基于SNOMED-CT的医疗术语语义相似度计算方法
2021-02-16吕晓云
戴 敏,朱 森,吕晓云
(天津理工大学计算机科学与工程学院,天津 300384)
医疗物联网(internet of medical things,IoMT)技术的发展推进了医疗服务、医疗保健的普及和发展。许多基于IoMT的工具、软件和设施已用于远程健康跟踪、身体恢复锻炼、慢性病人群和老年人群的护理[1-2]。当健康数据关联到具体的个体时,若处理不当,可能会引发严重的用户隐私曝光问题。
在医学领域内已经制定了关于隐私保护的正式条例,如《健康保险携带和责任法案》规定了在医疗文件允许发布之前应删除个人可识别信息[3]。美国许多州和联邦法律也规定,在向第三方发布医疗记录之前,必须对艾滋病状况、药物或乙醇滥用以及精神健康状况等因素进行脱敏[3-5]。
医疗文本中很多文本术语在语义上都是相关的,单纯删除或涂黑敏感术语(如艾滋病)可能会提高潜在攻击者的警觉性,并且未处理的语义相关术语(如免疫系统、流感和无保护的性行为)可能会增大敏感术语被揭露的风险[6]。因此,如何用语义泛化的形式来处理敏感术语,以及如何发现和处理语义相关术语成为了医疗文本脱敏工作的重点[7]。
文献[8]提出了一种基于信息量(information content,IC)的医疗文本自动脱敏方法,该方法不仅对敏感术语进行脱敏,还检测了语义相关的术语。该方法以搜索引擎必应(https://cn.bing.com)链接的资源来计算IC值以确定敏感词,并利用知识库将其泛化为通用术语。但互联网中的数据存在流动性的特点[9],特定医疗数据在搜索引擎中所链接的资源的稀疏性受阶段性流行病和社会舆论指向的影响。另外,依照数据稀疏性来判断术语敏感与否,可能会使一些非常用的非敏感术语被识别为敏感术语。
医学术语系统命名法-临床术语(systematized nomenclature of medicine-clinical terms,SNOMEDCT)作为世界上最全面的临床医疗术语,在国际上的临床医学数据分析的研究中应用极为广泛[10-12]。因其收录的大量医学概念及详细的分类结构,已被许多科研工作者用作医疗文本脱敏的知识库[13-14]。本文在分析SNOMED-CT结构的基础上,提出了一种基于SNOMED-CT的语义相似度计算方法,该方法可以有效地应用于医疗文本的语义脱敏。
1 SNOMED-CT结构分析
SNOMED-CT是目前最为全面的国际标准医学术语系统,包含30多万个医学概念和130多万个关系[15]。因具备完整、稳固的语义基础和结构化的术语表达形式,被医学领域许多信息模型指定为标准编码系统,在国际医疗与健康领域中有着广泛地应用。
SNOMED-CT概念模型由概念、描述和关系组成,并采取统一的数字标识符来唯一地表示各个概念、描述和关系,SNOMED-CT的逻辑结构如图1所示,其中概念关系可分为2大类。
第1类是继承关系(“IS_A”关系),又称“上下位关系”或“父子关系”,从纵向上连接语义上具有包含与被包含关系的概念。IS_A关系是SNOMED-CT建立概念分类层级体系的基础,众多语义上具有包含与被包含的概念基于IS_A关系纵向聚合,形成了SNOMED-CT中不同的概念分类层级体系。除了顶级的“根概念”——“SNOMED Concept”外,每个概念均至少有一个IS_A关系与上位概念相关联。
第2类是“概念模型属性”关系,从横向上连接两个概念并确定概念间的语义关系[16]。如图1中的“肺炎—肺结构”、“气管支气管炎—气管支气管结构”等都是概念模型属性关系。SNOMED-CT实际运用了60种概念模型属性,形成了数十万条的横向语义关联关系。
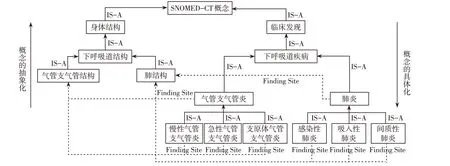
图1 SNOMED-CT的逻辑结构Fig.1 Logical structure of SNOMED-CT
2 语义相似度计算方法
结合SNOMED-CT的结构特点,本文利用SNOMED-CT中的2类概念关系来计算医疗术语的语义相似度,即计算2个概念的语义相似度时考虑2个因素:概念的具体化程度和语义距离。
2.1 具体化程度
在如图1所示的SNOMED-CT的逻辑结构中,概念所在的层次(深度),即概念节点与根节点之间的纵向关系距离(即“IS_A”关系数量),代表了概念描述内容的具体化程度。每一层都是对上层概念的具体化,也是对下层概念的泛化,故深度越大,具体化程度越高。设c1和c2是SNOMED-CT中的2个概念,则这2个概念节点的具体化程度可表示为:

式中,h代表c1和c22个概念节点的最小公共祖先的深度。最小公共祖先的深度越大,概念的具体化程度越高,反之亦成立。
2.2 语义距离
在SNOMED-CT的逻辑结构中,概念节点之间的横向关系距离(即“概念模型属性”关系数量)代表了2个概念之间的语义距离。设c1和c2是SNOMED-CT中的2个概念,可以用两个概念节点之间的最短路径长度描述2个概念的语义距离,其公式为:

式中,d是概念节点c1和c2之间的最短路径。
由此可见,两个概念节点之间的最短路径距离越大,它们之间的语义距离就越大,反之亦成立。
2.3 术语相似度的计算公式
综合考虑SNOMED-CT中2个概念间的2类关系,2个概念的相似度计算公式为:

由于一个单词可能具有多种概念含义,本文用与单词相关的概念的相似度最大值来描述单词之间的语义相似度。设单词q1具有多个概念(c11,c12,…,c1a),单词q2具有多个概念(c21,c22,…,c2b),则2个单词q1,q2间的语义相似度的计算公式为:

一篇医疗文本中包含若干医疗术语,每个医疗术语通常由若干单词组成。假设术语p1包含多个单词(q11,q12,…,q1m),术语p2包含多个单词(q21,q22,…,q2n),则2个术语之间的语义相似性的计算公式为:
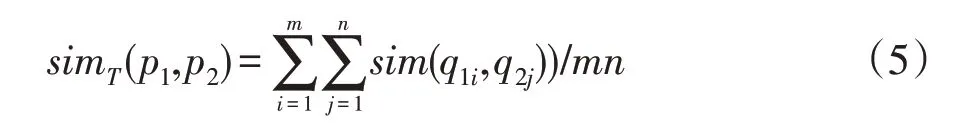
3 实验及结果分析
本文实验数据为从维基百科(Wikipedia)选择的6类共42篇医疗文本,这些文本分别从医学角度描述了性传播疾病、艾滋病毒、艾滋病、精神障碍和药物滥用。为了评估本文方法的有效性,以2名医疗专家对各文本进行手动脱敏的结果为参照标准,从脱敏精度和实用度两方面对本文方法与基于IC的脱敏方法进行了比较。
3.1 脱敏精度评估
本文用3个指标来评价脱敏的精度,分别是精准度(precision)、召回率(recall)和F-度量(Fmeasure,Fmea)。
精准度用来描述自动脱敏方法识别出敏感术语的准确率,其计算公式为:

式中,A代表自动脱敏识别出的敏感术语,B代表手动脱敏识别出的敏感词。Ppre越高,表明自动脱敏识别敏感术语的准确率越高。
召回率用来描述自动脱敏方法对文本中敏感术语的识别率,其计算公式为:

Prec越高,说明敏感术语的识别率越高。在文本脱敏过程中,Prec通常比Ppre更重要,若Prec过低,则意味着有更多敏感术语未被识别出来,文本披露隐私风险越高。
Fmea用Ppre和Prec的谐波均值来表示脱敏的准确性,其计算公式为:

用本文方法与基于IC的方法分别对6类文本进行脱敏实验,表1所示为精度实验结果的对比。
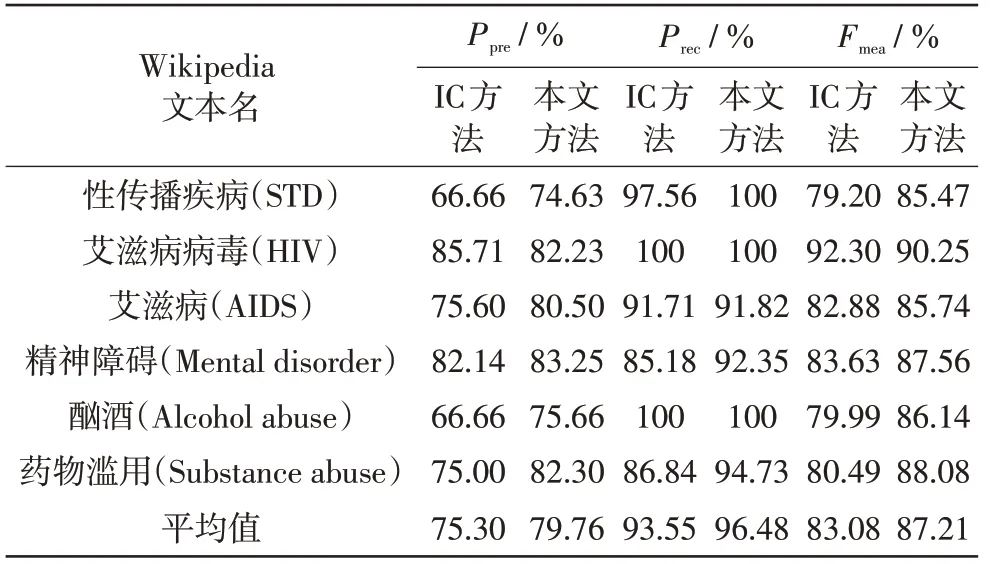
表1 精度实验结果的对比Tab.1 Comparison of accuracy test results
由表1可知,与基于IC的方法相比,采用本文方法对上述6类医疗文本进行脱敏,精准度、召回率和F-度量的平均性能分别提高了5.92%、3.13%和4.97%。
3.2 实用性评估
实用性代表了文本脱敏后的实用程度,即信息量的保留程度。本文采用文献[8]提出的基于IC的评估方式评估脱敏后文本相对于原文本所保留的实用性。
某术语t所包含的信息量可用其CIC值表示,其计算公式为:

式中,p(t)为t在知识库中出现的概率,这里以搜索引擎百度所链接的资源作为评估知识库。CIC(t)越高,意味着t包含着更多的信息量。
一篇文本的信息量为该文本所包含术语提供的信息量的总和,假设文本D包含多个术语(t1,t2,…,tn),则其信息量的计算公式为:

式中,ti为文本中所包含的术语。
文本脱敏后的实用性保留程度Putility的计算公式为:

式中,D为脱敏前的文本,D′为脱敏后的文本。
采用对比本文提出的方法与基于IC的方法脱敏后的文本的实用性进行分析,表2所示为实用性对比实验结果。
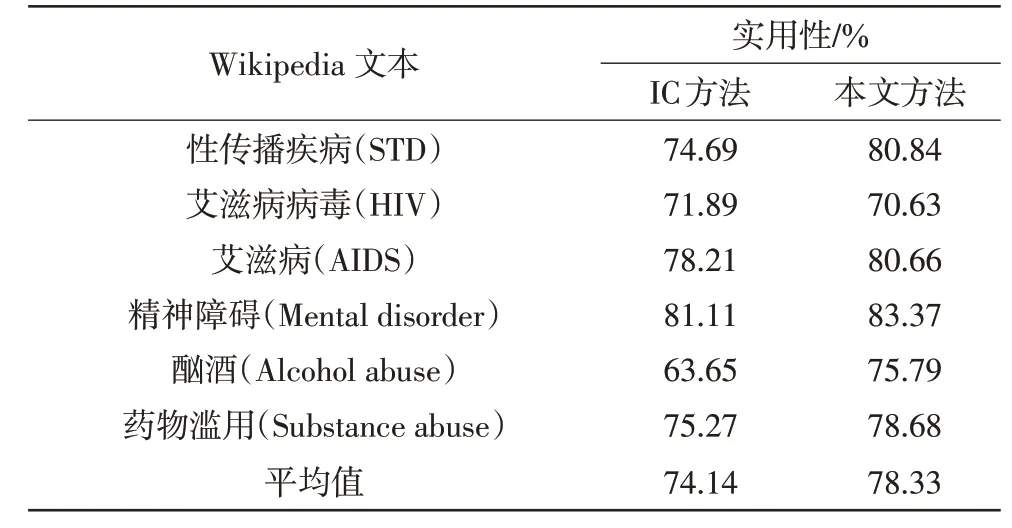
表2 实用性对比实验结果Tab.2 Experiment results of practicability comparison
由表2可知,与基于IC的方法相比,采用本文提出的方法脱敏后文章的实用性平均提高了5.65%。
4 结论
本文在深入分析SNOMED-CT知识库结构的基础上,提出利用该知识库中2类概念关系计算医疗术语的语义相似度计算方法,并将该方法用于医疗文本的脱敏。对从Wikipedia上选取的6类共42篇医疗文本进行脱敏提出的实验,结果表明,与基于IC的脱敏方法相比,本文提出的方法在脱敏精度和实用度方面都有一定幅度的提高,适用于以SNOMED-CT作为知识库的医疗文本敏感词识别和脱敏。
