虑性能和资源消耗, 与其他采样器相比, 积累分布表采样器性能突出. 在面向大标准差离散高斯分布采样中, Pöppelmann 等人[11]利用Peikert[56]卷积定理和Kullback-Leibler 散度定理, 对采样器进行优化, 在格基BLISS 数字签名方案中,与伯努利采样器相比, 积累分布表采样器在吞吐量/资源消耗方面比伯努利采样器性能更好. 伯努利采样器通过按位采样避免了e 的幂函数复杂运算,降低了资源消耗,结合二进制高斯分布,伯努利采样器同样可以用于大标准差离散高斯分布采样, 在众多采样器中, 该采样器需要的积累分布表尺寸最小. Knuth-Yao采样器硬件资源消耗小, 采样效率高, 采样所需的随机bits 输入数量接近于分布的熵, 与其他采样器相比需要的随机bits 数最少, 但是该采样器只适合用于面向窄带离散高斯分布采样, 不适合用于对离散高斯分布标准差要求较大的数字签名方案.
4 格基密码在硬件实现中的多项式乘法模块
正如上文所述, 在众多格基密码方案中, 基于标准格的密码方案由于涉及大量的复杂矩阵向量乘法、密钥尺寸过大等问题, 资源消耗巨大, 并不适合硬件实现. 而基于理想格的格基密码方案, 在保证安全性的同时, 兼顾了计算效率和密钥尺寸, 易于硬件实现. 在理想格上, 格基密码方案的计算主要是基于多项式环Rq=Zq[X]/(Xn+1)(通常情况下n是2 的幂,q是素数) 开展, 主要涉及多项式环Rq上的加/减法、乘法、模约减等, 其中加/减法的计算复杂度是O(n), 朴素乘法的计算复杂度为O(n2), 随着多项式阶n的不断增大, 多项式乘法运算会变得非常复杂. 在硬件实现格基密码方案的整个架构中, 多项式乘法部分是最耗时、最耗资源的模块. 基于理想格的格基密码方案中最常用的多项式乘法算法是Schoolbook multiplication 算法和数论变换(NTT) 算法.
4.1 Schoolbook multiplication 算法

Schoolbook multiplication 算法在硬件实现中主要分为2 种, 第一种是横向乘法, 先固定多项式a的一个系数与多项式b的所有系数相乘, 随后再固定多项式a的另一个系数与多项式b的所有系数相乘, 顺序进行, 直到全部乘法计算结束后再进行累加操作, 进而得出结果; 第二种是纵向乘法, 即两个多项式相乘,固定多项式X的次幂, 依次计算X0,X1,··· ,Xn-1次幂的乘法结果. 在多项式环Rq上, 两个多项式相乘, 采用Schoolbook multiplication 算法需要n2次模乘法运算和(n-1)2次模加/减法运算.
Güneysu 等人[22]在格基数字签名方案的多项式乘法器模块设计中采用Schoolbook multiplication算法, 模q约减电路利用Solinas[63]的思想, 采用轻量化设计. 虽然Schoolbook multiplication 算法的计算复杂度与其他(Karatsuba, NTT) 算法[64]相比较高, 但是它结构规则, 资源占用少, 运行频率高, 非常适合应用在资源受限的设备上. 该多项式乘法器模块在Spartan-6 上实现, 消耗204 个SLICEs, 3 个BRAMs, 4 个DSP, 运行频率可达300 MHz, 每秒能够完成约1130 次多项式乘法计算.
Brakerski 等人[65]发现, 在格基密码方案中, 模约减q不一定必须是素数, 如果q的值能取2 的幂次, 那么在硬件实现的模约减模块中, 电路结构将会变得简单而高效. 在此发现的基础上, Pöppelmann等人[58]在轻量化硬件格基公钥加密方案中使用(n= 256,q= 4096,s= 8.35) 这一组高效参数, 基于Schoolbook multiplication 算法设计多项式乘法器模块. 模块采用横向乘法模式, 由2 个计数器和1 个模乘法内核组成, 并将采样过程融入到多项式计算中, 节省BUFFER, 降低资源消耗. 在Spartan-6 上整个加密模块共消耗95 个SLICEs, 2 个BRAMs, 1 个DSP, 资源消耗下降明显.
Liu 等人[62]针对Schoolbook multiplication 算法进行了进一步优化. 作者发现, 在σ= 4.51,q=7681 时,对于无符号的离散高斯采样值需要使用13 bits 表示,而采用有符号的表示方法仅需要6 bits(1 bit 表示符号位, 5 bits 表示数据位). 利用这一发现可以有效降低对乘法器位宽的需求, 由26 bits (13 bits×13 bits) 降为17 bits (13 bits×5 bits). 在Xilinx7 系列芯片中, 由于DSP 支持25 bits×18 bits 位宽的乘法, 可以将2 个(13 bits×5 bits) 的乘法运算打包在一个DSP 中完成, 完成2 个乘法运算只需消耗一个时钟循环, 整体性能提升约2.2 倍.
根据表3 不难看出, 当格基安全参数n和p较大时, Schoolbook multiplication 算法[22]效率较低.文献[58] 采用轻量化设计, 引入新的高效参数, 在保证性能的同时, 偏向资源节约型优化, 降低多项式乘法器模块的尺寸, 使整个格基公钥加密算法架构资源占用减少, 能够部署在资源受限的设备中. 文献[62] 利用bits 约减和DSP 复用技术, 增强架构性能, 在资源消耗增长不多的前提下, 与文献[58] 相比吞吐量提升约4 倍.
4.2 数论变换算法(NTT)
NTT 算法的本质是定义在有限域上的快速傅里叶变换(FFT),使用有限域上的单位原根代替了FFT中的复数原根, 由模q上的整数运算代替了浮点数运算. 使用快速NTT 算法能够将Zq上多项式乘法的计算复杂度降为O(nlogn), 当多项式的阶数n增大时, NTT 算法优势明显. 该算法的应用场景非常广泛, 在数字信号处理中可用于滤波器、图像滤波等, 在格基密码方案中可用于多项式乘法的计算.
4.2.1 数论变换算法的基本概念
在Zq上(q是素数), 对于给定的n阶单位原根ωn, 正向NTT 变换是将长度为n的向量a=(a0,a1,··· ,an-1) 变换为长度为n的向量A= (A0,A1,··· ,An-1), 表示为:A= NTT(a), 正向NTT变换定义为:
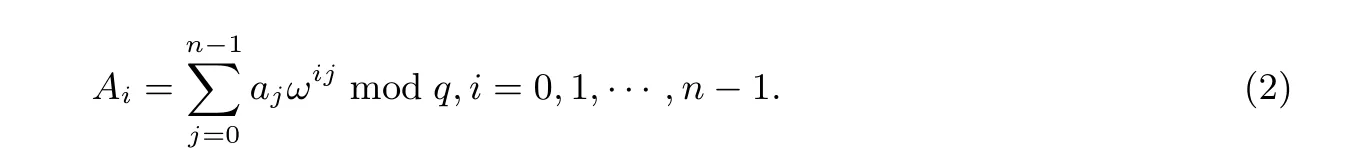
逆向NTT 变换是将长度为n的向量A= (A0,A1,··· ,An-1) 变换为长度为n的向量a=(a0,a1,··· ,an-1). 逆向NTT 变换表示为:a=NTT-1(A), 定义为:
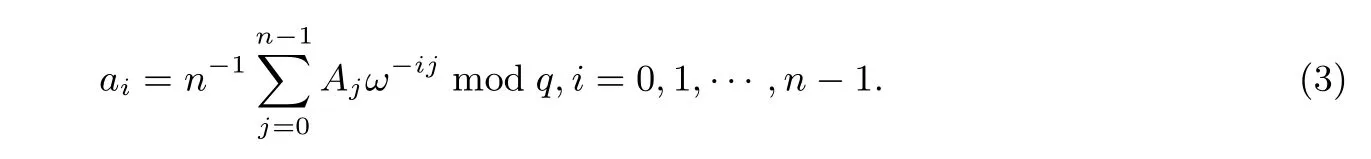
NTT 变换存在的条件是: 第一, 对于q中的每一个素因子p,n都可以整除p- 1[66]. 第二,ω是n阶原根,ωn= 1 modq且对于任何除数p,ωn/p/= 1 modq[67]. 如果q是素数,n是2 的幂,nmod(q-1)=1, NTT 变换可以使用快速算法计算.
卷积理论[68]. 令ω是Zq上的2n阶单位原根, 向量a= (a0,a1,··· ,an-1),b= (b0,b1,··· ,bn-1)为Zq上长度为n的向量. 在向量a,b后增加n个0, 得到向量a′= (a0,a1,··· ,an-1,0,··· ,0),b′=(b0,b1,··· ,bn-1,0,··· ,0), 长度为2n.a和b的卷积可以表示为:

利用卷积定理, 可以在多项式环Rq=Zq[X]/(Xn+1) 上做任意两个多项式乘法, 首先在两个多项式系数向量a,b后补n个0, 通过计算得到它们的NTT 变换, 对NTT 变换结果进行点乘, 对点乘结果进行INTT 变换, 再进行多项式模(Xn+1) 约减, 得到最终结果. 由于要在两个系数向量后补0, INTT 变换后还要进行多项式模(Xn+1) 约减, 利用该卷积理论计算Rq上的多项式乘法效率较低.
Wrapped 卷积理论[68]. 令ω是Zq上的n阶单位原根,φ2=ω. 向量a= (a0,a1,··· ,an-1),b=(b0,b1,··· ,bn-1) 为Zq上长度为n的向量.
(1)a,b的positive-wrapped 卷积为: INTT(NTT(a)°NTT(b)).
(2)a,b的negative-wrapped 卷积为: PowMulφ-1(INTT(NTT(a′)°NTT(b′))). 其中,a′=PowMulφ(a)=(a0,φa1,··· ,φn-1an-1).
Positive-wrapped 卷积定理适用于多项式模(Xn-1)约减,negative-wrapped 卷积定理适用于(Xn+1) 约减. 根据理想格Rq的定义, 可以利用negative-wrapped 卷积定理计算多项式乘法. 在φ存在,q为素数,n为2 的幂,q= 1 mod 2n的条件下, 在Rq上的多项式乘法计算过程中可以避免在多项式系数向量后补0, 避免多项式模(Xn+1) 约减步骤, 节省内存资源和时钟循环, 提高计算效率.
4.2.2 硬件中NTT 模块的架构设计
根据不同应用场景对于吞吐量、资源消耗、能耗、时延等方面的需求, 目前主流的NTT 模块设计方式有2 种. 第1 种, 采用流水线并行结构[9,10], 每一个时钟循环完成一个NTT 变换步骤. 这种并行结构所带来的优势是运算速度快, 吞吐量大, 劣势是硬件资源消耗巨大(特别是内存和寄存器). 第2 种, 紧致压缩结构[69,70]. 利用内存、地址生成器(digital address generator, DAG)、少量的操作单元(processing element, PE), 进行迭代计算, 根据步骤顺序执行完成NTT 变换. 与第1 种方法相比, 虽然吞吐量有所降低, 但是节省资源, 能够部署在资源受限的硬件设备上.
在文献[9] 中, 由于安全参数n,p较小(n= 64,p= 257), Györfi 等人设计了一套全并行流水线NTT 硬件架构, 由= 6 个蝶形步骤组成, 每个蝶形步骤包含64/2 = 32 个蝶形计算单元, 电路控制部分采用valid-ready 握手协议. 该方案采用diminished-one 数字系统[71], 在此数字系统上设计并优化模加/减电路, 节省资源消耗, 提升计算效率. 乘法器采用查找表(look up table, LUT) 法实现, 通过查表仅需一个时钟循环即可得出计算结果. 该NTT 架构吞吐量高, 在150 MHz 频率运行下, 一个时钟循环即可完成一次64 点NTT 变换, 但是代价是硬件资源消耗巨大, 在Virtex-5 上实现, 仅NTT 模块就需要3639 个SLICEs 和68 个BRAMs.
Gottert 等人[10]基于文献[72] 架构设计NTT 模块, 也采用并行流水线结构. 根据原根的性质, 作者发现在INTT 计算过程中, 只需计算奇数项的INTT 即可得到多项式乘法约减后的结果, 简化了计算过程. 模乘法采用Montgomery 乘法器[73], 由于整体架构采用并行流水线结构, 资源消耗量仍然很大, 当安全参数n >128 时, Virtex-6 器件的资源已经无法满足格基密码方案的硬件架构需求.
与上述两种NTT 模块架构不同, Pöppelmann 等人[74]提出了基于内存的紧致压缩结构NTT 模块架构, 将NTT 变换需要的多项式系数和常数变换因子存入BRAM 中, 构造1 个或少量的操作单元(PE)和地址生成器(DAG), 串行迭代计算NTT 变换. 随着n的增大, NTT 模块中除了BRAMs 的消耗线性增长明显外, 其他单元硬件消耗变化不大. 模约减电路采用的是文献[67] 的方案, 乘法器根据不同应用场景可以采用DSP 法、LUT 法等. 与上述2 个方案相比, 该方案在硬件资源消耗方面下降明显, 甚至可以在资源量较少的Spartan-6 上运行. 作者还设计了Schoolbook multiplication 算法架构模块, 并与NTT算法架构模块进行了对比, 在公钥加密方案和半同态加密方案中, 随着安全参数n的增大, NTT 算法架构模块在计算效率, 吞吐量方面优势明显, 而Schoolbook multiplication 算法架构模块资源消耗少, 电路简单, 运行频率高.
在文献[74] 的基础之上, Aysu 等人[75]对NTT 模块架构进行了进一步的优化, 首先, 在多项式系数载入阶段, 与文献[74] 中先计算后载入不同, 作者设计时钟循环时刻表, 以增加1–2 个DSP 为代价实时产生预计算乘数因子φi, 在多项式系数载入的过程中, 并行完成NTT 变换预乘计算, 该方法节省了大量的ROM 资源和时钟循环. 其次, 在NTT 变换中的常数变换因子生成方面, 与文献[74] 中将NTT 变换所需的常数变换因子存入ROM 中不同, 作者调整了NTT 变换主算法中两个循环的顺序, 根据设计好的时钟循环时刻表, NTT 常数变换因子迭代循环实时产生, 不仅节省了大量的ROM 资源, 还避免了大量的内存访问. 最后, 作者发现在NTT 变换执行过程中, 两个多项式对应的系数操作模式相同, 例如{ai,bi}系数对, 在运算过程中, 对预计算乘数和常数变换因子的需求和操作相同. 基于这个发现可以将两个多项式对应的系数以系数对的形式存入同一地址, 这样操作不仅能够节省内存空间, 而且一次内存访问即可获得2 个数据, 降低了内存访问次数, 提升了内存访问效率. 与文献[74] 相比, 综合性能提升明显, 根据不同的安全参数n, 可节省BRAMs 约66%–80%, 节省BRAM 访问次数约60%, 节省SLICEs 约52%–67%.
在前人的基础之上, Roy 等人[76]提出了更加优化的NTT 模块架构. 在NTT 变换中的常数变换因子生成方面, 作者也采用与文献[75] 类似的迭代循环实时产生方法, 与文献[75] 不同的是,ω的迭代放在次循环中, 而不是最内侧循环, 这样可以节省大量计算开销. 在NTT 变换预乘计算方面, 作者将常数变换因子ω的初始值由1 变为ω2m, 巧妙的把negative-wrapped 卷积中需要提前预乘的φi融入到主算法中去, 不仅省去了正向NTT 变换预乘计算的时钟循环消耗, 而且省去了文献[75] 中的硬件乘法器. 在内存优化方面, 虽然都是在同一地址中存入1 组系数对, 但是该方案与文献[75] 不同, 计算开始, 一次读取2个地址(获取4 个数据), 进行2 次蝶形计算, 将计算结果的4 个数据按照下一次蝶形计算的顺序重新排列成2 个数据对, 存入同一地址, 该内存优化不仅减少了内存访问次数, 而且提高了内存利用率. 如果模q的尺寸超过了18 bits (Virtex-6 中的BRAM 位宽最大36 bits), 多余的bit 值存储在窄分布型RAM 中.
上面提到的NTT 模块架构在系数载入阶段都需要进行bit 翻转操作, 将载入的系数按照要求重新排列. 与他们的设计不同, Du 等人[70]提出, 在NTT 运算过程中通过bit 翻转内存访问地址的方法实时读取数据, 从而避多项式系数载入时的bit 转换操作, 以计算一次n阶多项式乘法为例, 该方法能够节省(3×2n= 6n) 次内存访问和(3×n= 3n) 次时钟循环. 受到Roy 等人[76]的启发, 作者将NTT 变换预乘因子φi融入到主算法中去, 节省计算开销, 不同的是, 该方案中预乘因子φi不是实时计算产生, 而是存入ROM 中, 这样做不仅能够避硬件资源消耗(乘法器的使用), 还能够节省时钟循环. 作者还利用消去引理[72], 将NTT 变换的预乘因子φi、常数变换因子ωj, INTT 变换的后乘因子φ-in-1、常数变换因子ω-j进行压缩, 由4n个压缩约减到2.5n个, 节省37.5% 的ROM 空间. 基于文献[76] 的思想, 作者将NTT 主算法的两个循环调转, 保证在一个循环内蝶形计算所使用的常数变换因子相同, 减少了75%(n= 256) 和77% (n= 512) 的ROM 访问次数. 为了使蝶形操作单元的利用率最大化, 作者将需要相乘的两个多项式系数存储在两个不同的RAM 中, 采取奇、偶交替的方式从两个RAM 中读取和写入运算数据, 完成两组系数的NTT 变换. INTT 计算时, 将待变换的系数分半存在两个RAM 中, 采用与NTT 一致的方法进行计算, 与文献[74] 相比能够节省约50% 的RAM 位宽.
针对能源供给受限的硬件设备, 如电池供电的物联网设备、移动终端等. Fritzmann 等人[69]提出了首个面向低功耗、可拓展的NTT 架构. 与绝大多数采用双端口RAM 的方案不同, 该方案使用单端口RAM,可以节省约30%的功耗. 在常数变换因子优化方面,作者采取“半ROM 存储半实时计算”的方式,在ROM 中存储每一个蝶形变换步骤开始时需要的第一个常数变换因子(共logn个), 剩下的实时计算产生. 当常数变换因子ω重新选定时, 只需替换ROM 中少量的常数变换因子即可, 增强了该NTT 架构的可拓展性. 作者对NTT 和INTT 变换的最后一轮算法进行优化, 一次读取j和j+1 两个地址的数据进行蝶形计算, 使用该方法可以节省n/4 个时钟循环. 在模约减电路设计方面采用Barrett 和Montgomery约减, 进一步提升约减效率, 增强了该方案的可拓展性, 但缺点是需要使用大量的DSP, 导致资源消耗增大. 为了约减INTT 的后乘操作, 作者引入了4 个乘数因子辅助计算, 将n-1和φ-i整合进主算法, 避免INTT 的后乘操作, 节省了时钟循环, 但就INTT 的后乘操作而言, 乘法计算的数量并没有减少, 而且还需要增加额外的2 个乘法器, 该方案使用DSP 的总数量达到26 个.
在之前研究的基础上, Ma 等人[77]面向资源节约型架构进行优化, 提出一套低资源消耗低功耗的NTT 架构, 优化掉了NTT 模块架构中的DSP, 进一步提高了资源利用率和方案的通用性. 在模乘法器设计方面, 作者将多项式系数值采用D1-code 表示, 该方法表示的正整数比其真实值小1, 利用此方法, 模乘法的计算仅需简单的bit-shift 和bit-reverse 即可, 不再需要DSP, 极大地简化电路结构, 提升运行频率.为了增强NTT 架构的通用性, 作者采用一套蝶形单元. 在内存访问和管理方面, 作者采用Roy 等人[76]的方案, 在n阶多项式计算中, 将内存占用由5n降低为3n.
在面向可变参数的场景下, Mert 等人[78]针对NTT 算法的灵活性、可拓展性方面进行了进一步研究和优化, 提出了可配置通用NTT 硬件处理器架构. 在模乘法器设计方面, 作者利用Montgomery 算法思想, 并对其进行优化改进, 提出Word-Level Montgomery 模乘法器, 使其能够支持多种阶数的多项式环和多种位宽的模q; 在PE 设计方面, 采用Gentleman-Sande 型蝶形架构, 并在偶数项系数电路中添加寄存器, 以保证流水线流畅运行; 在内存访问方面, 为每个PE 配置2 个双端口BRAMs. 该NTT 架构可根据不同的应用场景, 配置不同数量的PE, 能够在性能和面积之间进行权衡, 作者还首次将该架构应用在同态加密的深度神经网络和格基数字签名方案qTESLA 中, 在性能和面积权衡方面获得了良好的效果.
Nguyen 等人[79]对NTT 模块架构进行进一步优化. 在模约减电路方面, 作者采用文献[80] 的思想,利用q=k·2m+1 的特殊结构, 设计约减电路KRED 和KRED2x; 在内存管理方面, 作者提出先进的内存回写方案, 在NTT 架构中采用4 个串行并行输出(SIPO) 寄存器, 将计算结果按照下一次NTT 乘法次序写入内存, 进一步提高内存利用率; 在整体架构方面, 作者采用4 套蝶形单元, 一个时钟循环能够完成4 点NTT 变换, 采用多路选择器控制整体架构在乘法计算和NTT 变换计算之间来回切换, 进一步提高硬件资源利用率. 作者将此架构在知名格基密码方案NewHope、FALCON、qTESLA、CRYSTALSDILITHIUM 中进行应用, 取得了良好效果. 但是由于该架构采用4 点NTT 变换设计, 仅当logN2为偶数时效率较高.
基于文献[76]的思想,Zhang 等人[81]利用Cooley-Turkey 频域抽取(decimation in frequency,DIF)型NTT 算法, 通过调整常数变换因子的初始值, 将NTT 变换预乘因子φi与主算法合并, 避免NTT 的预乘操作, 能够节省22.2% (n= 512) 和20% (n= 1024) 次模乘法运算. 基于文献[82] 的思想, 作者利用Gentleman-Sande 时域抽取(decimation in time, DIT) 型INTT 算法, 根据推导结果调整INTT 变换的常数变换因子的值, 将φi和n-1整合到INTT 变换的算法中去, 消除了INTT 变换的后乘操作, 节省了30.8% (n=512) 和28.6% (n=1024) 次模乘法运算. 在消除NTT 和INTT 的预乘操作和后乘操作的过程中, 没有增添额外的资源消耗和时钟消耗. 由于NTT 和INTT 采用两种不同的变换方式(DIF,DIT), 硬件中需要引入两套蝶形计算单元, 随后作者对这两个蝶形单元进行了压缩和整合, 减少了资源占用. 内存方面采用4 个双端口RAM 满足高速带宽需求, 根据q=12289 采用一个DSP 并设计一套4 级流水线的高效模约减电路, 与通用的Barrett 和Montgomery 模约减电路相比更节省资源和时钟循环.
根据表3 可以看出, 文献[9,10] 中设计的NTT 模块架构由于采用全并行结构, 计算速度快, 吞吐量大, 但当n逐渐增大时, 资源消耗巨大, 很难部署在资源受限的硬件设备中. 文献[74] 中设计的NTT 模块架构率先采用基于内存的串行紧致压缩结构, 与上述并行结构的NTT 模块架构相比虽然吞吐量有所降低, 但是在资源消耗方面下降明显, 能够部署在更广泛的应用场景中. 在文献[74] 的基础上, 文献[75] 以增加1–2 个DSP 的代价, 在吞吐量基本相同的前提下, 通过技术优化进一步压缩NTT 模块架构的面积,节省资源. 该方案中, 多项式系数成对存放在RAM 的同一地址中, 由于不同型号硬件中RAM 的位宽不同, 多项式系数的长度会有所限制. 在文献[76] 中, 对NTT 主算法进行优化, 减少了常数变换因子ω的计算开销, 消除了NTT 变换预乘计算, 降低资源消耗, 提升了算法效率. 文献[70] 的NTT 架构设计以访问地址翻转代替系数载入时的bit 翻转, 针对内存管理进行了全面优化, 与文献[74] 相比不仅SLICEs使用降低了约58.9%–61.1%、BRAMs 使用降低了约20%–37.5%, 而且吞吐量提升1.31–1.38 倍; 与文献[75] 相比DSP 使用下降50%–67%、RAM 宽度减少50%, 吞吐量提升1.46–1.53 倍. 文献[77] 采用了资源节约型设计思路, 对模乘法器进行重新设计, 与文献[70] 相比, 虽然增加了部分FF 的消耗, 但是其整个架构不需要DSP, 极大地提升了该架构的通用性. 文献[78] 提出Word-Level Montgomery 模乘法器,可以支持多种阶数的多项式环和多种位宽的模q, 整体架构还能够根据应用场景需求自动分配不同数量的PE, 与其他架构相比, 虽然资源消耗偏大, 但是该架构灵活性、通用性强, 能够在面积和性能之间动态调配. 文献[79] 采用4 套蝶形单元, 与其他架构不同, 每个时钟循环完成4 点NTT 变换, 采用4 个串行并行输出寄存器对计算结果进行内存回写, 提升了资源利用率, 但是由于4 点NTT 变换设计, 该架构仅对logN2为偶数时效率较高. 文献[69] 在设计方面采用单端口RAM, 目的是降低NTT 模块的功耗, 该方案在通用性、可拓展性方面做了很多优化, 但代价是增加了26 个DSP 的使用. 文献[81] 不仅消除了NTT变换预乘操作, 同时还消除了INTT 变换后乘操作, 针对特定的模q设计了专用的模约减电路, 极大地提升了运行效率, 综合考虑计算效率、资源消耗, 文献[81] 的NTT 模块架构性能最优.
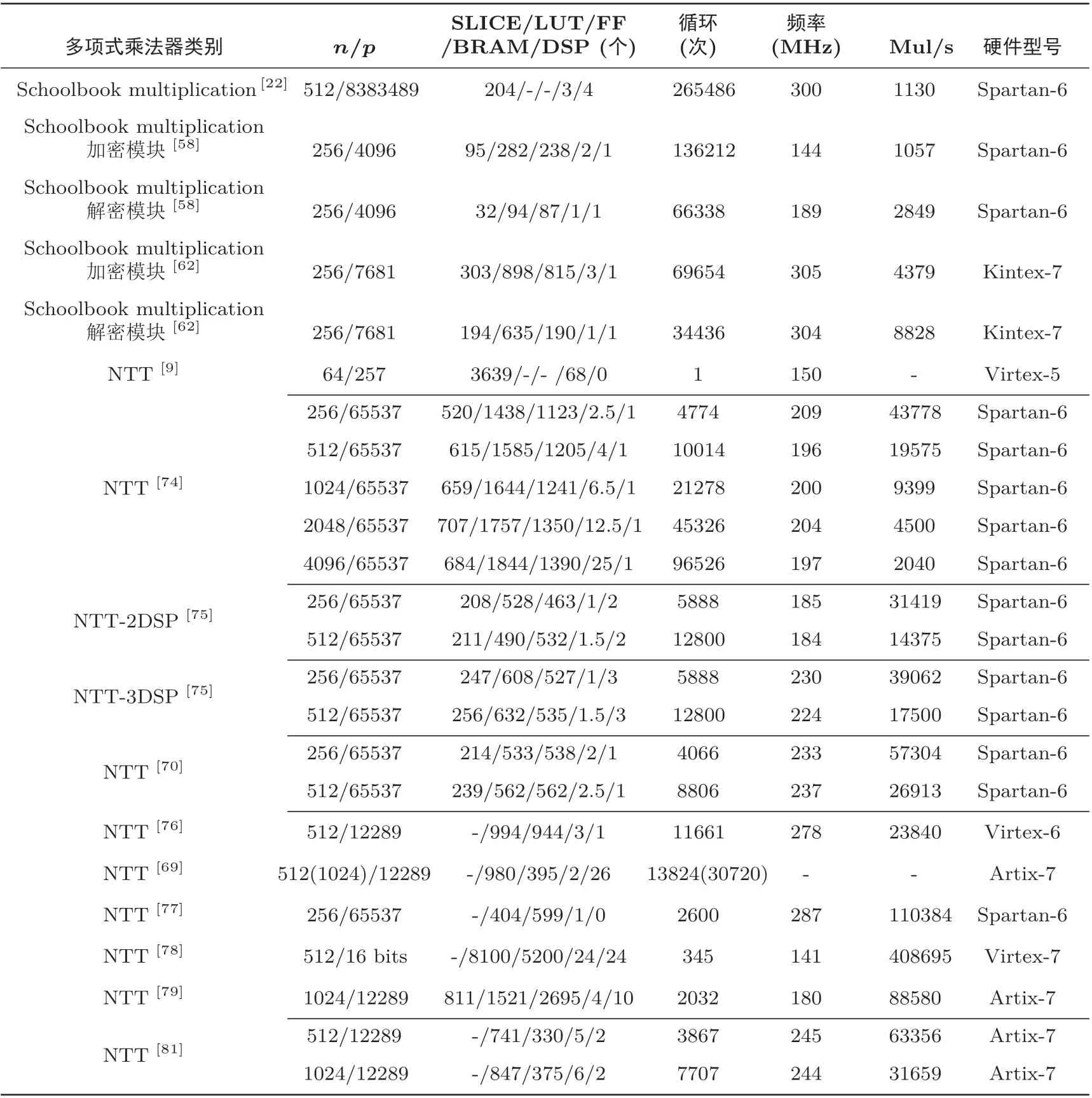
表3 格基硬件多项式乘法器对比Table 3 Lattice-based hardware polynomial multiplier comparison
5 格基密码方案的硬件实现
目前, 格基密码被视为在后量子时代能够有效抵抗量子攻击的密码算法之一, 在实际应用中有望替代传统密码体制. 正如前文所述, 硬件具有能够部署快速算法、并行处理、权衡性能与资源消耗等特点和优势. 利用硬件实现格基密码方案自然而然成为了当前研究的热点, 围绕计算性能、资源消耗、功耗等方面,各路学者对其进行优化提升, 提出了大量新颖的研究成果. 本节中, 我们讨论和对比格基密码方案在公钥密码、数字签名、密钥交换方面的硬件实现和优化设计.
5.1 格基公钥加密方案的硬件实现
格基公钥加密方案的硬件实现对比详情如表4 所示. Gottert 等人[10]分别对软硬件实现格基公钥加密方案进行了评估. 在软件实现方面, 作者使用集成NTL 库, 在Linux 系统上完成格基公钥加密方案, 其中高斯采样使用拒绝采样算法. 在硬件实现方面, 作者给出了一组硬件友好型格基安全参数, 在多项式乘法器模块中, 作者在文献[72] 算法的基础上进一步优化, 消除了逆NTT 一半的剩余乘法操作, 约减了关键路径, 提升了模块性能. 同时, 作者使用线性反馈移位寄存器(linear feedback shift register, LFSR) 和RAM 设计了一套基于查找表的硬件离散高斯采样器, 采样速度提升明显. 在相同安全等级下, 硬件实现格基公钥密码方案比软件实现在加密、解密方面分别快200 倍和70 倍. 由于采用全并行结构, 该方案资源消耗巨大, 当安全参数n >128 时, Virtex-6 上的硬件资源已经无法满足该方案的需求.

表4 格基公钥密码硬件实现对比Table 4 Comparison of hardware implementation of lattice-based public key cryptography
Pöppelmann 等人[23]发现去掉密文c2中的一些低bit 位数据并不会影响解密的正确性, 利用这一发现能够有效降低密文膨胀. 在提高解密正确率方面, 与以往1 bit 消息隐藏在1 个多项式系数中不同,作者通过将1 bit 消息隐藏在u个多项式系数中的方法, 大幅提高解密正确性. 同时作者对之前的架构进行了进一步优化, 在文献[74] 的基础上, 将简单的多项式乘法器拓展为成熟的可配置微代码引擎. 同时首次设计并采用积累分布表离散高斯采样器. 所有模块时钟循环消耗固定, 能够抵抗边信道攻击. 与全并行架构的文献[10] 相比, 在n= 256 时, 密钥生成、加密、解密资源消耗分别减小为原来的1/32、1/65、1/27, 而性能只下降约33%–50%.
Roy 等人[76]设计了一个高效紧致的格基公钥加密方案硬件处理器. 首先, 作者将NTT 模块中negative-wrapped 卷积的预乘计算融合到主算法中去, 消除了negative-wrapped 卷积的预乘计算, 同时进一步优化实时计算常数变换因子的结构, 减少了时钟循环和内存占用. 其次, 作者优化内存访问机制, 按照下一轮NTT 变换顺序存储和访问数据. 最后, 作者对NTT 主算法流水线结构进行优化, 简化关键路径提高运行频率, 将处理器的加密系统构架由5 组NTT 模块降低为4 组, 速度提升20%. 方案中的离散高斯采样使用文献[60] 提到的Knuth-Yao 型采样器. 作者在Virtex-6 上实现该架构, 与文献[23] 相比,本方案在性能和资源消耗方面都占优.
Brakerski 等人[65]发现, 格基公钥密码中q不一定必须为素数, 可以为2 的幂, 并给出了一组安全参数(256,4096,8.35), 这组安全参数对于硬件实现来讲非常高效. 在此基础上, Pöppelmann 等人[58]在多项式乘法器模块中, 采用资源消耗更低的Schoolbook multiplication 算法多项式乘法器. 在离散高斯采样器模块中, 作者采用伯努利型离散高斯采样器, 与文献[49] 的Knuth-Yao 型采样器相比, 虽然需要增大随机bit 的消耗, 但是可以节省10 个SLICEs. 作者采用一系列优化技术, 进一步降低了格基公钥密码硬件实现的资源消耗, 该方案可以在资源量较少的Spartan-6 上实现, 虽然吞吐量有所下降, 但是与文献[23]相比, 整体资源消耗下降明显.
5.2 格基数字签名方案的硬件实现
格基数字签名方案的硬件实现对比详情如表5 所示. Güneysu 等人[22]在文献[38,39] 格基签名方案的基础上进行了部分优化, 基于DCKp,n问题(决策型紧凑背包问题), 在保证安全证明的前提下, 采用压缩算法, 使签名和密钥尺寸降低了近一半. 在该方案的硬件架构中, 作者设计的随机数生成器模块、Schoolbook multiplication 乘法器模块、签名验证模块跨越3 个时钟域. 由于签名算法有一定拒绝率, 为保证签名和验证速度, 该方案设计了大量BUFFER 用于存储多项式对, 在s·c的计算中, 一旦检测出某个系数超过拒绝采样值, 立即停止当前计算和压缩, 从BUFFER 中载入新的多项式对重新计算. 该方案可以运行在硬件资源较少的Spartan-6 上, 与运行在Virtex-4 上的RSA 签名[83]相比, 不仅资源消耗减少一半, 而且性能提升1.5 倍.
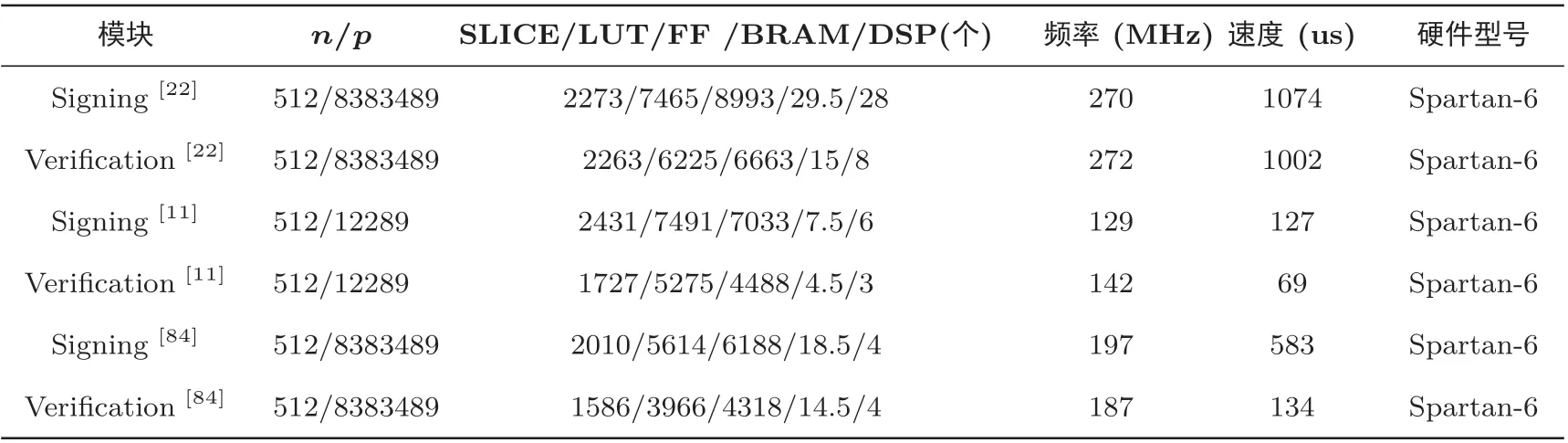
表5 格基数字签名硬件实现对比Table 5 Comparison of hardware implementation of lattice-based digital signature
Ducas 等人[51]进一步优化了Lyubashevsky 的格基签名方案[39], 作者结合双峰高斯分布, 针对原方案的核心拒绝采样算法进行了重新设计, 新方案在同等安全等级下, 比RSA 和ECDSA 更加高效, 同时进一步降低签名和密钥尺寸. Pöppelmann 等人[11]采用了这种双峰格基签名方案(BLISS), 并设计了对应的硬件架构, 在资源较少的Spartan-6 上首次使用硬件实现该数字签名算法. 该硬件架构与文献[22]类似, 采用2 级流水线结构, NTT 多项式乘法与哈希函数并行执行. 作者利用Peikert[56]的卷积定理和Kullback-Leibler 散度定理进一步设计和优化了积累分布表离散高斯采样器, 有效降低了采样器积累分布表的内存占用, 提高了采样效率. 与伯努利采样器相比, 每次采样消耗更少的随机比特和时钟循环. 与文献[22] 方案相比不仅资源占用少, 而且签名和验证速度更快, 效率更高.
Güneysu 等人[84]基于文献[38,39] 的理论基础上, 对签名方案进行改进, 将签名尺寸降低为原来的一半, 并给出安全证明. 作者设计了验证专用单元、签名专用单元和签名验证单元, 具体包括随机数生成器模块、轻量化的哈希函数模块、高效NTT 模块等. 该方案的理论部分与文献[22] 类似, 不同之处主要在于2 个方面, 第一, 多项式乘法模块由Schoolbook multiplication 算法替换为NTT 算法, 提高了多项式乘法计算效率. 第二, 签名中z1,z2的计算由串行优化为并行. 与文献[22] 相比, 该硬件架构不仅在签名速度方面提升约1.8 倍, 在验证速度方面提升约7.4 倍, 而且资源消耗有所下降.
5.3 格基密钥交换方案的硬件实现
格基密钥交换方案的硬件实现对比详情如表6 所示. Oder 等人[61]首次在 FPGA 上实现了NewHope-Simple[12]格基密钥交换方案. 文中采样器使用k= 16 的二项采样替代离散高斯采样, 能够减少内存占用, 提高性能. 在生成随机多项式a时, 采用1 个SHAKE-128 和3 个分析器并行采样,使拒绝概率可以忽略不计. 多项式乘法模块采用NTT 算法, 在文献[82] 的基础上进行优化, 正向NTT变换采用Cooley-Turkey 蝶形单元, INTT 变换采用Gentleman-Sande 型蝶形单元, 蝶形单元采用2 个DSP 并行计算, 提高计算效率. 模q约减采用与文献[11] 相同的方法. 该方案在兼顾性能的同时, 面向资源节约方向进行优化, 使之能够部署在资源受限的设备上, 在Artix-7 上运行频率为117 MHz, 完成一次密钥交换协议需要350 416 个时钟循环. 该硬件架构消耗时钟循环固定, 能够抵抗边信道攻击.

表6 格基密钥交换硬件实现对比Table 6 Comparison of hardware implementation of lattice-based key exchange
在前人研究的基础上, Kuo 等人[85]进一步优化了NewHope 密钥交换方案, 提出了一个高性能硬件实现架构. 在生成多项式a的随机均匀系数时, 为了避免采样偏执, 作者对16 bits (5q) 采样值进行拒绝采样, 成功接收概率为93.76%. 采样器方面, 与文献[61] 一致, 使用二项分布替代离散高斯分布. 在NTT模块和协商机制模块设计中, 作者分别采用4 个蝶形单元和2 套HelpRec/Rec 电路, 与文献[61] 相比,硬件资源消耗增多约4 倍. 随后, 作者在K-RED 模块中, 采用4 级流水线架构, 在模约减电路中, 采用Longa-Naehrig 技术, 提高运行频率, 降低资源消耗, 与文献[61] 相比, 在性能方面提升约19 倍. 综合考虑性能和资源消耗, 该方案优势明显.
6 结束语
本文回顾了格基密码的历史、背景、基础知识以及在公钥密码、数字签名、密钥交换等领域的应用现状. 介绍了格基密码体制硬件实现架构中的两大重要模块, 离散高斯采样器模块和多项式乘法器模块.对比分析了不同离散高斯采样器的特点以及其在实践中的应用, 同时还重点介绍和对比了Schoolbook multiplication 算法和NTT 算法在多项式乘法器模块中的应用, 根据不同优化方向(面向性能或面向资源) 探讨了不同改进型多项式乘法器模块的架构和优劣. 最后, 讨论和分析了格基密码体制中公钥密码、数字签名、密钥交换等在硬件实现中的具体设计思路和实现细节.
在后量子时代, 格基密码体制以其强大的安全性、高效性、灵活性、实用性等特点从众多后量子密码体制中脱颖而出. 格基密码体制与硬件实现相结合, 更加凸显其实用性和高效性的优势, 相信在不久的未来, 格基密码体制能够替代传统密码体制, 在实际中得到广泛应用.
