机器翻译模型中Attention和GRU的应用
2021-03-02云南民族大学黄钰凝
云南民族大学 黄钰凝
针对传统循环神经网络RNN在机器翻译中效率不高以及计算量过大的问题,提出一种基于GRU神经网络和Attention机制的机器翻译模型。首先,使用注意力模块保证堆叠多层结构的可复用性,提高运行效率。其次,模型融合了注意力机制的编码-解码器和循环神经网络模块提取被翻译的句子语义信息,并采用Adam优化器进行梯度下降,对模型优化,实现中英文间的互译。最后使用BLEU值对结果进行检验和评价。
机器翻译由于不同语言之间的差异和翻译中对“信、达、雅”的要求,成为了最困难的自然语言处理任务之一。神经机器翻译将复杂的翻译任务看作是序列到序列的转化任务:摒弃了大量的人工干涉和对语言学专家的需要,Attention机制相比于传统的编码-解码器模型,最大的区别是不要求所有输入信息都用编码器编码进一个固定长度的向量中,而是编码器将输入编码成一个向量的序列。在解码时,每一步都会选择性的从向量序列中挑选一个子集进行进一步处理。这样可以做到在产生每一个输出的时候都能够做到充分利用输入序列携带的信息。
传统的循环神经网络(RNN)会出现梯度消失现象。长期段记忆网络(LSTM)通过选通机制缓解了梯度消失问题,但模型复杂且难以收敛。GRU改善了LSTM,优化了选通机制,参数比LSTM少,也可以产生与LSTM相同的效果,使运营成本降低,速度大大提高。
1 Attention机制
注意力机制通过借鉴人脑的注意力,增强对关键信息的注意程度以提高关键信息对结果的贡献,在神经网络中引入注意力机制可以提高神经网络的训练效率。原理图如图1所示。
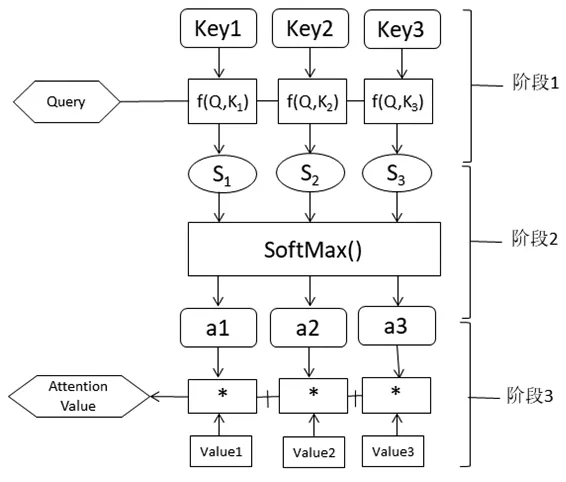
图1 Attention机制
Attention机制函数可以描述为一个Query到一个Key-Value的映射。通过在输入序列上保留LSTM编码器的中间输出结果,然后训练模型有选择地学习这些输入,并在模型输出时将输出序列与其关联。虽然此机制将增加计算量,但性能水平可以提高。此外,Attention机制用于了解输入序列中的信息如何影响模型输出过程中最终生成的序列。这有助于我们更好地理解模型的内部运行机制,并对一些具体的投入产出进行分析。当它用于输出输出序列中的每个单词时,它将关注输入序列中被认为更重要的一些单词。
在自然语言任务中,Key和Value通常是相同的。需要注意的是,计算出的Attention value是表示序列元素xj的编码向量的向量,包括元素xj的上下文,即全局联系和局部联系。全局连接很容易理解,因为计算中考虑了该元素与所有其他元素之间的相似性计算,而局部连接是因为在对xj进行编码时主要考虑了具有高相似性的局部元素。
2 GRU模型
大量实验表明,与传统的RNN模型相比,GRU的训练效果相似,但参数少,收敛速度快,训练相对容易,在过拟合方面体现较优良的优越性,只存在较少的过拟合现象。
GRU模型改进了RNN和LSTM两个神经网络模型。输入输出结构与RNN相似,其内部思想与LSTM相似,内部设置两个门:一个更新门z,一个重置门r。更新门用于控制上一次的状态信息进入当前状态的程度,值越大,引入的上一次的状态信息就越多;重置门用于控制忽略上一次状态信息的程度,值越小,被忽略的就越多。
原理图如图2所示。

图2 GRU结构图
其中,xt为当前输入,ht-1为上一个节点传输下来包括目前为止节点的隐藏信息,yt为当前隐藏信息的输出值。门控信号z的取值范围在0~1之间,信号值越趋近于1,意味着被记忆下来的数据信息越多;而越趋近于0则意味着被遗忘的越多。
3 Attention-GRU模型
3.1 模型步骤
此模型由四层构成,分别为:输入层、Attention层、GRU层以及输出层。
输入层:以预处理后的中英文语数据为输入,输出结果为一组向量,将这组向量封装为一个矩阵并将其转置作为最终的结果输出。
Attention层:将输入层的输出作为输入,通过迭代计算权重,输出结果为一组权重向量,计算公式如下所示:

GRU层:将Attention层的输出作为输入,通过正向输入和反向输出以及激活函数的作用输出结果,输出结果的计算公式如下所示:

其中,W为权重矩阵,b为偏置向量矩阵,因为ReLU函数在学习效果中较为突出,所以选取ReLU函数为激活函数。
输出层:将GRU层的输出作为输入,经过深度神经网络的运算得出结果。最终输出结果为翻译好的中文或英文句子。
当利用机器学习进行文本分类时为了提取文本特征,需要创建复杂的特征工程,而通过深度学习,获得了自动特征表达,解决了人工特征工问题。由于工艺简单、操作简单、对人工的依赖性低,因此得到了广泛的应用。
3.2 Adam优化器
Adam 优化器可以根据历史梯度的震荡情况和过滤震荡后的真实历史梯度对变量进行更新。Adam优化器在自适应学习上体现了优越性,速度快,准确率高,并有以下显著优点:
(1)更新步长在可控范围内;(2)占用内存小;(3)梯度的伸缩不影响参数更新;(4)超参数只需要进行微调;(5)对于不稳定的目标函数同样适合;(6)对大量数据和参数体现优越性;(7)可以在噪声很大的数据下使用;(8)能自动调整学习率。
使用Adam优化器对模型进行优化后,损失值由0此迭代的4.0降到1000此迭代的趋近于0。
4 BLEU检验
BLEU是将候选翻译与一个或多个其他参考翻译进行比较的评估分数。它经常被用来衡量一组机器生成的翻译句子和一组人工翻译句子之间的相似性,采用N-gram的匹配规则。值是一个处于0~1之间的数值,数值越接近1,结果越好。
BLEU 编程实现的主要任务是对候选翻译和参考翻译的 n 元组进行比较, 并计算相匹配的个数匹配个数与单词的位置无关匹配个数越多, 表明候选翻译的质量就越好。
虽然此指标的完美性有所欠缺,但它的优点更吸引在机器翻译任务研究中的学者。例如:计算量小、不限于语种、与人工翻译的评价结果相关性强。缺点如:语法性较弱、短句的测评精度较高、未考虑到近义翻译等。
5 模型结果
在此次实验中,将采用的双语料数据导入到所建立的模型中进行训练并优化,对参数学习并修改,得到参数结果如表1所示:

表1 模型参数表
翻译示例句如下:
输入中文:我想见你的姐姐。
实际英文: I’d like to see your sister.
预测英文:I want to see your old sister.
预测结果与实际结果很相似,模型效果得到一定的体现。
结语:通过此次实验的结果可以看出翻译效果不错,但并非优秀。BLEU值未达到预期,部分翻译结果也未如愿,但总体上来看由于模型搭建合理,呈现一个较良好的翻译效果。
本文提出一种基于Attention机制和GRU神经网络的机器翻译模型,实现了无监督的机器翻译,在提高准确性的同时降低了运算成本,提高了运算速度。理论上此模型在本数据上效果由于普通循环神经网络所得出的结果。在未来将继续探索优化模型,探索更多其他的优秀模型。
可以考虑在以下方面进行改进:
(1)进行预训练和微调;(2)多任务学习;(3)使用不同的编码解码器;(4)引入足够强大的语料库。
