基于A*算法的2种任务-处理器分配改进算法
2021-02-23高卫斌柳晓龙
高卫斌,柳晓龙
(1.宁德职业技术学院 信息技术与工程系,福建 宁德 355000;2.福建农林大学 计算机与信息学院,福建 福州 350002)
随着计算机和计算机网络的发展,分布式计算系统已成为富有吸引力的选择.为了利用分布式计算系统的有效并行性,必须把任务恰当地分配给处理器.把任务分配给处理器可以是动态的或静态的.
假设把一个并行程序用一个任务来表示,一个机器网络用一个处理器来表示,则分配任务给处理器也称为分配或映射问题[1-2];已提出了众多算法来实现分布式计算系统中的任务分配,如网络流算法[3]、状态空间搜索算法[4]、聚类算法[5]、装箱算法[6]以及概率和随机优化算法[7-8].这些算法大多可以分为最优算法和次优算法;最优算法可以进一步分为条件限制的或无条件限制算法.次优算法又分为近似算法或启发式算法.
在大多数情况下,任务分配问题是NP-完全的[9].一种任务分配算法总是寻求使某个成本函数最优化,如吞吐量最大或周转时间最小.通常,最优解可以通过穷举搜索来得到,但由于这种方法中m个任务可以分配给n个处理器,因而有nm种方式,故穷举搜索往往是不现实的.因此,最优解算法仅存在于有条件限制的情况下或非常小型化的问题;另一种可能性是采用提示性搜索来减少状态空间,如A*算法.尽管A*算法可以保证最优解,但由于其很高的时间和空间复杂度而不能应用于大型问题.
对此,本文在对A*算法原理分析的基础上,提出了2种基于A*算法的改进算法.一种是节省内存空间和减少任务执行时间的按序搜索最优分配算法,一种是提高算法执行时的加速性的并行搜索最优分配算法.
1 问题模型及A*算法原理
1.1 问题模型
一般情况下,有2种任务图模型:任务优先图(Task Precedence Graph,TPG)和任务交互图(Task Interacting Graph,TIG)[10-12].TPG模型通过找到任务之间的优先级关系来表示并行程序;在TIG模型中,多个任务可以同时运行,而不考虑它们的优先级.
本文的目标是将一个给定的任务图分配给一个处理器网络,以使程序完成所需的时间最小化.为使提出的算法兼具实用性和通用性,采用松弛假设和任务交互图模型,把并行程序用一个无向图来表示:
GT=(VT,ET) ,
(1)
式中VT为顶点集{t1,t2,…,tm},ET为边集(由任务之间的通信需求量来表示).也可以把处理器网络表示为一个无向图,其顶点代表处理器,边界代表处理器的通信链路;用一个nn连接矩阵L表示n个处理器{p1,p2,…,pn}的互连网络,如果处理器i和j是直接连接的,则L中的元素Lij为 1,否则为0,不考虑i和j不直接连接的情况.
可以在n个处理器系统上的任何一个处理器上执行集合VT中的一个任务ti.每个任务在一个给定的处理器上都有一个相关的执行成本,用矩阵X表示任务执行成本,矩阵X中的元素Xip表示任务i在处理器p上的执行成本;在2个不同处理器上执行的2个任务ti和tj当它们需要交换数据时会导致一个通信成本;任务映射将2个通信任务分配给同一处理器或2个直接连接的不同处理器;用矩阵C表示任务之间的通信,矩阵C中的元素Cij为任务i和j之间的通信成本(i和j为2个不同的处理器).
一个处理器的负荷(成本)包括与其分配的任务相关的全部执行和通信成本,最重负荷处理器所需要的时间决定整个程序的完成时间;任务分配问题必须找到一组m个任务到n个处理器的映射,使得程序完成时间最小化.把任务分配(映射)给处理器用一个矩阵A来表示,如果任务i分配给处理器p,则Aip为1,否则为0,p上的负荷表示为:
(2)
式中第一部分为分配给处理器p的任务的总执行成本,第二部分为处理器p上的通信开销,Aip和Ajq分别表示任务i和j分配给2个不同的处理器p和q,Lpq表示p和q是直接连接的.为了找到最重负荷的处理器,需要计算n个处理器中每个处理器上的负荷.
1.2 A *算法原理
A*算法是一种优先搜索算法,用公式表示为:
f(n)=g(n)+h(n) .
(3)
式中f(n)是从初始状态经由状态n到目标状态的估计成本,g(n)是在状态空间中从初始状态到状态n的实际成本,h(n)是从状态n到目标状态的最短路径的估计成本(对于路径搜索问题,状态就是图中的节点,成本就是距离或时间).
为了找到最短路径(最优解),关键在于成本函数f(n)的选取,由于g(n)很容易得到,所以f(n)的选取其实就是关于h(n)的选取.
为了得到成本函数f(n),由于g(n)容易得到,所以主要是计算h(n);为了计算h(n),定义2个集合:Tp—分配给最重负荷处理器p的任务集,U—在搜索阶段未被分配的任务集.U中的每个任务都将被分配给处理器p或与p有直接通信链路的任何其他处理器q.因此,可以把2种成本与每个ti的分配关联起来:或者Xip(在p上的任务ti的执行成本)或Tp中与ti链接的全部任务的通信成本的总和.这意味着考虑ti的分配,必须决定是否ti应当分配给p(考虑这2种情况下的最低成本).令cost(ti)为这两个成本的最小值,则h(n)为:
h(n)=∑ti∈Ucost(ti) .
(4)
1.3 A *算法在任务分配中的应用
下面用实例问题来说明A*算法在任务分配中的具体实现过程.
假设有5个任务{t0,t1,t2,t3,t4}的任务集和3个处理器{p0,p1,p2}的处理器集,如图1所示,图1(a)中两个任务之间的连线上的数字表示它们之间的通信成本,图1(b)为3个处理器构成的环形拓扑,图1(c)中的行数字是位于该行的任务分别在3个不同处理器上的执行成本;采用A*算法得到的搜索树如图2所示.
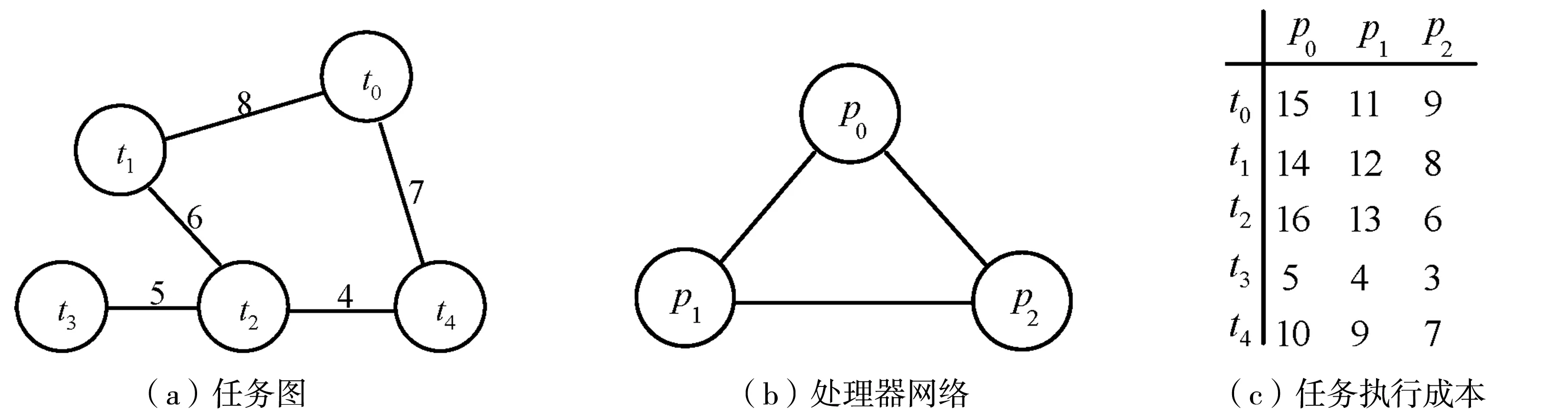
图1 实例任务集和处理器集
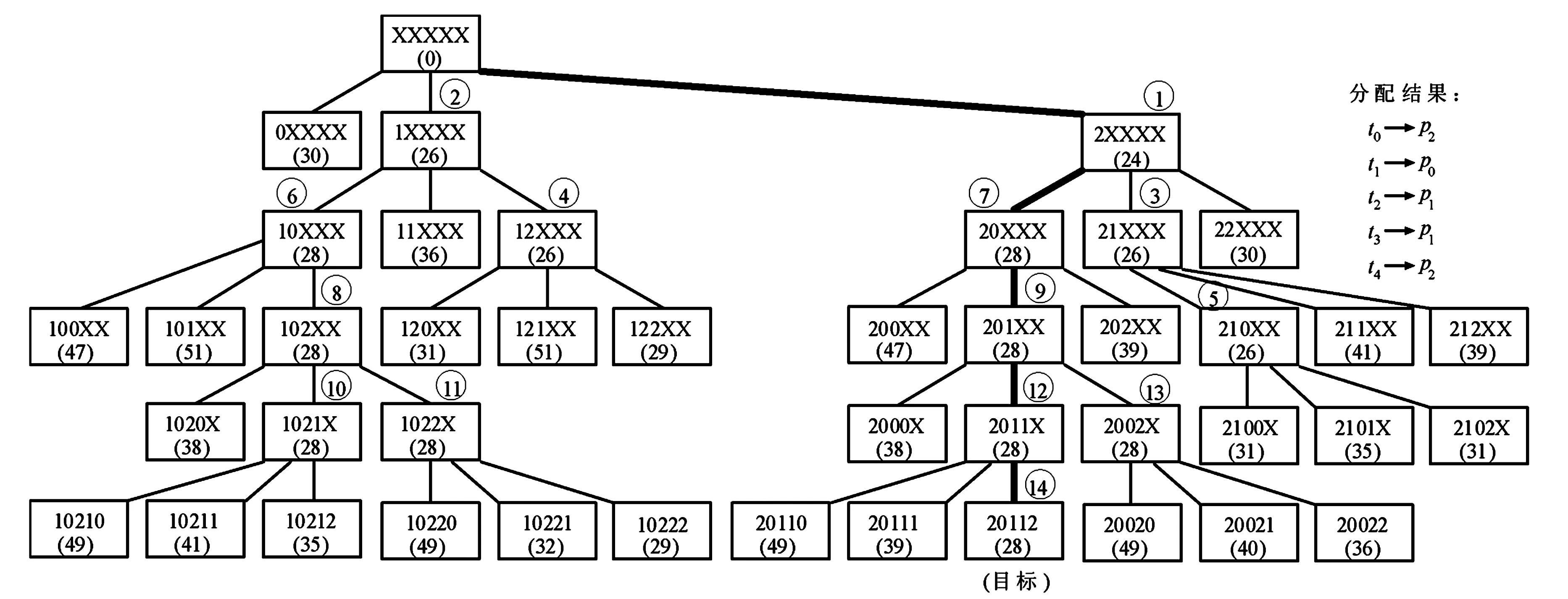
图2 采用A*算法得到的搜索树(生成42个节点,14个扩展节点)
搜索树节点(图2中的矩形方框)包括分配给处理器的部分任务(方框中第一排带X的内容)和f值(方框中第二排圆括弧中的数字,即部分分配的成本).把m个任务分配给n个处理器用一个m进制字符串a0,a1,…,am-1来表示,ai(0≤i≤m-1)表示算法已经分配第i个任务的处理器(0~n-1).部分分配意味着某些任务未被分配;ai的值为X表示第i个任务还没有被分配.树的每级对应一个任务,这样,将这个任务分配给一个处理器来替换具有某个处理器编号的分配字符串中的X.节点扩展意味着添加一个新的任务分配到部分分配中.因此,搜索树的深度d等于任务数m,且树的任何节点都可以有一个最大值后继节点数n.
根节点包含全部未分配任务XXXXX的集合.如图2,考虑把t0分配给p0(0XXXX),t0分配给p1(1XXXX)和t0分配给p2(2XXXX),以确定树的第一级分配成本.把t0分配给p0(0XXXX)得到总成本f(n)等于30.在这种情况下,g(n)等于15,这就是在p0上执行t0的执行成本,h(n)也等于15,这就是t1和t4(与t0相连接的任务)的最小执行或通信成本的总和;类似地,可计算出把t0分配给p1的总成本是26,把t0分配给p2的总成本是24.算法将这3个节点插入到OPEN列表.因为24是最小成本,故算法选择节点2XXXX作为扩展.
算法用下列方式扩展节点2XXXX.在树的第二级,算法会考虑分配t1,20XXX、21XXX和22XXX为3个可能的分配;对于20XXX,它的f(n)值是28,计算如下:选择具有最重负荷的处理器,这时是p0,g(n)等于22,即在p0上执行t1的执行成本(14)加上t1和t0之间的通信成本(8),因为它们被分配给2个不同的处理器,h(n)等于6,这是t2的最小执行或通信成本(唯一与t1相连接的未分配的任务);同样方式可计算出21XXX和22XXX的f(n)值.这时,节点0XXXX、1XXXX、20XXX、21XXX和22XXX在OPEN列表中.由于节点1XXXX有最小的节点成本,故算法下一步扩展它,得到节点10XXX,11XXX和12XXX.
图2中某些节点上圆圈中的数字表示该节点被选择为扩展采用的顺序,图中的粗实线表示连接到得到最优分配的节点边界.搜索继续进行,直到进程选择具有完全分配(20112)的节点作为扩展.这时,因为该节点具有完全分配和最小成本,所以它是目标节点,全部分配字符串是唯一的;图2中,算法考虑分配任务的顺序是{t0,t1,t2,t3,t4}.在最优解的搜索过程中,生成42个节点并扩展14个节点.
2 提出的改进算法
2.1 按序搜索最优分配算法
按序搜索最优分配(Optimal Assignment with Sequential Search,OASS)算法采用A*搜索技术,但有2个明显的不同.首先,算法得到一个随机解,并删除在最优解搜索过程中比此解的成本高的全部节点.删除不必要的节点不仅节省了内存,而且还节省了插入节点到OPEN所需的时间;其次,对于全部叶子节点,算法设置f(n)的值等于g(n),因为对于一个叶子节点n来说,h(n)等于0就避免了全部叶子节点上的h(n)的不必要的计算;算法实现的伪代码如算法1所示,算法1对于前面的实例问题得到的搜索树如图3所示.显然,算法的效率明显得到提高.
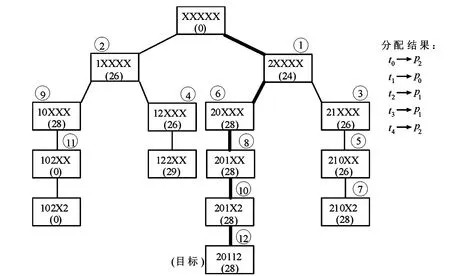
图3 按序搜索最优分配算法得到实例问题的搜索树
算法1 按序搜索最优分配算法实现的伪代码
1.得到一个随机解
2.设S_opt为这个解的成本
3.对任务重新排序
4.构建初始节点s并把它插入到OPEN列表
5.令f(s)=0
6.repeat
7.选择具有最小f值的节点n
8.if(n不是解)
9.生成n的后继节点
10.for每个后继节点ndo
11.if(n不位于搜索树的最后一级)
12.f(n)=g(n)+h(n)
13.elsef(n)=g(n)
14.if(f(n)=S_opt)
15.插入n到OPEN列表
16.endfor
17.endif
18.if(n是解)
19.报告解并终止运行
20.until(n是解)或(OPEN列表为空)
2.2 并行搜索最优分配算法
并行搜索最优分配(Optimal Assignment with Parallel Search,OAPS)算法是尽可能使用并行处理加速搜索,通过将搜索树在处理单元(Processing Elements,PEs)之间尽可能均匀地进行划分和通过避免不必要的节点扩展来实现的.算法基于系统中PEs的数目P以及搜索树中一个节点的后继节点的最大数目S静态地划分搜索树.为了说明算法原理,采用2个PE(PE1和PE2),将10个任务分配给4个处理器.这里S为4,指一个搜索树节点最多可以有4个后继节点,即每个PE生成编号为1到4的4个节点,如图4所示(图中矩形框里的数字是节点的f值),PE1得到分配的节点1和3,PE2得到节点2和4.

图4 并行搜索最优分配算法的初始静态划分
由于PEs被连成一个网状拓扑,故一个PE最多可以有4个邻居,且PE首先与它的邻居通信,故得到相对较小的通信开销,使得算法比采用全局通信策略更具可扩展性.算法2所示为OAPS算法实现的伪代码.采用初始负荷划分,每个PE在它的OPEN列表中有1个或多个节点,全部PE建立起它们的邻居来找到它们的相邻PEs.一个PE确定它的邻居是通过使用它自己的处理器网格位置和它的x、y坐标;一个PE用初始节点扩展开始节点,周期性地采用RR方式选择一个邻居,而且发送它最好的节点给邻居来实现邻近搜索空间的最好部分的共享;除了这种负荷均衡方式外,一个PE也广播它的解(当它得到一个解时)给所有PE,这样有助于避免一个PE不必要工作在搜索空间差的部分;一旦一个节点接收到一个比它目前最好节点还好的成本解,就停止扩展不必要的节点;得到第一个解的PE广播它的成本给所有其他PE.然后,当且仅当一个PE的成本优于先前接收到的解时,它才广播这个解;当一个PE得到一个解时,则记录下这个解并停止,即得到最低成本的最优解.
算法2并行搜索最优分配算法实现的伪代码
1.初始划分
2.建立邻居
3.repeat
4.扩展OPEN中最好成本的节点
5.if(得到一个解)
6.if(如果这个解比先前得到的任何解都好)
7.把这个解广播给全部PE
8.else
9.告知邻居
10.endif
11.记录下解并终止运行
12.endif
13.if(OPEN的长度增加)
14.采用RR选择一个临近的PE j
15.发送OPEN中当前最好的节点给j
16.endif
17.if(从邻居接收到一个节点)
18.把它插入到OPEN
19.if(从PE接收到一个解)
20.把它插入到OPEN
21.if(解发送者是一个邻居)
22.从邻居列表中移除它
23.endif
24.until(OPEN为空)或(OPEN为满)
3 实验结果
3.1 负荷生成
为了测试本文提出的2种改进算法的性能,收集10~20个节点的任务图数据和5个不同的通信-成本率(Communication-to-Cost Ratios,CCR)以及采用完全连接和环形2种不同拓扑结构的4节点处理器图,对于OAPS算法,采用2、4、8和16个32位英特尔Paragon 作为PE,CCR的5个值取0.1、0.2、1、5和10.
3.2 OASS算法的存储效率
首先来比较OASS算法和A*算法的内存节省情况.A*和OASS都开始于重新排序任务,但OASS得到一个随机解来消除不必要的节点,从而节省了大量内存,得到的实验结果如表1所示.从表1可见,CCR为0.1的4个处理器采用完全连接拓扑结构时,10~20个节点的任务图的OASS算法生成的节点数和扩展的节点数都要比A*算法少得多,平均节省内存约72.14%.

表1 环形连接拓扑结构(CCR=0.1)时的内存节省情况
表2为4个处理器在完全连接拓扑情况下的A*算法和OASS算法得到的运行时间.从表2可见,OASS算法在运行时间上比A*算法有很大幅度的减少,A*算法对于16个以上的任务不能得到解,而本文的OASS算法相比于A*算法,不仅在运行时间上有改善,而且能得到全部任务的解.

表2 完全连接拓扑结构时(CCR=0.1)的执行时间
3.3 OAPS算法的加速性能
本节通过在不同数量的PEs上运行本文提出的OAPS算法和A*算法,观察2种算法的加速比,从而来评价OAPS算法的加速性能.表3所示为对于4个处理器在完全连接拓扑和CCR为0.1时得到的加速比结果.表的第二、第三、第四和第五列分别对应于2、4、8和16个Paragon PE情况下的加速比,最后一行为所考虑的全部任务图的平均加速比.从表3可见,在不同PEs数目的情况下,对于全部任务图来说,OAPS算法与A*算法的加速比始终大于1,说明OAPS算法具有比A*算法更好的加速性;而且在相同PEs的情况下,加速比几乎是呈线性的,随着PEs数目的增加而增大,说明本文提出的OAPS算法是稳定可靠的,同时有很好的扩展性.

表3 全连接拓扑结构(CCR=0.1)时2种算法的加速比
4 结 论
分配问题的NP-完全性决定了其最坏情况下的复杂性为指数级,而本文提出的基于A*算法的2种改进算法大大降低了复杂度,有助于得到中等规模问题的最优解;按序搜索算法在内存和时间方面得到了相当大的改进,而且采用完全连接的处理器拓扑结构将进一步提高算法的性能;并行搜索算法在加速性能方面更有优势,如果不考虑最优解而考虑接近于最优的解,则有更好的加速性能.
