基于Python的租房信息可视化及价格预测
2021-02-28李涛


摘 要:文章以都匀市出租房为例,运用Python对安居客网上房源信息进行采集,对获取的数据进行清洗和处理,并从数据中选择小区、户型、朝向、住房面积和租房价格等特征进行数据分析和可视化展示,最后使用随机森林模型对租金价格进行预测。通过分析与价格预测,以期帮助寻租者在选择房源时能获取特定的需求信息,从而做出更好的决策。
关键词:出租房;数据分析;可视化;租金;随机森林
中图分类号:TP311;TP181 文献标识码:A文章编号:2096-4706(2021)16-0096-04
Rental Information Visualization and Price Prediction Based on Python
LI Tao
(School of Computer and Information, Qiannan Normal University for Nationalities, Duyun 558000, China)
Abstract: Taking the rental housing in Duyun City as an example, this paper uses Python to collect the housing source information of Anjuke real estate network, cleans and processes the obtained data, selects the characteristic data of community, house type, orientation, housing area and rental price from the data for data analysis and visual display, and finally uses the random forest model to predict the rental price. Through analysis and price forecasting, it is expected to help renters obtain required information when selecting houses, so as to make better decisions.
Keywords: rental housing; data analysis; visualization; rent; random forest
0 引 言
在中國持续城镇化建设过程中,农村富余劳动力逐步向城市进行转移[1]。由于现阶段城镇的房价高,买房比较困难,相当多买不起房的人只能租房。因此,这些年来国内的租房人群十分庞大,市场需求也很旺盛。与此同时,房价是在不断上涨的,租金也随着房价的上涨而上涨。文章以贵州省黔南州都匀市为例,以安居客租房网站上的挂牌房源数据为研究对象,对采集原始数据进行清理、异常值和缺失值处理以及特征向量数字化处理等工作,并选取相应特征向量进行可视化分析。在此基础上,运用随机森林预测模型来预测租金价格以及走向。其工作主要集中在以下6个方面:
(1)选取并收集URL,存储在待抓取的URL列表。
(2)使用Requests库抓取页面。
(3)使用Beautiful Soup解析页面内容。
(4)数据存储及预处理。
(5)分析数据并可视化。
(6)运用随机森林模型预测房租价格。
通过分析,可以了解到目前市面上出租房各项基本特征及房源分布情况,并对不同区域房租价格进行预测,为群体大众进行租房决策提供了参考意见,还会对当地政府合理地规范租房市场提供重要的数据支持。
1 数据采集及预处理
1.1 选取及提取网页
选取安居客黔南都匀租房页面(https://qn.zu.anjuke.com/fangyuan/duyun/),页面上显示所有出租房房源信息共25页。通过分析这些页面的URL地址,发现其呈现出如下规律,除了第一页URL地址为“https://qn.zu.anjuke.com/fangyuan/duyun/px”其他页面的URL地址为“https://qn.zu. anjuke .com/fangyuan /duyun/px3-p+数字”。网页获取代码为:
url_list = []
for i in range(25):
if i == 0:
url = ‘https://qn.zu.anjuke.com/fangyuan/duyun/px3’
url_list.append(url)
else:
url = ‘https://qn.zu.anjuke.com/fangyuan/duyun/px3-p’+str(i + 2) + ‘/’
url_list.append(url)
for i in range(len(url_list)):
response = requests.get(url_list[i], headers=headers)
1.2 使用Beautiful Soup解析页面内容
Beautiful Soup提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能。它通过解析文档为用户提供需要抓取的数据[2]。Beautiful Soup已成为和lxml、html6lib一样出色的python解释器,为用户灵活地提供不同的解析策略或强劲的速度[3]。针对下载的网页文档,使用Beautiful Soup提供各种选择器进行目标数据的解析并抽取。核心代码为:
soup = BeautifulSoup(response.text, ‘lxml’)
totaldivlist = soup.find_all(“div”, attrs={“class”, “zu-itemmod”}) #每页房源信息列表
lenth = len(totaldivlist) #每页房源的数目
for j in range(lenth):
house_info = totaldivlist[j].find(“div”, attrs={“class”, “zu-info”}) #房源名
house_name = house_b[0].text
house_u = house_info.find(name=”a”)
house_url = house_u[‘href’]#房源的链接
house_t = totaldivlist[j].find(“p”, attrs={“class”, “details-item tag”})
house_ty = house_t.find_all(name=”b”) #户型
for k in range(len(house_ty)):
if k == 0:
house_type += house_ty[k].text + ‘室’
elif k == 1:
house_type += house_ty[k].text + ‘厅’
else:
house_area = house_ty[k].text + ‘平米’#房源面积
house_location = totaldivlist[j].find(“span”, attrs={“class”, “cls-2”}).text #户型朝向
address = totaldivlist[j].find(“address”, attrs={“class”, “details-item”}).text #地址
price_span = totaldivlist[j].find(“div”, attrs={“class”, “zu-side”})
price = price_span.find(‘b’).text + ‘元/月’ #租房价格
1.3 数据清理及存储
1.3.1 數据清理
从网页中获取的数据均为文本数据,这些数据并不能直接进行数据分析。在数据分析和可视化之前,需要先去掉一些脏数据,修正一些错误数据,对存储数据进行预处理,如房租价格、房屋面积的数字化处理,房型数据的分割(厅、室和卫),如3室1厅1卫等。
1.3.2 数据存储
为了能够对出租房房源信息进行可视化,同时对租房价格趋势做出合理的预测,获取的房源数据,是从安居客网爬取的2021年3月到6月挂牌都匀市出租房房源信息,共1 039条数据。
Python中,常用数据存储是数据库(MySQL或Redis数据库)以及文件存储,如CSV文件和Excel文档等。本文中采用CSV文件进行数据存储。
2 数据分析与可视化
本阶段是对房源数据从整体上进行探究性分析,通过数据可视化呈现,能更好、更直观的认识数据,并寻找和探寻数据背后的内在规律。文章针对出租房房源的所属小区、住房面积、户型(室数、厅数和卫数)、朝向和出租房价格等特征项进行分析。
2.1 都匀出租房基本信息可视化分析
2.1.1 都匀各热门小区出租房及占比分析
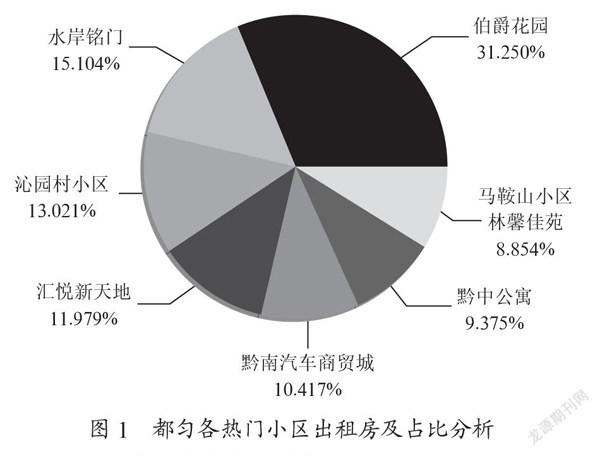
都匀各热门小区出租房及占比分析饼图如图1所示,选取并显示房源数量最多的7个热门小区。从图中可以看出,伯爵花园小区提供的房源占据了整体房源数据中的31.250%,其他各个小区的占比差别不大。由此看出,房源的地理位置很大程度决定租房的需求,邻近市中心区域,租房的需求和房源供应量就随之提升。
2.1.2 出租房屋面积的分布
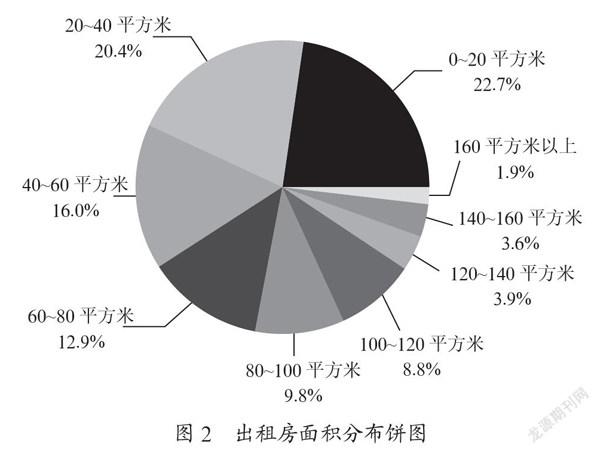
如图2都匀出租房面积饼图所示,大约82%的房源的建筑面积集中在100平方米以下,大面积的房源数量比较少。面积80平方米以下房源数据覆盖的范围比较广泛,满足绝大多数租房者的租赁需求。
2.2 出租房价格可视化分析
2.2.1 都匀租房价格区间与房源数量之间关系
都匀各热门小区租房每月均价与房源数量之间关系如图3所示。从图中可以看出,能提供出租房源数量最多小区是伯爵花园小区,共74套,每月租房均价1 392元。每月租房均价最高小区是碧桂园滨江一号,每月均价为2 257元,共20套。提供出租房源数量最少小区是文峰家园小区,共13套,每月租房均价1 223元。每月租房均价最低小区是平惠小区,每月均价为950元,共20套。
2.2.2 都匀租房价格与出租房面积之间关系
都匀出租房面积与每月租房均价关系如图4所示。从图中可以看出150平方米以上的房租每月均价是最高的,为1 904元/月。30平方米以下的房租每月均价是最低的,为751元/月。
每月租房均价的范围从751元/月到1 646元/月,面积从30平方米到150平方米,完全满足绝大多数人的租赁需求。位置的选择上基本覆盖都匀市主要的各个热门小区。
3 房租价格预测分析
近年来,作为机器学习算法之一的随机森林受到越来越广泛的关注。随机森林[4]是一种统计学习理论,利用bootstrap抽样的方式从原始数据集中抽取多个样本,对每个bootstrap样本进行决策树建模,组合多个决策树投票得到最终预测结果。
随机森林算法具有需要调整的参数较少、不必担心过度拟合、分类速度快、能高效处理大样本数据、能估计特征因素的重要性、很好的处理类别变量、有较强的抗噪声能力等优点[5]。与线性回归相比,避免了线性回歸事先假定的线性关系不符合实际造成较大误差的情况。且随机森林不用对函数形式事先进行假设,避免了假设误差。
首先利用自助抽样法,从原始数据集中抽取B个样本,且每个样本容量都与原始数据集相同;然后对B个样本分别建立B棵树,得到B个结果;最后,对这B个结果取平均值得到最终的预测结果。基于随机森林的出租房价格评估模型计算如下,出租房的随机森林模型由B棵树组成,{F1(X),F2(X),…,FB(X)},其中X={x1,x2,…,xp}是出租房的维特征向量。结果会产生B个结果,,……,。其中,是第b棵树的预测结果。算法流程为:
(1)原始数据含样本量为1 039多个,应用bootstrap方式抽样选择30个样本集,构建30棵决策树。每次抽样未被抽到的样本构成OOB样本作为随机森林的验证样本。
(2)样本中特征变量个数为6,使用随机森林做回归时,通常选取特征变量个数除以3。本文每一次划分选择2个变量。
(3)每一棵决策树生长到最大,无须进行剪枝,重复上述步骤直到生成30棵决策树。
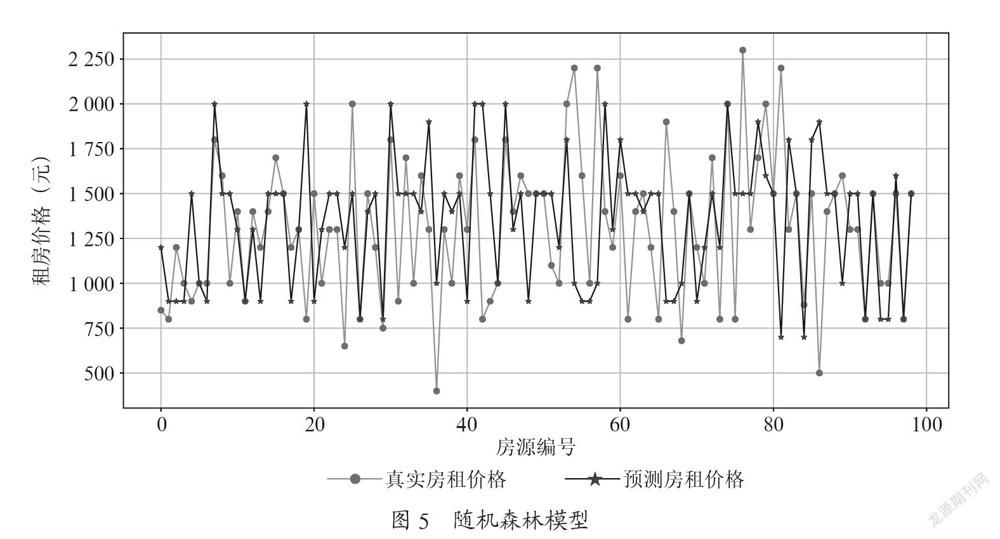
通过如上步骤,建立得到出租房的随机森林价格评估模型,将OOB样本输入随机森林模型得到房价预测精度。预测效果如图5所示。
从图5中可以看到随机森林模型有较好的评估精度,能够有效的挖掘出样本所隐含的信息,能较准确地对房租价格进行预测,具有实用价值[6]。
4 结 论
本文通过爬虫程序爬取都匀市出租房房源信息,通过数据清理及预处理后,以可视化方式对不同小区的租房价格,户型类型及租房面积进行展示,同时引入随机森林预测模型对房租价格进行较为准确的预测,为寻租者在查找出租房源的过程中提供了便利。
参考文献:
[1] 王凤丽,侯建华.边缘青年的现状与出路 [N].中华读书报,2021-02-10(19).
[2] 崔庆才.Python3网络爬虫开发实战教程 [M].北京:人民邮电出版社,2018:168
[3]陈海燕,朱庆华,常莹.基于Python的网页信息爬取技术研究 [J].电脑知识与技术,2021,17(8):195-196.
[4] 葛新权,张守一.变系数季度预测模型 [J].预测.1995(1):62-63+55.
[5] 刘冬琴.自然场景下交通标志检测算法研究 [D].北京:北京交通大学,2016.
[6] 王洪.基于K-means和BP神经网络的房租价格批量评估研究 [D].武汉:华中农业大学,2019.
作者简介:李涛(1974.05—)男,汉族,安徽芜湖人,副教授,硕士研究生,研究方向:智能信息处理及软件工程。
