支持冷启动用户推荐的区块链服务发布方案
2021-02-28董学文刘昊哲乔慧郑佳伟
董学文,刘昊哲,乔慧,郑佳伟
(西安电子科技大学计算机科学与技术学院,陕西 西安 710071)
1 引言
自2004 年服务计算的概念被正式提出以来,服务计算和云计算一直在高速发展。越来越多的服务信息需要在互联网上发布,并推荐给适合的用户使用。在这个过程中,服务发布系统是核心和关键。
本文解决的问题主要针对冷启动用户(即新进入系统缺乏用户行为特征的用户)的区块链服务发布和推荐。因为新用户缺乏用户特征,所以无法准确地用常用的协同过滤(CF,collaborative filtering)等算法进行推荐。
如图1 所示,传统的服务发布系统由以下3 个角色组成:服务请求者、服务提供者和服务管理中心。该系统的基本模型为:首先服务请求者向服务发布系统发出服务请求,服务管理中心在接收到服务请求之后发布其服务;然后有多个服务提供者竞争;最后服务请求者选择服务提供者来满足其请求。
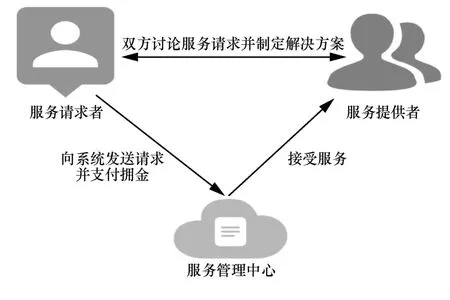
图1 传统服务发布系统
但是,这种模型存在严重不足。首先,这种传统的服务发布系统容易受到分布式拒绝服务(DDoS,distributed denial of service)攻击、远程劫持和恶作剧攻击,使某些服务发布功能无法使用。其次,大多数服务发布系统都运行在集中式服务器上,极易受到攻击,同时可能导致单点故障。再次,用户的敏感信息(例如姓名、电子邮件地址和电话号码)和任务解决方案保存在服务管理中心的数据库中,这存在数据丢失或篡改的风险。最后,对于这种服务发布系统,传统信任模型的弱点仍然是不可避免的挑战。
当前,已经有一些工作试图解决这些问题。例如,分布式体系结构用于确保传统服务发布系统的正常运行,同时,采用加密等方法来保护用户隐私与数据隐私,并提出了评分机制,以确保服务提供者和服务请求者之间相互信任,最大限度地避免作弊。
但是,这些问题很难被同时解决,而且这种传统的三角形结构在信任方面也不可避免地存在弱点。因此,本文提出一种基于区块链的分布式服务发布系统框架,以尽可能解决上述问题,使服务发布系统更加安全、可靠、公平。与传统的服务发布系统架构不同,本文提出的模型中,服务提供者将可以提供的服务发布到互联网上,然后服务管理中心向服务请求者推荐以进行浏览和选择,最后服务请求者与服务提供者进行交易。同时,还应注意在各种服务中如何准确有效地推荐服务请求者所需要的服务。协同过滤算法是一种广泛应用的推荐算法,利用某兴趣相投、拥有共同经验之群体的喜好来推荐用户感兴趣的信息,个人通过合作的机制给予信息相当程度的回应(如评分)并被记录下来以达到过滤的目的,进而帮助别人筛选信息,回应不一定局限于特别感兴趣的信息,特别不感兴趣的信息的记录也相当重要[1]。传统的CF 模型侧重于单域用户偏好预测,存在数据稀疏的问题。实际场景中经常存在多个项目领域,并且不同域中的用户偏好是相关的,例如喜欢幽默书的用户通常偏爱喜剧电影。因此,跨域协同过滤(CDCF,cross-domain collaborative filtering)被提出以通过多域评估来丰富目标领域的知识,并且这已成为一个新兴的研究主题。由于数据极为稀少,因此在一个区域内向冷启动用户提供可靠的推荐结果仍然具有挑战性。但是,大多数CDCF 模型,例如CBT(code book transfer)[2]、RMGM(rating-matrix generative model)[3]和TCF(transfer by collective factorization)[4],都是为了减轻单域数据问题而设计的,未能充分讨论如何有效地实现冷启动用户的精准推荐。
此外,还有一个问题亟待解决。一个不太喜欢参与某一项目领域的用户可能参与另一个项目领域[5],例如电影和音乐代表着不同的领域。因此,本文专注于为冷启动用户提供跨域推荐,并根据其中的项目类型级别对域进行分类。例如,科幻电影和喜剧电影属于同一领域。在本文的问题设置中,冷启动用户仅在辅助域中评分,这与以前的大多数工作不同。在不考虑冷启动用户的情况下,假设辅助域中的数据相对于目标域中的数据[6]更小,多个域中共同出现的用户称为链接用户。链接用户是模型跨领域的知识桥梁。向目标域中的冷启动用户进行推荐是一项艰巨的任务。首先,不同项目域的评分矩阵存在稀疏情况,因此如何更好地建模用户在不同域中的独特特征变得非常重要。其次,在目标域中没有冷启动用户的评分数据,并且在不同域中用户的评分行为或偏好设置是相关但不同的。因此,应该转让哪些知识以及如何跨域转让知识仍然是一个需要解决的问题。
2 相关工作
随着网络和移动设备的爆炸性增长,网页和服务发布的组合研究已成为一种新兴趋势。研究人员已经提出了一些服务架构和推荐技术。
面向服务的体系结构(SOA,service-oriented architecture)具有比传统体系结构更多的功能,如可重用性、可组合性、分布式部署和其他功能,因此在业界得到了广泛认可。近年来,面向服务的体系结构已经被讨论了很多次,但是尚未确定最合适的方法。Anurag 等[7]为了解决面向服务的体系结构中的服务识别问题,包括自下而上和自上而下的功能,提出了一种“中间相遇”方法模型。Zisman 等[8]提出了基于统一建模语言(UML,unified modeling language)的服务发现框架,它是面向服务的体系结构中最可靠的服务识别机制之一。Cheng 等[9]提出了一种面向SOA 的安全体系结构设计。Hasselbring 等[10]指出,微服务架构提供了可以彼此独立部署和扩展的小型服务,并且可以使用不同的中间件堆栈来实现它们。微服务架构旨在克服单片架构的缺点,在单片架构中,所有应用程序逻辑和数据都在可部署单元中进行管理。Sill[11]在物联网的背景下提出了一种微服务架构的新范式,同时指出了采用微服务架构的优势。
推荐技术方面,为了更准确、更有效地拟合观察到的等级,研究人员提出了大量的单域层、次矩阵分解模型[12-13]。Razzaque 等[14]认为,邻域模型可以有效地检测局部关系,而潜在特征模型通常可以有效地估计整体结构。Wang 等[15]则利用这2 种方法,将用户相似度纳入矩阵分解过程。TagiCoFi[16]旨在提高传统矩阵分解(MF,matrix factorization)模型[17-19]的性能,可以看作MF 模型的总结[20],其中每个域都有其自己的用户因子矩阵,但它依赖于标签信息,另外也未考虑冷启动用户。
对于冷启动问题,目前已有基于标记和审查的跨域分解模型[21-24]。文献[25-26]尝试使用多层感知机(MLP,multilayer perceptron)和转换矩阵来映射跨域用户特征向量,但它们考虑了所有链接用户,导致计算量较大,并且特征提取效果不佳。Wang 等[15]提出了一种针对目标域中冷启动用户的跨域潜在特征映射(CDLFM,cross-domain latent feature mapping)模型,该模型在矩阵分解过程中考虑了用户相似性。但是,它仅包含一个辅助域,由于相似度的计算成本高而需花费更多时间,并且由于考虑每个冷启动用户的个性化功能而增加了模型的复杂性。本文以一种更易于解释的方式综合多个域中映射的潜在特征。
国内区块链技术的应用研究方面,何蒲等[27]对区块链技术的应用前景进行了总体性概述,对相关应用问题进行了深入探讨。王妙娟[28]和张小华[29]论述了区块链技术在物流快递中的应用场景。许涛[30]从教育的维度,讨论了在教育领域应用区块链技术的可能性与现状。王凯正[31]就众筹模式存在的第三方支付信任问题,设计了基于区块链技术的众筹平台。王博等[32]以区块链技术为基础,提出智慧平台建设,利用智能合约将智慧城市各个部分进行整合,并结合大数据技术,有效解决了成本、开放度、灵活性等问题。韩爽等[33]针对传统交易平台不能保证资产安全性的问题,提出了利用区块链技术实施新型数字资产安全交易的方案。
3 系统模型
本节描述基于区块链的服务发布系统模型及其工作流程。
3.1 服务发布系统模型
本文所提的服务发布系统模型主要包含以下4种角色:服务请求者、服务提供者、服务管理中心以及区块链,具体如图2 所示。
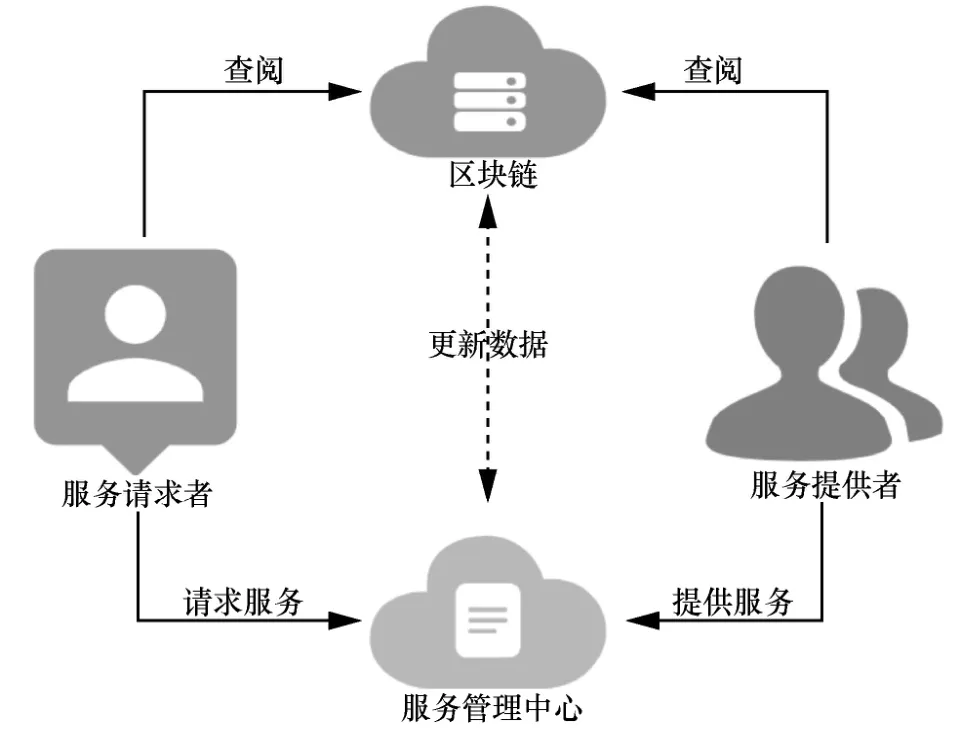
图2 服务发布系统模型
服务请求者将服务请求信息发送给服务管理中心,服务管理中心将这些信息存储在区块链上,并等待服务提供者接受服务请求信息,服务允许请求者和服务提供者浏览区块链上所有已发布的服务请求。
3.2 区块结构
区块结构如图3 所示。区块结构中,首先是一个与其他块区分的唯一编码格式,称为区块格式。下一个字段是区块的大小,其表示该字段之后区块的大小。区块头在区块大小之后,存储了区块的头信息,主要由版本号、上一个区块的哈希值、本区块体的哈希值(Merkel 根),以及时间戳、难度目标、Nonce 等信息组成。其对区块网络中保持不变性起到至关重要的作用。当攻击者想要修改区块头时,攻击者应该能够从创世块开始修改所有区块头,以伪造该区块的记录。但是,区块头包含上一个区块的哈希,即sha-256 哈希,此哈希值的作用是不更改上一个区块头就无法更改当前区块头,这样可以最大限度地保证链上各区块的完整性,有助于确保网络的更高级别的安全性。在恶意活动的情况下,区块不匹配将警告系统可触发数据取证可疑事件。
区块头之后是区块信息字段,存储服务管理中心的节点签名、服务提供者的信息、服务请求者的信息以及服务相关状态的信息和服务进度情况。
3.3 工作流程
服务发布系统交互过程如图4 所示。首先,服务请求者和服务提供者由服务管理中心进行注册和统一管理。每个提供者都具有代表其服务质量的评分。该分数的初始值是此类服务的所有提供者的平均分数。服务请求者根据其提供的服务质量进行评价,使服务质量评分增加或减少。系统会将与该服务提供者过往评分相差较大的数据作为恶意数据剔除,并将其余有效数据计算平均分,作为该服务提供者的正式评分。服务发布系统会将每个服务提供者和请求者的用户信息存储在数据库中,以便随时查阅。

图3 区块结构
本文所提的服务发布系统中,要求服务提供者将他们可以提供的服务信息上传到服务管理中心,并在数据库中存储信息。服务请求者创建账户后,服务管理中心将根据请求者的个人偏好向其推荐服务。同时,服务请求者可以查看任何服务提供者的服务评估,并决定是否向其发布请求。

图4 服务发布系统交互过程
服务提供者接受请求后,服务管理中心将服务内容、服务提供者的详细信息、服务佣金和其他相关内容通知服务请求者。当服务请求者确认信息并同意时,服务管理中心正式创建服务合同并将其上传到区块链。在服务合同生效期间,服务提供者将定期上传当前服务的最新进度,以确保服务请求者可以随时检查请求进度。服务提供者终止服务时,将最后一次上传服务进度,服务管理中心将结果反馈给服务请求者。服务请求者确认服务的完成,并支付相应的佣金。同时,服务提供者应根据服务的相关条件进行升级,以影响其当前得分的变化。最后,服务提供者收到佣金,服务合同正式终止。从服务请求者创建请求直到服务提供者收到佣金的过程中,服务管理中心都会在区块链上记录每个合同的更改,以防篡改。整个事务结束后,事务的备份将存储在数据库中。
3.4 推荐
本节详细介绍解决冷启动问题的具体推荐过程。本文的模型中有3 个域,包括2 个辅助域和一个目标域。辅助域中的评分矩阵为和。Rs表示对2 个辅助域中的数据进行筛选后形成的一个矩阵,即可以作为一个新的辅助域。目标域中的评分矩阵为,其中,?表示缺失的评分值,Uc和Pc分别表示聚类级矩阵Rc经过分解后,得到的辅助域中用户和产品的潜在特征。Ut和Pt分别表示目标域中用户和产品的集合。参考Wang 等[15]对2 个域情况下冷启动用户的跨域推荐的定义,本文定义了3个域的情况下冷启动用户的跨域推荐,具体定义参考文献[15,34]。
本文的TADCDR(two auxiliary domains-base cross-domain recommendation)模型的工作流程如图5 所示,主要包括3 个阶段:潜在特征模型建立、潜在特征映射以及个性化的跨域推荐。在潜在特征模型的建立过程中,采用K-means 聚类算法建立用户和产品之间的聚类级矩阵Rc。同时,本文考虑目标域中的用户评分行为的相似性,以获得目标域内用户和项目的潜在特征。然后,在潜在特征映射过程中,为每个冷启动用户训练一个基于MLP 的潜在特征映射函数。最后,根据冷启动用户的偏好为他们提供个性化的跨域推荐。
3.4.1 潜在特征模型
TADCDR模型工作流程的第一步旨在获得辅助域和目标域中实体的潜在特征(即用户或产品)。本节主要介绍对辅助域数据的处理和对目标域数据的处理。

图5 TADCDR 模型的工作流程
1) 对辅助域数据的处理
①采用偏置矩阵分解,将评分矩阵R映射到低维度的潜在空间P∈ℝn×l和Q∈ℝm×l,其中R=PQT。
② 将K-means聚类算法应用于用户潜在空间P和项目潜在空间Q,使用户和项目分类到不同的聚类中。
某类用户对某类项目的聚类级评分矩阵可表示为


2) 对目标域数据的处理
首先,对目标域的用户−项目评分矩阵进行分解,并将用户之间评分行为的相似度整合到传统的矩阵分解过程中。
所述用户评分行为相似度的计算包含3 个方面:基于共同评分的相似度、基于不感兴趣猜测的相似度以及基于评分偏好值的相似度。
基于共同评分的相似度的计算式为


3.4.2 潜在特征映射
本节主要介绍知识迁移的过程。在这个过程中,系统可以通过训练辅助域和目标域的评分数据来获得一个特征映射函数以处理潜在特征匹配问题。使用MLP 方法作为映射函数具有以下优点。首先,MLP 可以很容易地捕获input-output 结构,因为映射函数的输入和输出都是K维向量。其次,作为一个非线性变换,MLP 比线性映射函数更灵活。下面,本文将详细描述一个基于MLP 的潜在特征映射模型。
对于冷启动用户,他们只能从辅助域获得其潜在的特征,而且所获得的潜在特征不能直接用于个性化且准确的推荐。然而,同一用户在不同领域的潜在特征可能是高度相关的。所以,本文采用MLP方法来获得映射函数Fu以及用户u在辅助域中的潜在特征向量,通过计算得到其在目标域中的映射特征向量;冷启动用户对目标域中全体项目Pt的评分预测为

3.4.3 个性化跨域推荐
如果没有给定目标域中某个用户或者产品的足够信息,系统就无法估计该用户或者产品的潜在特征以进行推荐。通过对其在辅助域的潜在特征的学习,以及辅助域与目标域之间的映射函数,便可以得到其在目标域的相应仿射潜在特征。例如,对于目标域中的用户ui,可以推导出它对应的仿射特征向量为

4 实验过程
本节在所建立的原型系统中,对所提的服务发布框架和推荐方案进行性能测试。
4.1 推荐测试
本节研究本文所提模型在真实的评分数据集上的效果,并与其他相关的跨域推荐模型进行比较。具体如下。
CCBMF-PT[22]:一种具有个性化阈值的聚类级矩阵分解模型。
EMCDR[23]:一个跨域推荐嵌入和映射框架。EMCDR 是面向冷启动用户的最新跨域推荐方法之一。
CDLFM[13]:一种考虑用户评分行为的跨域潜在特征映射模型。
4.1.1 实验设置
本文从Amazon 平台上的评分数据中提取了3 个真实的数据集用于性能评估,包括多个目标域,如图书、电影和音乐。首先,过滤很少评分的锚用户和产品。为了更好地评估实验性能,在每个数据集中随机选择了300 个用户的评分作为训练数据,剩下的200 个用户进行测试。潜在特征的维度K分别设置为5、10、20。
4.1.2 实验结果
本文比较了不同模型在不同参数配置下的性能,调整了不同模型的参数,并基于多个参数设置的最优组合报告了最佳的实验结果。本文以MAE(mean absolute error)为评价指标。
MAE 是平均绝对误差,是所有单个观测值与算术平均值的偏差的绝对值的平均。平均绝对误差可以避免误差相互抵消的问题,因此可以准确反映实际预测误差的大小。其计算式为

其中,TE表示测试集,|TE|表示测试集中评分的数量,分别表示用户u对产品i的真实评分和预估评分。MAE 值越小,评分预测准确度越高。
所有对比模型在不同参数配置下的MAE 性能如表1 所示。分别以图书、电影、音乐为目标域,MAE 的性能如图6 所示。从实验结果可以看出,在所有推荐模型中,最优的是本文所提TADCDR模型。与EMCDR 模型相比,CDLFM 模型具有更好的性能,这表明考虑用户相似性的方法可以获得有意义的知识。TADCDR 模型优于CDLFM 模型,这意味着从中学习的潜在特征可以提高性能,从类似用户中学习的映射函数更加合理。与现有模型相比,本文的TADCDR 模型对高级跨域潜在特征映射更有效。

表1 不同参数配置下模型的MAE 值
4.2 服务管理和区块链测试
服务管理中心会在页面上显示所有已发布的服务以及针对冷启动服务请求者的个性化推荐结果。同时,服务请求者可以查询现有服务的服务调用。请求者可以通过服务被调用的次数和提供的服务的质量来大致了解服务提供者的可靠性,以便提出新的服务请求或直接选择现有服务。
此外,区块链功能测试如下:图7 显示了存储在单个块中的内容,包括区块提示信息、区块哈希块号、数据和其他详细信息。
4.3 系统性能测试
本文针对所提系统进行了压力测试,主要针对系统服务发布能力的高并发性和吞吐量进行测试,并采用JMeter 线程组来模拟高并发情况下的服务吞吐量性能,实验结果如表2 所示。

图6 不同参数配置下的MAE 性能
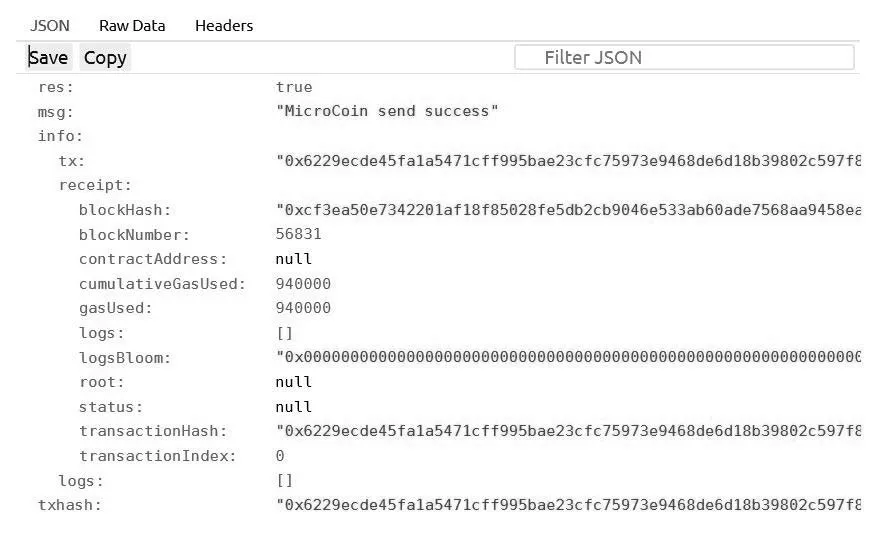
图7 单个区块信息
根据实验结果分析,系统的并发线程数可以达到1 100。当并发线程数达到1 150 和1 200 时,系统的异常率显著增加,吞吐量显著下降。
5 结束语
本文在传统服务发布架构的基础上,结合微服务架构,提出了一种具有松耦合、强大的容错能力和服务子域部署的服务发布架构,引入了区块链结构,可以更好地保证服务请求者和服务提供者的信息和财产安全。在向服务请求者提供服务建议方面,本文提出了一种TADCDR 模型,以便为冷启动用户提供更有效和个性化的跨域推荐。实验结果表明,本文所提的针对冷启动用户的个性化跨域推荐模型优于其他推荐方法。此外,本文对服务发布系统进行了压力测试,结果表明该系统可以为用户提供稳定、可靠、高效和开放的服务能力。

表2 系统性能
