基于语义相似性的跨模态图文内容筛选存储机制研究
2021-02-07冯树耀肖志立
刘 渝 郭 婵 冯树耀 周 可 肖志立
1(华中科技大学武汉光电国家研究中心 武汉 430074)2(深圳市腾讯计算机系统有限公司技术工程事业群 广东深圳 518054)(liu_yu@hust.edu.cn)
多媒体数据的井喷式增长使得非结构化多模态数据在云端存储中占据的比例剧增,进而催生了大量的分析需求,使得存储系统在满足数据存储稳定性的同时,对数据分析的服务与支持越来越受到关注.
然而,非结构化多模态数据的分析需求大多建立在内容感知与语义关联之上,这使得传统存储系统在提供服务时捉襟见肘.一方面,传统存储系统只完成了对数据浅层内容的感知,即对数据属性的获取.这些属性不具备完整描述非结构化数据语义的能力.另一方面,传统存储系统没有为应用分析提供最佳的数据管理与查询结构.现有的树形结构导致语义上相近的数据在存储逻辑结构中可能相距甚远.在这2个方面的共同制约下,现有存储系统在面对应用分析时只能先从存储系统中读出所有的数据,从而陷入漫长的读取等待中.以1亿张图像,每张图像大小为1 MB的分析为例,部署在腾讯数据中心上的SATA硬盘(顺序读取带宽为220 MBps)需要5.26天完成读取.更为不幸的是,被读取的数据中只有小部分真正参与了实际分析.以腾讯QQ相册所在的数据中心为例,我们分别针对含有“动物”“人”“植物”“风景”的数据进行收集与分析,来自6台服务器内的相关数据分别平均占比仅为20.11%,53.45%,17.01%,29.43%.大量的数据经过简单分析并被发现无关后即刻被弃用,但之前读取造成的带宽消耗已经无法弥补.
为解决以上问题,我们设想是否可以在数据读取前进行简单的筛选,通过只读取与分析相关的数据减少读取时间.具体的,从语义层面感知数据,获取表达语义的元数据,之后建立新的结构管理这些元数据.如果获取语义元数据与筛选的时间小于不相关数据的读取时间,那么我们的工作将是有效且有意义的.
基于此,我们以非结构化数据中占比最多的图像(视频的基础内容)和文本为对象,研究改进现有的存储系统机制,以满足在图像或文本为请求的分析需求下,从存储层面筛选内容语义相近的图文进行读取,从而实现支持分析需求的存储系统.本文提出了基于语义相似性的跨模态图文数据内容筛选存储机制(cross-modal image and text content sifting storage, CITCSS).并从以下2方面入手:第一,针对大规模异构多模态的图文数据,在存储环境下以相同范畴感知其语义,以相似性Hash码实现图像和文本之间的统一空间表示,以元数据形式进行管理.第二,在现有的存储系统中以语义元数据为内容,图谱化关联为结构设计内容筛选功能,支持用户在分析前根据文件的语义相关性缩小读取范围,从而节省读取时间和带宽.
值得一提的是,我们提出的筛选机制适用于应用分析场景,这种场景关注相关数据的找到与相关数据表达出的共同规律.因为语义筛选机制的引入,存在部分相关数据遗漏的问题,但在较高的召回率下,并不会影响其业务需求.比如检索业务,最为关心的是前N个数据中的相关数据,而不是所有数据.
本文的主要贡献有3个方面:
1) 存储环境下的跨模态图像文本统一语义表征算法的嵌入与实现.在损失少量精度的前提下,采用二值化Hash方法,实现轻量级语义Hash元数据管理.同时,克服图像和文本之间的模态差异,实现相似性内容的统一空间融合;
2) 语义Hash图谱构建的设计与实现.从元数据层面提供相似内容筛选接口,利用语义相近Hash码间汉明距离短的特性,在Neo4j实现语义关联.并在元数据图谱中提供深度遍历接口,支持相关节点查找;
3) 在线筛选相似内容文件接口的设计与实现.基于语义Hash图谱中间件,在可接受的召回率下,筛选与需求相关的图像和文本进行返回.在公开的跨模态数据集中,模拟按需筛选的效果.实验表明,与传统的语义存储系统相比,CITCSS在召回率超过98%的性能下,读取延迟相对降低了99.07%~99.77%.
在后续的章节中,首先介绍本研究相关的研究现状、本研究用作存储系统和元数据系统的物理组件以及本文使用的Hash算法基础模型;然后提出CITCSS总体设计框架与工作流程;最后通过实验验证本文方法的实用性和有效性.
1 相关工作
1.1 语义存储系统
现存的大规模语义数据存储模型主要分为2种:关系型模型与图模型.1)关系模型直接进行关系映射[1],使用关系型数据库将语义和数据进行关联.Wilkinson等人[2]提出了采用属性表的方式存储语义数据.Weiss等人[3]构建六元组索引,使得语义中的每一个数据都可以建立索引,加快索引速度.Du等人[4]构建Hadoop集群索引,集群中的每一个节点都可以提供存储和检索服务.2)图模型基于图的数据管理方式可以更好地维护语义结构,并且通过图的匹配实现语义查询.Udrea等人[5]对特定类型的语义数据构建一种轻量型索引结构.Zou等人[6]将语义的主体或者客体对应图的顶点,并将语义数据的查询语句转换为子图完成匹配.
这些语义存储系统在取得突破的同时却忽略了本质的问题,即管理的内容.以属性进行关联不可能真正做到对数据内容语义的管理,尤其针对非结构化数据标签不完整的情形.因此,在现有系统之上,注入内容语义的元数据,既是本文的初衷,也是语义存储系统需要完成的首要任务.
1.2 跨模态检索
跨模态检索是跨越模态间差异实现特征相似性感知的一种多媒体检索方式[7].二进制表示的相似性Hash码则具备存储上的优势,并且基于异或的汉明距离度量方式具有极高的运算速度.He等人[8]使用标准增强学习方法学习双模态数据的Hash函数.Zhang等人[9]提出了基于语义相关最大化的Hash跨模态模型.语义主题多模态Hash[10]对文本进行聚类,对图像矩阵进行分解,得到语义上的主题,对原始数据向语义主题所在的公共子空间的映射进行Hash编码.Lin等人[11]提出将训练数据的语义相似度作为监督信息转化为概率分布,通过最小化KL(Kullback-Leibler)散度,在汉明空间中使用待学习的Hash码对其进行近似处理,然后用带有采样策略的核逻辑回归学习Hash码.Jiang等人[12]设计了一种端到端的深度神经网络跨模态Hash学习框架.它无需人工标注,并使用负对数似然损失来保证跨模态相似性.在此基础上,Li等人[13]又提出了一种将自监督的语义学习与对抗性学习相结合的深度Hash网络.利用2个对抗网络共同对不同的模态进行建模,并在学习到的语义特征监督下进一步捕获它们的语义相关性和表示一致性.
基于Hash的跨模态检索适用于存储环境,但尚无研究表明如何在存储系统下嵌入此类Hash算法,如何在不影响存储性能及稳定性的条件下应用此类Hash算法.因此,本文将尝试在存储系统下嵌入跨模态Hash算法,实现元数据的生成.
2 存储系统与元数据系统
2.1 OpenStack Swift存储系统
本文采用OpenStack对象存储组件Swift[14]搭建多模态数据混合云存储的架构平台,原因在于:
1) Swift对于文件大小和数目没有限制.本文研究对象为大规模跨模态图像文本数据,其中单个文本文件相对于图像文件所占据的存储空间较小,适合使用Swift完成存储.
2) Swift中的元数据以分布式进行管理.从元数据的可扩展性和安全性考虑是更优的选择.
3) Swift使用Python进行开发,贴近本文将结合的深度学习算法工具PyTorch[15],TensorFlow[16].从系统的开发兼容性考虑更加合适.
Swift中的文件作为独立的对象以其文件名称的Hash值和最后的操作时间组成存储路径.原生态Swift存储系统没有跨模态文件的分析处理机制,我们在其基础上以图数据库添加语义信息,管理元数据.
2.2 Neo4j图数据库
图数据库在以关联为需求的检索方面具有天然优势.本文使用Neo4j[17]图数据库完成语义元数据载入与修改.数据批量导入包括CREATE,LOAD CSV,neo4j-import[18].CREATE适用于1万个节点内的插入.LOAD CSV用于加载本地或远程CSV的实时插入,每秒约能插入5 000个节点.neo4j-import占用资源少但只能构建新的图谱,作为启动时构建元数据图谱使用.
3 Hash算法
自监督对抗式Hash(self-supervised adversarial hashing, SSAH)算法主要研究双峰数据(即图像和文本)的跨峰检索,通过采用2个对抗网络共同学习高维特征及其对应不同模态数据的Hash码.双模态数据同时通过一个自监督的语义网络,利用多标签注释修正语义信息,通过有监督的对抗性学习,最大程度地跨越模态差异提取语义相关性.
SSAH分为2个阶段:在第1阶段中,从各自模态中提取语义信息关联至公共语义空间中.由于深度神经网络中的每个输出层都包含语义信息,因此在公共语义空间中关联特定的模态信息可以帮助提升模态之间的语义相关性.在第2阶段中,语义特征和特定于模态的特征反馈给2个对抗网络,使得2种模态的特征分布在相同语义特征的监督下趋于一致.
跨模态Hash的主要功能是为不同模态数据学习统一的映射函数.假设Hash码集合为Bv,t∈{0,1}K,其中上标v表示来自图像数据集,上标t表示来自文本数据集,K表示Hash码的长度.2个Hash码bi∈Bv,t和bj∈Bv,t之间的相似性使用汉明距离disH(bi,bj)进行表达.汉明距离和Hash码内积bi,bj之间的关系为因此可以使用内积来量化2个Hash码之间的相似性.假设源数据间语义相似,则Sij=1,否则Sij=0,在集合B内的实例相似性概率可以表示为

(1)
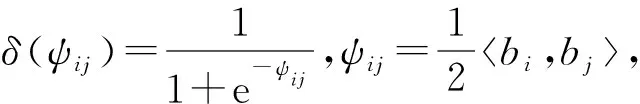
通过构建2个对抗网络ImgNet和TxtNet分别独立地学习图像模态和文本模态的Hash函数Hv,t=fv,t(v,t;θv,t).同时,还构建一个端到端的自监督语义网络LabNet,以便在学习语义特征的Hash函数的同时,在公共语义空间中对图像和文本模态之间的语义相关性进行建模,即Hl=fl(l;θl).其中,l表示来自标签集,fv,t,l表示Hash函数,θv,t,l表示网络参数,对Hv,t,l应用符号函数生成二进制Hash码Bv,t,l:
Bv,t,l=tanh(Hv,t,l)<0,B∈{0,1}K.
(2)
为方便理解,我们使用Fv,t,l来表示图像、文本和标签公共语义空间中的语义特征.Fv,t,l也对应于深度神经网络ImgNet,TxtNet,LabNet的输出层.
值得一提的是,传统跨模态Hash模型中往往只以高维特征相似性保持为依据进行特征选择,这种方式无法克服2种模态间对于实例表达时的语义鸿沟,使得不同批次下的数据难以在训练中获得统一的映射机制(表现为损失函数难以收敛).SSAH选择以标签集作为中间桥梁调和图像与文本间的语义鸿沟,不仅弱化了直接拟合2种模态特征的难度(因为文本和特征在拟合标签上都已经十分成熟),同时以标签集中的多个实例作为拟合通道更是实现了特征细化,使得图像或文本中的多个实例能够被独立的理解和捕获.另外,使用对抗网络交互提升图像和文本对于同一标签的拟合,能够防止在单一模态数据上出现过拟合现象.因此,SSAH能够针对多标签的图像和文本数据获得比现有方法更准确的特征,从而获得更好的Hash码.
SSAH模型训练通过3个损失函数完成,即自监督学习的目标损失函数、图像和文本特征学习的损失函数和对抗学习的损失函数.
1) 自监督学习的目标损失函数
使用三元组(vi,ti,li)来描述相同的第i个实例,将li作为图像数据集vi和文本数据集ti的自监督语义信息,在LabNet中,通过非线性变换将语义特征投影到汉明空间中,从而很好地保留语义特征与其对应的Hash码之间的相似关系.因此,LabNet的目标损失函数表述为
(3)
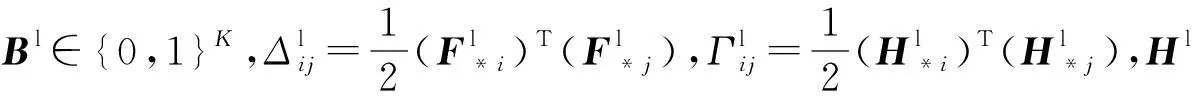
2) 图像和文本特征学习的损失函数
针对图像和文本的不同模态的自监督特征学习的目标损失函数可以写为
(4)
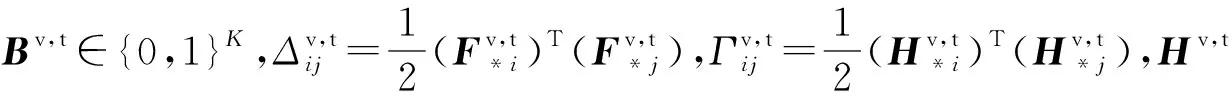
3) 对抗学习的损失函数
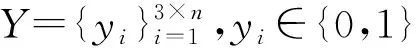
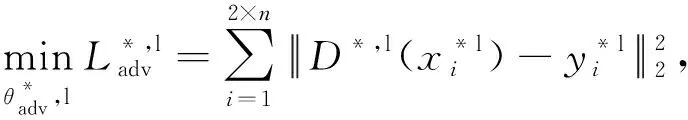
(5)

本文选择SSAH作为Hash元数据生成算法原型的主要理由如下:
1) SSAH产生的Hash码具有轻量级存储、计算速度快等优势,适合海量跨模态数据的内容表示;
2) SSAH是目前为止最新且效果最好的跨模态Hash算法,能够更准确地拟合不同模态特征中一致的分布,从而有效地捕获语义之间的相关性.
4 CITCSS
4.1 CITCSS总体框架
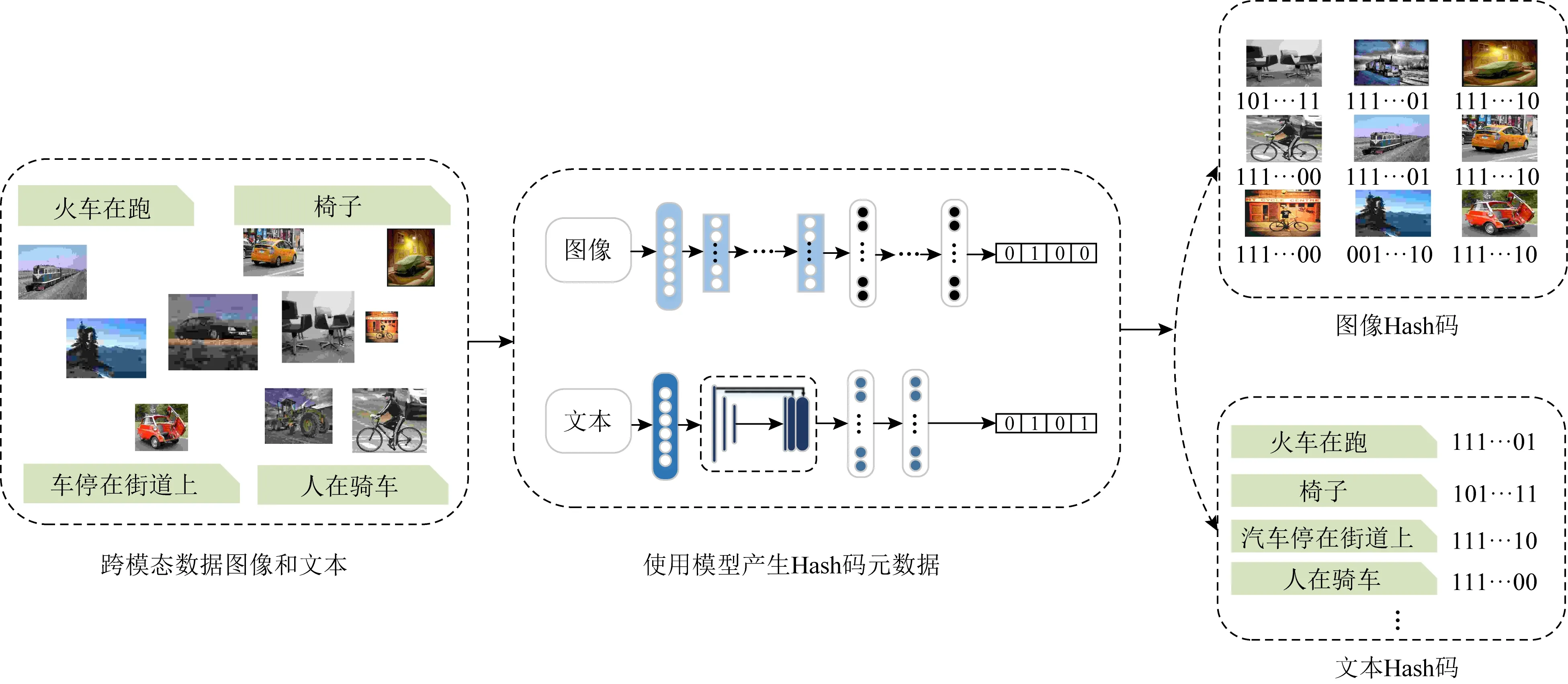
CITCSS总体框架和数据流如图1所示.框架由3部分组成:Hash元数据生成模型(Hash code meta-data generating model, HCMGM)、语义Hash图谱(semantic Hash code graph, SHG)和文件存储系统(file storage system, FSS).HCMGM用于获得图像和文本内容的Hash元数据,即相似性Hash码.SHG以Neo4j为载体管理Hash元数据.本文将语义相关的对象聚类到图的相邻区域,从而提供准确且快速的内容筛选机制.SHG开辟独立的空间进行管理,不影响原有文件系统的元数据组织.FSS是一个以文件为对象的存储系统,海量的图像和文本文件可以批量上传,单个新的图像或文本文件在生成Hash码元数据的同时,原有机制同时运行.

Fig. 1 The overall framework of CITCSS图1 跨模态图文数据内容筛选存储系统CITCSS整体框架
该系统实现内容筛选机制的工作总体流程如图2所示,分为离线处理和在线筛选2个阶段.离线处理阶段,首先训练HCMGM,然后通过模型获得所有数据的Hash元数据,最后根据汉明距离和阈值在Neo4j上构建SHG.在线筛选阶段,根据用户的筛选条件利用Neo4j的Cypher查询语言筛选出SHG中内容相似的节点,进而筛选出与分析相关的文件返回给用户.较之传统存储系统,CITCSS不需要在分析前读取所有的数据内容,从而降低了数据的读带宽压力.

Fig. 2 The overall workflow of CITCSS图2 跨模态内容筛选机制的工作总体流程
4.2 HCMGM
4.2.1 概况
图3展示了HCMGM示意图.该模型主要由3个部分组成,包括1个自监督的语义生成网络LabNet,以及2个分别针对图像模态和文本模态的对抗网络ImgNet和TxtNet,其中实线箭头表示通过前向传播得到结果,虚线箭头表示在反向传播前需要进行的计算.HCMGM包含以下3个学习阶段.

Fig. 3 The framework of HCMGM图3 Hash元数据生成模型示意图
1) 自监督生成语义.跨模态数据集的表现形式为1个实例带有多个标签.多标签注释能够作为细粒度级别上桥接模态之间语义相关性的条件而被使用.LabNet是一个端到端的全连接深度神经网络.给定一个实例的多标签向量,LabNet会逐层提取抽象语义特征,从而监督ImgNet和TxtNet的学习过程.
2) 特征学习.为了保持跨模态实例的语义相关性,本文使用LabNet监督从语义特征学习Hash码的过程.ImgNet负责将图像特征投影到Hash码中,因为使用相同的LabNet监督学习过程,所以本文可以保持ImgNet与语义网络之间相同的语义映射.同样的,在考虑文本形式时,本文使用语义网络以相同的方式监督TxtNet的特征学习过程.
3) 对抗学习.尽管在LabNet的监督下,跨模态语义的相关性可以得到保留.但是不同的模态会有着不一致的特征分布.为了降低这种差距,模型引入对抗性学习,分别为图像和文本模态建立2个鉴别器DrcNet,鉴别器的输入通过LabNet生成的图像或文本的模态特征和语义特征,输出为单一值,即“0”或“1”,本文将给定的标签定义为“1”,将由ImgNet(TxtNet)生成的图像(文本)标签定义为“0”.
4.2.2 损失函数
损失函数是模型训练的目标约束条件.预测值与实际结果偏离越大,损失值越偏大.一般情况下,随着优化器的调整和训练轮数的增加,损失值会逐渐趋于稳定,表明模型训练完毕.本文模型中,主要应用3个损失函数:对比损失、对抗损失和分类损失.下面详细阐述了设计过程.
1) 对比损失.这里使用均方误差(mean squared error, MSE).对于特征比较损失的计算如下:
(6)
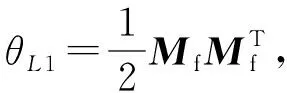
(7)
lossPairF=FMSE(θL1,lg(1+eθL1)),
(8)


(9)
lossPairH=FMSE(θL2,lg(1+eθL2)),
(10)
2) 对抗损失.本文将图像模态特征和标签反馈给图像鉴别器,将文本模态特征和标签反馈给文本鉴别器,通过这2个鉴别器相互对抗来训练模型.对抗损失的计算如下所示:

(11)
其中,xv l和xt l分别表示图像和文本在公共空间中的语义特征,而yv l和yt l则分别是图像和文本的模态标签,这里通过平方损失来放大计算的数值.
3) 分类损失.通过标签网络LabNet自监督地训练图像网络ImgNet和文本网络TxtNet,每个网络都有其对应的分类损失,计算如下:
lossS=α×lossPF+γ×lossPH+βFMSE(B,Hl)+
ηFMSE(l,L)+δ×lossD,
(12)
其中,lossPF为图像或文本的特征比较损失,lossPH为图像或文本的Hash比较损失,B为图像或文本预测的Hash码,Hl=fl(l;θl)则为Hash模型,fl是Hash函数,θl是要学习的网络参数,l是预测的标签值,L是本身所属的标签,预测Hash码和标签的损失依然采用平方损失函数,lossD为对抗损失,α,γ,β,η,δ均为超参数.
4.2.3 优化器
模型训练是一个不断优化最小化目标函数J(θ)的过程,实现该过程的算法即可称为优化器.优化器的通用表达如下:

(13)
Adam算法综合考虑了梯度的均值和未中心化的方差这2项来不断修正迭代更新的步长,从而达到一个自适应调整的效果.Adam算法优化过程如下:

(14)

4.2.4 网络参数配置
HCMGM中包含了4个网络的设计:ImgNet,TxtNet,LabNet和对抗网络DcrNet.下面我们将分别详细描述这4个网络的设计情况.
1) ImgNet
首先我们对图像文件提取语义特征.目前针对图像特征的提取,大多采用CNN网络架构.考虑特征提取的准确性和网络架构的复杂程度,本文选择VGG-19作为ImgNet主干.VGG-19包含19个隐藏层,包括16个卷积层和3个全连接层,每个卷积层使用3×3卷积核,步长为1,最大池化层核尺寸为2×2,步长为2.为了将VGG-19应用到Hash模型的图像特征提取网络中,我们改进VGG-19结构,保留卷积层并将全连接层由4 096维降到512维,输出层为N维.改进后的VGG-19的网络结构如图4所示,conv表示卷积层,maxpool表示最大池化层,fc表示全连接层,depth表示深度.
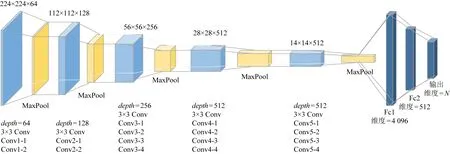
Fig. 4 Themodified VGG-19 network structure图4 更改后的VGG-19的网络结构图
2) TxtNet
针对文本特征提取,我们使用了一种多尺度融合模型(MS),该模型由5个平均池化层和1个1×1的卷积层组成,首先用多个平均池化层提取文本数据的多个比例特征,然后使用1×1卷积层融合多个特征,从而捕获不同文本之间的相关性.其中,5个平均池化层的卷积核大小分别是1×1,2×2,3×3,5×5,10×10.
本文使用3层前馈神经网络和多尺度融合模型构建TxtNet.输入文本经过模型,获得1个4 096维的向量,然后经过2个全连接层,将特征维度降到512维,再到N维.如图5所示:
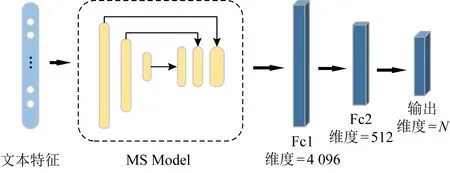
Fig. 5 The TxtNet network structure图5 TxtNet的网络结构图
3) 自监督语义标签网络
本文使用4层前馈神经网络构建LabNet,该网络以标签为输入使用2个全连接层进行映射,按照L→4 096维→512维→N维进行提取.
4) 对抗网络
对抗网络模型使用2个鉴别器分别监督图像和文本的特征获得.单个鉴别器使用3层前馈神经网络构建,经过2次4 096维转换,得到0或1的结果.4个网络设计中,图像特征提取网络ImgNet、文本特征提取网络TxtNet、自监督语义标签网络LabNet都将输出层的维度降到N维.N由Hash码的长度和跨模态数据集的总类别标签个数决定.假设Hash码的长度选取为32 b,跨模态数据集总类别标签个数为81,那么N=32+81=113.之后,结合损失函数和优化器的设计,利用标签进行自监督训练,通过随机梯度下降(stochastic gradient descent, SGD)和反向传播(back propagation, BP)[21]算法学习模型参数.
4.2.5 HCMGM训练流程
按照SSAH模型设计,分别构建标签网络LNet,图像网络INet,文本网络TNet和2个鉴别器网络DNet.模型分别独立地结合标签网络LNet训练图像网络INet和文本网络TNet,在训练的过程中计算对抗损失、成对比较损失等,从而使标签网络、图像网络和文本网络的参数逐渐收敛.流程如算法1所示.
算法1.训练HCMGM.
输入:图像文本跨模态数据的训练集trainSet,批处理大小BatchSize,训练轮数epoch;
输出:训练好的HCMGM模型及参数,LNet,INet,TNet,2个DNet.
① 初始化LNet,INet,TNet,DNet;
②L,I,T←splitData(trainSet,BatchSize);
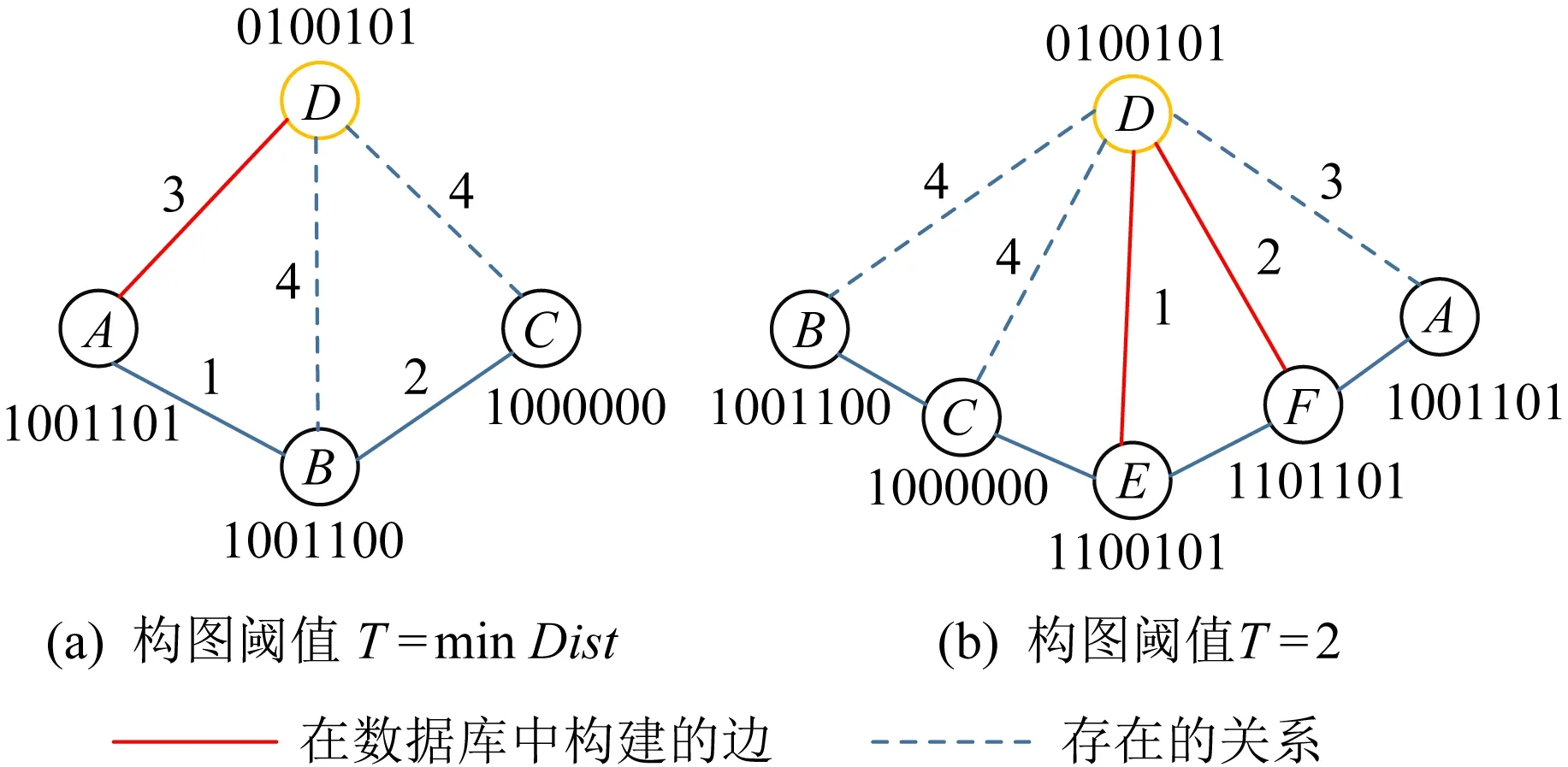
③ for (i=0;i ④optimizer←tf.train.AdamOptimizer(lr); ⑤lossD←(lossAdverIL+lossAdverTL+lossAdverL1+lossAdverL2)4.0; ⑥lossPairHash←mse_loss(multiply(S,θL2),lg(1.0+eθL2)); ⑦lossL=α×lossPairFeaL+γ× lossPairHshL+β×lossQuantL+ η×lossLabelL; ⑧lossI=α×lossPairFeaI+γ× lossPairHshI+β×lossQuantI+ η×lossLabelI+δ×lossDI; ⑨lossT=α×lossPairFeaT+γ× lossPairHshT+β×lossQuantT+ η×lossLabelT+δ×lossDT; ⑩ end for 其中,BatchSize=128,学习率lr=10-6,各层使用ReLU统一激活. 为了确定超参数α,γ,η,β,本文从语义筛选存储系统已有的文件中随机选择了5 000个数据点作为验证集,令α,γ,η,β从集合{0.000 1,0.001,0.01,0.1,1,2}中取值.经过实验,本文取α=γ=1,η=β=0.000 1时,训练的模型效果最好. 我们在图6中展示了语义Hash元数据的提取过程.HCMGM在经过多轮训练后,损失函数的结果趋于稳定.在模型收敛后,将图像和文本批量输入ImgNet和TxtNet,获取所有数据统一空间的跨模态语义Hash码. Fig. 6 The workflow of getting Hash code metadata of image and text files图6 图像文本文件Hash码获取示意图 Hash码提取的执行流程如算法2所示,首先加载跨模态图文数据集,将其分为多个处理批次,然后加载已经训练好的HCMGM及参数,图像和文本文件分别按序进入模型相对应的特征提取网络提取特征向量.二值化特征向量得到Hash码.最后将Hash码存入语义Hash码文件中.这里批处理大小BatchSize可以根据跨模态图文数据集的规模自主设定.这里生成的Hash码便可以作为文件的语义元数据,与文件占用的空间大小、文件的创建时间、文件的修改时间等元数据共同组成文件的元数据信息. 算法2.获取语义Hash码. 输入:图像文本跨模态数据集D,批处理大小BatchSize; 输出:语义Hash码文件H. ①H←hashCode.h5; ②BatchData=getData(D,BatchSize); ③model←训练好的HCMGM模型, hashCode←NULL; ④ fordatainBatchDatado ⑤BatchHashCode←model(BatchData). gpu(); ⑥HashCodes.append(BatchHashCode); ⑦ end for ⑧H.create_dataset(“hashcode”,data= hashCode).*将获得的Hash码写入语义Hash码文件H* SHG是用户完成在线筛选的基础.在相似内容的文件逻辑位置越近,语义查找效率越高的原则下,我们构建具有广泛连接的图谱结构,并利用深度遍历算法轻松实现相似数据的快速访问.考虑2个内容相似的图像或文本具有相似的Hash码,根据汉明距离组织Hash码,再建立Hash码与存储路径之间的映射,便能够迅速地实现内容筛选后的文件读取功能. 基于此,SHG设计如图7所示.我们计算图像和文本对应的语义Hash码间的汉明距离并存入基于阈值形成关系的CSV文件.另外,由语义Hash码和相应的存储路径生成节点的CSV文件.基于这2个文件,Neo4j完成节点上Hash码与文件信息存储.在此过程中,我们减少图谱中的节点连接和在线筛选的通信开销,详细内容如下. Fig. 7 The workflow of the construction of SHG图7 SHG构建示意图 4.4.1 构图阈值选择 我们规定:SHG中节点ID为跨模态语义Hash码;2个节点之间存在边则表明这2个节点所对应的Hash码之间存在语义相关性;边上的权值则表示2个Hash码之间的汉明距离. 对于存储系统中的N个文件(文本或图像),考虑文本和图像由于内容相似可能会共享相同的Hash码,本文将具有相同Hash码的节点合并为1个节点,假设图中的节点个数为M,显然M≤N,同时M也表示了不同Hash码的数量.这些Hash码之间的汉明距离代表链接每2个节点的边的权重,显然,边是无向的,因为语义相关性是相互的. 设Vx表示SHG中G的第x个节点,H(Vx)表示Vx的Hash码,对于任意i和j(0 Distij=H(Vi)⊕H(Vj). (15) 对于包含M个节点的G,在节点全连接情况下,边的最大数量是M×(M-1)2.在G中进行筛选时,时间复杂度是线性的,假设S是筛选出的节点数,E是深度遍历经过的边数,那么筛选的时间复杂度可以表示为O(|S|+|E|).显然,如果边的条数太多,会造成在线筛选过程的巨大延迟,同时如此庞大的节点关系也会增加存储开销.因此,本文设置阈值T来限制边数.Ti的选择基于2个原则:1)最小汉明距离必须保证G中没有孤立节点从而保证筛选半径内的有效查询,即存在召回结果;2)在相同精度的条件下要达到最佳性能. 在大量实验对比下,我们发现HCMGM在汉明半径小于等于2时的检索精度最高.这意味着在以边上权值小于等于2为原则构建的图上进行搜索能够获得最准确的结果,既保证了准确性也提高了构图与查询效率.令Tx表示第x个节点的汉明距离阈值.对于∀i∈(0,M],Ti可以按照如下方式选择: (16) 对于G中的节点,只有2个节点之间的汉明距离小于阈值的时候才连接并赋予连接边权重,从而减少图中的边数. 图8(a)展示了不同条件下的连边选择,节点A,B,C是G中已经存在的节点,节点D表示新上传的节点,计算节点D与节点A,B,C的汉明距离分别为3,4,4,最短的汉明距离大于2,所以本文将节点D的阈值取为3,节点D只与节点A相连,这是阈值选择的第1种情况.如图8(b)所示,节点A,B,C,E,F是SHG中已经构图完成的节点,节点D表示新上传的节点,分别计算节点D与节点A,B,C,E,F的汉明距离,结果是3,4,4,1,2,最短的汉明距离为1,所以本文将节点D的阈值取为2,连接权重小于等于2的节点,故节点D分别与节点E,F相连,这是阈值选择的第2种情况. Fig. 8 Threshold T of graph construction图8 构图阈值T选择示意图 4.4.2 图谱与存储系统通信优化 SwiftGraph[22]用于实现两端分离链接的Hash表来连接SHG和FSS,其中Hash表的键是文件的Hash码值,键值所对应的链表结构是Hash码作为语义元数据的文件标识,使用绝对路径表示.在语义查询过程中,第1步先将查询文件的Hash码发送到SHG中,通过深度遍历,返回符合查询条件的节点;第2步再将Hash码发送给两端分离的Hash表,得到符合查询条件的文件绝对路径;第3步通过存储系统返回查询结果.整个过程中,SHG、两端分离的Hash表和FSS之间必须建立通信.为了减少开销,本文提出将Hash表作为批量构图的辅助结构,利用Neo4j的属性将文件绝对路径直接存储在SHG中.在在线筛选阶段,SHG直接与FSS建立连接,返回相关文件,提高筛选效率.SHG与FSS之间的通信连接如图9所示: Fig. 9 The communication between SHG and FSS图9 SHG与FSS之间的通信连接 4.4.3 SHG构建执行流程 Neo4j支持批量导入数据,这里本文选择官方最快的neo4j-admin import,它只接受CSV文件导入,所以本文需要将构图的节点和节点关系分别存在2个CSV文件中.主要有以下4步: 1) 首先初始化节点文件N和关系文件R,然后根据Hash链表HL建立Hash码H和对应文件存储路径P的映射关系; 2) 将所有Hash码依次取出,并分别和对应的文件名建立联系; 3) 将每个Hash码节点依次与其他节点比较距离,根据阈值T建立节点关系,写入关系文件R; 4) 将Hash表HL中的该节点对应的所有存储路径写入文件路径,存入Hash码节点文件N. 得到这2个文件后,本文就可以利用Neo4j批量导入节点和关系构建Hash图谱,因neo4j-admin import的使用有3个前提条件:1)清空图数据库;2)关停Neo4j服务;3)节点ID唯一.构建过程如算法3所示: 算法3.批量导入节点和关系构建Hash图谱,getHashGraph(N,R). 输入:Hash码节点文件N,节点关系文件R; 输出:SHGG. ①G←停止服务,申请内存空间; ②G←输入节点N,关系集合R; ③ 服务开启. 为了直观展示图谱中的节点和关系,图10展示了通过浏览器查看的Neo4j信息.本文在浏览器中输入http:localhost:7474后的可视化界面.其中,每个节点有2个属性,hashCode是节点的唯一属性,filename则表示此Hash码对应的文件存储路径,当有多个文件时,路径之间用“;”间隔. Fig. 10 An example of a node property in Neo4j图10 节点属性示例 在线筛选时,用户提交筛选请求(包含筛选目标文件和筛选半径).HCMGM映射文件为相似性Hash码,Hash码在图谱中依据深度优先算法遍历图结构,以筛选半径确定内容相似的节点,并获取节点上文件存储的绝对路径,从而获取内容相关文件返回给用户.内容筛选流程如图11所示: Fig. 11 The workflow of content siftingprocess图11 内容筛选流程示意图 SHG构建流程的完成,表示离线处理结束.之后,用户将筛选目标(图像或文本)文件上传至SHG中提供的筛选接口,完成筛选读取.在此过程中,用户需要提供筛选半径,此参数需要预先配置,可修改. 文件上传后首先通过训练好的HCMGM获得Hash码,然后通过Neo4j内置的CQL检索图谱中逻辑相连的节点,通过深度遍历接口,下沉搜索到有关联关系的任意深度,进而筛选出用户可能需要的文件返回给用户.相似内容筛选执行流程如算法4所示: 算法4.内容筛选. 输入:SHGG,筛选所依据的图像或文本文件Fsifting,筛选半径R; 输出:符合条件的文件F1,F2,…,Fn. ①N←NULL,P←NULL;*列表N存储所有符合筛选条件的Hash节点,列表P存储所有符合筛选条件的文件路径* ②model←HCMGM;*这里的HCMGM是离线阶段训练好的模型* ③hashCodemodel(Fsifting).gpu();*生成筛选所依据的图像或文本文件Fsifting的Hash码* ④N←matchnode:hashCoder:relationships wherer.Dist ⑤P←N.filename; ⑥P1,P2,…,Pn←P.split(“;”); ⑦F1,F2,…,Fn←open((P1,P2,…,Pn),‘r’). 系统的测试环境由2台服务器搭载而成,Open-Stack Swift作为对象存储系统部署在2台服务器上,从而实现分布式地管理图像和文本的源文件,语义元数据管理系统只部署在1台服务器上,从而实现更迅速的语义查询操作.2台服务器的配置分别如表1和表2所示: Table 1 Metadata Management Server Configuration表1 元数据管理服务器配置 Table 2 Configuration for Object Storage System Deployment 系统基于Python开发,Hash算法部分通过深度学习框架TensorFlow完成.元数据图谱由Neo4j管理.Swift的版本2.16.1,Neo4j版本3.3.3,Python版本3.6.5,TensorFlow版本1.4.0. 图像-文本检索测试中使用跨模态数据集完成,包括使用MIRFlickr-25k和NUS-WIDE进行语义筛选准确率测试,使用MS-COCO进行语义筛选的性能测试和SHG的构建测试. 1) MIRFlickr-25K数据集[23].包含从Flickr网站收集的25 000张图像以及相关的文本描述.这些文字描述来自用户上传图像时添加的注释.这些图像及其对应的多个标签组成多个图像-文本对,本文实验挑选具有至少20个文本标签的数据对进行实验,据此,总共选择了20 015个数据点,并且在24个类别标签中,每个数据点都至少使用一个手动注释的标签.每个数据点的文本特征用1 386维词袋(BoW)向量表示,图像特征由512维GIST特征向量表示.本文随机采样2 000个数据点作为测试集进行查询操作,其余数据点作为检索集存储在Swift存储系统中,此外,本文在检索集中采样了10 000个数据点作为训练集完成测试. 2) NUS-WIDE数据集[24].包含269 648个Web图像和相关的文本标签.总共81种类别,剔除没有标签信息的数据后,本文选择了最常见的21类中的195 834个图像-文本对作为本文的数据集.每个数据点的文本特征表示为1 000维的词袋向量,而图像特征则表示为500维视觉袋向量.这里,本文随机采样2 000个数据点作为测试集,其余数据点作为检索集,并在检索集中采样了10 000个数据点作为训练集. 3) MS-COCO数据集[25].包含约118 287个训练图像,40 504个验证图像和40 775个测试图像的跨模态数据集.每个图像有80个类别中的一些标签信息,本文从验证集中随机选取了5 000张图像与其对应的标签构成了检索集,检索集中的每个数据项都由2种模态的图像-文本数据对构成,从而用于语义内容筛选的性能测试. 5.2.1 基准方法与评价指标 1) 基准方法 为了评估本文中HCMGM的检索效果,本文选取了目前已知的几种跨模态Hash算法与之进行比较,主要的基准方法如表3所示.为了和其他方法有一个比较公平的比较,我们使用ImageNet数据集[26]来训练ImgNet网络中VGG-19模型的参数. 2) 评价指标 为了评价检索结果的准确性,本文选择检索领域常用的评估标准PR(precision and recall)曲线[27].本文先引入查准率和召回率的概念.假设TP表示查询到的结果确实是内容相关的文件数,FP表示查询到的结果是内容无关的文件数,FN表示未检索到内容相关的文件数,TN表示未检索到内容无关的文件数.查准率和召回率的计算公式如下: (17) Table 3 The Main Benchmark Methods with Brief Introduction 查准率表示查询到的内容相关的文件数占所有查询结果的比例,召回率表示查询到的内容相关的文件数占所有内容相关文件的比例.PR曲线表示以召回率为横轴,查准率为纵轴,综合描述检测结果的准确性.因为PR曲线的2个指标都聚焦于TP,所以PR曲线和2个坐标轴之间的围成区域的面积可以综合地反映模型效果,面积越大,表示模型越好,反之亦然. 5.2.2 实验结果及分析 为比较跨模态检索效果,所有跨模态数据集需要进行图像检索文本和由文本检索图像2组检索实验.实验设置随机采样2 000个数据点作为测试集来进行查询操作,其余数据点作为检索集,根据返回同类图像(文本)的比例计算该查询的检索精度.本文分别在MIRFlickr-25K和NUS-WIDE数据集下进行实验,比较HCMGM与7种基准方法的PR曲线. 图12为MIRFlickr-25K数据集上8种算法在Hash码长度为32 b时的PR曲线.图12(a)表示以图像检索文本,图12(b)表示以文本检索图像.从对比结果可以看出,在相同召回率下,本文的算法比其他算法具有更高的准确率,同时在相同准确率的情况下,本文的算法能够召回更多内容相关的样本.通过PR曲线与2个坐标轴之间的面积比对,说明本文算法的性能优于其他基准方法,具备更好的内容检索优势.另外,对比图12(a)和图12(b)可以看出,图像检索文本性能略优于文本检索图像性能. Fig. 12 The PR curve on MIRFlickr-25K at 32 b图12 数据集MIRFlickr-25K上32位Hash码下的准确率-召回率曲线 Fig. 13 The PR curve on NUS-WIDE at 32 b图13 数据集NUS-WIDE上32位Hash码下的准确率-召回率曲线 同理,如图13(a)和图13(b),NUS-WIDE数据集上32 b Hash码PR性能所示,具有和MIRFlickr-25K上相同的结论.从PR曲线与2个坐标轴之间的面积也可以看出,NUS-WIDE数据集的面积明显小于MIRFlickr-25K数据集,说明数据集中类别数量的增加会导致算法准确率的下降. 值得注意的是,本文的算法是在有监督的条件下训练的,显然相较于无监督的算法准确率要高出很多,因为基准不同,本文没有列出比较,但是在现实应用中,标签的得到具有较高的成本,因此后续研究应建立在无监督的Hash算法之上. 5.3.1 筛选半径R的性能测试 R表示语义SHG中的筛选半径,在CITCSS中,召回率会受到筛选半径R的影响.筛选半径越大,召回率越高.但是随着R的增大,筛选时间也会增加.因此需要找到平衡点下的R,使跨模态图文数据内容筛选存储系统在满足一定召回率的同时,具有令用户满意的筛选时间,使系统具备较高的性能. 实验选用公开的跨模态数据集MS-COCO,筛选半径R从1~10逐渐增加,每次使用10个不同的图像和10个不同的文本作为筛选条件独立地测试不同R下的性能,以10次测试的平均值作为结果进行展示.实验展示以筛选半径R为横坐标,分别以召回率和筛选时间为纵坐标,测试当改变R时对召回率和筛选时间的影响. Fig. 14 The relationship of recall rate, sifting time and sifting radius on MS-COCO图14 数据集MS-COCO下的召回率、筛选时间与筛选半径R的关系 实验结果如图14所示,召回率和筛选时间都随着筛选半径R的增大而增加,由图14(a)可以看出,在MS-COCO数据集中,筛选半径R=6时,召回率就已经高达98.56%,随后随着筛选半径的增加,召回率的增长小于0.01个百分点,可以视为无明显涨幅,但是在图14(b)中,在筛选半径R>6时,筛选时间迅速攀升,在筛选半径R>8时,筛选时间大于10 s,实际中会给用户造成不佳的体验. 5.3.2 与传统存储系统对比测试 为了从数据层面直观量化CITCSS的性能优势,实验对比了CITCSS与传统存储系统在用户提交相同文件后以内容语义相似筛选图文文件进行读取所需要时间.由于筛选半径R的限制,CITCSS可能不能筛选出所有相关的图文文件,但可以保证召回率在98%以上.我们认为这一结果接近筛选出所有的图像和文本文件.注意,实验中用于实验的跨模态数据集中的所有数据已经提前存储在需要对比的系统中,CITCSS中已经批量构建好所有数据的SHG. 本节实验依然选择MS-COCO数据集,根据5.3.1节的结论,在MS-COCO数据集上,当筛选半径选R=6时,CITCSS在此数据集上可以达到最好的性能,因此实验选取筛选半径R=6进行实验.为了体现实验的可靠性,实验每次使用10张不同的图像和10个不同的文本文件作为筛选条件,获取从客户端请求到数据下载的总读取时间,以20次筛选的平均值作为实际结果.为了获得可视化差距明显的效果,我们重复执行100 000次上述操作后,给出积累下的时间比对. 实验结果如表4所示.我们选取MS-COCO数据集上人、车、天空3个类别作为筛选目标.从结果看,对于没有语义元数据的存储系统Spyglass和SmartStore,无论用户筛选任何类别的数据,都需要读取所有数据再进行筛选.表4仅仅记录了这2个存储系统的读取时间.出于公平考虑,本文假设一个正常的成年人阅读一个文件并判断其内容是否满足需要的平均时间是0.01 s,MS-COCO数据集约有100 000个数据,故筛选时间约为1 000 s.与此同时,CITCSS仅需7~8 s完成筛选和读取工作.由表4可知,当筛选类别为人的数据时,CITCSS的筛选时间分别比Spyglass系统和SmartStore系统降低99.07%和99.74%;筛选类别为天空时,分别降低99.11%和99.75%;筛选类别为车时,分别降低99.19%和99.77%.综上,CITCSS在召回率超过98%的前提下将读取延迟降低99.07%~99.77%,证明CITCSS在读操作上具有优越性. Table 4 Comparison of Sifting Time with Different Systems on MS-COCO 以上实验结果可表明,CITCSS在保证召回率的前提下,筛选出了和需求相关度高的数据,从而保证对分析数据读取的可靠性与准确性.同时,因为筛选机制的引入,相比传统系统只读出了相关数据,进而减少了读取时间. 由于相比传统存储系统增加了SHG,在构图的过程中不可避免地造成多余的时间开销和存储开销,我们对这部分开销进行了实验验证.时间开销主要来自于图像和文本文件的语义Hash码生成、Hash码间的汉明距离计算,以及利用Neo4j导入节点和关系的总时间.存储开销表现为Neo4j构图完成后生成的graph.db文件所占用的空间.因为构图过程中生成的节点文件nodes.csv和关系的文件relationships.csv作为辅助文件在构图完成后会即可删除,因此本部分实验中只统计最终生成的图谱文件大小下的时间开销和存储开销. 5.4.1 构图时间开销 本小节在表5中展示了3个跨模态数据集MIRFlickr-25K,NUS-WIDE,MS-COCO上各自构建SHG的时间开销. Table 5 Time Overhead of SHG Construction表5 SHG构建时间开销 s 综合3个数据集来看,每批次平均构图时间达到11 h 45 min 3 s,由于整个过程是离线完成的,因此不会影响用户体验.相较于用户在线筛选过程中获得的效率,我们认为离线工作耗费的时间是值得的.针对系统中已存储的文件,批量构图的过程只发生一次,对于动态上传的单个文件,无需重复构图,而采用在原有图谱中插入节点关系的操作即可.而单个文件生成Hash码并插入SHG所需要的平均时间仅为0.32 s,我们认为这是可以接受的. 5.4.2 构图存储开销 本节在3个跨模态数据集MIRFlickr-25K,NUS-WIDE,MS-COCO上各自构建SHG,测试所占用的存储空间,性能如表6所示: Table 6 The Storage Space Overhead of SHG Construction表6 SHG构建存储开销 MB 从表6中可以看出,针对MIRFlickr-25K,NUS-WIDE,MS-COCO,构建图谱增加的存储空间在900 KB~11 MB之间,相比包含图像和文本的数据集本身GB甚至TB的数量级,可以忽略不计.在最高MB级的存储空间开销下,图谱在语义筛选阶段产生的效率却能够降低读取带宽百倍以上.我们认为这样的性价比是值得推崇的. 为进一步了解引入筛选机制后系统面对压力的性能,我们以腾讯QQ相册的图像(平均大小为65.8 KB)为输入,测试了存入100万张图像后图谱的在线查询时间和文件系统的读写性能.数据显示,图谱以批量策略存入后,每条数据的平均查询(根据Hash码查询节点)时间为521.337 283 ms.以Swift为基础的文件系统读带宽为8.09 KBps,写带宽为7.58 KBps.这些性能不会对用户的在线行为造成困扰. 基于以上实验,我们认为CITCSS在不影响原有存储性能的前提下,提升了传统存储系统对于应用分析的支持,通过引入自监督对抗的跨模态Hash算法,并使用图谱结构管理内容语义Hash元数据,使用筛选机制减轻了大规模跨模态图文数据分析时从磁盘读取所有数据造成的延迟. 本文针对服务于分析需求的云端存储系统,提出了一种跨模态内容筛选存储的机制.包括基于Hash元数据生成算法模型获取图像文本统一语义表征的Hash码,利用Neo4j图结构构建SHG和在对象存储系统Swift中在线筛选相似内容文件. 本文优化了SHG和FSS之间的通信开销.通过修改Neo4j节点属性,将Hash码与文件存储路径之间的映射关系融入Neo4j的节点中,以Hash码为键,属性附带文件存储路径的方式对节点进行改进,进一步减少读取过程中的时间开销. 在跨模态数据集测试中,我们通过图像和文本相互检索的准确率评估我们的算法与现有算法的优势,证明了我们嵌入存储系统中的HCMGM的可靠性与稳定性.通过模拟语义内容筛选过程,观察改变筛选半径和与传统存储系统性能比较,证明我们设计的存储机制在面对分析需求时不仅具备压倒性的读延迟优势,并且不会带来严重的数据丢失.与此同时,我们设计的机制具有可以被接受的时间开销和存储开销.实验表明,与传统的语义存储系统相比,CITCSS在召回率超过98%的性能下,读取延迟相对降低了99.07%~99.77%.4.3 语义Hash元数据提取
4.4 SHG构建

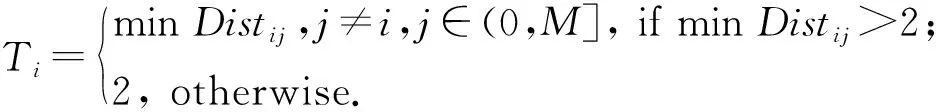


4.5 内容筛选流程

5 性能测试与结果分析
5.1 测试环境与数据集


5.2 语义内容筛选的准确率测试


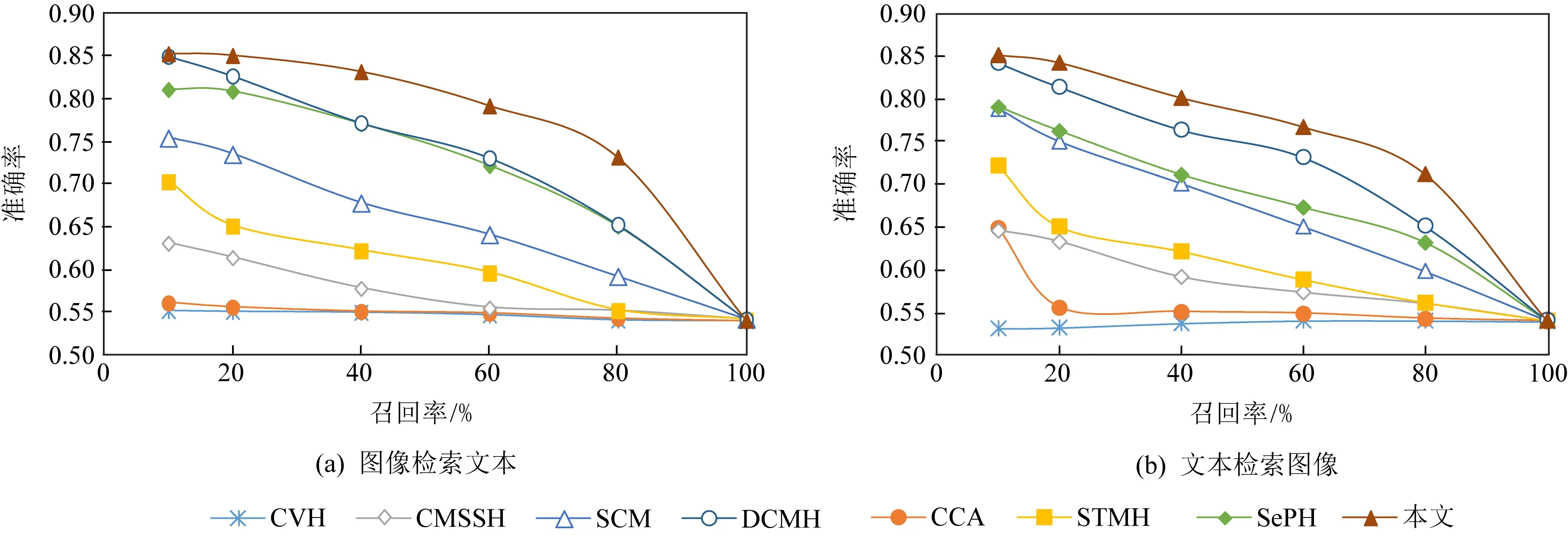
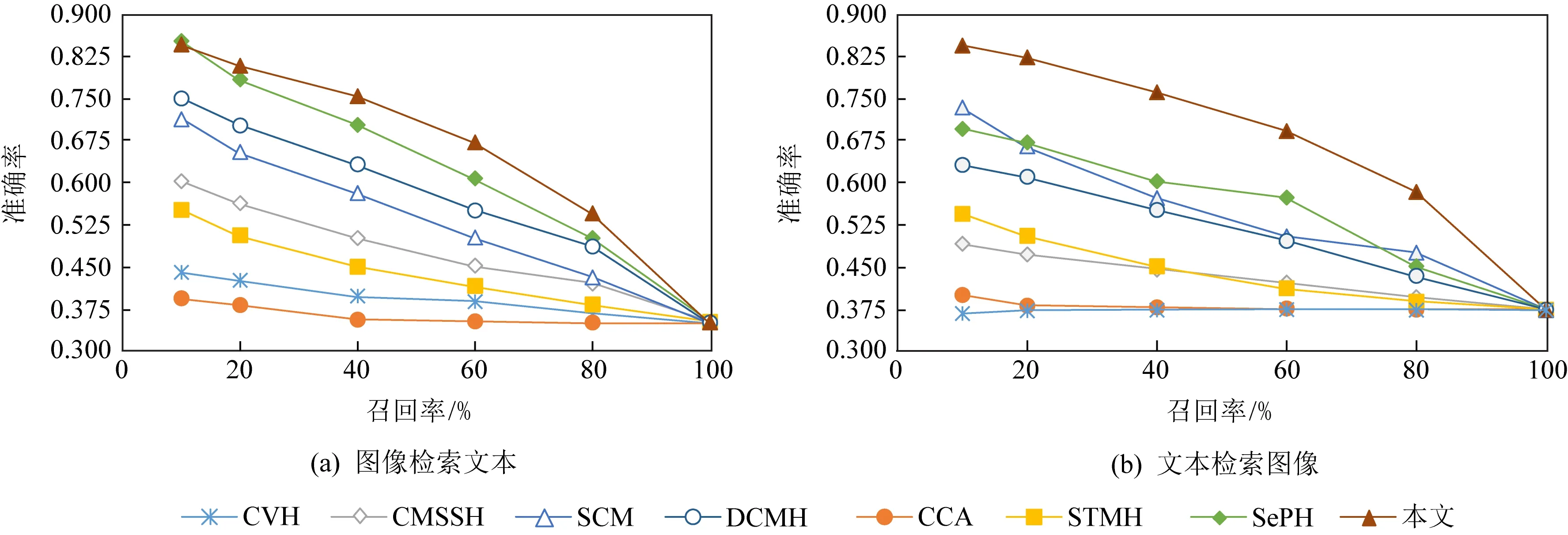
5.3 语义内容筛选的性能测试


5.4 SHG构建及压力测试


5.5 图数据库及文件系统压力测试
6 总 结
