基于深度学习的MOOC作弊行为检测研究
2021-02-28万子云陈世伟
万子云 ,陈世伟 ,秦 斌 ,聂 伟 ,徐 明
1 深圳大学电子与信息工程学院 深圳 中国 518061
2 深圳大学机电与控制工程学院 深圳 中国 518061
3 深圳大学信息中心 深圳 中国 518061
1 引言
近年来,大规模开放在线课程(Massive Open Online Courses,MOOC)作为一种全新的网络在线课程模式受到了广泛的关注,但是相比于线下教学,缺少了必要的监督,导致学习者通过作弊手段来完成相应的学习任务的现象层出不穷,例如刷课、抄袭、替考等。随着近几年高校对MOOC 学分认可度的提高,对MOOC 的作弊行为进行检测势在必行。
针对MOOC 存在的作弊问题,常规的解决方法分为两种,一种是采用被动防护的手段来阻止学习者作弊或者增加学习者作弊的难度;另一种则是采用主动的检测技术来发现作弊行为并进行相应的处理,以减少作弊行为的发生。对于第一种解决方法,一般是通过技术手段禁止学习者在在线学习过程做一些违规操作。例如,采用操作系统内核的API 调用技术、系统消息拦截技术、回调技术、钩子技术、注册表访问技术等手段对一些违规操作实施禁用或者屏蔽,从而达到禁止学生进行页面切换、答案复制及互助抄袭的目的,但是这种通过技术的手段来限制作弊的方法往往是不够的,因为计算机系统庞大复杂,这种硬编码的防护方法在新的作弊手段下效果欠佳,所以还是需要采用检测技术来对作弊行为进行检测。
对于MOOC 的作弊行为检测,工程应用上一般是通过人工检测与规则检测相结合的方式进行排查,但这种方法不仅要消耗大量的人力物力,还存在着检测效率低和检测效果欠佳等问题。学术研究上,常永虎等人[1]基于考生在网络考试中的行为数据,提出了一种基于互相抄袭的作弊检测算法,该算法通过计算考生在答题的时间和答案上的相似度来判断作弊的可能性。Ruiperez-Valiente J A 等人[2]开发了一种算法来识别使用CAMEO(使用多个账号复制答案)方法进行作弊的学习者,该算法通过比较学习者、问题和提交特征对CAMEO 的影响,建立了一个不依赖IP 的随机森林分类器,以识别CAMEO 学习者。Sangalli V A 等人[3]针对学习者互相分享答案以及使用虚假账号获取正确答案这两种作弊手段,设计了一些指标来得到相应的特征,再利用K-means 聚类算法对其进行聚类来识别使用这两种作弊手段的学习者。上述研究都是针对于某种特定作弊形式,构造相应的特征后采用统计学或机器学习的方法进行作弊检测。本文研究一种更加通用的,可解决多种作弊形式的作弊检测模型。
学习者在学习过程中所执行的学习动作路径是不一样的[4],例如正常的学习者会先观看学习视频,再做练习,最后提交答案,异常的学习者可能会直接做练习或者集中在某一个时间段进行刷课等。从本质上看,MOOC 的作弊行为检测属于一种异常行为检测问题。
异常行为检测问题广泛存在于各个领域,例如网络入侵检测[5-6]、信用卡欺诈检测[7]、故障检测[8]、居民用电检测[9]。根据已有的文献研究,异常行为检测算法可以分为基于人工提取特征的传统机器学习算法和基于自动化提取特征的深度学习算法[10],但是传统机器学习算法过度依赖于人工特征提取,且常常由于特征提取不完整,导致模型性能不佳等问题。因此,许多学者尝试使用基于深度学习的方法进行异常行为检测。
卷积神经网络(Convolutional Neural Networks,CNN)[11]与循环神经网络(Recurrent Neural Networks,RNN)[12]是比较常见的深度学习网络模型,CNN 的优势在于能够在空间维度上提取局部特征,RNN 的优势在于能够在时间维度上提取时序特征。对于复杂的MOOC 学习者的学习行为数据,一般是具有序列性质的,因此,在挖掘学习行为特征时,需要考虑其空间上的联系,也需要考虑其时间维度上的关联信息。本文尝试将深度学习模型应用于MOOC 作弊行为检测中,结合CNN 和RNN 网络模型来对学习者的学习行为序列进行建模,但是,普通的RNN一方面存在着梯度消失的问题,另一方面只能学习单个方向的时序特征,为了解决这些问题,本文将RNN网络替换成其变种网络—双向门控循环单元(Bidirectional Gated Recurrent Unit,BiGRU)[13],采用CNN-BiGRU 联合网络提取学习行为序列的空间及时序特征。注意力(Attention)机制[14]是一种模拟人脑注意力机制的模型,已有实验表明,融入注意力机制的循环神经网络比单一的网络在机器翻译、情感分类、异常检测等问题中有更好的表现,Brown A 等人[15]在RNN 中引入了注意力机制,明显提高了系统日志异常检测的性能。
本文的贡献包括以下三个方面的内容:
(1) 针对之前的MOOC作弊行为检测方法存在的应用场景单一化,过度依赖人工提取特征,检测效果不稳定等问题,本文提出了一种基于CNN-BiGRUAttention联合网络的MOOC作弊行为检测模型,该模型融合了CNN、BiGRU、Attention三层网络结构,实现了自动化特征提取,可以适用于多种作弊形式的检测,性能较好。
(2) 针对实际情况下,MOOC作弊行为检测中存在的数据类别不均衡问题,采用数据扩增的方法增加少数类样本量后再进行模型训练,增强了模型的泛化能力。
(3) 实现了原型系统,并基于真实场景下的数据进行了实验验证,证明了本文提出方法的有效性。
本文后续章节安排如下:第二部分,介绍MOOC原始行为日志数据的分析及处理过程;第三部分,详细介绍MOOC作弊行为检测模型设计方案;第四部分,对模型的性能进行实验验证分析;第五部分,结论。
2 数据处理及分析
MOOC 平台的行为日志文件是学习者学习行为数据记录的主要载体,每一条行为日志数据详细记录了学习者与MOOC 平台的交互信息。例如访问时间、访问IP、访问路径、请求数据、响应数据、访问者信息等。图1 展示的是某学习者一条完整的行为日志数据,本文对行为日志数据进行json 解析,提取与研究问题相关的数据信息。
图2 为经过数据解析后某学习者在一个时间段内的学习行为路径数据,其中,不同的Uid 表示不同的学习者,Time 表示学习者执行该动作的时间,Path表示动作的类型,Mark 是对动作进行的统一标记,Description 是对动作进行的描述。本文以“教学天”为单位对学习者的学习行为动作进行聚合处理,得到一系列的具有时间先后顺序的行为序列数据,如图3 所示。通过对学习行为序列长度进行分析可知,正常学习者一天24 小时内产生的学习行为序列长度一般为几十到几百,而通过作弊学习的行为序列长度往往很长,极端作弊者一天产生的行为序列长度最长可达几十万。由于行为序列建模与文本序列建模的原理类似,可以把学习者一个“教学天”的行为序列数据看作一篇文章,行为序列中的学习动作看作文章中的单词,由此可以利用Word2Vec[16]对行为序列中的每个动作进行向量表示,得到表征行为序列的特征向量矩阵后,将其作为深度神经网络模型的输入,完成最终的检测任务。
3 MOOC 作弊行为检测模型
本文研究了一种深度学习混合模型CNN-Bi-GRU-Attention 用于MOOC 作弊行为的检测,模型结构如图4 所示。分为嵌入层、卷积神经网络层、双向门控循环单元层、注意力层、输出层。下文将对各层进行详细描述。
3.1 嵌入层(Embedding)
正如前文所提到的,先利用Word2Vec 将行为序列中的行为动作表示成密集的实数向量,才能将其输入到神经网络模型中,嵌入层是整个模型的输入,假设xi∈R1*d表示行为序列中第i 个动作的词向量,该词向量的维度为d,则长度为n 的行为序列可表示为实数向量矩阵,如公式(1)所示。其中,⊕符号表示连接操作.。
获得行为序列的向量矩阵表征后,将其作为CNN 层的输入,对其进行卷积与池化操作,提取行为序列中的局部空间特征。同时将其作为BiGRU 层的输入,提取行为序列的时序特征。
3.2 卷积神经网络层(CNN)
CNN 最初被广泛应用于计算机视觉领域,近年来,随着深度学习在文本领域的研究逐渐增多,CNN 也被应用于文本领域,用于提取文本序列的局部特征。考虑到学习者学习行为序列中,相邻的几个行为之间具有关联关系,因此采用CNN 挖掘行为序列的局部信息。CNN 一般包含卷积和池化两种操作,卷积操作以滑窗的方式在不同的地方提取文本序列中的局部信息,池化操作一般接在卷积操作的后面,主要作用是减少数据特征维数,降低计算复杂度。
3.2.1 卷积(Convolution)
本文使用30 个尺寸为3 的卷积核提取行为序列中的局部空间信息。假设一个行为序列共有n 个行为动作,每个动作由一个d 维的向量表示,使用一个尺寸为h 的卷积核ω与h 个连续行为动作进行卷积操作后得到相应的特征映射ci,卷积操作可由公式(2)表示。
其中:xi:i+h-1是行为序列中第i 个到第i+h-1 个连续行为动作组成的子行为序列向量矩阵;b 是偏置项。通过卷积操作后,可得到特征映射向量c=[ c1, c2, …,cn-h+1]。
3.2.2 池化(Pooling)
池化就是对卷积之后得到的特征映射向量c 进行下采样,求得局部最优解Mi,池化分为最大池化和平均池化,本文模型使用最大池化,最大池化操作可以由公式(3)表示。
由于池化会中断序列结构,因此将经过池化后的Mi连接成特征向量u,如公式(4)所示。其中,K 表示卷积核的个数。
3.3 双向门控循环单元层(BiGRU)
RNN 是一类用于处理序列数据的神经网络模型,通过网络中的循环结构单元记录序列数据的历史信息,即当前隐藏层的输出不仅与当前时刻的输入有关,还与前一时刻隐藏层的输出有关[17]。普通RNN可以有效地利用近距离的语义特征,但存在着梯度消失的问题[18],为了解决该问题,RNN 出现了LSTM[19],GRU[20]等变体,GRU 其实是LSTM 的一种改进,它们都通过“门机制”来记忆前面的序列信息,以弥补普通RNN 的不足。不过相比于LSTM 的三个门单元,GRU 只有两个门单元,分别为更新门和重置门,其模型更简单、参数更少,收敛速度更快。
图5 为GRU 单元结构图。zt和rt分别为GRU 的更新门和重置门,xt是t 时刻GRU 单元的输入,ht是t时刻GRU 单元输出的隐藏信息。GRU 单元的具体计算过程如下所示:
其中,ωz,ωr,ωh分别为更新门,重置门以及候选隐含状态的权重矩阵。
虽然GRU 能够很好地捕捉到行为序列的长距离信息,但是单向的GRU 在t 时刻只能捕捉到t 时刻之前的历史信息,为了捕捉到前后行为之间完整的关联信息,本文使用双向的GRU(BiGRU)网络对行为序列进行建模,BiGRU 既考虑了t 时刻之前的行为信息,同时考虑了t 时刻之后的行为信息。
图6 为BiGRU 网络结构图,从图6 可以看出,BiGRU 网络包含前向GRU 和后向GRU。t 时刻,前向GRU 的隐藏状态由xt和决定,可以获取到t 时刻之前的行为信息,后向GRU 的隐藏状态由xt和决定,可以获取到t 时刻之后的行为信息,然后再通过向量拼接的方式得到最终的隐藏状态,这样,行为序列中的每个行为的隐层状态都包含完整的前后关联信息。相较于单向的GRU 而言,BiGRU可以挖掘出更为全面的特征信息。BiGRU 具体的计算过程如式(9)、(10)、(11)所示。
3.4 注意力层(Attention)
Attention 机制的作用是通过对模型输入特征赋予不同的权重,加强重要信息对最终结果的影响。在作弊行为检测的过程中,每个行为特征对最终检测结果的贡献度是不同的,基于此,本文引入Attention机制来对不同的特征分配不同的权重值。此前已通过CNN、BiGRU 网络分别获取了行为序列的局部特征向量、时序特征向量,为了更加完整的表征行为序列,将局部特征向量和时序特征向量进行首尾相连得到新的行为序列特征向量zi,然后将其输入到Attention 层得到作弊行为的最终表示。
Attention 层的计算过程如公式(12)、(13)、(14)所示。
其中,ω1和ω2为权重矩阵;b 为偏置项;γ为注意力层的输出。
3.5 输出层(Output)
输出层实际上是一个Sigmoid 分类器。经过前面几步,我们已经得到了行为序列的最终表征向量,将其输入到Sigmoid 分类器中进行分类得到作弊检测结果。
4 实验
本文实验环境为一台高性能服务器,搭载Centos7操作系统;CPU为Corei5-8300H,128G内存;硬盘配置 2 块 1TB 的 3.5 寸 SATA;GPU 为QuadroGP100,16GB 的HBM2 显卡。本文使用Keras来实现模型的搭建,Keras是一个用Python编写的高级神经网络API,它能够以TensorFlow、CNTK 或者Theano 作为后端运行,旨在完成深度学习的快速开发。
4.1 数据来源
本文从某MOOC 在线学习平台的数据库中获取了210 门学分课程总计203.5GB的脱敏数据,时间跨度为2018 年的9 月到2019 年的12 月,涵盖了60 个院校共46920 名学习者的学习行为轨迹。对原始数据进行预处理,最终提取了1788416 条学习行为序列来验证所提方法的有效性,选取其中75%的样本作为训练集,25%的样本作为验证集。
4.2 参数设置
参数设置会直接影响本文模型的检测效果,模型的参数设置如表1 所示。
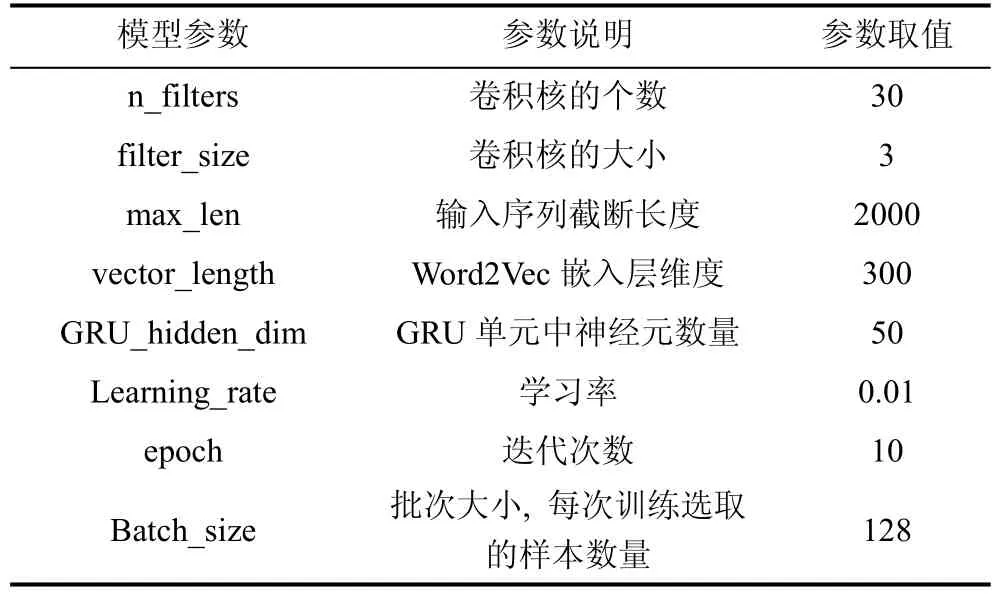
表1 模型的参数设置Table 1 Parameter settings of the model
4.3 实验结果与分析
4.3.1 MOOC 作弊行为检测模型对比
为了评估本文模型的检测性能,分别选用CNN、LSTM、GRU、BiGRU、CNN-BiGRU、BiGRU-Attention 等方法在验证集上进行对比实验,结果如表2 所示。从实验结果来看,本文提出的CNN-BiGRU-Attention 模型取得了最高的精确率、召回率、AUC 和最低的误报率,分别为98.51%、81.35%、91.07%和0.016%,可见本文模型的检测效果优于其对比模型。对比前四组实验,可以看出,相比于CNN 和LSTM 模型,GRU 的作弊检测性能更好,另外,BiGRU 对比单向的LSTM 和GRU,模型的各个性能指标均有提升,说明采用双向结构的BiGRU能更充分的提取序列的上下文信息,进而提高了作弊行为的检测能力。对比第一组、第四组和第五组实验,CNN-BiGRU 联合模型相比于单一的CNN 或者单一的BiGRU 模型,在精确率、召回率和AUC 上都有明显的提升,主要是因为CNN-BiGRU 联合模型同时结合了CNN和BiGRU模型结构的优势,既学习了行为序列的空间特征,又学习了行为序列的时序特征。对比第四组和第六组实验,可以看出,在BiGRU 的基础上引入注意力机制后,检测模型的精确率、召回率和AUC 值分别提升了1.15%、0.4%和1.44%,究其原因,主要是因为引入注意力机制后,对检测贡献度大的特征给予了更高的权重,提升了重要特征对行为序列分类的影响力。本文提出的CNN-BiGRU-Attention 网络模型,由于同时结合了CNN、BiGRU 以及注意力机制等网络结构的优势,模型的检测性能进一步得到了提升。

表2 实验结果Table 2 Experimental results
此外,在实验过程中发现,由于数据规模较大,上述模型往往在第一个epoch 就能达到收敛,为此选取了上述模型中表现较好的三个模型,绘制了它们在第一个epoch 的训练损失曲线,如图7 所示,可以看出,相较于CNN-BiGRU、BiGRU-Attention,CNNBiGRU-Attention 的收敛速度最慢,但是损失最低,模型拟合效果最好。
4.3.2 数据扩增性能提升对比
在训练深度学习模型时,常常会出现模型过拟合的现象,而导致这一现象出现的原因很可能就是训练样本不足或者训练样本类别不均衡。在进行MOOC 作弊行为检测研究时,相对于正常样本,作弊样本往往是少之又少。基于此,本文采用序列截断扩增、平移扩增这两种数据扩增方法来增加作弊行为序列的样本量。截断扩增,具体而言就是对长度过长的作弊行为序列进行截断,将截断后的序列打上作弊的标签,从而增加作弊标签的样本量。而平移扩增是指通过时间滑窗的方式,以24 h 的固定窗口前后滑动,获取一段新的作弊行为序列。实验表明,通过数据扩增后再进行模型训练,能够提高模型的泛化能力。经过数据扩增前后的训练集样本分布如下表3 所示。
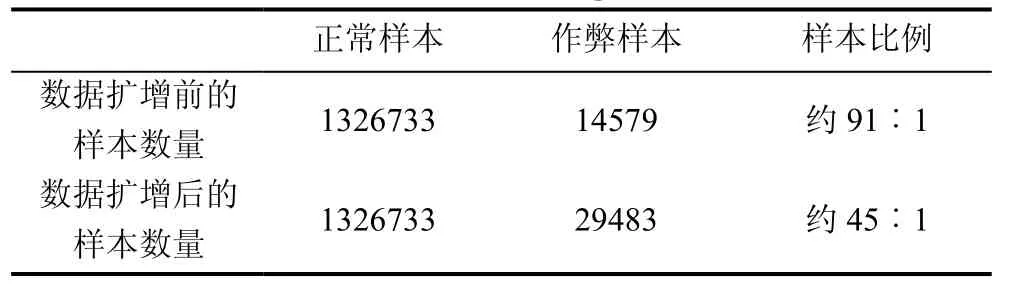
表3 数据扩增前后的训练集样本分布Table 3 Sample distribution of the training set before and after the data augmentation
图8 为采用LSTM,GRU,BiGRU 以及本文模型分别对数据扩增前后的训练集进行模型训练后,在验证集上得到的AUC 结果。本文提出的CNNBiGRU-Attention 模型在数据扩增前,在验证集上获取的AUC 为91.07%,而经过数据扩增后,在相同验证集上获取的AUC 为92.85%,相比之前提升了1.78%。LSTM、GRU、BiGRU 经过数据扩增后AUC也分别提升了1.45%,1.47%,1.58%。
5 结论
本文研究了一种基于深度学习混合模型CNN-BiGRU-Attention 用于MOOC 作弊行为检测。利用CNN-BiGRU 联合网络提取行为序列的空间和时序特征,并引入注意力机制对作弊检测贡献度大的特征给予更高的权重,然后利用Sigmoid 分类器进行分类得到作弊检测结果。此外,通过对比实验CNN、LSTM、GRU、BiGRU、CNN-BiGRU、BiGRU-Attention 等算法,证明了本文实验方法的有效性。另外,针对实际情况下,MOOC 作弊行为检测中存在的数据类别不均衡问题,采用数据扩增的方法增加少数类样本量,实验表明,通过数据扩增后再进行模型训练,能降低模型过拟合的风险,提高模型的泛化能力。
本文讨论的是有标签数据集情况下的MOOC 作弊行为检测,而在实际情况下,带有标签的数据是较少的,后续研究需要进一步结合半监督学习的MOOC 作弊行为检测方法,提高作弊检测的准确度。
