基于深度学习的桥梁裂缝识别方法研究
2021-02-03应俊杰卢国庆
应俊杰,夏 峰,卢国庆,王 炎
(1.浙江理工大学建筑工程学院,浙江 杭州 310018;2.中铁四局集团第二工程有限公司,江苏 苏州 236000)
随着我国经济迅猛发展,为了满足铁路运输、公路发展等方面的需求,建设了大量的桥梁,其中,大部分桥梁建设以混凝土梁桥为主,在长时间使用过程中,会受到车辆挤压作用,同时所采用的材料性能也会发生退化,从而在桥梁底板出现裂缝,甚至露筋,有重大安全隐患[1]。因此,定期对裂缝检测对桥梁的维护和运行有着关键作用[2]。根据裂缝的形态特征和表观特征,可以推断出结构劣化的潜在原因,为桥梁结构健康诊断提供合理的依据[3]。传统的桥梁裂缝检测主要依据人工测量,效率低、漏检率高、耗时耗力、成本高。因此,自动、高效的裂缝检测对桥梁结构健康评估至关重要。
目前,基于计算机视觉的裂缝自动检测方法得到了广泛关注。大多采用数字图像处理技术和机器学习算法,可以检测出一些简单类型的结构损伤[4-5]。Tong等[6]通过采用灰度阈值方法进行裂缝提取裂缝,王植等[7]根据边缘梯度信息特征自动化设置阈值来提取裂缝,但是稳定性较差。随着计算机技术的发展,近些年来,卷积神经网络(CNN)在图像分类和识别方面取得了巨大突破[8]。相比于传统的图像处理技术,基于CNN的裂缝检测方法更加出色[9]。Zhang等[10]中首次提出将裂缝图像切割成多个小图片,再利用CNN网络把图像分为裂缝和非裂缝,完成裂缝提取。但是这种方法检测速度慢、效率低、效果差。Chen等[11]结合卷积神经网络和朴素贝叶斯数据融合方案的NB-CNN网络识别裂缝图像,但是此方法仅能识别裂缝位置,不能提取裂缝形状。Ronneberger等[12]首次提出了UNet模型,是一种全卷积神经网络模型实现图像分割,最初用于医学领域如心脏CT图像[13]、肺结节图像分割[14]。由于UNet网络有小样本、检测快、识别精准等优点,近年来也应用在其他领域中,如道路检测[15]、遥感影像语义分割[16]。
对此本文将加入了残差模块的UNet网络应用于桥梁裂缝检测中,提出一种应用于桥梁裂缝识别的新方法,并结合数字图像提出一种裂缝长度、宽度的测量办法,为实现桥梁自动化识别提供一定的帮助。
1 网络结构
语义分割是目标检测领域的重要研究方向之一,它可以实现像素级的目标检测。语义分割由编码器和解码器组成。编码器利用卷积层来输入图像的特征,采用池化层的方法减小了特征读取的规模和速度,减轻了网络计算的负担。解码器则利用反卷积方法将特征图像恢复到输入图像大小,并预测结果。本文将Residual模块(残差模块)加入到UNet网络中、并加入对桥梁裂缝进行识别检测。从输入图像中分割出裂缝像素和背景像素。
ResNet由He[17]等提出,残差网络是基于卷积神经网络的构造。与传统的神经网络相比,ResNet最大的区别是将输入加到输出中,这和最下层的功能信息融合到上层效果是一样的。当网络训练层数越深时,也意味着能提取到的特征越多,更能表达图像语义,但同时也会面临严重的梯度消失和网络退化问题。残差块的加入完美解决了这个问题网络难以优化的问题。如图1所示,相比于传统模块,残差模块加入了一个恒等的快捷链接。其中H(x)为最优映射,F(x)为残差映射,H(x)=F(x)+x。这使得对H(x)的学习转为对F(x)的学习,而学习F(x)更加容易。
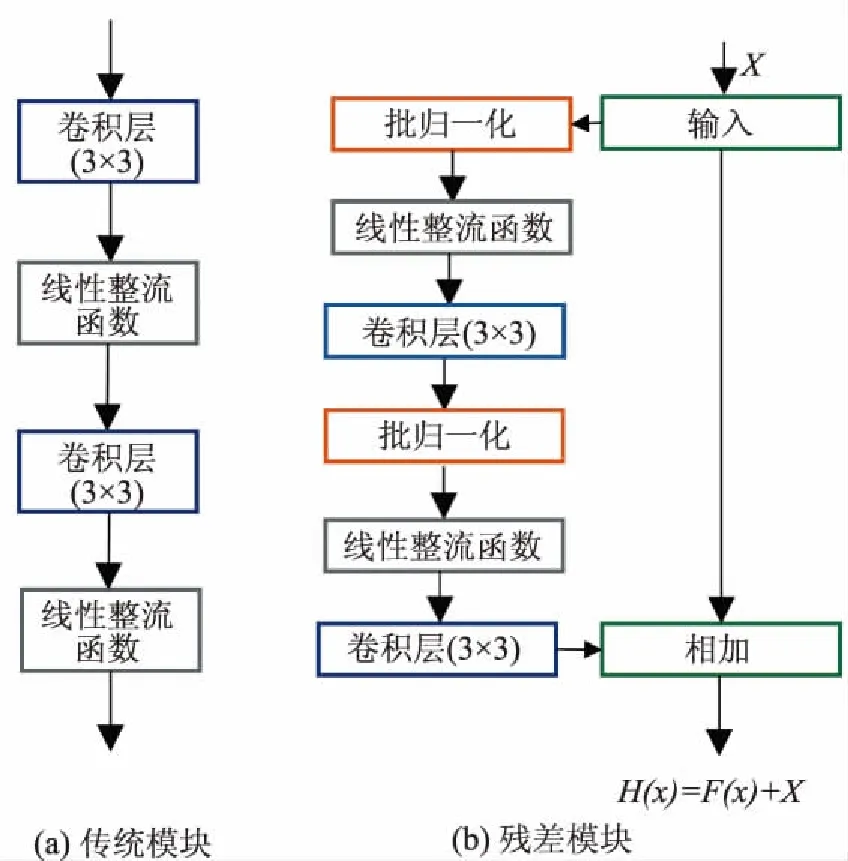
图1 传统模块与残差块
Res UNet网络是基于ResNet(Rsidual Nural Ntwork)和UNet的语义分割网络模型,其结构类型与UNet大体相似。Res UNet网络由编码器、连接器和解码器三个部分组成。解码器是由3个残差模块( residual block)组成,主要作用是对输入图像进行解码,读取特征,也就是下采样过程。连接器是应用于连接编码器和解码器之间的信息传播路径。解码器是应用于图像恢复过程,原理是对图像中每个像素进行分类,主要由3个解码模块(decoder block)组成,每个解码模块包括批归一化(Batch Normalization,简称BN)、ReLu层和反卷积层。
将残差网络加入到UNet模型中有效克服了因网络层数过多而导致过拟合、参数冗杂以及深度模型退化等问题。并且由于残差块加入,训练速度大大提高,也使得网络在以保存较少参数的情况下确保损失精度较高。网络结构如图2所示。

图2 Res UNet网络结构
2 实验
2.1 图像来源
实验对象为浙江省某市约200余座桥梁,进行为时30d的调研。拍摄天气均为晴天,拍摄时间为8点至17点,主要对桥梁梁板裂缝照片信息采集。图像格式为.jpg,像素为5184DPI×3888DPI。
若直接进行分割耗时较长,且效果较差,因此本文将照片裁剪成256DPI×256DPI的图像。每张图像包含了65536DPI样本,经整理,有1702张裂缝图像,共计111542272DPI样本。采集到的图像裂缝实际情况使用国产软件精灵标注助手进行像素级手动标注。按照规定,将裂缝标记为淡蓝色,其余背景均自动标记为其他类别数据库中的所有图像和标签都是RGB三通道PNG格式。在标签图像中,黑色代表背景,白色代表裂缝,即(0,0,0)代表背景像素,(255,0,0)代表裂缝像素。如图3所示。

图3 裂缝图像与标注结果
2.2 实验设置
模型由开源的深度学习框架TensorFlow和Keras进行搭建,利用Anaconda建立了Res UNet网络的虚拟Python环境,利用CUDA和CUDNN来加速GPU计算,从而提高网络的训练速度。软件的版本和硬件设施见表1—2。

表1 训练网络所使用的硬件环境

表2 训练网络所使用的软件环境
2.3 参数设置
由于语义分割的原理是对每个像素进行分类,而不是整个图像,以实现图像像素级检测。网络参数设置为:学习率(learning rate)为2×10-4;批量大小(batch size)为4;动量(momentum)为0.99;权重延迟为0.000001;一阶矩估计的指数衰减率(beta1)为0.7;二阶矩估计的指数衰减率(beta2)为0.999,模糊因子(epsilon)为10-8,共200个周期。激活函数选择Sigmoid,解决网络深度带来的过拟合问题。
(1)
式中,S(x)—线性激活函数,由于它的梯度总是在0和1之间,不存在梯度消失的问题。
选择Adam作为优化工具,采用自适应时刻估计方法计算每个参数的自适应学习率,加快收敛速度。
选择Focal Tversky作为损失函数,使网络集中在裂缝样本上。该损失函数是基于Dice函数进行改进的版本,既解决了正负样本不平衡而难以分类学习的问题,又帮助模型提升到感兴趣的小区域,增强分类的速度和准确率。公式如下:
(2)
(3)
式中,TIc—Focal损失函数;FTIc—Focal Tversky函数;gic—真实标签的概率,代表着像素i属于c类的概率;pic—预测标签的概率,代表着像素i属于c类的概率;∈—提供代表一个防止被除零的数值;α、β—超参数,可以调整正负样本不平衡的回归能力。
2.4 网络评估指标
本文使用客观的评判标准来评估裂缝识别效果:准确率(precision),召回率(recall)作为图像分割结果的评价指标,并以综合评价指标(F1)作为准确率和召回率的评估值。用交并比(IoU)作为检测裂缝准确度的标准。
(4)
(5)
(6)
(7)
式中,TP—正确分割裂缝像素数;FP—错误分割裂缝像素数;FN—漏分割裂缝像素数;TN—正确预测背景像素数。
3 结果分析
3.1 训练结果
设置好超参数后,开始对网络参数进行训练,其中训练集1069张,验证集633张。为了防止过度拟合,使模型更具鲁棒性。在训练的同时采用了数据扩充方法,包括:随机裁剪、水平翻转、平移、随机亮度对比等将数据集扩充至6倍。为了节约时间,设置了早停程序,一共设置了240个迭代次数。每次迭代时,计算当前的网络训练损失,并保存权重。
3.2 不同模型对比分析
为了验证该方法的像素级分割性能,本文采用3种模型进行了研究比较:UNet、VNet在保证其他参数都相同的情况下,训练网络模型,并通过精确率、综合评价指标、交并比、召回率来验证训练效果。UNet是在医学领域中较为经典的分割网络,其结构类似于U型,其原理是对FCN加入了跳跃结构,保留了一些特征信息。VNet是基于UNet基础上,引入了ResBlock模块,用卷积模块代替池化层。而Res UNet并未对卷积模块进行池化,因此这三个模型对比具有较大的参考价值。
loss变化情况如图4所示,可以看出UNet下降幅度最大,收敛需要的迭代周期最久,其次为VNet和Res UNet,这可能与模型结构有关,UNet模型结构相对简单,迭代过程中容易丢失细节,下降需要更多迭代周期,约40个周期才趋于稳定。VNet和Res UNet由于ResBlock模块加入,需要迭代周期少,分别需要约20个周期和15个周期,从最后表现结果来看Res UNet效果更佳。

图4 不同模型的训练损失
各模型准确率、综合评价指标、交并比、召回率的变化如图5所示。可以看出UNet与VNet表现效果差不多,都略逊于Res UNet。精确率方面,Res UNet比VNet高出4.613%,比UNet高出6.471%,达到72.337%;交并比方面,Res UNet比VNet高出4.966%,比UNet高出4.024%,达到66.245%;召回率方面,Res UNet比VNet高出5.059%,比UNet高出5.651%,达到90.478%;综合评价指标方面,Res UNet比VNet高出4.844%,比UNet高出6.472%,达到80.242%。参考评价指标以及迭代周期,Res UNet模型表现最佳。

图5 评价指标:(a)准确率,(b)召回率,(c)交并比,(d)综合评价指标
3.3 识别结果对比
部分识别结果见表3,表3分别对比了原图、标签图以及各模型输出图片。样本1中UNet模型未识别出细裂缝(左上角),而其他两个模型识别效果较好可能由于UNet模型对细节把控不佳。样本2中UNet、VNet模型均将左上角误识别为裂缝,而标签图未标记为裂缝,观察实际原图也不是裂缝,仅是类似为裂缝。样本3中3个模型表现都与标签图类似。样本4中VNet模型误识别了细裂缝。通过分析之后,发现对于大多数情况所有模型都能识别出来,但是对于细节方面仅Res UNet表现较好。综合对比之后,Res UNet模型输出图片最接近标签图,识别效果最好。

表3 不同模型识别结果对比
4 结语
本文阐述了全卷积神经网络技术识别裂缝信息的原理,针对桥梁裂缝识别问题,提出采用python语言编写裂缝识别程序,并进行了验证,得出如下结论:
(1)采用消费级相机人工采集桥梁裂缝病害数据集,并对图像数据进行归一化处理并标注,构建训练库以供网络模型训练,但目前数据数量远远不足,未来主要任务还需要整理收集更多样本。
(2)针对现有桥梁自动化识别研究中存在的问题,提出了加入残差块的改进UNet模型,对比了UNet、 VNet模型,结果表明:本文所提供方法能较为精确地检测出桥梁裂缝。
本文所提出的一整套桥梁裂缝自动检测方法,对桥梁的养护和运营具有重要意义。
