基于t-SNE降维预处理的网络流量异常检测
2021-02-27郝怡然盛益强王劲林
郝怡然,盛益强,王劲林
(1.中国科学院声学研究所国家网络新媒体工程技术研究中心,北京 100190;2.中国科学院大学电子电气与通信工程学院,北京 100049)
0 引 言
网络流量中经常会出现偏离正常范围的异常流量,主要是由DDOS攻击、渗透攻击等恶意的网络行为引起的,这些异常行为通常会导致网络质量下降,甚至导致网络直接瘫痪[1]。因此引入网络安全态势的预测来判断网络中的异常,进而在网络攻击发生或者造成严重后果之前进行预警。网络安全态势的预测是指根据态势的历史信息和当前状态对网络未来的发展趋势进行预测。现有的主要安全态势预测方法包括神经网络、机器学习(如支撑向量机)等。基于机器学习的异常检测被认为是一种网络安全态势预测的方法[2-3],现有的异常检测算法主要是对网络中的历史数据进行分析,进而预测未来的网络中是否具有攻击行为。现有的异常检测方法主要分为基于规则的异常检测[4]、基于统计的异常检测[5]和基于机器学习的异常检测[5]。基于规则的异常检测通常需要通过人工经验构建规则库,该方法能够准确地找出符合规则的异常,但无法检测未知的异常。基于统计的异常检测通常需要假设数据服从某种分布,之后利用数据进行参数估计,该方法鲁棒性较强,但过于依赖假设的分布。基于机器学习的异常检测能够检测未知的异常[5],并且不需要假设数据的分布。但基于机器学习的异常检测算法需要找到准确刻画网络数据包的特征。然而,现有的异常检测算法由于无法准确提取网络数据包的低维特征导致算法的性能不佳。因此,需要找到网络数据包的准确的低维特征表示,该低维特征表示能够区分网络数据包是正常的还是有攻击的。
由于网络中的标签数据较难获得,如果对所有的数据进行标记需要大量的人力,但如果忽略大量的无标记数据则会忽略大量的信息。此外,网络流量中的正常网络数据包数量远远大于有攻击的网络数据包数量,并且通常网络中会有很多新的攻击出现,如零日攻击等。人们无法提前把所有可能出现的有攻击的网络数据包都找到并打上标签。因此本文提出一种基于t-SNE(t-distributed Stochastic Neighbor Embedding)降维的局部异常因子(Local Outlier Factor, LOF)算法,记为t-SNE LOF。该算法首先将网络流量切分成网络数据包,之后将网络数据包采用t-SNE算法自动学习网络数据包的低维特征,最后将t-SNE算法的输入作为LOF算法的输入检测异常的网络数据包。值得说明的是,该算法的训练集中仅有正常的网络数据包,测试集中有少量的有攻击的网络数据包和部分正常的网络数据包。由于采用t-SNE自动学习网络数据包的低维特征,因此本文提出的t-SNE LOF算法能够更准确地检测不在训练集中的攻击。
本文的主要贡献如下:
1)现有的网络数据包特征大多都是高维非线性的[6],很难得到准确刻画网络数据包的低维特征进而进行异常检测。本文提出基于t-SNE降维的NLOF算法,该算法首先采用t-SNE算法自动学习网络数据包的低维特征,之后将得到的低维特征作为NLOF算法的输入进行异常检测。其中,NLOF算法首先采用k-means算法将网络数据包聚类成为K个簇,并将网络数据包数量小于N个的簇标记为异常簇,之后将未被标记为异常簇的网络数据包作为LOF算法的输入进行异常检测。由于采用t-SNE算法自动学习网络数据包的低维特征,本文提出的算法能够更准确地检测攻击。这是因为异常检测中提取网络数据包特征时首次采用t-SNE算法提取低维的网络数据包特征。此外,LOF算法仅能捕获异常点,而本文提出的NLOF算法能够同时捕获异常点和异常簇。
2)现有的网络安全态势预测算法,如基于神经网络的入侵检测算法等,通常仅能检测训练集中包含的攻击。本文提出的基于t-SNE降维的NLOF算法能够检测不在训练集中的攻击。
3)实验结果表明,基于t-SNE降维的LOF算法达到最优性能时,准确率为98.46%,精确度为98.38%,召回率为98.54%,错误率为0.66%,该算法比现有最新算法的准确率、检测率和F1分别高3.18个百分点、0.02个百分点和0.01个百分点。基于t-SNE降维的NLOF算法达到最优性能时,准确率为98.53%,精确度为98.86%,召回率为98.86%,错误率为0.32%,该算法比现有最新算法的准确率、检测率和F1分别高3.25个百分点、0.34个百分点和0.41个百分点。
1 异常检测技术
现有的异常检测技术已经在数据清洗、金融欺诈检测[7]等领域取得了较好的效果。现有的异常检测方法主要分为基于规则的异常检测、基于统计的异常检测和基于机器学习的异常检测[6]。基于规则的异常检测通常需要通过人工经验构建规则库,该方法能够准确地找出符合规则的异常,但无法检测未知的异常。基于统计的异常检测通常需要假设数据服从某种分布,之后利用数据进行参数估计,该方法鲁棒性较强,但过于依赖假设的分布。基于机器学习的异常检测能够检测未知的异常[6-7],并且不需要假设数据的分布。
LOF算法[8-10]基于样本的局部密度信息判断是否有异常的网络数据包。该算法的优点是同时考虑了数据集的局部属性和全局属性,即使在数据集中样本分布不均匀的情况下,该算法仍然能够获得较好的效果,但该算法不适用于高维数据。
Isolation Forest算法[11]从给定的特征集合中随机地选择特征,之后在特征的最大值和最小值之间随机选择一个分割值,并将小于该分割值的样本作为该节点的左孩子,将大于该分割值的样本作为该节点的右孩子。不断地重复上述过程,至满足终止条件为止,通常终止条件为所有节点均只包含一个样本或者多个相同的样本,或者树的深度达到了限定的高度。这种特征的随机划分会使异常的网络数据包在树中生成的路径更短,从而将异常的网络数据包和正常的网络数据包划分。该算法的缺点是不适用于高维数据。
K近邻(k-Nearest Neighbor, KNN)算法[12]采用基于距离的方式检测是否有异常点。但该算法不适用于高维数据,且该算法仅可以找出全局异常点,无法找到局部异常点。
以上算法的共同点是,都不适用于高维数据。但网络数据包特征大多数都是高维的[6],因此,本文提出一种基于t-SNE降维的NLOF异常检测算法以得到更好的异常检测性能。
2 基于半监督的未知类别数据包的态势预测
2.1 定义
异常检测(Anomaly Detection)[13]:是指从数据中找到和预期的行为不一致的异常行为模式。其中,异常的行为模式通常是指异常、离群点等。
奇异值检测(Novelty Detection)[13]:是指从数据中检测到之前从未观察到的模式。常见的奇异值检测算法有one class SVM算法等。
高维空间和低维空间的区别:在高维空间中,很多基于距离的度量都会失效,比如欧氏距离,且高维空间会带来维度灾难[14]。解决维度灾难的重要途径是降维[6](Dimension Reduction),即通过一些手段将原始高维空间数据转变为一个低维子空间[6],在这个低维的子空间中样本密度较高,更容易计算样本间的距离。此外,现有的研究没有对低维空间和高维空间定义非常明确的划分界限。
2.2 流程
图1是基于t-SNE NLOF异常检测的算法流程图。该异常检测算法主要分为3个部分:1)将原始流量切分成网络数据包;2)采用t-SNE算法自动预处理网络数据包以获得低维的网络数据包特征;3)将得到的低维的网络数据包特征作为NLOF算法的输入进行异常检测。

图1 基于t-SNE NLOF异常检测的算法流程图
数据预处理是提升整个入侵检测系统性能的基础[15],因为数据预处理提取的网络数据包特征会决定整个模型性能的上限。现有的网络数据包特征通常都是高维的,无法适用于现有的异常检测算法,因此本文提出一种基于t-SNE降维的NLOF异常检测算法。该算法采用t-SNE自动学习得到低维的网络数据包特征以得到更好的异常检测性能。此外,LOF算法仅能捕获异常点,提出的NLOF算法能够同时捕获异常点和异常簇。
2.3 数据降维
作为数据降维的准备步骤,本文首先将网络流量转换成了网络数据包的特征。将网络流量转换成网络数据包的特征的过程是:首先采用SplitCap[16]将网络流量中一组源IP和目的IP的交互划分到同一个网络数据包中[14],之后将网络数据包格式化以提取网络数据包特征。其中,网络数据包格式化的流程是:首先将网络数据包的每个字节映射成为一个特征,之后对每个网络数据包的特征进行截断,仅保留每个网络数据包的前r个字节。图2是网络数据包格式化的过程。

图2 格式化网络数据包的包头和负载信息
之后对提取的网络数据包特征采用t-SNE算法进行降维,以得到能够准确刻画网络数据包的低维特征。t-SNE算法是一种非线性降维算法,该算法能够将数据从高维空间映射到低维空间。采用t-SNE算法降维主要包括以下2个步骤:首先,采用SNE在高维空间构建网络数据包的概率分布,之后t-SNE算法在低维空间构建网络数据包的概率分布,使高维空间的概率分布和低维空间的概率分布尽可能地相似[17]。
其中,采用SNE在高维空间构建网络数据包的概率分布的过程如下。给定一个包含N个网络数据包的集合X={x1,x2,…,xN}。对任意2个网络数据包xi和xj,采用SNE将网络数据包之间的高维欧几里得距离转换为表示网络数据包间相似性的条件概率pj|i,定义如下:
(1)
其中,σi是以网络数据包xi为中心的高斯分布的标准差。
为了避免不对称的代价函数带来的问题,采用公式(2)计算网络数据包xi和xj间的距离pij。
(2)
假设t-SNE降维后的网络数据包集合是Y={y1,y2,…,yN},那么该集合是高维空间X到低维空间Y的映射。也就是说,高维空间中的网络数据包xi和xj在低维空间中分别对应为yi和yj。之后,在低维空间中采用t-分布计算yi和yj之间的距离,得到网络数据包之间的距离qij的计算公式为:
(3)
t-SNE算法的最终优化目标为KL散度,计算公式如下:
(4)
其中,由于最小化KL散度为非凸优化,因此采用随机梯度下降进行求解。KL散度的梯度为:
(5)
2.4 基于正例样本的异常检测算法挖掘未知攻击
本文将降维后的低维网络数据包特征作为NLOF算法的输入。NLOF算法能够计算每个网络数据包的离群程度因子。离群因子较大的网络数据包周围的网络数据包密度相对较低。因此,具有较大离群因子的网络数据包称为离群的网络数据包,又被称为异常的网络数据包。反之,离群因子较小(接近1)的网络数据包被认为是正常的网络数据包[11,15]。
NLOF算法首先采用k-means算法将网络数据包聚类成为K个簇,并将网络数据包数量小于N个的簇标记为异常簇,之后将未被标记为异常簇的网络数据包作为LOF算法的输入进行异常检测。本文中,K的取值为4,N的取值为5。
下面详细介绍LOF算法的一些基本概念。
第k距离(k-distance):网络数据包p的第k距离是指,对于网络数据包p和网络数据包o之间的距离,任取一个自然数k,网络数据包o满足下面的条件:
1)存在至少k个网络数据包o′∈D/{p}满足d(p,o′)≤d(p,o);
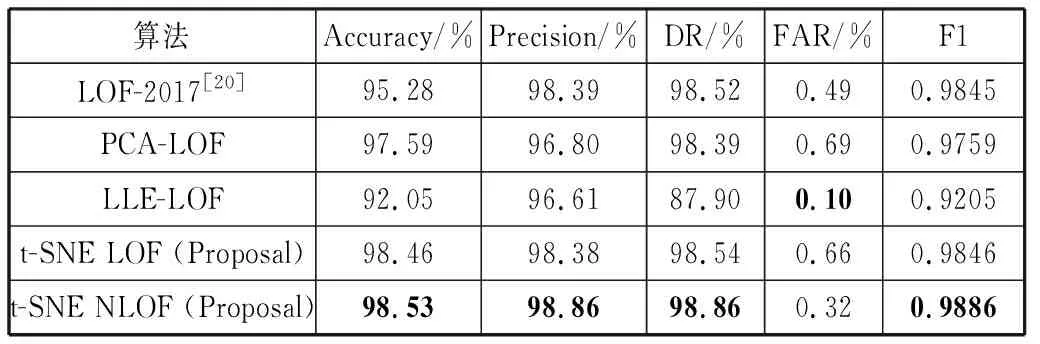
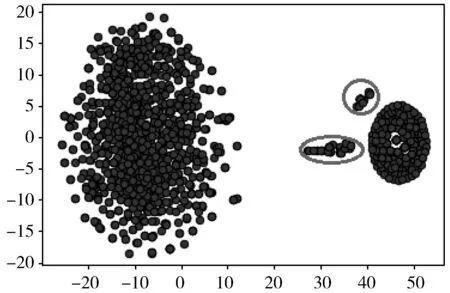
2)最多存在k-1个网络数据包o′∈D/{p}满足d(p,o′) 其中,d(p,o)表示网络数据包p和网络数据包o之间的距离。 第k距离邻域(Nk-distance(p))): 网络数据包p的第k距离邻域是指,一个包含所有和网络数据包p之间距离没有超过k-distance的网络数据包的集合。 Nk-distance(p)={q|d(p,q)≤k-distance(p)} (6) 其中,Nk-distance(p))在后文中被简化成Nk(p)。 可达距离(reach-dist(p,o)):是指网络数据包p和网络数据包o之间第k距离和o、p之间真实距离的最大值。网络数据包p和网络数据包o之间可达距离的公式如下: reach-dist(p,o)=max(k-distance(o),d(p,o)) (7) 局部可达密度(lrdk(p)):网络数据包p的局部可达密度是网络数据包p的第k距离邻域内到p的平均可达距离的倒数。 (8) 局部离群因子(LOFk(p)):网络数据包p的局部离群因子是指通过网络数据包p的特征判断该网络数据包的离群程度。网络数据包的局部离群因子越大,该网络数据包是离群点的可能性就越高。局部离群因子的计算公式如下: (9) 算法1基于t-SNE降维的NLOF异常检测算法 输入:网络流(fi)。 输出:测试集的评价结果。 步骤1将网络流切分成网络数据包。 采用Splitcap将网络流切分成q个网络数据包(p1,p2, …,pq)。 步骤2网络数据包格式化。 取第i个网络数据包的前r个字节,将其中的每一个字节映射成一个特征。之后,能够得到第i个网络数据包的向量表示I=(veci1,veci2,…,vecir)。 步骤3t-SNE降维。 采用SNE在高维空间构建网络数据包的概率分布。 t-SNE算法在低维空间构建网络数据包的概率分布,使高维空间的概率分布和低维空间的概率分布尽可能地相似。 步骤4NLOF异常检测。 采用k-means算法将网络数据包聚成多个簇。 将网络数据包个数小于N个的簇标记为异常簇。 将未标记为异常的网络数据包进行如下计算: 4.1计算网络数据包p的第k距离。 4.2比较所有网络数据包和网络数据包p之间的距离,获得网络数据包p的第k距离邻域集合。 4.3计算网络数据包p和网络数据包o之间第k距离和o、p之间真实距离的最大值,即可达距离。 4.4计算网络数据包p的第k距离邻域内到p的平均可达距离的倒数,即网络数据包p的局部可达密度。 4.5通过网络数据包p的特征判断该网络数据包的离群程度,即计算网络数据包p的局部离群因子。 步骤5训练评估模型。 采用训练集数据训练t-SNE LOF模型。 步骤6测试评估模型。 采用测试集数据测试t-SNE LOF模型。 返回测试集的评价结果。 现有的入侵检测的数据集有KDD CUP 1999[18]、NSL-KDD[19]、Kyoto 2009[20]、ISCX 2012[16]和DAPAR 1998[21]。其中,只有ISCX 2012和DAPAR 1998数据集是原始流量数据。因为ISCX 2012数据集较新,因此本文采用该数据集进行实验。表1是该数据集的描述。本文将数据划分成训练集、测试集部分。其中,训练集的数据为6000个正常的网络数据包,测试集中包含5000个正常的网络数据包和10个有攻击的网络数据包。 表1 ISCX 2012数据集的数据描述[22] 本文采用准确率(ACC)、检测率(DR)、错误率(FAR)和F1作为评价指标[23]。其中,准确率是描述正确检测出是否有入侵的指标。检测率是描述有多少攻击被检测到的比例。错误率是指描述模型对非攻击行为的误判。计算公式如下: (10) (11) (12) Precision=TP/(TP+FP) (13) (14) 其中,FN(False Negative)是指网络数据包实际是有攻击的,但是被预测成为正常;FP(False Positive)是指网络数据包实际是正常的,但是被预测成为了有攻击的;TN(True Negative)是指网络数据包实际是正常的,也被预测成为了正常的;TP(True Positive)是指网络数据包实际是有攻击的,也被预测成为了有攻击的;Precision是精确度,精确度是由TP/(TP+FP)计算得到的。混淆矩阵如表2所示。 表2 混淆矩阵 表3是基于t-SNE NLOF算法进行异常检测和基于LOF算法进行异常检测的性能比较。表4是采用t-SNE NLOF算法与采用其他的降维算法对异常检测结果影响的比较。图3是采用t-SNE算法和采用其他的降维算法对异常检测结果影响的比较。图3(a)是基于t-SNE LOF算法进行异常检测的结果图。图3(b)是基于LOF算法进行异常检测的结果图。图3(c)是基于主成分分析(Principal Component Analysis, PCA)算法降维,之后采用LOF算法进行异常检测的结果图。图3(d)是基于局部线性嵌入(Locally Linear Embedding, LLE)算法降维,之后采用LOF算法进行异常检测的结果图。图中灰色圈中为异常的网络数据包,其余部分为正常的网络数据包。从表3中可以看出,基于t-SNE LOF算法进行异常检测算法比基于LOF算法进行异常检测算法的准确率、检测率和F1分别高3.18个百分点、0.02个百分点和0.0001。基于t-SNE NLOF算法进行异常检测算法比基于LOF算法进行异常检测算法的准确率、检测率和F1分别高3.25个百分点、0.34个百分点和0.0041。从图3可以看出,基于t-SNE NLOF算法进行异常检测算法得到的正常网络数据包的决策边界更加清晰,因此能够更加准确地划分出有攻击的网络数据包。基于LOF算法进行异常检测算法得到的正常网络数据包的决策边界略模糊,容易将边界处的正常的网络数据包误分为异常的网络数据包。一个可能的解释是,高维的网络数据包特征中可能包含很多冗余信息,因此对LOF算法划分正常网络数据包的决策边界造成了干扰,进而导致有网络数据包被误分。从表4可以看出,本文提出的t-SNE LOF算法的准确率、检测率、精确度和F1值都比PCA LOF算法和LLE LOF算法高。也就是说,采用t-SNE算法降维后采用LOF算法进行异常检测能够得到更高的异常检测性能。一个可能的解释是,采用t-SNE算法在降维时,通常使高维空间的概率分布和低维空间的概率分布尽可能地相似。该算法在降维时没有信息损失。采用PCA算法降维时,只保留影响较大的特征,该算法在降维时有信息损失。因此,与PCA算法和LLE算法相比,t-SNE算法能够更好地表征网络数据包的低维特征。从表4可以看出,本文提出的t-SNE NLOF算法的准确率、检测率、精确度和F1值都比t-SNE LOF算法高。一个可能的解释是,本文提出的t-SNE NLOF算法能够检测异常点和异常簇,因此具有优于t-SNE LOF算法的性能。 表3 t-SNE NLOF算法与LOF算法的性能比较 表4 t-SNE NLOF算法与采用其他的降维算法对异常检测结果的影响 (a) t-SNE LOF 现有的应用于网络安全态势预测中的异常检测算法主要有One class SVM[24]、Isolation Forest[25]、Elliptic Envelope和LOF[9]。这些算法通常无法很好地适用于高维特征,由于网络数据包的特征大多都是高维的,因此导致现有的算法性能不高。表5给出了本文算法和现有最新算法的性能比较。从表5能够看出,本文提出的t-SNE LOF算法比现有最新算法在准确率和检测率上分别提高3.18个百分点和0.02个百分点。本文提出算法的准确率、精确度、检测率和错误率分别为98.46%、98.38%、98.54%和0.66%。一个可能的解释是,由于网络数据包特征是高维的特征,且包含部分冗余信息。因此,对于Isolation Forest算法而言,部分冗余的网络数据包特征会干扰异常检测的性能,因此Isolation Forest算法的错误率较高。Elliptic Envelope算法通过训练集学习出一个椭圆型的决策边界,采用该算法进行异常检测时如果内围分布是双峰的或者内围分布不是正态分布则无法很好地拟合正常网络数据包的边界[26-28]。因此,Elliptic Envelope算法的性能相对不佳。LOF算法是基于密度的异常检测算法,该算法考虑到数据集的局部和全局属性。也就是说,即使异常的网络数据包在具有不同潜在密度的数据集中,LOF算法仍然能够表现得很好。由于高维的网络数据包特征中可能包含很多冗余信息,因此对LOF算法划分正常网络数据包的决策边界造成了干扰。因此,采用t-SNE LOF算法的准确率和检测率比LOF算法的准确率和检测率高。 表5 与现有最新的算法的性能比较 一个准确的正常行为的边界通常很难得到,因为经常会有正常的网络数据包处于决策边界的位置而产生误判。因此,未来可以考虑对网络数据包的原始特征进行筛选,以降低冗余特征的干扰。 本文将一个网络数据包作为一个点,相当于是捕获一个网络数据包构成的图中的点异常。由于很多的网络攻击事件是有关联的,因此未来可以考虑采用集体异常(Collective Anomalies)算法捕获有关联的异常。 本文提出了一种基于t-SNE降维的NLOF异常检测算法预测有攻击的网络数据包。实验表明提出的算法比现有最新算法在准确率、检测率和F1值上分别高3.25个百分点、0.34个百分点和0.0041。本文提出算法的准确率、精确度、检测率和错误率分别为98.53%、98.86%、98.86%和0.32%。 本文采用大量正常的网络数据包训练模型,在测试时加入有攻击的网络数据包进行检测。由于正常的行为也一直在演进和发展,因此即使是现在定义了对正常网络数据包的良好的决策划分边界,在未来不一定能很好地划分异常的网络数据包。此外,随着入侵者调整其网络攻击以逃避现有入侵检测解决方案,异常的性质会随着时间不断变化。因此,未来可以考虑对正常网络数据包的决策边界进行修正以适应不断变化的网络环境。3 评 估
3.1 数据集

3.2 评价指标

3.3 几种降维方法对算法性能影响的比较

3.4 与最新的技术比较

4 讨 论
5 结束语
