一种室内混响语音盲分离算法
2021-02-09曾金芳陈达张钰李友明
曾金芳 陈达 张钰 李友明
摘 要:在信號处理领域,室内环境下的混响语音盲分离一直以来都是一个重点与难点,主要是由于混合系统存在的混响和回声严重影响了语音质量,从而降低了算法分离效果。因此,本文提出了一个应对算法,由麦克风采集到室内混响语音混合信号后,对该混合信号进行两阶段去混响处理:首先通过设计一个逆滤波器来抑制早期混响或增大信号混响能量比,再采用谱减法来消除回声;然后将处理过的时域卷积混合语音信号通过短时傅里叶变换转化为频域各个频点的瞬时混合形式,用IVA算法分离混合语音信号,最终恢复为时域语音信号。实验表明,该方法可以有效提高室内混响环境下的语音盲分离效果。
关键词:去混响;盲源分离;频域分离;时域卷积
*基金项目:湖南省自然科学基金(2018JJ3486)
0 引言
盲源分离(blind source separation, BSS)是指当源信号参数和信号混合模型都未知时,基于输入源信号的统计特性,将源信号从观测信号分离出来的过程。盲源分离技术先后应用于文本数据挖掘、语音信号处理、地球物理信号处理等多个领域[1-3]。
独立分量分析[4](independent component analysis, ICA)算法是解决盲源分离问题的一个常用且高效的算法。然而,在真实的室内环境中,由于室内存在的混响和回声,接收器接收得到的信号一般都不是线性混合的,而是卷积混合的。因此通常采用频域ICA算法进行分离。频域ICA算法是通过短时傅里叶变换(short-time fourier transform, STFT)将混合信号由时域的卷积混合转到频域各个频点的瞬时混合,再使用ICA算法进行分离。但传统的频域ICA算法通常存在幅度模糊性和排序模糊性问题[5-6],经过学者们的不断研究,目前已有许多算法被用来解决该问题 [7-8],如独立向量分析(IVA)算法。
频域ICA算法另一个需要注意的是混响强弱问题,处理不好会导致分离性能严重下降。在无噪声条件下,混响语音的质量主要依赖于两个不同的感知成分:早期混响和回声。它们分别对应两个物理变量:信号混响能量比和混响时间。受此启发,我们采用一种单麦克风双级语音去混响算法[9]。在第一阶段,通过估计一个逆滤波器来抑制早期混响或增大信号混响能量比。在第二阶段,采用谱减法来减少回声的影响。实验表明,该算法在一定程度上抑制了室内的混响和回声,提高了语音的质量。
由于混响和回声的存在,室内混响语音盲分离导致算法性能严重下降。因此,通过结合两阶段去混响算法和IVA算法,构建出一个新的算法模型,来处理真实室内环境下的语音盲分离问题,即先对室内混响语音混合信号进行两阶段去混响处理,抑制早期混响和消除回声,再将目标信号转到频域,用IVA算法分离语音信号,最终恢复为时域语音信号。
1 语音卷积混合模型


至此,在室内混响环境下,其时域上的卷积混合便转换成为频域各个频点上的瞬时混合。
2 一种室内混响语音盲分离算法
2.1 本文算法流程
算法流程图如图1所示。首先,接收一段室内混响语音信号,对该混响混合信号采用两阶段去混响算法,滤除信号中存在的混响和回声,增大信号混响能量比和减小信号混响时间,再使用STFT变换将信号由时域上的卷积混合转换成为频域各个频点上的瞬时混合,采用IVA算法分离语音信号,最后通过STFT逆变换恢复为时域语音信号。
2.2 两阶段去混响
通常在室内环境中,信号在传播时会产生混响和回声。因此,一个麦克风接收到的信号分为直达语音和混响成分。直达语音,即直接到达麦克风的语音。混响成分一般分为早期混响和回声,如图2所示,室内脉冲响应的早期部分(t<50 ms)看起来像一连串脉冲,显示了房间的早期混响。脉冲响应的后面部分(t>50 ms)看起来更随机,则是房间的后期混响,也就是回声。由于脉冲响应的两个部分的不同性质,本文用一个两阶段去混响算法分两阶段解决这两种干扰。在第一阶段,我们通过估计一个逆滤波器,以抑制早期混响。第二阶段,我们采用谱减法来消除回声的影响,如图3所示。
1)抑制早期混响
在单通道去混响算法的第一阶段,我们通过估计一个逆滤波器来抑制早期混响效应或增大信号混响能量比[11]。

图4显示了图2逆滤波后的室内脉冲响应波形图。通过图2与图4的对比可以看出,图2原始脉冲响应50 ms之前的混响成分幅度大、多且杂乱,而图4逆滤波室内脉冲响应波形图50 ms之前的早期混响部分在很大程度上被抑制住了。由此可得出,此算法估计的逆滤波器能在一定程度上抑制室内脉冲响应的早期混响部分,增大信号混响能量比,提高语音质量。




3.3 仿真结果
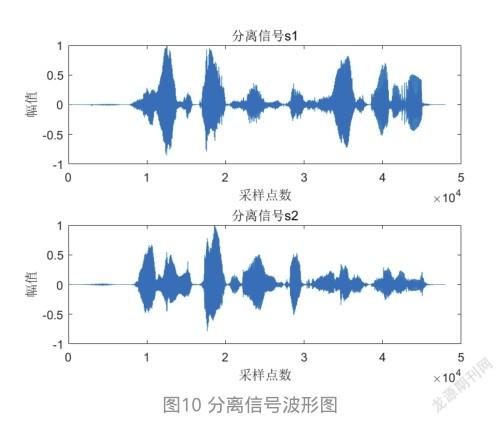
对两组信号采用本文提出的基于去混响的室内混响语音盲分离算法进行分离,并输出波形。两组语音的源信号、混合信号以及分离出来的信号均如图7所示。为了美观,本文只列出了一组室内混响语音盲分离的波形图。源信号如图7所示。将源信号与通过Roomsim生成的混响冲击响应卷积得到混合信号,如图8所示。再将混合信号经过两阶段去混响处理,得到语音去混响波形图,如图9所示。最后通过本文提出的算法得到分离信号波形图,如图10所示。

通过图8与图9之间对比可以看出,经过去混响算法后,混合语音细节变得更加清晰,且明显消除了室内混响所产生的回声。因此,两阶段去混响算法效果十分明显。
通过将图10和图7进行对比可以看出,该算法能够将源信号有效分离出来。但是仅仅通过观察,并不能准确评价算法的分离效果。因此本文引入盲源分离工具箱来评估算法的分离效果,并与未进行两阶段去混响的原频域分离算法进行对比分析。通过实验仿真,得到两组数据的两种算法的SIR和SDR性能参数,如图11和图12。从图11中可以看出,改进算法的SIR相对于原算法最高获得了2.13 dB的提升,SDR最高提升了1.21 dB。
4 结语
针对室内混响环境下卷积混合语音信号存在混响和回声而导致频域盲分离精度低的问题,提出了一种新的室内混响语音盲分离方法,可以有效提高室内混响语音盲分离的效果。
参考文献:
[1] LEGLAIVE S, BADEAU R,RICHARD G.Separating Time-Frequency Sources from TimeDomain Convolutive Mixtures Using Non-negative Matrix Factorization[C]. IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), Oct 2017, New Paltz, New York, United States.
[2] 张华,冯大政,庞继勇.卷积混迭语音信号的联合块对角化盲分离方法[J].声学学报(中文版),2009,34(02):167-174.
[3] 季策,姜雨田.基于方向幅值比的欠定盲源分离算法[J].东北大学学报(自然科学版),2019,40(07):920-924.
[4] 陈秀敏,李珊君,董兴建.Fast-ICA算法非线性函数性能的仿真分析[J].计算机应用与软件,2020,37(06):277-282+333.
[5] 李扬,张伟涛,楼顺天.基于联合对角化的声信号深度卷积混合盲分离方法[J].电子与信息学报,2019,41(12):2951-2956.
[6] 张天骐,张华伟,刘董华,李群.基于区域增长校正的频域盲源分离排序算法[J].电子与信息学报,2019,41(03):580-587.
[7] 冷艳宏,郑成诗,李晓东.功率比相关子带划分快速独立向量分析[J].信号处理,2019,35(08):1314-1323.
[8] 朱坚坚,王惠刚,李虎雄.联合频域盲语音分离排序算法[J].计算机应用,2008(06):1552-1554+1562.
[9] WU M, WANG D. A two-stage algorithm for one-microphone reverberant speech enhancement[J]. IEEE Transactions on Audio, Speech, and Language Processing, 2006, 14(3): 774-784.
[10] 顧凡,王惠刚,李虎雄.一种强混响环境下的盲语音分离算法[J].信号处理,2011,27(04):534-540.
[11] GILLESPIE B W, MALVAR H S, FLORENCIO D, et al. Speech dereverberation via maximum-kurtosis subband adaptive filtering[C]. international conference on acoustics, speech, and signal processing, 2001: 3701-3704.
[12] HAYKIN S.Adaptive Filter Theory[M].4th ed. Upper Saddle River, N.J.: Prentice-Hall, 2002.
[13] NAKATANI T, MIYOSHI M.Blind dereverberation of single channel speech signal based on harmonic structure[C]. international conference on acoustics, speech, and signal processing, 2003: 92-95.
[14] KIM T,ATTIAS H T,LEE S Y,et al.Blind source separation exploiting higher-order frequency dependencies[J].IEEE Transactions on Audio Speech &Language Processing, 2006,15(1):70–79.
[15] 张天骐,徐昕,吴旺军,等.多反复结构模型的精确音乐分离方法[J].声学学报, 2016(1): 135-142.

