基于多任务学习框架的红外行人检测算法
2021-02-28苟于涛宋怡萱
苟于涛,马 梁,宋怡萱,靳 雷,雷 涛*
基于多任务学习框架的红外行人检测算法
苟于涛1,2,3,马 梁1,2,3,宋怡萱1,2,3,靳 雷1,2,雷 涛1,2*
1中国科学院光电探测技术研究室,四川 成都 610209;2中国科学院光电技术研究所,四川 成都 610209;3中国科学院大学,北京 100049
与高质量可见光图像相比,红外图像在行人检测任务中往往存在较高的虚警率。其主要原因在于红外图像受成像分辨率及光谱特性限制,缺乏清晰的纹理特征,同时部分样本的特征质量较差,干扰网络的正常学习。本文提出基于多任务学习框架的红外行人检测算法,其在多尺度检测框架的基础上,做出以下改进:1) 引入显著性检测任务作为协同分支与目标检测网络构成多任务学习框架,以共同学习的方式侧面强化检测器对强显著区域及其边缘信息的关注。2) 通过将样本显著性强度引入分类损失函数,抑制噪声样本的学习权重。在公开KAIST数据集上的检测结果证实,本文的算法相较于基准算法RetinaNet能够降低对数平均丢失率(MR-2)4.43%。
红外行人检测;多任务学习;显著性检测

1 引 言
目前,基于可见光图像的行人检测技术得到了飞速发展[1-2],通过与行人重识别[3-4]等技术相结合,在安防监控、自动驾驶等领域中具有较大的应用价值。然而,受光照、烟雾、遮挡等干扰,仅依赖这类图像作为检测任务的解决方案难以在全天候复杂环境下实现较为鲁棒的检测。为此,文献[5-7]等提出基于多传感器信息融合的算法。但其数据获取难度较大,硬件成本较高。由于红外图像能够感知目标所发射的指定波段的热辐射信息,抗干扰能力强,不受环境光照的影响[8]。因此,本文基于红外图像,通过利用空间显著性信息,提升网络对红外行人的检测能力。
传统的行人检测算法主要通过滑动窗口产生大量候选区域,提取区域内手工特征,例如:HOG,SIFT等,再通过SVM等分类算法完成对候选区域内容的判别。但这类方法人工干扰较强,检测精度较差。随着深度学习技术的发展,R-CNN系列[9],Yolo系列[10]等以不同的检测思路实现了较高精度的目标检测。面向基于可见光图像的行人检测算法,Zhang等人[1]首先将Faster R-CNN在行人检测中的应用进行了相关研究。为了有效地感知不同尺度大小的行人样本,Li等人[2]引入尺度感知模块。与上述方法相比,基于红外图像的检测算法性能距离实际应用存在较大的差距,主要存在以下几个原因:
1) 图像质量较差。由于红外物理特性以及硬件设备的限制,红外图像往往成像模糊,分辨率较低。目前大多数红外目标检测算法主要通过基于可见光图像的检测模型迁移而来,未能有效结合红外图像本身性质对检测算法进行优化。
2) 噪声样本。由于温度分布及拍摄环境的复杂性,红外图像中的部分样本并不具备良好的特征信息,如图1(a)红框内所示。这些噪声样本因遮挡、成像距离、环境等因素产生,与背景特征较为接近,加大了网络学习的难度,容易使网络陷入较强的数据拟合而难以学习到具有普适性的红外行人特征。
针对问题1),John等人[11]提出了一种自适应模糊C-means与卷积神经网络结合的检测模型,利用C-means分割算法对红外行人目标进行分割并筛选候选框。Devaguptapu等人[12]通过Cycle-GAN将红外图像转化为伪彩色图像,并通过双目标检测器进行检测。同年,Ghose等人[13]在保持原有纹理特征不变的情况下引入红外图像的显著信息,使其在不同时段的丢失率均有所下降,但推理时大量的计算消耗导致其难以应用于实际场景。针对问题2),最新的TC-Det[14]通过引入分类网络分支,利用场景光照信息有效弱化噪声标签的干扰。

图1 KAIST行人样本可视化。(a) 不同尺度的部分行人样本;(b) 尺度分布情况
在深度学习技术中,多任务学习方式主要是通过共享相似任务间的有效信息,提升原有任务的表现。本文从多任务学习的角度出发,对比分析独立学习式及引导注意力式两类分支结构的设计,使其具有对红外图像显著区域的判别能力,最终以共享特征提取层的方式为检测分支提供场景显著信息,提升行人检测性能。此外,根据样本显著性分析可知,这些红外图像中所存在的噪声样本和背景的差异较小,具有较弱的显著性表达。因此,将协同分支所推理出目标的显著性信息引入至分类损失函数中,能够有效弱化网络对这些样本的关注,提升网络整体的泛化性能。
本文的主要贡献包括:
1) 在目标检测网络的基础上添加显著性检测分支,使网络具备红外图像显著性检测能力的同时,能以共同学习的方式,强化检测器对显著区域的关注。
2) 将显著性检测结果转换为每个样本的显著性得分,并结合手工设计的Smooth Focal-Loss函数计算网络分类损失,弱化噪声样本对网络学习的干扰。
3) 本文对整个网络结构进行消融测试,并通过横向对比主流的红外检测算法,证实了本文训练方式的有效性。最终,本文实现KAIST数据集上的MR-2相较于基准算法RetinaNet[15]显著降低4.43%,且仅作为训练方式不增加计算消耗。
2 方法原理


图2 网络整体框架示意图
2.1 引入显著性检测的多任务学习框架设计
Ulman等人[17]将某一位置的显著性定义为该位置在颜色、方向、深度等方面与周围环境的差异程度,而图像所对应的显著图能够有效显示出该场景内的突出区域。Ghose等人[13]首先提出将显著图通过通道替换的方式对红外图像进行加强,整体实验流程如图3(a)所示。基于其实验结果分析可知,显著图作为一种显式的空间注意力,能够引导检测器学习显著区域。同时,相比于传统基于手工特征的显著性检测方法(如文献[18-19]),深度学习方法加强了对语义特征的关注,有效降低了大量背景噪声的干扰。该实验对训练集中的1702张图像以及测试集中的362张图像进行了像素级的显著区域标注,并通过PICA-Net[20]和R3Net[16]两种深度显著性网络预测出数据集中所有的显著图并进行实验。虽然实验结果证实了利用显著图增强红外行人检测的有效性,但该方法作为一种数据增强手段,在实际应用时,需要通过额外的网络对测试图像进行显著性检测,严重影响了单帧行人检测的推理速度。
考虑到上述方法的局限性及显著图对红外目标检测的强化作用,本文设计了一种多任务学习方式,即在训练过程中同时完成目标检测及显著性检测两个任务,具体流程如图3(b)所示。其中,协同分支在该框架中主要有两个作用:1) 学习红外图像显著区域的判别能力,以共同学习的方式替代原先的注意力强化手段,引导检测器关注显著区域;2) 显著性标签中包含显著目标精细的轮廓信息,与目标框标注相比,更有利于检测器的学习。下面本文将从协同分支结构的设计和学习方式进行分析。
2.1.1 协同分支结构设计
目前显著性检测网络大多数基于全卷积框架的设计,在采用特征提取网络进行不同层级的语义特征提取后,通过解码器框架对其进行解码,最后由像素级的标注信息进行监督学习。由于数据集中行人样本尺度差异较大,本文采用经典的单阶段多尺度目标检测算法RetinaNet[15]作为实验的基准检测网络,特征提取部分采用ResNet50。最终,本文设计并测试了两类不同共享层级的多任务学习框架,以判断最优共享方式的结构。
独立学习式框架。目前大多数多任务学习模型采用独立学习式的架构[21-22],即不同分支共享特征提取模块,以独立并行的方式完成各自任务。这种架构要求共享的特征能够满足不同任务的需要,并通过分支任务信息改善主任务的训练效果。在此基础上,本文设计了以下三种模型架构,设计方案如图4所示。
(a) 多尺度级联
考虑将FPN输出的每层特征沿通道方向进行级联,再将级联后的特征图通过1´1´1024的卷积核进行通道压缩,该框架使显著性分支的loss直接作用于原检测特征,对检测分支的归纳偏置较大,但由于特征压缩卷积核的通道数过多,网络学习难度较大。
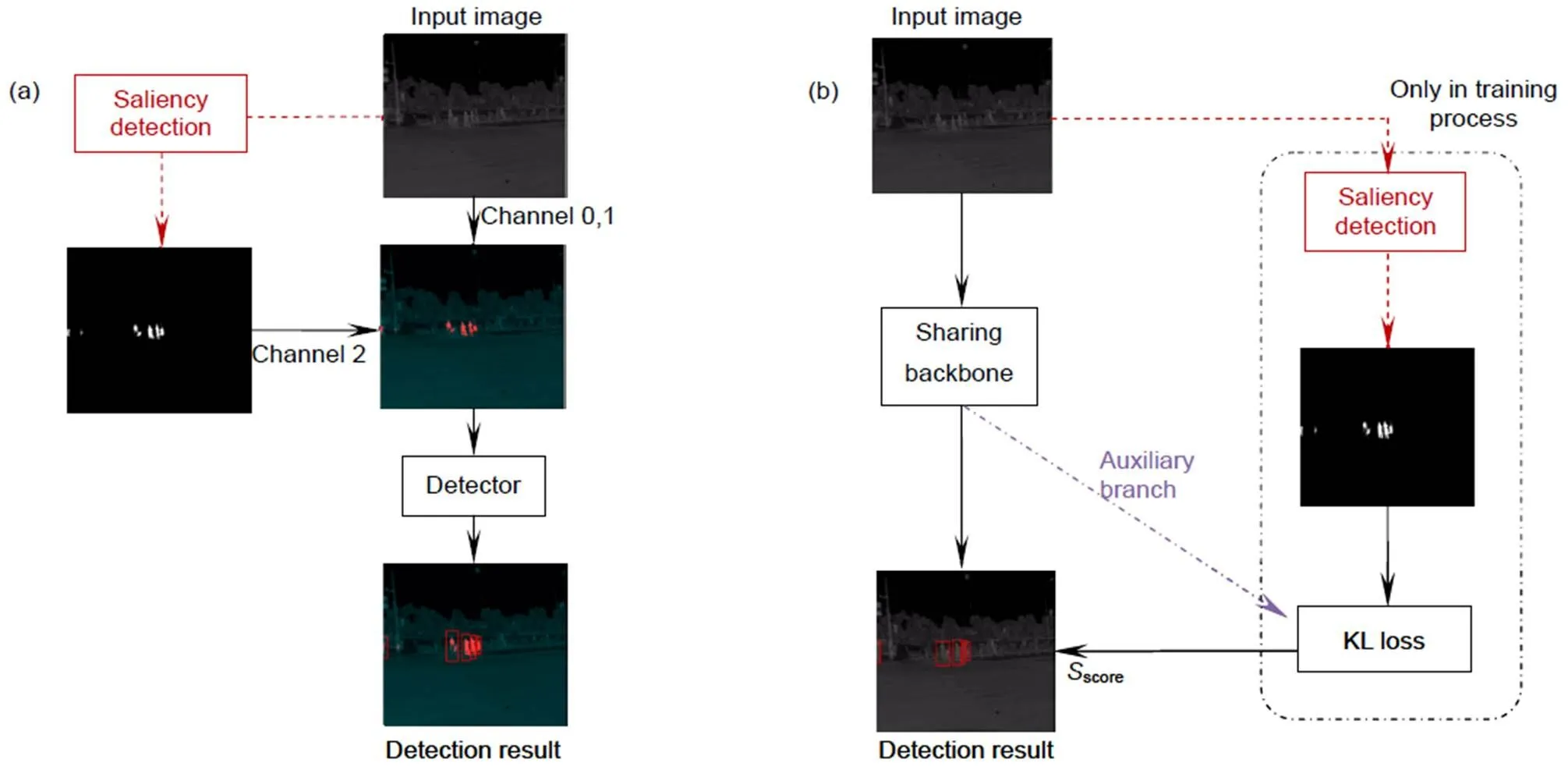
图3 文献[13]的方法与本文方法的整体框架对比。(a) 文献[13]方法的整体检测框架;(b) 本文所提方法

图4 三种独立学习式网络结构设计方案。(a) 多尺度级联式;(b) 多尺度并行式(PAR);(c) 流注式(CAS)
(b) 多尺度并行式框架(PAR)
将不同尺度层级的特征独自进行特征压缩,卷积层参数共享,最后通过元素级相加得到最终结果。与框架(a)相比,框架(b)有效地降低了分支网络的卷积层参数,但由于每层特征最后相加时权重相同,在loss反传时难以考虑不同尺度目标的特征差异,因而造成精度的下降。
(c) 流注式框架(CAS)
考虑到Unet框架的设计,本文将最高层语义特征P6通过双线性插值不断上采样,并将每次上采样后的结果D4~D6分别与P3~P5进行元素级相加及1*1卷积,最后D3特征通过卷积层降低维度,输出预测结果。相较于前两个模型,框架(c)充分利用了不同尺度层级的特征。
独立学习式框架模型在多任务学习中最为普遍,其要求特征提取模块具有容纳两种不同特征的能力,性能的提升主要通过分支网络额外的信息标注驱动主任务分支的特征提取。同时,由于两个分支完全独立,显著性分支与检测特征之间并未存在直接作用关系。
引导注意力式框架。
在引导注意力式框架中,协同分支在完成辅助任务的同时,会将网络中的特征表达作为空间或通道注意力对主任务模型中的特征进行强化。本文以级联模型为基础,将显著性分支特征或最后预测结果以元素级相加的方式作用于原有检测特征,具体模型结构如图5所示。

图5 两种引导注意力式网络结构设计方案。(a) 结果强化式框架(Guided(a));(b) 特征强化式框架(Guided(b))
(a) 结果强化式框架(Guided(a))
直接将协同分支的预测结果通过最大值池化后分别与(P4~P6)进行相加,为了使预测结果与原有特征的通道数相匹配,本文将预测结果在通道维度上复制256层。
(b) 特征强化式框架(Guided(b))
本文将FPN上每层特征经过与高级特征元素级相加即等通道卷积后再作用回原特征,该方法将显著性分支中的特征整体作为注意力对(P4~P6)进行强化,其相加时两边通道数相对应。
引导注意力式框架扩展了两个分支所共享的网络,其将分支中的特征信息直接用于加强主网络特征,例如文献[14]。根据3.2的实验结果可知,流柱式框架(CAS)与引导注意力式框架Guided(b)相较于原始模型均有所提升。考虑到Guided(b)增加了推理阶段的计算消耗,最终本文采用流柱式框架作为后续优化的基础框架。
2.1.2 显著性检测标注及损失函数
本文基于文献[13]的标注,采用迁移学习的训练方法,完成协同分支的训练。网络训练框架如图3(b)所示,首先将以ResNext101为特征提取结构的R3Net[16]显著性检测网络作为教师模型,通过已标注的部分显著性标签完成网络训练后,再对学生模型,即协同分支双线性插值后的结果进行像素级监督指导。本文通过KL-Loss计算两种网络检测结果分布的相似性,使协同分支的显著性检测结果与R3Net接近,其中KL-Loss的计算为



表1 R3Net显著性检测结果的定量分析
2.2 基于样本显著性的分类损失函数设计
RetinaNet算法针对目标的分类损失采用Focal-Loss函数[15],该函数将预测得分与交叉熵损失相结合,使网络更关注难分样本,忽略大量易分样本,从而缓解网络正负样本不平衡的问题。但在红外行人检测中,红外图像分辨率普遍较低,存在大量噪声样本。在Focal-Loss的影响下,网络过度关注这些特征空间中的离群点,而忽略了大量具有普适性特征的行人目标。这种现象严重影响了网络的泛化性能,导致网络产生大量误检结果。

图6 教师网络R3Net的部分显著性检测结果可视化。奇数列为红外图像,偶数列为显著性检测结果
本文对不同显著性强度的样本进行分析,部分样本如图7所示。本文发现这类特征质量较差的样本往往不具备良好的显著性表达。因此,得益于多任务学习框架,本文考虑将协同分支所预测的显著性检测结果转为显著性得分,并作为样本的先验信息引入目标检测的标签中,以合理方式降低显著性较差的样本权重,从而使网络学习到更加泛化的行人特征。本文将从样本显著性得分因子的计算和分类损失设计两个方面进行分析。
2.2.1 样本显著性得分因子计算




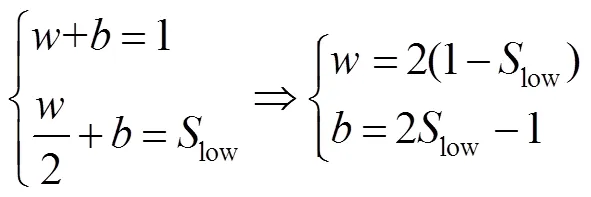
2.2.2 Smooth Focal-Loss函数

图7 协同分支的部分显著性检测结果可视化。(a) 显著性较强样本;(b) 显著性较差样本

图8 (a) 不同参数下显著性得分因子的映射函数曲线;(b) 部分映射结果可视化。红框为检测label,数字为计算的显著性得分因子Si
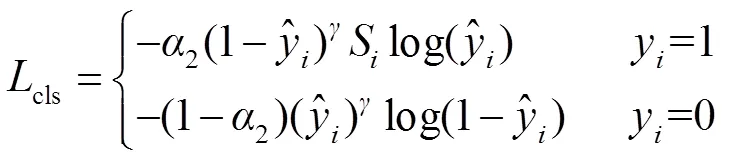

2.3 算法整体计算步骤
3 实验结果
3.1 实验细节
3.1.1 实验环境
本文采用Pytorch框架完成所有算法的训练和测试。网络ResNet50部分参数在ImageNet数据集中完成预训练,其余参数采用Xavier方法进行初始化。本文采用Adam优化器以0.0001的学习率在单个NVIDIA TITANX GPU上训练40轮。学习过程中,本文将单批数量设置为8,锚框长宽比为0.42,并在4个不同尺度上分别设置[1, 1.4, 1.7]三个不同大小的框。在训练过程中,本文采用数据增强方法对样本进行随机增强,包括:随机裁剪、缩放、翻转、归一化等方法,并通过随机通道对比度、亮度等模拟红外成像所产生的噪声干扰。在测试过程中,本文采用阈值为0.3的非最大值抑制以去除预测过程产生的大量重复框。针对显著性检测网络R3Net,本文采用0.9动量,学习率为0.001的SGD优化器,单批数量为10进行9000次迭代训练。
3.1.2 数据集
本文在KAIST多光谱数据集上进行实验测试。其中该数据集包含95328张配准的可见光¾远红外图像对,并包含1182个独立的行人样本。本文仅采用红外部分图像用于本文的实验。本文采用与文献[14]一致的实验方案,即训练集采用文献[24]中提供的清洗后的训练标注,而测试集采用文献[6]提供的测试标注,测试集按照行人检测的合理设置[5]进行测试。其中测试图像有2252张图像样本组成,其包含1455张白天图像与797张夜晚图像供实验分析。为了完成显著性检测任务且保证实验的合理性,本文采用Ghost等人提供的1701张像素级标注。这些标注均从训练集中采集而不包含任何测试集信息。
3.1.3 评估指标
针对行人检测,本文借助于KAIST标准评估工具对行人检测结果进行评估,其中采用对数平均丢失率(log-average miss rate,MR-2)对检测性能进行量化。该指标计算方式为在[10-2, 100]中的单张图片误检数(false positive per image,FPPI)按对数间隔均匀取9个点,并由每个点所对应的最小丢失率(miss rate,MR)的对数平均值计算所得。FPPI和MR的计算式如下:




Precision为所有预测为正的样本中,实际为正的样本比例。Recall则为所有实际为正的样本中能够有效检出的比例。其中AP指标主要用于统一衡量Precision及Recall的整体情况,AP越大表明目标检测的综合性能越强。由于本文仅针对行人单类目标进行分析,因此mAP与AP值相同。
3.2 消融实验分析
3.2.1 多任务学习框架性能测试
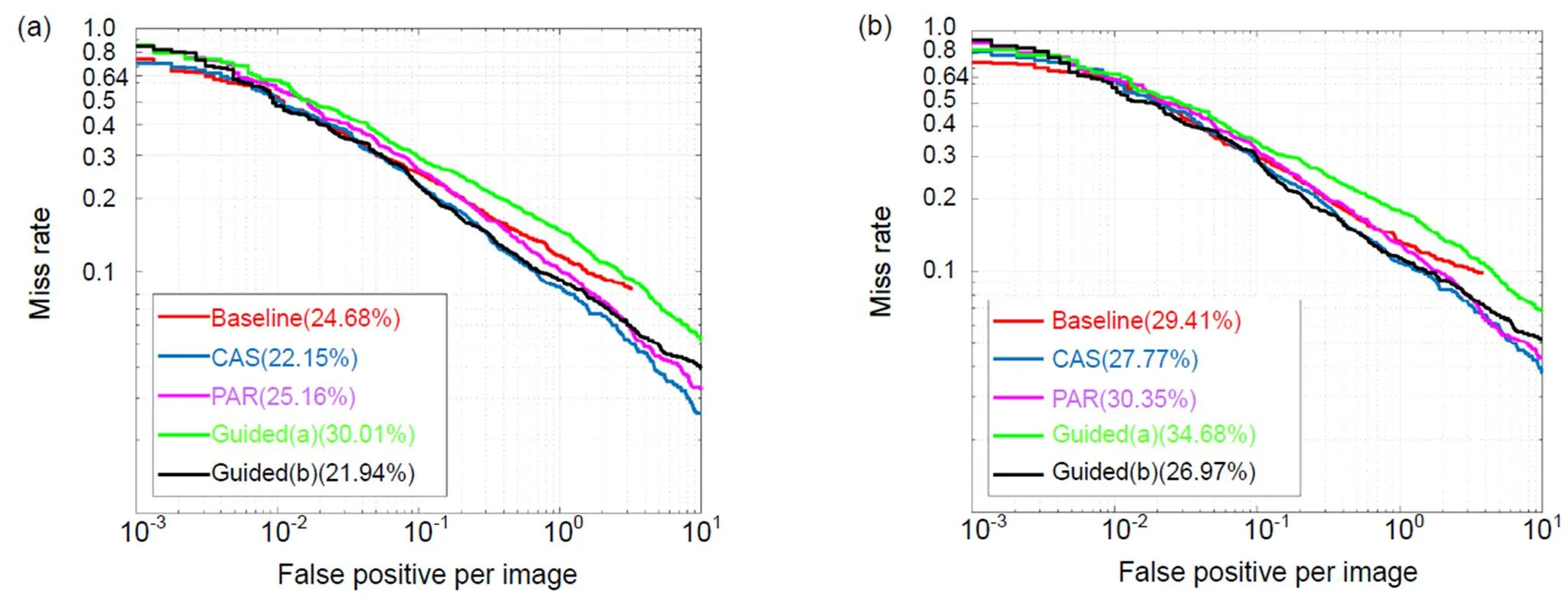
本文在数据集中完成了2.1中设计的PAR、CAS、Guided(a)、Guided(b)这4种方案的性能测试,其中测试结果如表2、表3及图9。
通过对表2、表3及图9的数据分析,本文可得到以下结论:
1) 采用流注式的多任务网络(CAS)丢失率低于基准网络,这说明引入合理的显著性检测分支结构能够从侧面强化行人检测的性能。
2) 引导式注意力模型(Guided(a))由于采用单通道复制的方法直接与原特征通道数匹配,破坏了原有的特征分布情况,MR-2上升7.86%。而模型(Guided(b))通过将与注意力特征重新结合,强化了特征提取网络,对原有检测分支添加了近似自注意力的结构,MR-2下降0.21%。但在推理时仍需要保留分支网络,加大了计算消耗。
3) 在独立学习式框架中,多尺度并行框架相较于
基准网络MR-2反而上升0.48%,其精度的损失主要来源于不同尺度目标特征分布的差异性,由于不同层级分支网络等权重的反向传播分支损失,使其难以适应这种差异性而进行等效的优化,造成了性能的下降。考虑到以上三点,本文将采用CAS模型作为多任务学习的基本方案,并在此基础上完成对基于显著性的损失函数性能研究。

表2 独立学习式框架性能测试

表3 引导注意力式框架性能测试
3.2.2 基于样本显著性的分类损失函数性能研究

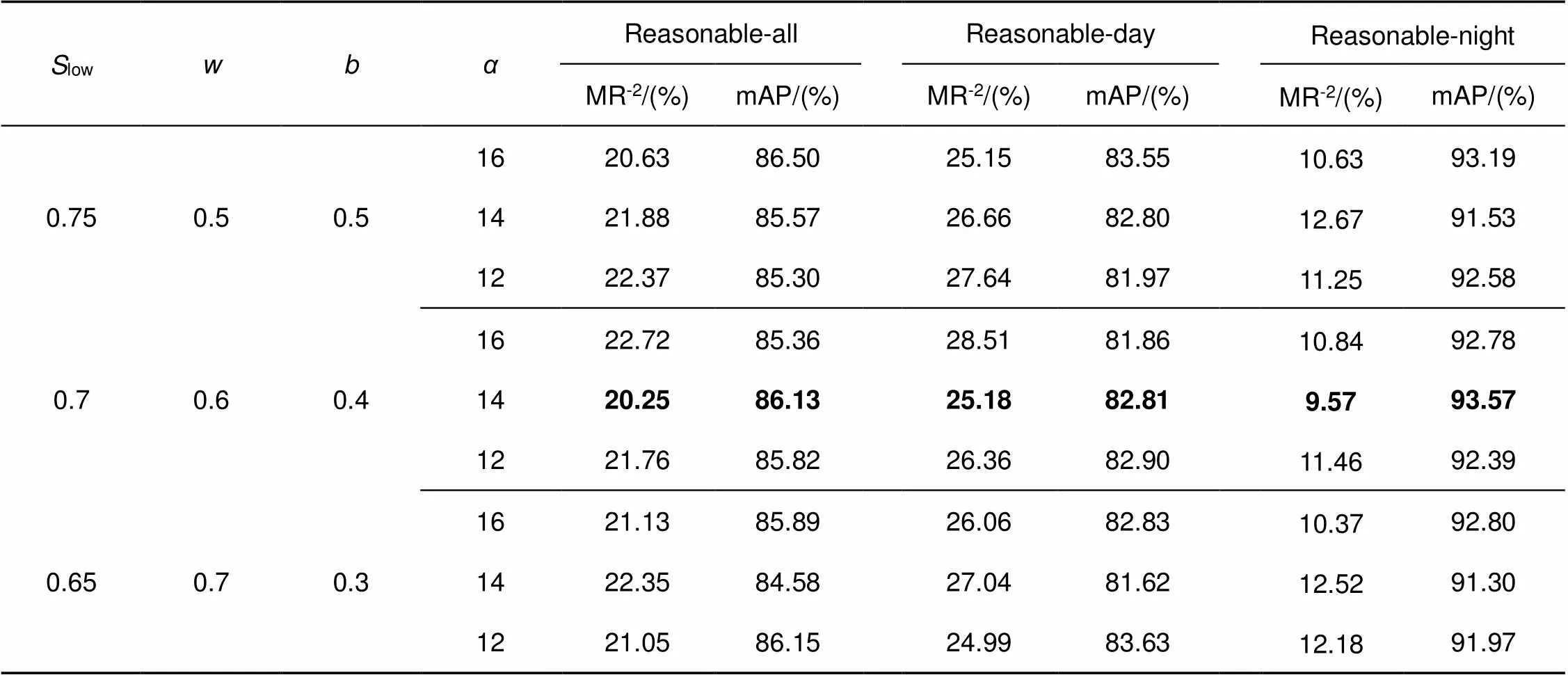
表4 不同参数下的检测性能对比实验
3.3 与主流红外行人检测算法的对比分析
本文将该算法与目前主流的红外行人检测算法Faster RCNN-T[13],Faster RCNN+SM[13],Bottom up[25],TC-thermal[14],TC-Det[14],RetinaNet[15](baseline),RetinaNet+SM进行了对比,对比结果如表5所示。RetinaNet+SM在RetinaNet基础上采用与文献[13]相同的方式对原图进行显著图的堆叠。
表中MR-2-all, MR-2-day, MR-2-night分别代表全天、仅白天、仅夜晚情况下的行人检测丢失率,(CAS+Smooth FL)表示采用本文CAS分支模型且通过设计的Smooth Focal-Loss损失函数进行优化,根据表中数据可得本文的多任务学习相较于baseline能够有效降低4.43%,其中白天下降4.23%,夜晚下降5.84%。由于本文设计的网络框架强化了检测器对显著目标的关注,误检现象大幅度减小,最终检测效果如图10所示。实验结果表明,采用本文多任务学习方式的检测结果优于直接对原图进行增强的方法(MR-2分别为20.25%与23.47%),且在测试阶段无需通过额外的网络进行显著性图的预测。

表5 KAIST 红外行人检测算法性能测试对比,其中+SM 表示采用文献[13]的方式引入显著图

图10 5个场景下真实值及不同模型的检测结果。
(a) 真实值;(b) RetinaNet;(c) 本文模型检测结果;(d) 协同分支显著性检测结果
Fig. 10 Partial test results.
(a) Ground-truth; (b) Baseline; (c) Ours detection result; (d) Saliency detection result of the auxiliary network
4 结 论
本文提出了一种用于红外行人检测的多任务学习框架。针对红外图像质量较差,缺乏样本色彩及细节信息的问题,引入显著性检测任务,从侧面引导检测网络对强显著区域的关注。同时,针对红外图像中存在大量噪声样本的问题,将协同分支显著性检测的结果映射为每个样本的显著性得分因子,在分类损失中抑制噪声样本对网络学习的影响。最终,实验测试结果证实了方法的有效性,并能够在不增加推理计算消耗的同时,相较于基准算法RetinaNet有效降低4.43 MR-2。但是,本文方法仍受限于大量手工设计的参数。如何使网络以自适应的方式适应各种复杂场景将作为下一步研究的重点。
[1] Zhang L L, Lin L, Liang X D,. Is faster R-CNN doing well for pedestrian detection?[C]//, 2016: 443–457.
[2] Li J N, Liang X D, Shen S M,Scale-aware fast R-CNN for pedestrian detection[J].2018, 20(4): 985–996.
[3] Zhang B H, Zhu S Y, Lv X Q,. Soft multilabel learning and deep feature fusion for unsupervised person re-identification[J]., 2020, 47(12): 190636.
张宝华, 朱思雨, 吕晓琪, 等. 软多标签和深度特征融合的无监督行人重识别[J]. 光电工程, 2020, 47(12): 190636.
[4] Zhang X Y, Zhang B H, Lv X Q,. The joint discriminative and generative learning for person re-identification of deep dual attention[J]., 2021, 48(5): 200388.
张晓艳, 张宝华, 吕晓琪, 等. 深度双重注意力的生成与判别联合学习的行人重识别[J]. 光电工程, 2021, 48(5): 200388.
[5] Hwang S, Park J, Kim N,. Multispectral pedestrian detection: Benchmark dataset and baseline[C]//, 2015: 1037–1045.
[6] Liu J J, Zhang S T, Wang S,. Multispectral deep neural networks for pedestrian detection[Z]. arXiv preprint arXiv:1611.02644, 2016.
[7] Wang R G, Wang J, Yang J,. Feature pyramid random fusion network for visible-infrared modality person re-identification[J]., 2020, 47(12): 190669.
汪荣贵, 王静, 杨娟, 等. 基于红外和可见光模态的随机融合特征金子塔行人重识别[J]. 光电工程, 2020, 47(12): 190669.
[8] Zhang R Z, Zhang J L, Qi X P,. Infrared target detection and recognition in complex scene[J]., 2020, 47(10): 200314.
张汝榛, 张建林, 祁小平, 等. 复杂场景下的红外目标检测[J]. 光电工程, 2020, 47(10): 200314.
[9] Ren S, He K, Girshick R,. Faster R-CNN: towards real-time object detection with region proposal networks[J]., 2016, 39(6): 1137–1149.
[10] Redmon J, Divvala S, Girshick R,. You only look once: unified, real-time object detection[C]//, 2016: 779–788.
[11] John V, Mita S, Liu Z,. Pedestrian detection in thermal images using adaptive fuzzy C-means clustering and convolutional neural networks[C]//, 2015: 246–249.
[12] Devaguptapu C, Akolekar N, Sharma M M,. Borrow from anywhere: pseudo multi-modal object detection in thermal imagery[C]//, 2019: 1029–1038.
[13] Ghose D, Desai S M, Bhattacharya S,Pedestrian detection in thermal images using saliency maps[C]//, 2019: 988–997.
[14] Kieu M, Bagdanov AD, Bertini M,. Task-conditioned domain adaptation for pedestrian detection in thermal imagery[C]//, 2020: 546–562.
[15] Lin T Y, Goyal P, Girshick R,. Focal loss for dense object detection[C]//, 2017: 2999–3007.
[16] Deng Z J, Hu X W, Zhu L,R3Net: recurrent residual refinement network for saliency detection[C]//, 2018: 684–690.
[17] Koch C, Ullman S. Shifts in selective visual attention: towards the underlying neural circuitry[J].1985, 4(4): 219–227.
[18] Hou X D, Zhang L Q. Saliency detection: a spectral residual approach[C]//, 2007: 1–8.
[19] Montabone S, Soto A. Human detection using a mobile platform and novel features derived from a visual saliency mechanism[J].2010, 28(3): 391–402.
[20] Liu N, Han J W, Yang M H. PiCANet: learning pixel-wise contextual attention for saliency detection[C]//, 2018: 3089–3098.
[21] Li C Y, Song D, Tong R F,. Illumination-aware faster R-CNN for robust multispectral pedestrian detection[J].2019, 85: 161–171.
[22] Li C Y, Song D, Tong R F,. Multispectral pedestrian detection via simultaneous detection and segmentation[Z]. arXiv preprint arXiv:1808.04818, 2018.
[23] Guo T T, Huynh C P, Solh M. Domain-adaptive pedestrian detection in thermal images[C]//, 2019: 1660–1664.
Multi-task learning for thermal pedestrian detection
Gou Yutao1,2,3, Ma Liang1,2,3, Song Yixuan1,2,3, Jin Lei1,2, Lei Tao1,2*
1Photoelectric Detection Technology Laboratory, Chinese Academy of Sciences, Chengdu, Sichuan 610209, China;2Institute of Optics and Electronics, Chinese Academy of Sciences, Chengdu, Sichuan 610209, China;3University of Chinese Academy of Sciences, Beijing 100049, China

The visualization of pedestrian samples in KAIST
Overview:In recent years, pedestrian detection techniques based on visible images have been developed rapidly. However, interference from light, smoke, and occlusion makes it difficult to achieve robust detection around the clock by relying on these images alone. Thermal images, on the other hand, can sense the thermal radiation information in the specified wavelength band emitted by the target, which are highly resistant to interference, ambient lighting, etc, and widely used in security and transportation. At present, the detection performance of thermal images still needs to be improved, which suffers from the poor image quality of thermal images and the interference of some noisy samples to network learning.
In order to improve the performance of the thermal pedestrian detection algorithm, we firstly introduce a saliency detection map as supervised information and adopt a framework of multi-task learning, where the main network completes the pedestrian detection task and the auxiliary network satisfies the saliency detection task. By sharing the feature extraction modules of both tasks, the network has saliency detection capability while guiding the network to focus on salient regions. To search for the most reasonable framework of the auxiliary network, we test four different kinds of design from the independent-learning to the guided-attentive model. Secondly, through the visualization of the pedestrian samples, we induce noisy samples that have lower saliency expressions in the thermal images and introduce the saliency strengths of different samples into the classification loss function by hand-designing the mapping function to relieve the interference of noisy samples on the network learning. To achieve this goal, we adopt a sigmoid function with reasonable transformation as our mapping function, which maps the saliency area percentage to the saliency score. Finally, we introduce the saliency score to the Focal Loss and design the Smooth Focal Loss, which can decrease the loss of low-saliency samples with reasonable settings.
Extensive experiments on KAIST thermal images have proved the conclusions as follows. First, compared with other auxiliary frameworks, our cascaded model achieves impressive performance with independent design. Besides, compared with the RetinaNet, we decrease the log-average miss rate by 4.43%, which achieves competitive results among popular thermal pedestrian detection methods. Finally, our method has no impact on the computational cost in the inference process as a network training strategy. Although the effectiveness of our method has been proven, one still needs to set the super-parameters manually. In the future, how to enable the network to adapt to various detection conditions will be our next research point.
Gou Y T, Ma L, Song Y X,Multi-task learning for thermal pedestrian detection[J]., 2021, 48(12): 210358; DOI:10.12086/oee.2021.210358
Multi-task learning for thermal pedestrian detection
Gou Yutao1,2,3, Ma Liang1,2,3, Song Yixuan1,2,3, Jin Lei1,2, Lei Tao1,2*
1Photoelectric Detection Technology Laboratory, Chinese Academy of Sciences, Chengdu, Sichuan 610209, China;2Institute of Optics and Electronics, Chinese Academy of Sciences, Chengdu, Sichuan 610209, China;3University of Chinese Academy of Sciences, Beijing 100049, China
Compared with high-quality RGB images, thermal images tend to have a higher false alarm rate in pedestrian detection tasks. The main reason is that thermal images are limited by imaging resolution and spectral characteristics, lacking clear texture features, while some samples have poor feature quality, which interferes with the network training. We propose a thermal pedestrian algorithm based on a multi-task learning framework, which makes the following improvements based on the multiscale detection framework. First, saliency detection tasks are introduced as an auxiliary branch with the target detection network to form a multitask learning framework, which side-step the detector's attention to illuminate salient regions and their edge information in a co-learning manner. Second, the learning weight of noisy samples is suppressed by introducing the saliency strength into the classification loss function. The detection results on the publicly available KAIST dataset confirm that our learning method can effectively reduce the log-average miss rate by 4.43% compared to the baseline, RetinaNet.
thermal pedestrian detection; multi-task learning; saliency detection
10.12086/oee.2021.210358
* E-mail: taoleiyan@ioe.ac.cn
苟于涛,马梁,宋怡萱,等. 基于多任务学习框架的红外行人检测算法[J]. 光电工程,2021,48(12): 210358
Gou Y T, Ma L, Song Y X,Multi-task learning for thermal pedestrian detection[J]., 2021, 48(12): 210358
TP391.41;TN215
A
2021-11-12;
2021-11-30
苟于涛(1997-),男,硕士,主要从事基于深度学习的目标检测和多模图像融合识别的研究。E-mail:gouyutao19@mails.ucas.ac.cn
雷涛(1981-),男,博士,研究员,主要从事基于传统方法及深度学习技术的图像处理与分析、复杂场景下目标检测识别与跟踪等方面的研究。E-mail:taoleiyan@ioe.ac.cn
