基于GBDT回归的光伏电站出力人工智能预测算法研究
2021-03-02朱祺杨鹏
朱祺,杨鹏
(中国电力工程顾问集团华东电力设计院有限公司,上海 200001)
随着3060碳中和目标的提出,光伏发电作为典型的绿色电源形式,其装机容量占整个电力系统总装机容量的比重越来越大,在电力系统中所起的作用也愈发重要。准确的光伏发电出力预测对于保障高比例光伏接入后系统的安全稳定与经济运行具有重要意义[1]。
在光伏发电预测方面,最初的数据挖掘方法比较原始,如静态知识和单源挖掘方法,它们不适用于包含大量异构和流数据的智能电网场景,针对这一问题,学者们提出了多源挖掘机制和动态数据挖掘方法。如文献[2]将马萨诸塞州东南部分为15个片区,通过分析历史开源气象数据及光伏电站历史出力数据并构建气象参数-输出功率的转化模型,最终实现了预测时间分辨率为1小时的区域日前出力预测。文献[3]依据多维参量,包含气象参数、经纬度以及光伏阵列安装倾斜角等,对整个欧洲地区进行了片区划分并建立了不同片区的区域光伏发电模型,对整个欧洲地区的光伏出力实现了时间分辨率为1小时的预测。
相较于低效率、高成本传统集中式数据处理的分析方法,分布式计算更加高效,已被广泛应用于地质、气候和环境分析、人类基因组计划、暗能量测量计划等领域[4]。随着计算能力的大幅提高和硬件成本的降低,一些新的信息提取方法被提出,机器学习就是其中之一。本文即是通过基于GBDT回归的光伏电站出力人工智能预测算法对于光伏电站的出力进行预测,通过准确度较高的预测结果提前预知光伏电站的未来超短期和短期的出力情况,保证电网的运行安全。同时,各类气象元素与光伏电站出力之间的相关性数据也能为光伏电站的选址提供参考,为光伏电站的选址决策提供数据支持。
1 GBDT算法原理
针对预测场景的算法有很多种,较为常见的有线性回归、Bayes、LDA、KNN等。这些算法有的适用于回归场景,有的适用于分类场景,部分能够同时被应用在两大类场景中。如文献[5-8]采用混合k-聚类和主成分分析相结合的方法,进行数据降维和估计映射。文献[9]基3639个用户电表数据,利用回归分析的方法进行用户负荷分类。
GBDT算法全称为梯度提升迭代决策树算法,是机器学习算法中对真实分布拟合的最好的几种算法之一,其典型特点为既可以用于分类也可以用于回归。
算法的原理如下[10]:
梯度提升迭代决策树预测函数的表达式为:
(1)
式中:x为输入样本;ht为第t棵回归树;ωt为回归树参数;ρt为第t棵回归树的权重。
对于N个样本,预测函数的最优值为:
(2)
式中:L为损失函数。
梯度提升迭代决策树算法的迭代过程如下:
(1)定义
(3)
式中:fi为弱学习器。
(2)构造基于回归树的训练样本、目标函数分别为:
(4)
L(yi,F(xi))=(yi-F(xi))2
(5)
式中:(yi,xi)∈R×RN。
(3)基于梯度下降方向训练决策树得到的拟合数据为:
(6)
其最佳拟合数据为:
(7)
(4)求得梯度下降方向的最佳步长为:
(8)
式中:ρt0为第t棵回归树的初始权重。
(5)求得第t棵回归树的弱学习器为:
ft=ρ*ht(xi,ω*)
(9)
(6)迭代后的预测函数为:
Ft(x)=Ft-1(x)+ft
(10)
若损失函数满足误差收敛条件或得到的回归树的t值达到预设值,则迭代终止;若不满足,则继续迭代。
2 光伏电站出力预测算法
2.1 数据集情况
本文所采用的数据集为某光伏电站的气象及出力实测数据,时间跨度为3年(其中包含1个完整年),数据的采样周期为5分钟。数据的总数为42969条,特征构成如下表所示:
按照人工智能训练、调节参数和测试的习惯,整个数据集需要按照比例进行拆分,分别用于训练模型、调节模型参数和测试模型预测效果。如文献[11]提到了采用LSTM模型来预测电力系统负荷的方法,数据集的拆分比例为81%的数据用于训练模型,19%的数据用于测试模型预测效果。文献[12]采用了XGBoost极限梯度提升模型、随机森林模型和LSTM模型三种模型融合的方式来进行电能表需求预测,使用最大约之前75%的数据预测约之后25%的结果。本文采用Holdout交叉验证[13]方法,将整个数据集按照60%、20%和20%进行拆分,分别用于训练模型、调节模型参数和测试模型预测效果,如下表所示:
Holdout交叉验证方法能够避免训练完成的模型出现过拟合情况,防止出现模型对训练数据拟合较好但是却没有办法对于测试数据做出精确预测的情况。在以上数据集拆分基础上进行光伏电站出力预测算法模型的设计及后续的训练、调节和测试验证工作。最终成果为形成光伏电站出力预测算法模型。
2.2 光伏电站特征维度和出力间的相关性分析
光伏发电的输出功率曲线在时域范围呈现不稳定性和波动性,外界的干扰极易造成输出功率的突变[14]。光伏出力与辐照度及转换率有很强的关系,影响光伏出力的根本因素只有两个,包括太阳能电池实际接受的辐照度和电池板面温度,天气、湿度、气温等都是通过影响上述两个根本因素,进而对光伏出力产生影响的[15]。由于12个特征维度未必每个都会影响光伏电站最终出力,因此在光伏设备不变的情况下,光伏发电量主要受到客观物理因素的影响,可选择其中关联性较强的因素作为特征进行预测学习建模。先计算训练集中每个特征与光伏出力之间的相关系数,以确保用于GBDT回归模型训练的特征最符合光伏电站运行的实际情况。相关性分析是对两个或多个具备相关性的变量进行分析,衡量变量间的密切程度[16]。相关性一般分为:正相关、负相关和无相关。Pearson相关系数能较好地表示变量的相关性,当Pearson 相关系数r 的平方,即相关判定系数r2 大于0.3 时,可认为两变量具有强相关性,支持使用回归模型进行预测[17]。计算结果如图1所示:
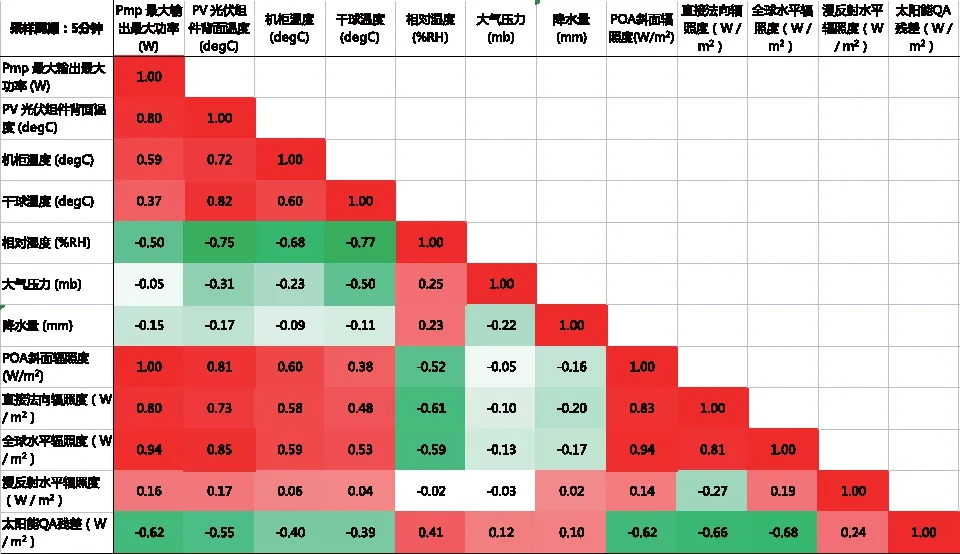
图1 光伏电站特征与出力相关性分析图Fig.1 Correlation analysis diagram between characteristics and output of photovoltaic power station
图中,红色的代表特征与光伏电站出力之间为正相关性,绿色的代表特征与光伏电站出力之间为负相关性,白色的代表特征与光伏电站出力之前几乎没有相关性,颜色越深则相关性就越强。根据相关性分析的结果,确定将以下六个特征作为GBDT算法模型的输入特征:
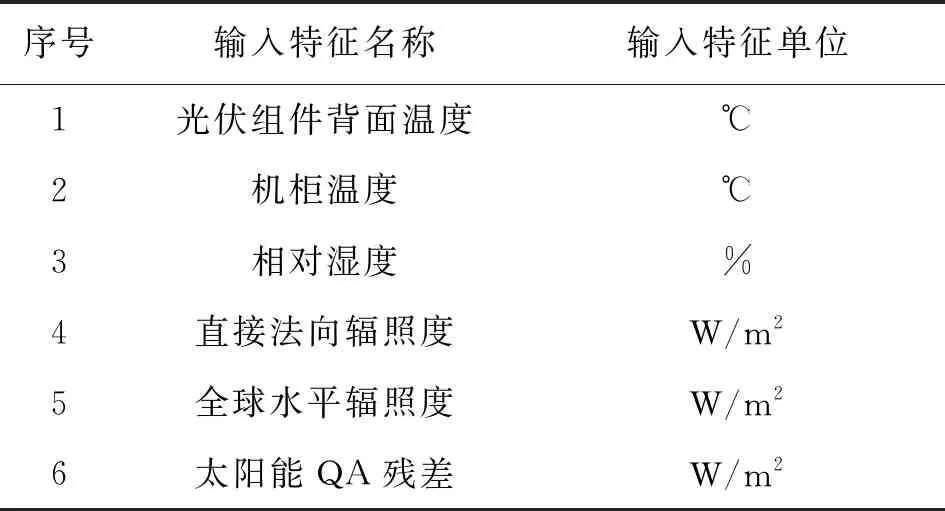
表3 GBDT算法模型输入特征表Tab.3 GBDT algorithm model input characteristic table
2.3 GBDT回归算法流程设计
按照数据科学的标准运作流程进行预测算法流程设计,明确训练数据集、交叉验证数据和测试数据集的数据流向,完整地反映从数据输入到模型训练、参数调节、预测结果输出直至预测结果验证的流程,为通过代码构建算法提供基础性输入资料。
本文所采用的数据集为多模态数据集[18]。在数据层面理解,多模态数据则可被看作多种数据类型的组合,如图片、数值、文本、符号、音频、时间序列,或者集合、树、图等不同数据结构所组成的复合数据形式,乃至来自不同数据库、不同知识库的各种信息资源的组合[19]。因此,本文在多种气象数据基础上设计的机器学习方法应该归类为多模态机器学习算法。按照多模态机器学习算法设计模式进行算法流程设计。
所完成的预测算法流程图如下图所示:
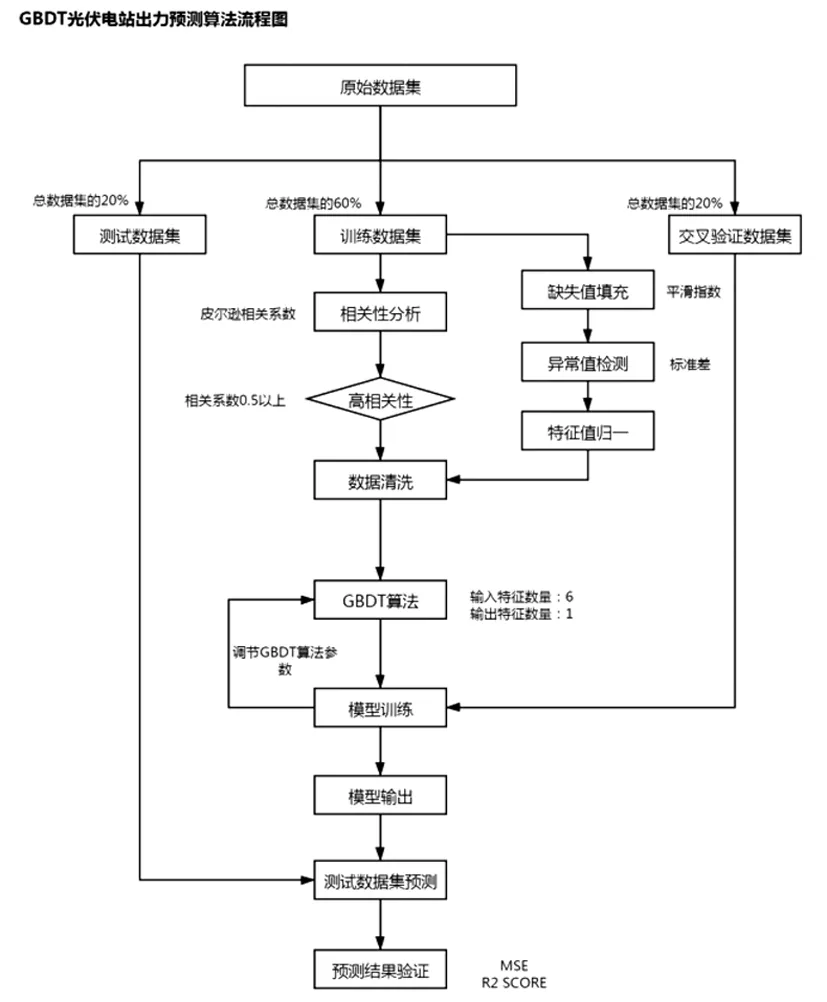
图2 GBDT回归算法流程图Fig.2 GBDT regression algorithm flow chart
3 算法实施及结果验证
采用Python语言按照算法流程图的设计进行代码构建。将训练集中根据之前相关性分析选定的六个特征输入GBDT算法模型,采用交叉验证数据集对于训练完成的模型进行验证和参数调节[20],运用交叉验证思想的算法求解出来的属性子集不仅进一步降低了训练集合的总决策代价,而且更加有效地降低了测试集合的决策总代价[21]。参数调节过程中通过经验法则防止出现而不会出现梯度消失[22]和梯度爆炸的问题。常用的参数调节方法有手动调参和自动调参两种,手动调参的方法是通过手动调整超参数,直到找到一组很好的超参数值组合,这个过程需要通过手工调节进行反复尝试,从效率角度相对较低,但对于有足够调参经验的技术人员也是经常被采用的调参方法。本文采用网格自动调参方法,在算法实施过程中设置所需要调节的模型的超参数和需要尝试的值的范围,在算法实施过程中算法将会使用交叉验证来评估超参数值的所有可能组合,根据交叉验证的结果选择使模型预测效果最为精准的超参数组合。
最终,当GBDT算法的参数调节至如下表所示时,模型的预测结果有较好的表现,如下表所示:
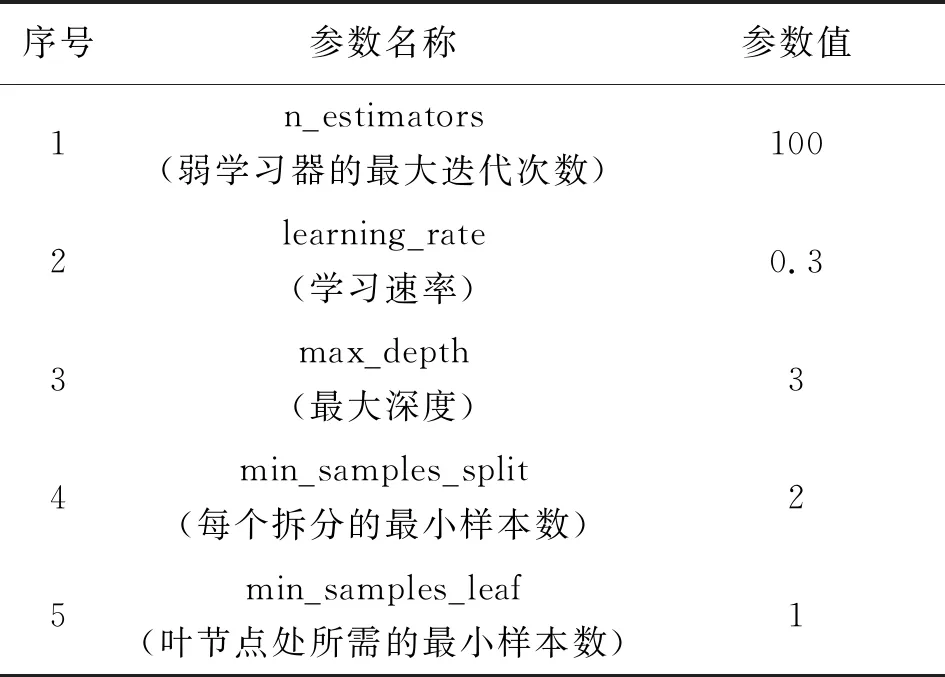
表4 GBDT算法参数表Tab.4 GBDT algorithm parameter table
其中,弱学习器的最大迭代次数太小,模型容易欠拟合,而太大又容易过拟合,一般与学习速率结合考虑,本文中经过参数调节,当弱学习器的最大迭代次数为100并且学习速率为0.3的时候,模型的表现最为良好。最大深度一般来说,数据少或者特征少的时候可以不管这个值,但是结合本文的数据多特征特点,需要限制最大深度防止过拟合,经过参数调节,当最大深度为3的时候,模型的表现最为良好。每个拆分的最小样本数限制了模型子树继续划分的条件,如果某节点的样本数少于这个值,则不会继续再尝试选择最优特征来进行划分。 本文的数据样本总量并不大,因此设置为2时模型的表现最为良好。叶节点处所需的最小样本数限制了叶子节点最少的样本数,如果某叶子节点数目小于样本数,则会和兄弟节点一起被剪枝,同样因为本文的数据样本量不大,采用默认的值1会使模型表现较为良好。
采用测试数据集对于参数调节完毕并已经训练完成的模型进行预测及结果验证。在验证指标的选择方面,由于决定预测模型精确性的评价指标较多,采取单一的评价指标容易受到计算误差的影响[23],因此本文采用的验证指标为均方误差(MSE)[24]及R方值,均方误差(MSE)能够判断参数估计值与参数值之差平方的期望值,是衡量平均误差的一种较方便的方法,通常用来评价数据的变化程度,MSE的值越小,说明预测模型描述实验数据具有更好的精确度。R方值能够反映因变量的全部变异能通过回归关系被自变量解释的比例,其使用均值作为误差基准,计算预测误差是否大于或者小于均值基准误差,R方值为1时代表样本中预测值和真实值完全相等,没有任何误差,为0时代表样本的每项预测值都等于均值,为负时代表模型的预测表现不如随机采取,处于失效状态[25]。
验证指标的输出结果及说明如下表所示:
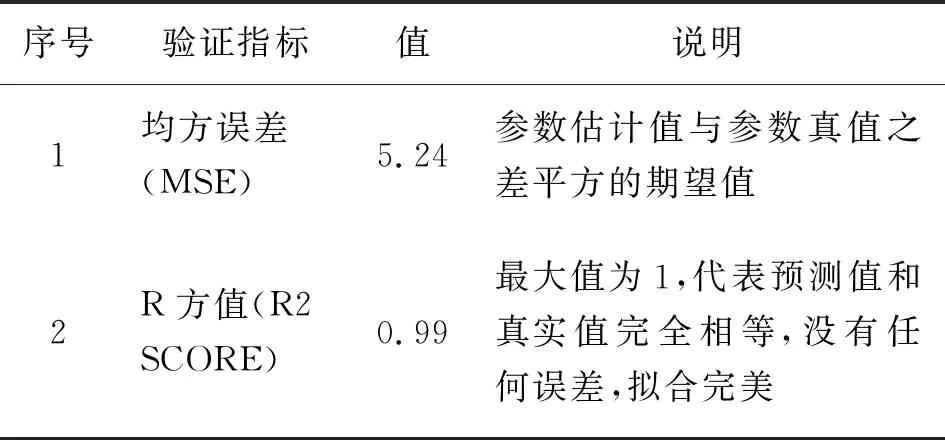
表5 验证指标输出结果及说明Tab.5 Verification index output results and description
验证指标显示模型对于光伏电站出力有较好的预测效果。采用可视化工具进一步验证模型的预测效果,选取测试数据集中的前100条数据及前500条数据,叠加绘制真实值及预测值,直观显示两者之间的差异,如下图所示:
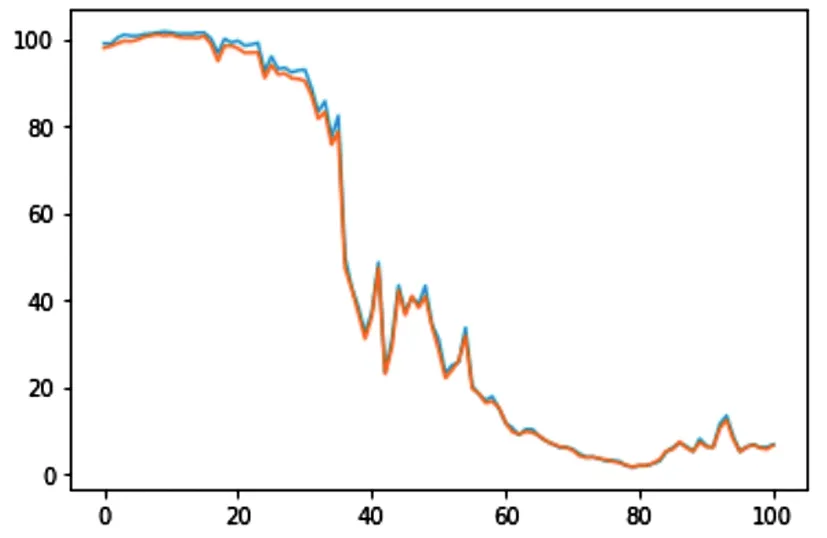
图3 测试集前100条数据预测值真实值对比曲线图(蓝色为预测值,黄色为真实值)Fig.3 Comparison curve of predicted value and real value of the first 100 data in the test set (blue is the predicted value and yellow is the real value)
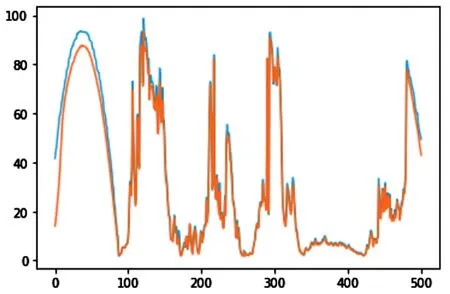
图4 测试集前500条数据预测值真实值对比曲线图(蓝色为预测值,黄色为真实值)Fig.4 Comparison curve of predicted value and real value of the first 500 data in the test set (blue is the predicted value and yellow is the real value)
两幅预测值真实值对比曲线图验证指标同样显示模型对于光伏电站出力有较好的预测效果。
GBDT算法进行训练模型时,不能使用类似于mini-batch的方法,而是需要对样本进行无数次的遍历。如果想要提高训练的速度,就必须提前把样本数据加载到内存中;但这样会造成可以输入的样本数据受限于内存的大小。然而在I/O数量众多的情况下,算法运行速度仍相对较慢。为了使GBDT能够更加高效地使用更多的样本,学者开始考虑引入分布式GBDT。但是相对于分布式GBDT,LightGBM更具优越性。本文算法实施过程中所采用的LightGBM是一个实现GBDT的快速、分布式、高性能框架,它的特点是训练时保留所有梯度较大的样本,而对梯度较小的样本随机采样,并引入常量系数,抵消采样对数据分布的影响。
其他能源电力行业在实施GBDT算法时LightGBM框架也是最常用的GBDT框架之一,如文献[26]提出了基于LightGBM和深度神经网络(DNN)的配电网在线拓扑辨识方法。该方法借助LightGBM实现特征选择,筛选出对配电网拓扑辨识最有效的少量量测。文献[27]在基于卷积神经网络与LightGBM的短期风电功率预测方法时考虑到单一卷积模型在预测风电时的局限性,将LightGBM分类算法集成到模型中,从而提高预测的准确性和鲁棒性。
4 结论
(1)GBDT算法对于多维度特征的光伏出力预测有较好的预测效果,适用于光伏电站出力预测场景。由于光伏电站的数据各个特征维度之间的测量单位不同,各维度的单位之间存在数量级差异,与其他基于树的模型类似,GBDT算法不需要对数据进行缩放,能够避免各维度的单位之间存在的数量级差异对模型的预测效果产生影响。
(2)通过相关性分析能够准确判断对光伏电站出力影响较大的特征,从原始数据中找出具有物理意义的特征。从而剔除不相关或者冗余的特征,减少有效特征的个数,减少模型训练的时间,提高模型的精确度。
(3)本文所采用的交叉验证方法为Holdout交叉验证法,能够避免模型训练过拟合[28]的情况。将整个数据集以60%、20%和20%的比例分别拆分成训练数据集、交叉验证数据集和测试数据集是较符合常规的做法,三个数据集之间需要确保完全独立没有重复。
(4)预测效果验证采用指标验证和可视化验证结合的方式是较为理想的多角度验证手段。本文所采用的两个验证指标包括均方误差(MSE)及R方值指标适用于光伏电站出力预测场景。
(5)GBDT算法实施过程中,本文所采用的LightGBM是一个实现GBDT算法的快速、分布式、高性能框架,适用于光伏电站出力预测场景。
(6)本文在GBDT模型超参数调节过程中采用了网格自动调参方法,在算法实施过程中算法将会使用交叉验证来评估超参数值的所有可能组合,根据交叉验证的结果选择使模型预测效果最为精准的超参数组合。避免了手工调节参数的片面性。
(7)光伏电站出力预测有超短期、短期,根据时间周期的不同可以采用不同的机器学习、深度学习或者时序预测算法,可以考虑采用包含本文的GBDT模型在内的多种预测模型融合的方案来适应不同的时间周期预测。
