基于Word2vec和卷积神经网络特征提取的双高疾病预测
2021-02-25范会敏
谢 爽 范会敏
(西安工业大学计算机科学与工程学院 陕西 西安 710021)
0 引 言
高血压和高血脂是常见慢性病,早期一般没有症状,是心脑血管疾病的主要危险因素[1]。《2017中国心血管病报告数据》中指出,双高疾病对我国公民的危害日益加剧,人们对双高的预防治疗手段的需求也越来越迫切。
在如今信息发展迅速的现代化社会中,医疗数据大部分都以电子医疗病历的形式记录,其中包含诊断、症状、检查和化验等信息,具有维度高、稀疏的特点。针对医疗数据维度高、稀疏的特点,一些疾病预测模型被提出。
传统的疾病风险预测主要基于Cox比例风险回归模型及逻辑回归模型。Cox比例风险模型是由英国统计学家D.R.Cox提出的一种半参数回归模型。Wang等[2]利用Cox模型,基于弗雷明汉心脏研究来建立房颤患者发生脑卒中及死亡的风险预测模型。该研究脑卒中预测模型和脑卒中或死亡预测模型的H-L统计量分别为7.6和6.5,AUC分别为0.66、0.70。
尽管传统的回归方法在疾病预测方面有广泛的应用,但这些方法在预测准确度和模型可解释方面仍有提升的空间。近年来,机器学习领域的特征选择和有监督学习建模方法越来越多地用于疾病预测问题。
Khosla等[3]采用了特征选择和机器学习方法来预测5年内的脑卒中发生率。该研究的数据来自心血管健康研究数据集,采用了四种方法进行缺失值填充,包括均值填充、中位数填充、线性回归,及期望最大化方法;特征选择方法包括前向特征选择、L1正则化和保守均值特征选择;建模时尝试了支持向量机和基于边缘的删失回归方法。使用L1正则化逻辑回归进行特征选择,然后使用支持向量机进行预测,采用十折交叉验证的平均测试AUC(Area Under Curve)为0.764,优于L1正则化Cox模型。将各种特征选择算法与预测算法相结合的平均显示,保守均值和基于边缘的删失回归相结合在AUC评价标准中能达到0.777,为性能最佳的结果。
Choi等[4]在心衰的预测上率先使用了基于循环神经网络(RNN)的方法。针对单个临床事件的建模采用了自然语言理解中常用的one-hot向量的方式,把任何一个临床事件都表示成N维的向量,但向量的最后一位为事件发生时间距离预测时间的间隔,类似于一个时间戳。使用门循环单元从每个输入的临床事件向量计算相应的隐状态,在最终的隐状态上应用逻辑回归模型计算最后的心衰风险概率。与线性回归、支持向量机和K近邻算法等多种经典回归或机器学习方法实验对比后发现,基于RNN方法的预测AUC有提高。
综上所述,由于电子病历数据高维度、高稀疏的特点,疾病预测研究的重点主要在特征处理方面。因此,本文提出一种Word2vec和卷积神经网络相结合的特征提取方法(WV-CNN),从特征处理方面入手进行双高疾病的预测研究。
1 WV-CNN特征提取方法
使用Word2vec进行词语表示,得到的词向量为低维稠密性实数,并且很好地保留了语义信息[5],最后利用卷积神经网络从局部到全局相关性特征的学习能力,对大量文本向量进行深度学习,将文本特征中的重要信息提取出来,以提高预测效果。
1.1 Word2vec词向量库构建
由于针对医学体检领域的文本特征提取,需要采用该领域的文本进行向量库的训练,得出的词向量更贴合该问题领域。具体词向量库构建流程如图1所示。
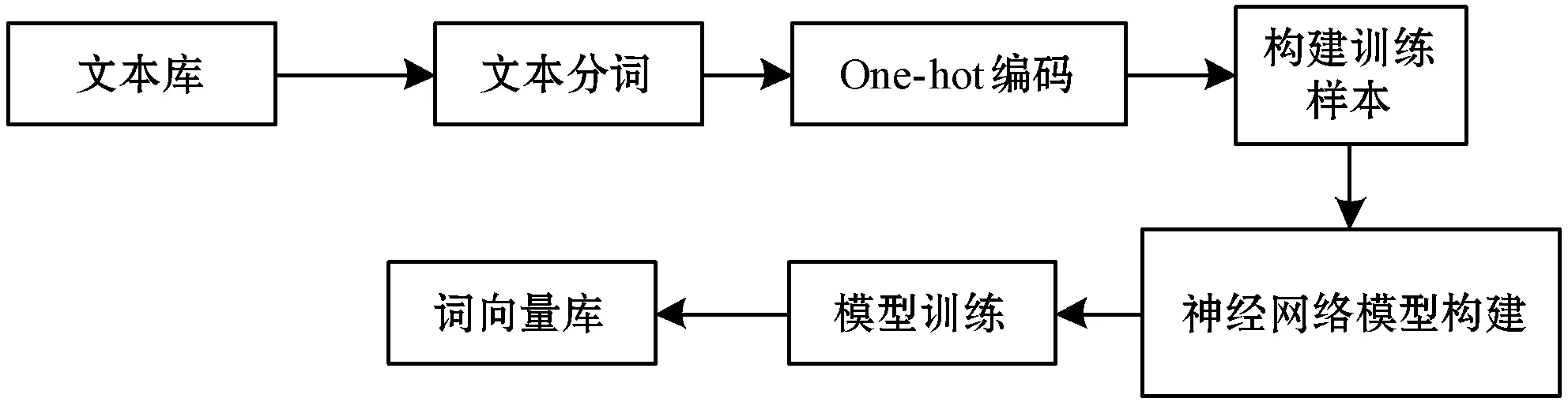
图1 词向量库构建
先对文本Di进行分词处理Di=[wi,w2,…,wn],n为词语个数。再根据Word2vec词向量库把分词后的文本替换成低维数值向量Wi=[Vi1,Vi2,…,Vik],k为词向量的维度,如图2所示。

图2 词向量表示
经过上述处理过程使文本特征从高维度、高稀疏数据,变成了类似图像的连续稠密矩阵数据表示,并且进一步作为下一步卷积神经网络的输入。这种文本向量化表示免去了一般特征处理的繁琐工作,让文本原始信息得到了最大限度的保留。
1.2 卷积神经网络提取特征
卷积神经网络结构如图3所示,有输入层、卷积层、池化层、全连接层四层,特征以词向量的形式输入到神经网络中,经过卷积层、池化层提取出特征中的重要信息,最后再经过全连接层输出特征。

图3 卷积神经网络结构
经过Word2vec词向量,令xi∈Rk为对应于文本特征中的第i个词的k维词向量,将这些词向量作为卷积神经网络的输入。长度为n的文本表示为:
x1:n=x1⊕x2⊕…⊕xn
(1)
式中:⊕是连接运算符;xi:i+j指的是词向量xi,xi+1,…,xi+j的连接。
卷积中卷积核w∈Rhk作用在h个词向量上以产生新特征,h为卷积步长。卷积核扫过词向量xi:i+h-1生成特征ci,计算式表示为:
ci=f(w·xi:i+h-1+b)
(2)
式中:b∈R是偏置项;f(·)是激励函数。文本表述中,单个主语、主语+谓语、主语+谓语+宾语三种文本表述组合就能将一个句子的主要意思简洁地表述清楚。卷积层中,考虑到上述三种文本表述组合,卷积核大小分别为1个词向量、2个词向量和3个词向量三种。
使用非线性函数作为激励函数,使神经网络表达能力更加强大,不再是输入的线性组合,几乎可以逼近任意函数,以协助表达复杂特征。常见的激励函数有Sigmoid函数、tanh函数和ReLU函数等,本研究中使用tanh函数:
(3)
卷积核作用于文本{x1:h,x2:h+1,…,xn-h+1:n}中产生特征映射,表示为:
c=[c1,c2,…,cn-h+1]c∈Rn-h+1
(4)
然后,在特征映射上进行最大化池化操作,并取最大值c=max{c}作为对应于该特定卷积核的特征,这是为了在特征映射找到最据代表性的特征,最后再经过全连接层直接输出特征。卷积神经网络的具体参数设置如表1所示。

表1 卷积神经网络参数设置
2 实 验
2.1 实验设计
基于数据挖掘的疾病预测的步骤包括数据集的预处理、特征工程、使用机器学习算法训练预测模型,然后使用测试集验证模型的效果。数据预处理是指对训练集和测试集中的特征规范化,如科学计数法表示数据的处理、数值与字符混合数据的处理等。数据中含有文本型数据,运用特征提取方法将文本型数据中的关键信息提取出来并转化为向量,作为新的特征合并到数据集中,然后利用预测算法预测出双高的具体数值。
为了验证WV-CNN的效果,从输入数据量级和预测算法等几个不同角度对算法进行对比实验。
在训练过程中分别使用Doc2vec算法和WV-CNN算法进行特征处理,将处理后的数据特征输入到训练后的模型中,对测试集进行预测,得到对每个个体的收缩压、舒张压、甘油三酯、高密度脂蛋白胆固醇和低密度脂蛋白胆固醇五项指标的预测结果,并与实际检测值进行对比。对比实验设计如图4所示。

图4 实验设计
实验使用均方误差MSE作为评价指标,其第j项的计算式为:
(5)

(6)
本实验采用的数据集是由体检中心提供的共10 000条个人体检信息数据集,涉及BMI指数、心电图、B超、血液检验和尿液检验等一系列数值型和文本型数据特征。实验中,对数据集按9 ∶1的比例分为训练集和测试集,再在训练集中以9 ∶1的比例分为训练集和验证集。其中,训练集的作用是计算梯度并更新权重;验证集的作用为确定正确的超参数,以避免过拟合现象的发生;测试集的作用为给出实际的评价指标。
2.2 不同数量级样本数据对比实验
在疾病预测中,样本数据的大小不仅影响预测的效率还对预测的准确率有着极大的影响。样本数据不是越大越好,对于每一个具体问题,都有其最合适的样本数据。为验证在不同样本数据输入下Doc2vec算法和WV-CNN算法的MSE值变化,本实验分别在支持向量机(SVM)和梯度提升树(GBDT)算法下进行对比实验,结果如图5和图6所示。

图5 SVM算法预测

图6 GBDT算法预测
实验结果表明,相对于其他预测算法,WV-CNN算法的MSE值在不同的数量级输入下基本都要低于Doc2vec算法。
由图6可见,在输入样本数量在500和1 000左右时,Doc2vec算法的MSE值比WV-CNN算法略微高一些,分析原因主要是因为输入样本数量太少,导致经卷积神经网络提取到特征信息有限。在图5和图6中,随着输入样本数量的增加,MSE值都呈下降趋势。此外,在输入样本数量为8 000或8 500左右时MSE值较低,且之后MSE值趋于稳定。
2.3 不同预测算法对比实验
为了验证WV-CNN方法在不同预测算法下的有效性,本实验分别选取线性回归、支持向量机、随机森林、梯度提升树和极端梯度提升(XGBoost),在输入样本数量为8 000的相同环境下进行对比实验,实验结果详细数据如表2所示。

表2 Doc2vec方法与WV-CNN方法在不同预测算法下的对比实验结果
实验结果表明,在使用不同的预测算法情况下,本文算法的MSE值都要低于Doc2vec算法。可以看出,支持向量机算法相对于其他算法的预测效果而言最差,但经过WV-CNN算法得到的MSE值相比Doc2vec算法下降了0.314 2,经过特征提取改进后预测效果提升明显。相对于其他算法,极端梯度提升算法的MSE值变化不明显,使用了WV-CNN算法特征提取后MSE值下降了0.081 7,但预测效果最稳定。综合比较,经WV-CNN算法提取文本特征后再使用极端梯度提升算法预测获得的MSE值最小,达到了0.025 4。
2.4 实验结果
为了验证WV-CNN算法对文本特征提取的有效性,本文进行了一系列对比实验,分别从输入数据数量级、预测算法两方面进行实验,采用MSE值作为评价指标,得到了多组实验结果,结果数据汇总如表3所示。
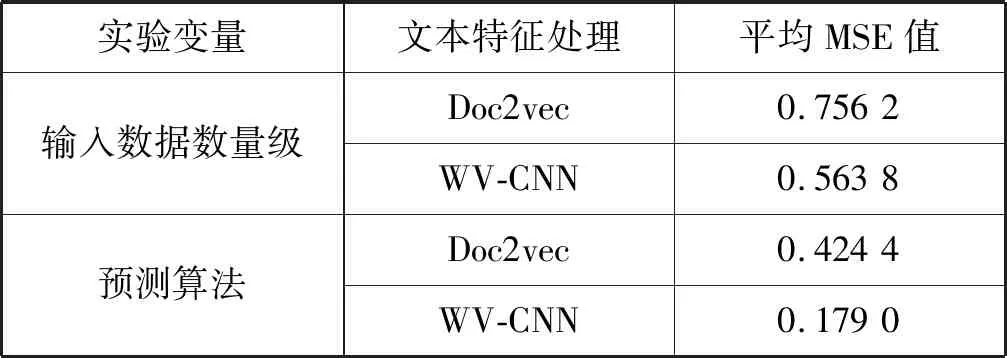
表3 实验结果汇总
实验结果表明,本文算法的特征提取能力优于Doc2vec算法。本文算法在不同输入数据数量级的MSE值平均降低了0.192 4,在各个不同预测算法中MSE值平均降低了0.245 4。经过上述对比实验可以得出,在双高疾病预测中,WV-CNN算法的特征提取能力在不同输入数据数量级和不同预测方面都有很好的表现。
3 结 语
在双高疾病预测过程中,本文提出了一种基于WV-CNN的特征提取方法,对体检中心提供体检数据进行特征处理,并且使用Doc2vec算法作为对比组对特征进行处理。经过不同数量级样本数据和不同预测算法两个对比实验,结果表明:基于WV-CNN的特征提取在疾病预测方面有较低的误差率,具有不错的效果。尽管如此,基于WV-CNN的双高指标预测方法在疾病预测方面仍然不够完善,下一步将继续完善预测模型。今后研究中,将基于WV-CNN的低误差率预测,根据对双高影响程度大小对体检项目进行排序,从数据分析的角度得到导致双高的原因,医护人员可以以此调整双高治疗方案。
