基于多传感融合的有轨电车在途障碍物检测方法研究
2021-02-28杨峥岭
张 勇,王 磊,杨峥岭,徐 梦
(1.通号万全信号设备有限公司自动化研究院,北京 310008;2.通号万全信号设备有限公司项目中心,北京 310008)
1 研究背景
有轨电车一般采用混合路权的形式,在一定程度上增加了安全事故发生的风险。有轨电车的安全保障除依赖于信号系统、轧道车轨道巡检外,还依靠行车司机的在途确认,当交通发生拥堵、车流较大、天气恶劣、突发状况或司机疲劳时,极易产生安全事故或疏漏。因此,在加强司机安全意识、规范司机行车的同时,更需要可靠的、智能的技术手段辅助司机驾驶,为行车安全提供保障。
在途列车障碍物检测技术是目前列车安全驾驶的辅助技术手段之一,其功能在于检测列车轨行区域内是否存在行人、社会车辆、异物等,并在危险时对司机发出警示,以减少列车发生碰撞造成安全事故的风险。其实现依赖于视觉传感器、激光雷达、毫米波雷达、红外传感器等检测元器件以及相应的检测算法,如深度学习、支持向量机(SVM)分类器、卡尔曼滤波算法等。一般情况下,使用多传感融合的方式,即采用2种或多种技术手段共同对轨行区进行检测,可达到优势互补、提升识别效率的目的。
2 在途障碍物检测方法发展现状
在众多常见的障碍物检测手段中,基于深度学习的视觉传感器检测、识别方法使用日趋广泛。其中,基于单定点多边框检测器(SSD)算法的卷积神经网络模型通过使用自适应感受野特征回归的方式,实现了准确度与速率的平衡优化;该优化使得SSD卷积神经网络模型可以更好地完成有轨电车在途障碍物检测工作,在准确提取障碍物特征的同时,做到实时更新在途信息,为司机行车做出有效辅助。
激光雷达在轨道交通行业亦有较为广泛的应用。视觉传感器受天气、光线条件影响较大,而激光雷达可以克服这些因素对检测结果的影响。在正常情况下,视觉传感器结合神经网络算法的检测能力强于激光雷达的检测识别能力,故而激光雷达和视觉传感器形成了非常有效的互补。
因此,为发挥视觉传感器及激光雷达检测的自身优势,达到更为优异的检测效果,本文旨在以SSD卷积神经网络为基础,结合视觉传感器以及激光雷达的技术特点,提出一种基于多传感融合的有轨电车在途障碍物检测方法。
3 在途障碍物检测方法
3.1 SSD卷积神经网络介绍
SSD保留了传统卷积神经网络框架,同时以候选框机制为基础对其识别方式进行优化。在目标检测、识别过程中,该网络依据默认配置,在识别图片上生成多个不同大小的识别框,通过采样对每个识别框需要的偏移量以及置信度进行计算,以确认目标的种类及位置。SSD官方给出的检测速率为59 F/s,平均全类别识别准确率(mAP)为74.3%,是一种兼顾识别速率和准确率的卷积神经网络。其原始网络结构如图1所示。
3.2 激光雷达检测障碍物原理
激光雷达内部包含一组扫描线(激光器),其线数一般为16线、32线或更多。扫描线在激光雷达内部按照垂直方向均匀分布。同时,激光雷达内配有一台横向旋转电机,带动激光器360°水平旋转,向周边射出激光束进行扫描,并根据反射回的激光束相位、时间等信息构建周围环境的点云图,同时保存相关距离和位置信息。
在有轨电车行进过程中,一般采用直角坐标系评价车辆与障碍物之间的关系,而激光雷达得到的点云信息实质上是激光束的水平、垂直旋转角信息,以及在该方向上的距离信息,即球坐标系。通过对比实际点位在2种坐标系下的位置信息关系,对激光雷达采集的数据进行校定,从而得到有轨电车障碍物的位置信息。
3.3 传感融合
激光雷达的点云数据转换为列车所用的直角坐标后,通过对其扫描范围进行标定的方式使其与视觉传感器采集回的信息做“一一对应”。此时,视觉传感器采集到的环境信息不仅包含物体的颜色、轮廓信息,还包含相应的距离信息。同时,激光雷达自有的障碍物检测功能,还可以为基于视觉传感器的检测方法提供一定的辅助,尤其是在可见度严重不足时,该功能便显得尤为重要。当获得一组包含视觉传感器及激光雷达检测信息的数据时,分别使用SSD卷积神经网络检测算法和激光雷达检测算法对其进行障碍物检测,若仅是单一方法检测到障碍物,则仅对司机做出提示;若是2种方法同时检测到障碍物,且距离小于有轨电车的安全制动距离(一般选定为50 m),则发出报警提示司机注意。其具体流程如图2所示。
另外,视觉传感器和激光雷达的采集速率存在较大差异,为防止信息不同步的现象产生,需要对2种传感器采集到的数据做融合处理,但由于视觉传感器的采集周期大于激光雷达,因此对激光雷达的采集信息进行缓存,并通过队列的方式与视觉传感器采集到的图片信息共同保存。具体步骤如下:
(1)开辟2片缓存区域,即缓存a和缓存b;
(2)激光雷达实时采集周围环境信息,保存在缓存 a中,并覆盖原有数据信息;
(3)视觉传感器在采集到1帧图片后,从缓存a中读取数据,打上时间戳后共同保存至缓存b;
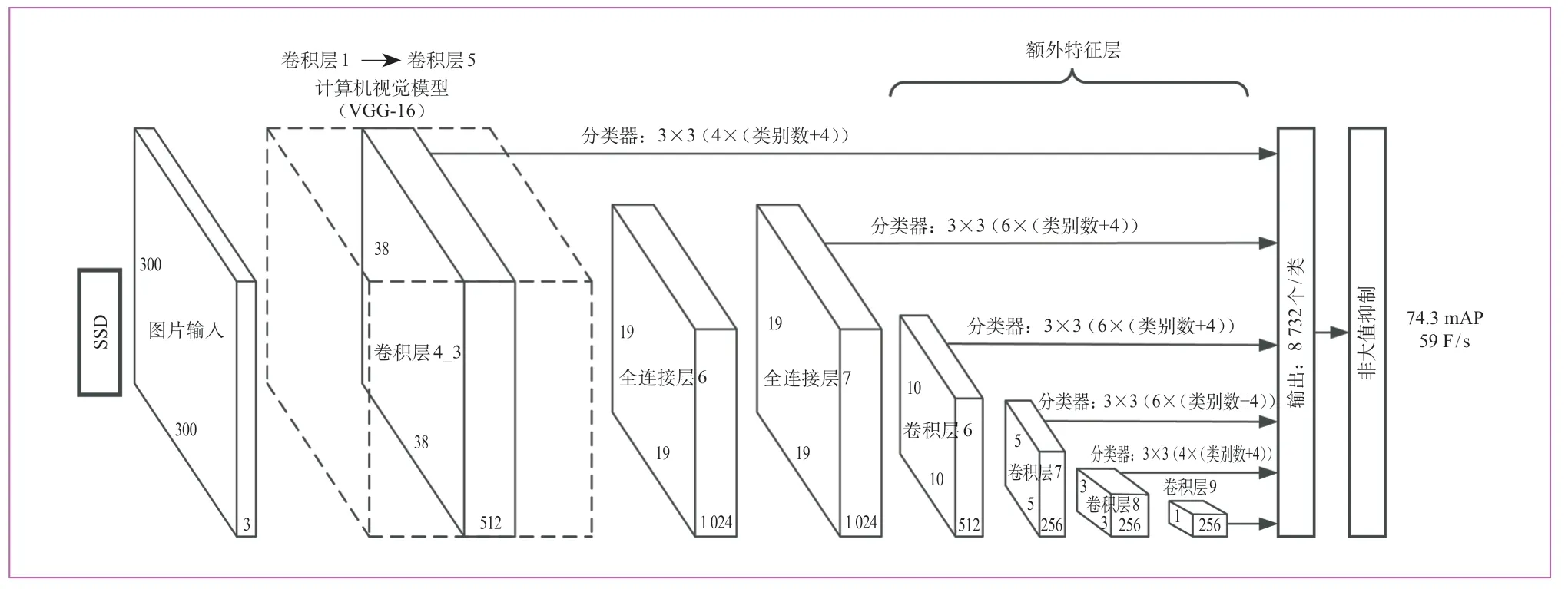
图1 SSD原始网络结构
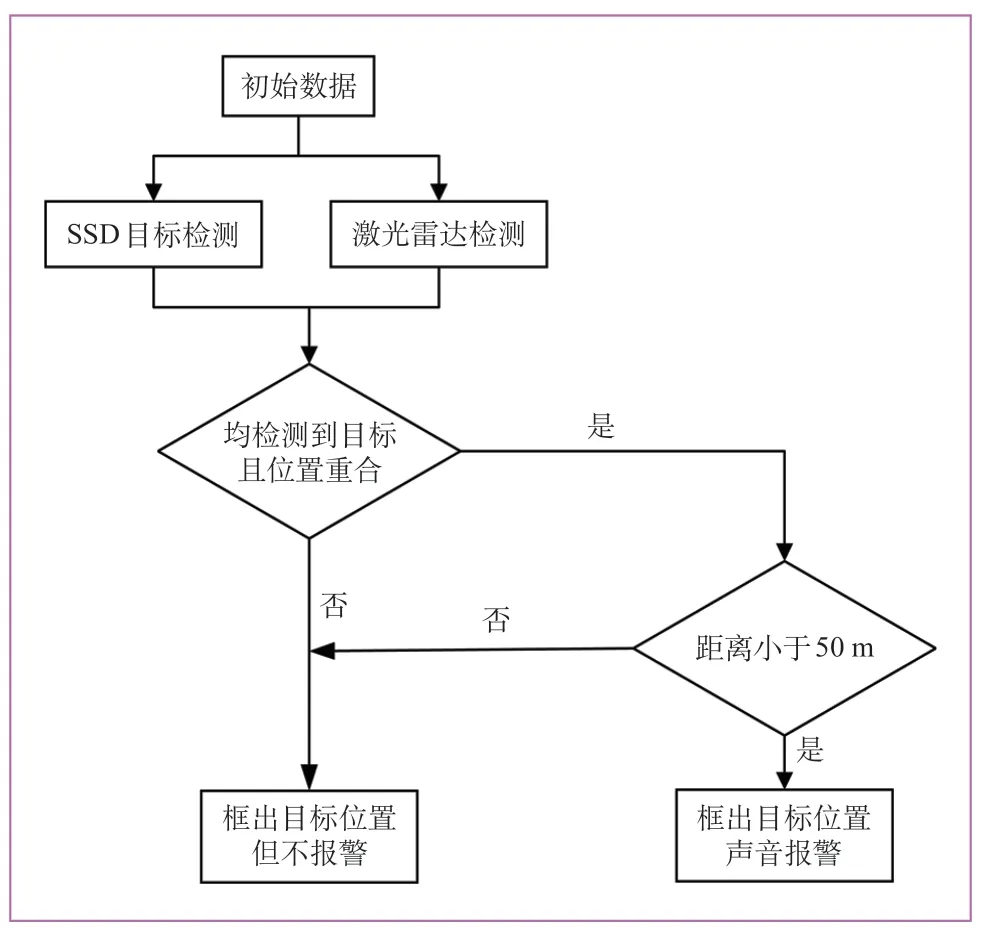
图2 视觉传感器及激光雷达融合后的障碍物报警提示流程
(4)不断检查缓存b,若缓存b为空,则不进行任何操作;若缓存b不为空,则清空该片缓存,并依据图 2所示的步骤对其进行检测。
该方法可以保证缓存b中永远保存当前时刻采集到的最新数据,以确保数据的同步性和实时性。同时,由于检测流程所需时间小于视觉传感器采集1帧图片的时间,故而在流程完成后,若没有新的数据采入则不做任何操作,以节约资源。
4 实验验证
4.1 数据集准备
在测试过程中,使用10 000帧采集自甘肃天水有轨电车现场的车辆运行视频作为训练集,其中包含社会车辆和信号机样本图片各5 000张,并使用SSD卷积神经网络对其进行学习。训练过程中设置单次抓取样本个数(batch_size)为24个,特征图尺度范围(anchor_size_bounds)为[0.15,0.90],为防止过拟合迭代,将次数设置为20 000次。同时,收集1 000组视频样本图片及其对应点云图作为测试集,以验证该方法的检测效果。
4.2 实验结果
将采用单一视觉传感器配合SSD卷积神经网络的障碍物检测方法(简称为“SSD”)与多传感融合后的障碍物检测方法(简称为“R+SSD”)做对比测试,测试结果如表1所示。
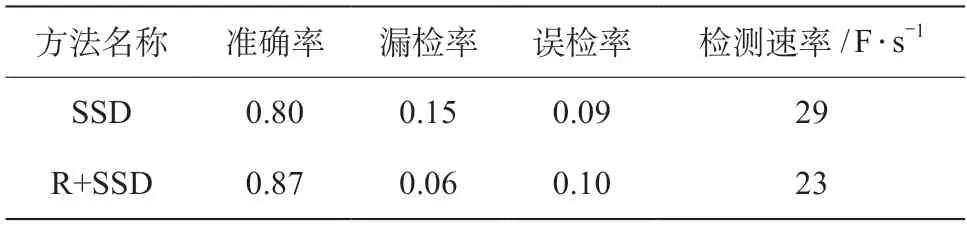
表1 SSD与R+SSD识别准确率对照
R+SSD识别效果如图3所示。
由表1和图3可得,SSD方法整体识别率约80%,除网络本身识别能力因素外,还与现场视觉传感器采集到的样本清晰度有关,若样本图像清晰度不够,在一定程度上制约了算法的识别能力,尤其是当目标较远、特征较小时尤为明显。R+SSD方法在误检率上虽然没有明显提升,但漏检率远低于SSD方法,主要是由于激光雷达本身并不具备目标识别能力,但对于轨行区域的障碍物,尤其是对中远距离障碍物有着很好的检测效果。因此,当视觉检测手段发生漏检时,激光雷达检测手段提供了一定的补足,提升了整体识别准确率。

图3 多传感融合后的障碍物识别效果
另外,激光雷达采集速率约为15 F/s,视觉传感器采集速率约为10~20 F/s,而R+SSD方法的检测速率约为23 F/s,大于2种传感器的采集速率,故而认为其可以做到对采集数据的实时检测。同时,在R+SSD检测方法中,视觉检测方法与激光雷达检测方法之间的融合率即二者同时检测到某一障碍物的概率为69%,考虑到视频清晰度不足、视觉检测方法目前可识别目标种类不多等因素,其看作一个可接受的融合率。后期,可通过优化激光雷达检测算法、提升视频清晰度、增加学习样本目标类别等方式予以提升。
5 结语
本文以SSD卷积神经网络为基础,通过多传感融合的方式,将视觉传感器障碍物检测与激光雷达检测相结合,提出了一种在途列车障碍物检测方法,并对其检测效果进行了验证。实验表明,该方法对于有轨电车在途障碍物检测有较强的适用性。
