显著性物体检测研究综述
2021-02-03蒋峰岭
蒋峰岭, 孔 斌, 钱 晶, 王 灿, 杨 静
(1.中国科学院合肥物质科学研究院 智能机械研究所,安徽 合肥 230031; 2.中国科学技术大学,安徽 合肥 230026; 3.合肥师范学院,安徽 合肥 230061; 4.鹏城实验室,广东 深圳 518053; 5.安徽省智能驾驶技术及应用工程实验室,安徽 合肥 230088)
人类的视觉系统具有极强的数据处理能力,能够在复杂场景中快速地选择比较醒目的区域或者是感兴趣的区域,并且只对选择出的区域进行处理而忽略其他区域中的信息。这种视觉信息处理机制被人们称之为“选择性视觉注意机制”或者“视觉注意力机制”,又常常简称“注意机制”。由于选择性视觉注意机制能够快速地锁定视觉场景中的感兴趣区域或者目标区域,从而极大地减少数据的处理量、加快信息处理的速度,这对于计算资源有限以及实时性要求较高的各种机器视觉应用来说具有非常大的吸引力,因而受到学术界的广泛关注。将人类这种选择性视觉注意机制引入到计算机视觉的信息处理中,近些年来已经成为计算机视觉领域的研究热点,并在各种视觉计算任务中得到了快速的发展,如目标检测[1]、目标跟踪[2]和图像理解[3]等。
人工神经网络被认为是一种以简化的方式模仿人类大脑并行计算机制的数学模型,人们同样试图建立一些计算模型来模仿人类视觉系统注意机制,以实现选择性地专注于一些与视觉任务目的相关的事物而忽略其他事物,从而可以利用有限的计算资源来快速完成视觉场景的处理和理解等过程。
早在1980年,Treisman等[4]就从认知心理学与神经科学方面对人类注意力机制进行了研究,提出了显著特征整合理论。Koch等于1985年发表了被认为是视觉注意力领域的奠基文章[5],并于1987年发表了该文的扩展版[6]。到1998年,Itti等[7]发表了第一个基于显著度的视觉注意计算模型,使用多种特征的融合获得最终的显著图,视觉注意力机制模型正式引入到计算机视觉领域。之后,视觉注意模型逐渐受到研究者的关注,并运用于视觉任务计算的方方面面。在今年前不久召开的IEEE国际计算机视觉与模式识别会议(CVPR)和全国图象图形学学术会议(NCIG)中,都各有超过15篇论文/报告的主题或内容涉及注意力机制或显著性检测。
对视觉注意力的研究主要有两个分支——关注点检测(Fixation Prediction)和显著物体检测(Salient Object Detection)。关注点检测可以应用在广告和人类行为研究等领域,显著物体检测可广泛应用于各种视觉任务的预处理过程(详见第4.1节)。用于这两个分支研究的数据集都需要人为地标注真值。关注点的真值需要利用专门设备——眼动仪对实验者的注视落点(如图1(b)中的白色点)进行标注,标注通常侧重于物体的某块区域或某些像素值;而显著物体的真值则是根据人眼主观感知通过手工标注,一般标注整个显著物体的像素区域,并表示为二值图片(如图2(b)所示),通常值为1的白色部分表示显著物体区域,值为0的黑色部分表示背景。人眼关注点检测示意图如图1所示,显著性物体检测示意图如图2所示。在本综述中,主要关注的是显著物体检测。

图1 人眼关注点检测示意图

图2 显著性物体检测示意图
目前在视觉注意力和显著物体检测方面已有一些较长的综述文献。其中,文献[8]主要介绍显著性检测的发展历程、模型等,从传统方法到深度学习方法对显著性检测进行了总结归纳;文献[9]侧重于介绍深度学习时代的显著性检测模型,并对其进行分析和讨论;文献[10]分别从人眼关注点检测和显著物体检测两个方面综述了视觉注意力检测的最新研究进展;文献[11]则侧重于对视频中显著目标检测的相关研究成果的介绍;另外,文献[12]主要对视觉注意力机制在相关领域的应用进行了综述。还有几篇中文综述,因其篇幅很短、参考价值较低,在此不予提及。
与上述综述文献相比,本文首先简单叙述视觉注意力研究的发展历程,然后主要介绍显著性物体检测的各种方法,包括传统的方法和基于深度学习的方法,并根据不同的算法特点和网络结构对这两大类的方法进行了进一步的分类和小结,同时从不同角度对现有的显著性物体检测的数据集进行了整理和列表、对评测算法效果的方法和指标作了详细的介绍,另外还探讨了显著性物体检测在不同领域的应用,最后对显著性物体检测研究的发展趋势和方向进行了分析和总结展望。
1 显著性物体检测方法
显著性物体检测可以分为静态物体检测和动态物体检测,静态物体检测主要是针对一幅图像中的显著物体进行检测,而动态显著物体检测主要是对视频场景中的显著物体进行检测。静态图像和动态视频中物体显著性的区别有:① 静态图像中的显著性物体主要表现在显著目标与环境中其他目标在特征上和语义上的对比,而视频中运动的物体一般被定义为显著物体,并且人眼会随着视频中物体的运动关注和跟踪该物体,或者随着物体的消失和出现而不断改变显著物体;② 由于视频播放的过程是一个连续动态的过程,因此在观看视频时人眼的注意力在每一帧的停留时间很短,新的物体出现更能吸引人的注意,另外视频显著性目标的能量相对较为集中,当没有显著物体时,人的关注点往往会集中在视频画面的中央。一般来说,对于视频中的运动物体,其显著性检测依赖于每一帧图像(如图3所示),当存在物体消失和出现时,其显著性检测也依赖于前后帧图像的对比。因此,图像的显著性物体检测是基础,所以本文对显著性物体检测方法的综述主要集中在静态图像的显著性物体检测上。

图3 视频显著性检测示意图(每列图像的上图为视频中的帧、
近些年来,一些高性能的显著性物体检测方法相继被提出,总的来说可分为传统的显著性物体检测方法和基于深度学习的显著性物体检测方法。传统方法属于自底向上的检测方法,主要利用低级特征,如颜色、纹理、亮度等信息,通过颜色对比、图像周边和中心的差异等获得显著图。基于深度学习的方法属于自顶向下的检测方法,主要利用任务先验和高级特征,可以被认为是任务驱动的检测方法,如在驾驶场景下司机更关注于前方的信号灯、标识牌、前车尾灯等,通过这些目标的先验特征,进行显著目标的检测。下面分别对这两类方法进行介绍。
1.1 传统的显著性物体检测方法
自从Itti等[7]将视觉注意力机制模型引入到计算机视觉领域,其后研究的显著度检测或显著图计算主要针对图像中具有各种显著特征的区域而不是具有明确语义的整个物体。对于具备显著性的整个物体的检测研究一般被认为是从2007年开始兴起的。文献[13]将视觉注意力检测从特征区域级别发展为物体级别的显著度计算与检测研究,即在检测出显著区域的同时提取该区域的显著物体的轮廓,并给出了第一个显著性物体数据集MSRA-B,以及显著性物体检测的相关评价标准,如查准率、查全率。随后,文献[14]使用了基于频域的方法来进行显著性物体检测,并给出了两种新的评价指标,即PR曲线(查准率对比查全率曲线)和F测度(一般又简称F值)。这两篇文献对后续的显著性物体检测研究具有重要的影响。对于传统的显著性物体检测方法,文献[8]等都进行了分类。根据这些方法在计算过程中的不同特点,将显著性物体检测方法划分为:基于全局和基于局部对比的计算方法、基于频域的计算方法、基于稀疏理论的计算方法、基于图的计算方法和基于背景及前景先验的计算方法等。当然,有一些算法不能笼统地归属某一种方法,它们可能是结合多种方法来使用的,所以在本文的归类中可能会出现同一文献在多个分类中出现的情况。
1.1.1 基于全局和基于局部对比的计算方法
全局信息和局部信息在显著性物体检测当中分别起到不同的作用。对基于全局对比和基于局部对比的计算方法的划分,主要考虑视觉系统是先加工图形的整体性质,还是加工其局部的性质。陈霖等在文献[15]中,对图片中的整体性质和局部性质的关系、视觉系统感知图片中的全局信息和局部信息的顺序,进行了实验和分析,并提出了视知觉“大范围拓扑优先”理论。同样,程明明等[16]提出基于直方图对比度的方法(Histogram Contrast,HC)和基于区域对比度的方法(Region Contrast,RC)来计算显著性目标,这两个方法都归类为基于全局对比的方法,其中RC是在HC的基础上改进的算法。HC方法是通过像素点之间的颜色差异来得到像素点的显著值。RC方法将像素的空间关系和颜色差异结合到一起,首先将图像划分为若干个区域块,然后计算区域块之间的颜色对比度,再将区域之间的对比度加权和作为该区域的显著值。
基于全局对比和基于局部对比的方法有很多,除了文献[16],其他主要的方法归纳在表1中。

表1 基于全局和基于局部对比的方法
1.1.2 基于频域的计算方法
基于频域的计算方法,主要是根据信息论的观点来对图像进行处理,该观点认为图像由冗余和突出两部分组成,那么找出图像当中的冗余部分,将其除去即为突出部分,也就是对应的显著部分。Hou等[26]提出了频域残差法(Spectral Residual)来计算图像的显著部分。该文认为图像的统计特性具有尺度变换不变性,首先将原图进行傅里叶变换,得到振幅谱和相位谱;然后根据得到的振幅谱,求其对数振幅谱;将对数振幅谱减去对数振幅谱均值滤波后的结果,即为剩余谱;最后利用傅里叶反变换将相位谱和剩余谱求得的自然指数转换到空间域,再进行高斯滤波,即得到最终的显著图。但是该方法得到的结果仅仅是对图像中显著物体部分像素进行高亮处理,没有检测到整个显著物体。在Hou等的基础上,复旦大学Guo等[27-28]提出相位谱方法。在文献[14]中,作者从图像的频率域角度进行图像中的显著性物体检测,即通过滤波器将图像分为高频域和低频域,然后通过高斯平滑和均值的计算得到了显著图,随后作者在之前的基础上,考虑到显著物体的边缘与物体中心的频率特征不同,又提出了改进的频域方法[29],从而提升了显著性物体的检测性能。
1.1.3 基于稀疏理论的计算方法
基于稀疏理论的计算方法,主要是将样本转换为稀疏表示的形式,达到简化模型、降低数据维度的目的。根据人眼观察的特性,人们在观察场景中的目标时,往往更关注于稀疏区域的物体,而获得的这部分稀疏区域可以用来作为显著性物体检测的结果。Shen等[30]提出了使用稀疏理论进行显著性物体检测,该方法通过分割和特征变换,将图像表示成一个低秩矩阵和稀疏噪声的组合,再融合了底层信息和高层先验知识实现显著区域的优化。该算法存在的主要问题是计算量大、运行速度慢、实验效果一般。随后,Li等[22]在稀疏理论的基础上,利用图像的边界作为提取背景线索的模板,在得到背景模板的基础上,通过构造稠密和稀疏重建误差来进行显著性检测,最后利用多尺度重构得到显著性结果。
这类基于稀疏理论的计算方法为显著性物体检测开辟了一个新的解决问题的思路,也获得了较好的实验效果,后续还有学者在此基础上进行了改进和优化,如文献[31]等。
1.1.4 基于图模型的计算方法
自从简单线性迭代聚类算法[32](Simple Linear Iterative Cluster,SLIC)在图像分割中得到广泛应用之后,出现了越来越多的基于图模型的显著性物体检测方法。基于图模型的计算方法一般是通过SLIC算法将图像的像素转换为超像素(Superpixel),以各个超像素作为图模型的节点、超像素之间的关系作为模型的边,构建好图模型后,利用图的相关知识来解析图像得到显著图。Jiang等[20]将图像转换为图模型,利用马尔可夫链(Markov Chain,MC)的吸收特性来计算显著图,即将图像四周边界的节点作为吸收节点,然后计算转移节点到吸收节点的平均吸收时间,吸收时间短的被认为是背景的可能性大,而吸收时间长的被认为是前景的可能性大,根据这种原理最终得到显著图。Yang等[33]采用基于图的流形排序(Manifold Ranking,MR)方法来计算显著性,首先构造图模型,然后使用图像四边界的节点作为背景种子点,得到4个边界的显著值并进行融合,作为第一阶段的显著图,然后对第一阶段的显著图进行阈值分割,从而选出种子节点,再通过优化计算得到最终的显著结果。Zhu等[18]利用边界连通率来度量节点与边界之间的关系,并提出一个统一的优化框架来优化结果,得到最终的显著图。
这类基于图模型的计算方法都取得了较好的性能,类似的方法如文献[34]等。
1.1.5 基于背景和前景先验的计算方法
先验信息在显著性物体检测中非常重要,如颜色先验[30]、中心先验[35]、形状先验[36]等。在这里,主要介绍基于背景和前景先验的显著物体检测方法。
很多基于背景先验的计算方法都将图像四周的边界作为背景先验。Wei等[37]提出一种基于背景先验的显著性检测方法,认为背景区域通常比显著的物体更加接近边界,这样就将计算显著图的问题转化为计算到边界的距离长短的问题。其他采纳类似思想的方法有:Jiang等[20]在马尔可夫链的基础上,将四边界作为吸收节点;Yang等[33]提出的流形排序的显著性检测算法,将图像四边界作为背景节点。基于前景先验的计算方法,主要通过假设前景先验信息进行显著物体检测。Zhu等[38]提出了一种利用Harris角的凸包来近似定位前景物体的方法,将凸包先验图和凸包中心偏置值相结合为初始显著图,然后对其进行优化得到最终结果。
还有一些将背景先验和前景先验相结合的方法,如文献[39]等。
1.1.6 小结
总的来说,传统方法使用空域或频域中大量的特征对比,或者利用先验信息等进行图像显著性检测,其针对性较强,一般来说只适用于主体明确、物体颜色及结构较为单调的场景。由于泛化能力差、无法描述和适应复杂的场景和对象结构,导致此类显著性检测方法的研究陷入瓶颈。但因不需要进行大规模的样本训练,并且具有较快的计算速度,可满足实时性需求,此类方法还是具有一定的吸引力。
1.2 基于深度学习的显著物体检测方法
随着计算机计算能力的提升、深度学习相关模型在众多视觉任务上的成功应用,基于深度学习的显著性物体检测也逐渐成为当前该领域的主流方法。
基于深度学习的显著性物体检测方法,需要对模型进行训练,因此需要大量的样本图片及其对应的标签。虽然在人工标注时耗费大量的时间,以及在网络训练和调参时也花费一定的时间,但是一旦将网络模型训练好,可以适用于较为复杂场景下的显著性物体检测,其性能明显优于传统的显著性物体检测方法。目前,大多数的基于深度学习的显著性物体检测方法都是采取全监督的方式,即需要大量的样本进行训练;按照其网络结构,一般可以将这些方法分为基于传统卷积神经网络的方法和基于完全卷积神经网络的方法。
1.2.1 基于传统卷积神经网络的方法
由于传统的卷积神经网络应用于目标检测和图像分类等视觉任务时展现了卓越的性能,它也被用来进行显著性物体检测。在这类方法的网络训练中,一般将图像块对照标签,其包含的显著区域阈值大于某个指定值的被认为是正样本,反之为负样本。文献[40]中,作者提出了一种融合局部估计和全局搜索的显著性检测方法。该方法先训练一个深度神经网络DNN-L来检测局部显著性,确定每个像素的显著度值、获得局部信息中对象边界等细节信息,但没有突出整个对象;另外再结合局部显著度值、对象候选框和颜色对比度进行特征提取,训练另一个深度神经网络DNN-G,根据全局特征预测每个目标区域的显著性得分;最后将两个网络的结果加权得到最终的显著图。Li等[41]提出了一种多尺度的卷积神经网络检测模型,将图片分为3个尺度,利用3个卷积网络模型进行特征提取,然后对特征进行融合,最后进行显著区域的检测,并达到了超过传统显著性物体检测的性能。Zhao等[42]则是利用上下文信息,通过上采样和下采样,构建两个卷积神经网络模型,然后将通过网络得到的显著值进行展平融合获得最终的显著图。He等[43]提出SuperCNN来进行显著性物体检测,将输入的图片划分为3个超像素块,然后分别生成颜色类别和颜色分布的特征向量,再进行卷积神经网络的训练,最后将得到的多尺度显著图进行融合获得最终的结果。其他的方法还有Chen等[44]提出的渐进式表示学习的深度计算模型等。
通过以上介绍可以看出,传统的卷积神经网络模型的显著性物体检测要将图像块的区域大小调整到固定的尺寸,或进行多尺度的处理,然后进行卷积神经网络的特征提取,最后进行融合,获得每个区域的显著值。从模型结构可以看出,卷积神经网络最后的全连接层丢失了空间信息,从而影响了分割显著物体结果的性能。
1.2.2 基于完全卷积神经网络的方法
自从基于完全卷积神经网络(Fully Convolutional Network,FCN)的语义分割模型[45]被提出,因其可以克服传统卷积神经网络模型的缺陷,具有空间保存的功能,被广泛应用于显著性物体检测当中。FCN模型是端到端的模型,可以输入任意尺度的图像,并且是像素级别的检测,很好地保留了空间特性。自FCN模型被提出,出现了很多基于FCN模型的显著性物体检测方法,而这些检测方法中大多使用了VGGNet[46]或ResNet[47]这两种骨干网络架构。下面主要基于这两种骨干网络架构,进行基于完全卷积神经网络显著性检测方法的介绍。
VGGNet网络都使用了3×3的卷积核和2×2的池化层,训练时间相对较少,文献中有各种各样具体的VGGNet架构,主要体现在有不同的网络深度,如VGG16,VGG19等。Liu等[48]提出了一个端到端的显著性物体检测网络DHSNet,首先从全局结构信息得到一个粗略的显著图,然后再用一个层次结构的循环神经网络HRCNN,通过整合局部上下文信息,分层逐步地细化得到最终的显著图。在文献[49]中,作者针对高分辨率图像进行显著性物体检测,在建立高分辨率显著物体数据库的同时,提出融合全局语义信息和局部高分辨率信息进行显著性物体的检测,在下采样的过程中,利用全局语义网络提取全局语义信息;然后在此结果上,利用局部细化网络针对一些局部区域进行检测,产生高分辨率的预测;最后利用全局和局部融合的网络进一步增强空间表现力,得出最终的检测结果。文献[50]中,作者提出一个多尺度的注意反馈模型,利用边界增强损失函数预测边界轮廓更清晰的显著性物体。在文献[51]中,同样为了解决基于FCN的网络对显著物体轮廓细节检测不精确的问题,作者提出了利用显著性物体前景轮廓和边界等信息进行显著性物体检测,构建了一个相互学习模块,在前3个VGG-based模块下,利用相互学习模块和边界模型得到3个特征,然后利用另外3个VGG-based模块和前景轮廓、显著物体在相互学习模块的作用下得到2个特征,最后将这些特征级联起来,得到最终的显著结果。
虽然基于VGGNet的显著性物体检测方法大多取得了不错的性能,并且随着其模型深度的增加,往往能提高模型的检测精度,但造成了梯度消失的现象,导致了模型训练误差的提高。相比较于VGGNet,ResNet架构具有更深的卷积层,如ResNet50,ResNet101,因ResNet使用了短连接(Shortcut Connection),不仅加快了模型的训练速度、提高了训练效果,而且当模型的深度加深时,这个简单的结构能够很好地解决退化问题。因此ResNet的提出在图像检测上具有重要的意义,近些年来也被广泛应用在显著性物体检测当中。文献[52]中,作者提出了一个自顶向下和自下而上迭代和协作的显著性物体检测模型。自顶向下的过程用于从粗到细的预测,高层信息逐渐利用底层信息获取到精细的检测结果,自下而上的过程通过逐渐使用上层语义上更丰富的功能来推断出高级但粗略的显著性特征;这两个过程是交替执行的,其中自下而上的过程使用从自顶向下的过程获得的细粒度显著性来产生增强的显著性检测结果,而自顶向下的过程又进一步受益于改进的高层的显著性信息。针对显著性物体的内部一致性和边界清晰度,文献[53]提出了一种图像连续扩展的边界感知网络模型,该模型通过一个边界定位过程来增强边界特性的提取,而物体内部的特征通过一个复杂的内部感知过程获得,同时针对物体内部和边界区域,提出一个过渡补偿模块进行特征提取,最后融合这些信息,获得最终的显著图。文献[54]中,作者针对现有模型的缺陷,提出了一个新的显著性物体检测模型。该模型将先验信息转换到一个嵌入空间中,获得可选择的注意特征,并获得显著物体的轮廓。具体地说,作者先通过网络模型获得一个粗略的预测图,然后利用训练的特征嵌入网络获得显著目标,并抑制非显著区域的像素,最后通过深浅层递归特征集成网络优化最终的显著结果。
1.2.3 小结
总的说来,虽然基于完全卷积神经网络的显著性检测方法相比传统卷积神经网络的显著性检测方法能更好地保存空间信息,但经过卷积、下采样和上采样后,最终的特征图丧失了显著物体的一些细节,在一定程度上影响了检测的精度。因此,在此基础上,基于复杂的特征融合网络结构被提出,如将底层特征和高层特征进行连接,获得更加丰富的语义信息;在文献[55]中,作者加入了注意力机制,来进行更加精确的显著目标检测,从而克服之前的网络模型的缺点,提高模型的检测精度。
2 显著性物体检测数据集
显著性物体检测近年来得到快速发展的重要原因是其具有很多公开数据集,有系统的评价标准。参考了其他综述文献中的形式,对这些数据集的信息进行了搜集整理,详细列表如表2所示。表2中主要列举了数据集的名称、容量,数据集中物体的属性、特点,以及相关文献和发表时间等信息。

表2 显著物体检测数据集
在这里主要列举了几个广泛应用的显著性物体检测数据集,这些数据集中的图片质量都比较清晰,其中数据集MSRA-10K[13,16],DUT-OMRON[33],HKU-IS[41],ECSSD[61],DUTS[62]和SOC[64]被广泛应用于深度显著性物体检测模型的训练。图4展示了这6个常用数据集的图片和对应的真值。下面对其进行介绍。
Liu等在文献[13]中公开了第一个用于显著物体检测的数据集MSRA-B,Cheng等[16]在其基础上,将原来的只有5000张标注物体边界框的图像的数据集,扩展成为有10K张标注显著物体像素级别标注的数据集MSRA-10K。如图4(a)所示,该数据集中的图片目标清晰,多为大目标,并且具有一个目标物体的图片居多,被研究者广泛使用。

图4 6种常见的数据集中的图片和真值示例图
DUT-OMRON是由Yang等[33]在2013年建立的,该数据集包含了5168张图像,每张图像中有一个或者多个目标(见图4(b)),且目标背景复杂,具有一定的相似性。该数据集不仅包含显著物体检测的像素级别的真值,还提供了人眼关注点的真值和物体标注框的真值。
HKU-IS是Li等[41]于2015年建立的,该数据集包含了4447张图像,具有多个目标,并且每个目标具有分散性,如图4(c)所示,背景和目标具有相似性,给检测带来了一定的难度,具有很大的挑战性。
ECSSD是Shi等[61]于2015年在CSSD数据集[58]的基础上建立的,将原来200张的数据集扩展到1000张,该数据集中的图片具有复杂的背景结构(见图4(d)),具有一个或多个目标,具有一定的检测难度,也被广泛使用于各种方法的研究中。
DUTS是Wang等[62]于2017年建立的,该数据集包含10553张训练数据和5019张测试数据,总共15572张图片,适用于基于深度学习的检测方法,需要大量标签的数据。该数据集的图片中具有多个目标,并且目标与背景相似度高(见图4(e)),被广泛应用于基于深度学习的方法当中。
SOC是Fan等[64]于2018年建立的,该数据集有6000张图片,其中包含3000张具有显著目标的图片和3000张没有显著目标的图片。SOC全称为Salient Objects in Clutter,译为杂乱环境下的显着对象,该数据集具有复杂背景和非显著目标(如图4(f)前两张图片所示,因其没有显著目标,其真值图片是一张全黑色的图片)。SOC建立的目的是面向深度学习的方法,作者将该数据集分成了3600张训练子集、1200张测试子集和1200张验证子集。
3 显著性物体检测评价标准
对显著性物体检测的算法效果进行评价的相关方法,主要是计算其算法得到的显著图像与标注的真值图像之间的误差,其公式表示为
(1)
式中,i为1,2,…,n张图片中的任意一张图片;Li为任意一张图片的真值,即Li的取值为0或1;f(Ii)为对于任意输入的图片Ii,通过相关显著性物体检测的算法f(·)得到的显著图像的值,这里f(Ii)∈[0,1],0表示背景,1表示显著值;E为显著性物体检测的评价标准。而算法优化的目标是使得非显著物体所在区域的像素值趋向于0,显著物体所在区域的像素值趋向于1。
为了进行不同方法之间的性能对比,在建立统一的标准数据集后,需要有统一的评价标准和指标。目前,关于显著性物体检测的评价指标主要有PR曲线(Precision-Recall Curves)、F测度值(F-measure)、平均绝对误差(Mean Absolute Error,MAE)、接收者操作特征曲线(Receiver Operating Characteristic Curve,ROC)、ROC曲线下方的面积(Area Under the Curve of ROC,AUC ROC)和S测度值(S-Measure)等,下面分别对各评价指标进行简单的介绍。
3.1 PR曲线
PR曲线是反映Precision和Recall相互关系的曲线。其中,Precision指的是查准率,Recall指的是查全率(也译为召回率),一般将Precision作为PR曲线的纵坐标,Recall作为PR曲线的横坐标。所谓查准率(Precision)指的是检测出的正样本数与检测的所有正样本数之间的比值,查全率(Recall)指的是正确检测的正样本数占所有正样本数的比例。检测结果和真实样本之间的关系如表3所示。参见表3的示意可以用公式(2)给出其定义:
(2)
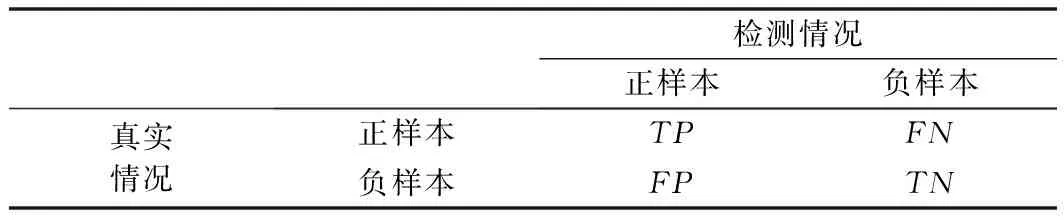
表3 检测结果和真实样本之间的关系表
在实际的显著性物体检测过程中,一般用公式(3)进行计算。
(3)
式中,S为检测方法得出的显著值;G为真实的实际标注的值。在图5中用通俗易懂的可视化的形式展示了这几个值的具体对应区域及其相互关系。其中,白色区域(绿色框显示部分)为标记的G真值为1的部分,其他区域(黄色区域)为真值G的背景0部分;蓝色框的区域为显著性检测方法得到的显著区域,S与G相交的部分为其重叠的区域,即为TP,蓝色框的区域去除重叠部分为FP,绿色框的白色区域去除重叠部分为FN,黑色框的黄色区域去除画线段的部分为TN。

图5 PR值相关区域示意图
这里,与文献[10]中所比较的方法不同,分别选择了另外一些传统显著性计算方法和基于深度学习的计算方法对它们在ECSSD数据集上检测效果进行了测试,得到如图6所示的PR曲线图。这些方法包括MR[20],MS[65],RBD[18],RR[66],MST[67],DHS[48],FSN[68],ASNet[69],BDMP[70]和SCRN[71]10种。前5种方法主要是传统的显著性计算方法,后5种主要是基于深度学习的显著性计算方法,具体对比参见表4。从PR曲线上来看,一般认为曲线越靠近图的右上方表示该模型的效果越好。从图6中可以看出,基于深度学习的显著性计算方法明显优于传统的显著性计算方法,因为基于深度学习方法的PR曲线的高度都高于传统方法的PR曲线。

表4 10种方法对比列表
3.2 F-measure
因PR曲线的值不能很好地评估模型的有效性,在文献[14]中,提出了F测度值(F-measure),简称F值。F值是根据查准率(Precision)和查全率(Recall)加权和的平均值求得的结果,当一个显著性物体检测模型的F值较高时,表示该模型越有效。F值可以通过式(4)计算得出:

图6 10种方法在ECSSD数据集中的PR曲线
(4)
式中β2的值,根据文献[16],一般经验性地取0.3。
另外,在文献[72]中,作者对F值进行了改进,对表3中的4个值进行了非二值化的处理,根据检测错误的位置分配不同的权重w,得出了新的F值,为了跟之前F值的进行区分,其被写为Fw,表示为
(5)
同样地,计算了上述10种方法的F值,一般认为F值越大,该方法的检测效率越好。10种方法在ECSSD数据集中的F值如图7所示。从图7中可以看出,基于深度学习的方法比传统的方法高出0.2,表明了基于深度学习的方法要优于传统的显著性计算方法。

图7 10种方法在ECSSD数据集中的F值
另外一种关于F值的曲线图将统计的阈值和对应的F值进行关联,如图8所示。
3.3 MAE
MAE (Mean Absolute Error)即为平均绝对误差,反映的是模型的检测值与实际真值的误差情况,可表示为式(6)。
(6)

图8 10种方法在ECSSD数据集中的F值和对应的阈值曲线图
式中,w为检测图像的宽度;h为检测图像的高度;S为检测模型计算出的显著值;G为标注图像的真值。将S和G二值化后,通过计算每个像素点在显著值与真值之间的误差的平均值,反映出图像中各个像素点通过模型检测的正确率。因此,平均绝对误差值越低,表示模型检测的精确程度越高。这里,给出了上述的10种方法在ECSSD数据集上的MAE值,具体如表5所示,可以看出基于深度学习的显著性计算方法具有较低的MAE值,表示这类方法的检测正确率比传统的方法更高。
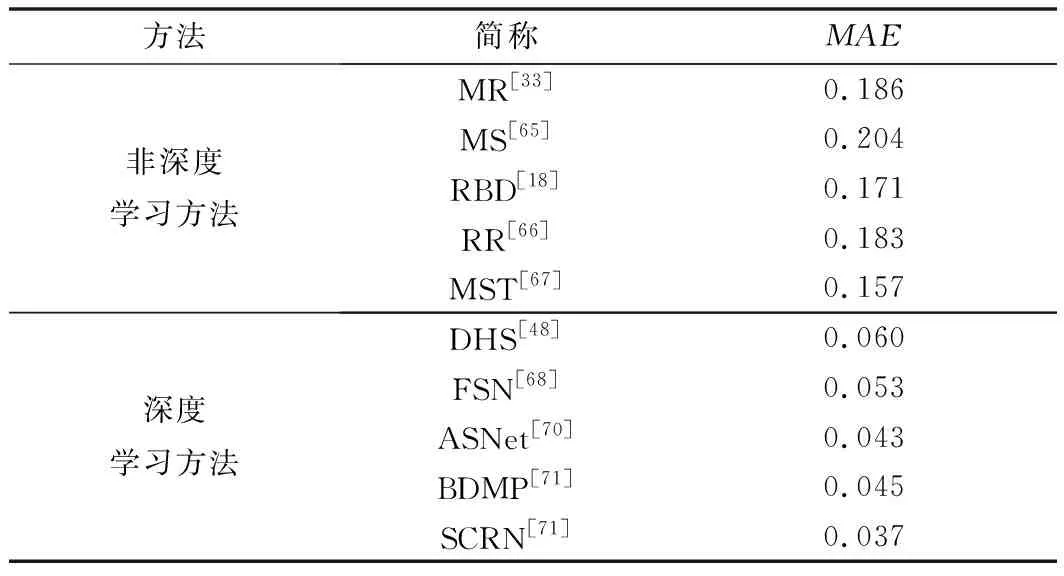
表5 10种方法在ECSSD数据集中的MAE值表
3.4 ROC和AUC
ROC(Receiver Operating Characteristic curve)译为接收者操作特征曲线,而AUC(Area Under the Curve of ROC)为ROC曲线下的面积。通过表3可知,TP表示检测为正样本,实际也是正样本,而FP表示检测为正样本,但实际为负样本。基于此,得出两个比值,即真正率TPR(True Positive Rate)和假正率FPR(False Positive Rate),用式(7)表示。
(7)
由式(7)可知,TPR表示正确被检测出的正样本和实际的正样本的比值,FPR表示被检测为正样本的负样本占实际的负样本的比值。在ROC曲线中,一般将FPR设为横坐标,TPR设为纵坐标。因得到的显著值S的灰度值范围为[0,255],二值化后的区间为[0,1],通过设置阈值对像素进行标记,若S中的某个像素的值大于阈值则标记为1,否则为0,结合图5和式(3),最终能计算出TPR和FPR的值。
ROC曲线及其AUC如图9所示。从图9中可以看出,如果ROC曲线越靠近左上方,那么检测结果效果越好。同时,通过积分可以计算得到AUC的值,其值越大,则表示显著目标检测算法效果越好。

图9 ROC曲线及其AUC
3.5 S-measure
以上所有的评测方法主要针对像素级别的误差评估,但对显著性物体的结构性特性没有进行评测,Fan等[73]针对以往的评测标准忽略了结构相似性,提出新的评测指标S-measure。该评测指标主要由区域结构相似性度量和物体结构相似性度量组成,从而更好地评价前景物体,如显著性物体。具体公式如下:
S=a×So+(1-a)×Sr
(8)
式中,S为结构性评测S度量值(S-measure);a为权重参数,其取值范围为[0,1],一般地,a的值设置为0.5。So为结构相似性度量值:
So=λ×OFG+(1-λ)OBG
(9)
式中,λ为前景区域与整个图像区域的比值。作者通过实验得出前景和背景具有强烈的对比特性以及内部近似均匀分布特性,因此,OFG和OBG分别为前景和背景相似性度量值,将两者通过λ参数加权求和,作为最终的物体结构性度量值So。式(8)中,Sr为区域结构相似性度量值:
(10)
即在计算区域相似性度量值时,将真值和检测的结果切分成k×k块,然后用结构性评价指标SSIM[74]计算每一块的ssim(k),再加上每块占前景的比例权重wk,最后将每块的乘积相加得到区域相似性度量值Sr。通过在相关数据集上进行实验,表明了S-measure评测指标具有很强的鲁棒性和稳定性,因其计算方式简单、计算速度快,将被广泛运用于显著性物体检测当中。
4 显著性物体检测的应用
显著性物体检测的相关方法的不断出现、数据集的不断更新和评价标准的更加有效,使得显著性物体检测的应用范围越来越广。正如在本文开始所述,显著性物体检测既可以应用于各种任务的预处理,也可以用于完成相关任务的检测。本节介绍了近年来显著物体检测在多个领域的应用,如表6所示。

表6 显著性物体检测在各个领域的应用
表6展示了显著性物体检测可以应用在计算机视觉、计算机图形学、多媒体等众多领域的许多任务中。下面分别介绍其代表性的工作。
4.1 计算机视觉
计算机视觉中有各种各样的视觉任务,这里主要列举了显著性物体检测在目标检测、目标识别、目标分割和目标跟踪等方面的应用。
在目标检测任务当中,主要任务是把目标的轮廓从背景中检测出来。文献[75]中指出,针对水下复杂环境,如何从大量的水下场景的视频和图像中检测物体的轮廓,是一项具有挑战的任务;作者提出一种基于显著性梯度的形态活动轮廓模型去提取水下目标的形状,活动轮廓模型的停止条件是从显著性梯度和场景的梯度中得到的,其流程图如图10所示。文献[76]提出了一个基于颜色和运动特征的显著烟雾检测模型,该模型首先增强烟雾的颜色和所在区域,然后将得到的增强的区域图和运动图结合得到显著图,最后利用显著图和运动能量图得到最终的烟雾区域预测。

图10 基于显著物体检测的水下目标轮廓检测流程图
在目标识别的任务当中,需要检测到物体,并识别出物体所属于的类别。在文献[77]中,作者针对细粒度图像识别问题,判别类间物体类别,即在识别出物体所属鸟类(大类)的同时判断该物体具体属于哪种鸟类(小类)。作者提出了一个递归注意卷积神经网络模型用于细粒度图像的识别,该网络结构设计上主要包含3个尺度的子网络,每个尺度的子网络的网络结构相同,网络参数不同,在每个尺度的子网络中包含两种类型的网络:分类网络和注意力建议网络(Attention Proposal Network,APN)。因此,数据流为:输入图像通过分类网络提取特征并进行分类,然后APN网络基于提取到的特征进行训练得到注意区域信息,再将该区域剪裁出来并放大,再作为第二个尺度网络的输入,这样重复进行3次就能得到3个尺度网络的输出结果,通过融合不同尺度网络的结果可达到更好的效果。具体流程图如图11所示。
在目标分割任务当中,主要是将目标从背景中分离出来,并且找到目标物体的轮廓。在视频中的目标分割使用较多,这部分的文献有文献[78]和文献[79],两篇论文中均使用了显著性物体检测作为其分割的预处理过程。文献[78]中,作者提出了一个融合运动信息和图像显著特性的目标分割模型,该模型通过光流法得到了运动显著信息,再与区域对比的显著性方法得到的显著图进行组合,通过阈值设置,达到目标分割的目的,可以很好地应用于静态和动态的目标分割。文献[79]中,Wang等提出了视频目标分割模型,该模型利用光流得到运动边界,再结合静态的边界概率图和超像素块分割图得到时空边界概率图,通过测地距离得到初始的显著图,最后再融合全局外观模型(Global Appearance Model)和动态定位模型(Dynamic Location Model)得到最终的分割结果,如图12所示。

图11 递归注意卷积神经网络的细颗粒度图像识别流程图[77]
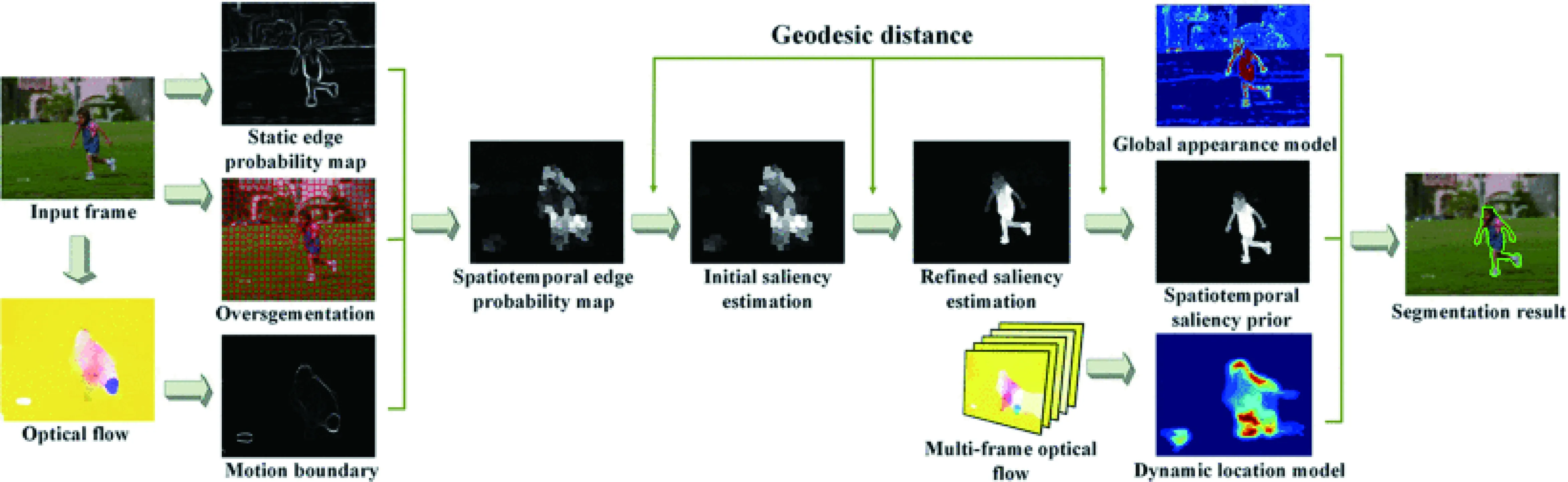
图12 基于显著性检测的视频目标分割流程图[79]
目标跟踪任务中,需要先检测出目标,在目标后续的运动帧当中,根据目标的位置变化和大小变化等,实现目标的锁定。文献[80]提出了一种基于视觉显著性的海上目标跟踪方法,该检测方法在自适应滞后阈值的显著性映射的布尔映射显著性(BMS)方法[86]的基础上进行改进,从而抑制海上目标的尾迹和表面闪烁的检测问题来减少假阳性,然后将检测的结果匹配到帧,进行跟踪,并用卡尔曼滤波器平滑轨迹,对海上船只具有较好的检测效果。具体示意图如图13所示。

图13 基于显著性检测的海上目标跟踪示意图[80]
4.2 计算机图形学
在计算机图形学领域,显著性物体检测也有广泛的应用。显著性物体检测算法一般先找到图片中的最显著的目标,通过其他方法再次优化该目标,然后实现背景和目标的分离、目标的大小调整、颜色渲染和缩放等操作,如文献[81]中所述。文献[82]将显著性检测方法应用在图像处理当中。
4.3 多媒体
在多媒体领域,主要涉及图像和视频的压缩和图像的检索。如在文献[83]中,作者将显著性检测方法应用在图像压缩方面,从而以较少的计算量来产生高质量的压缩图像,实现高压缩率。在文献[84]中,作者将显著性检测方法应用在图像检索当中,从而获得较高的图像检索能力。
4.4 其他
程明明及其团队在2017年成功地将显著性物体检测的相关成果应用在华为Mate10手机当中[85],使得手机的摄像机能够实现类似于单反相机的功能,能够锁定场景中的显著物体,并且对背景进行虚化,从而突出拍摄者想拍摄的目标。如图14所示,显示了未使用该项技术拍摄的图片和使用该项技术拍摄的图片,从图像中可以明显看出,使用显著性检测方法拍摄的图片目标更加清晰,轮廓更加显著。

图14 显著性检测方法在华为Mate10上的应用
因视觉显著性的特性,其相关方法也被用在物体表面缺陷检测中。如文献[87]和文献[88]利用显著性的特点,将其与其他方法结合,用来检测存在表面缺陷的物体,从而帮助提高检测的效率。当然,随着显著性相关方法的发展,未来越来越多的应用将与相关方法结合起来,从而更好地帮助人们解决实际应用中的问题。
5 总结与展望
本文主要介绍了显著性物体检测的方法、数据集、评价标准及其在多个领域的应用。总的说来,显著性物体检测仍然是一个非常具有挑战性的工作,具有十分重要的研究价值。目前,显著性物体检测的首选方法是基于深度学习的方法,具有较高的检测精度,可适应于复杂场景下的物体检测。未来,显著性物体检测将更加关注网络模型的大小、检测的精度以及实时性方面,作为视觉任务的前序的预处理,为各种实际的应用任务服务。当然,基于显著性物体检测也可拓展为其他的研究方向,如最近Fan等[89]提出了伪装物体检测,提出了相应的数据集和检测标准,为显著性物体的检测提供了一个新的挑战方向。
另外,本文初始部分提到过,人类的选择性视觉注意机制包含两个方面,一个是选择场景中比较醒目的区域,既涉及自下而上的视觉处理过程,也涉及自顶向下的视觉处理过程;另一个是选择场景中感兴趣的区域,主要涉及自顶向下的视觉处理过程。比较醒目的区域与感兴趣的区域在视觉场景中并不总是一致的。例如,驾驶员在驾驶车辆行驶在道路上时,需要经常关注交通标志牌和信号灯,以便于按照交规采取正确的行动,然而在复杂的交通场景中,交通标志牌和信号灯常常未处于醒目位置。到目前为止,在视觉注意力相关的研究中,人们关注的基本都是比较醒目的区域,对于感兴趣区域的视觉选择注意方面,未有有效的研究。关于感兴趣区域的视觉选择注意模型和计算方法的研究具有极大的挑战性,并且在这一方面的突破将有助于视觉信息处理技术、类脑计算等领域的发展,值得相关学者关注研究。
