基于深度学习的变压器图像识别系统
2021-02-02吴海东俞志程叶晓康
薛 阳, 吴海东, 俞志程, 张 宁, 叶晓康, 华 茜
(上海电力大学 自动化工程学院, 上海 200090)
随着计算机视觉技术的快速发展,以及传统变电站逐步向智能变电站的发展,变电站无人值守、无人巡检已成为发展趋势。使用高清视频、红外热像监视等智能化检测技术可以实现电站的无人值守[1-3],使用搭载摄像头、行外成像仪的无人机巡检、机器人巡检等巡检技术对变电站进行快速巡检也得到了广泛应用[4-7]。对大量图像数据流中的电力关键设备进行自动检测与识别,代替人工对图像的处理,可以提高巡检效率。
基于机器学习的电力设备识别的传统算法主要采用人工设计的特征作为图像的特征[8],具有代表性的有尺度不变特征变换(Scale-invariant feature transform,SIFT)特征[9],方向梯度直方图(Histogram of Oriented Gradient,HOG)特征[10],再结合高效的分类器进行电力图像分类的研究。这些方法设计的原则往往是基于特定类别、特定型号的设备,需要设计者针对不同的对象设计专门的特征量,具有一定的局限性,且这些方法不具备随着样本数量的增多、图像识别准确率随之提升的能力。
为此,本文在电站复杂背景情况下,针对不同型号的变压器图像,采用改进Visual Geometry Group(VGG)网络模型进行识别,对网络的结构、输出分类器进行重新设计,构建了基于改进VGG-16网络模型的变压器图像识别系统,并对改进的VGG-16网络模型进行了实验验证。
1 模型构建
1.1 卷积神经网络
卷积神经网络(Convolutional Neural Networks,CNN)是包含卷积计算且具有深度结构的前馈神经网络,属于多层神经网络,主要应用于识别二维特征方面[11-13]。相比传统的反向传播(Backward Propagation,BP)神经网络,在其基础上增加了卷积层和降采样层,CNN能够进行平移不变分类。CNN网络结构主要由4部分组成,包括卷积层(C层)、降采样层(S层)、全连接层(F层)以及SoftMax分类层。CNN在面对图像平移、旋转等变形情况下,具有较强的识别能力。VGG-16网络模型是当前比较常用的CNN网络模型。
1.1.1 卷积层
卷积层通过使用卷积核对输入层进行若干次的卷积运算处理和特征提取,并将结果组合成特征矩阵,然后通过稀疏连接与降采样层相连。卷积核的尺寸决定局部连接区域。CNN的识别性能直接受局部连接区域的影响。常用的卷积核尺寸有3×3或者5×5,其深度与当前神经网络节点矩阵深度一致。卷积运算实际上就是卷积核与输入矩阵进行线性运算的重复过程,具体公式为
(1)
(0≤m≤M,0≤n≤N)
式中:yconv——输出的卷积结果;
f——卷积层激活函数;
x——输入接受区域,是长宽为(M,N)的矩阵;
w——卷积核,长宽为j和i的卷积核;
b——每个卷积操作时所加的偏置项;
M,N——输入矩阵的长和宽。
1.1.2 降采样层
降采样层又叫池化层,主要作用是对一个输出层的不同区域的特征进行聚合,即对结果压缩并得到更重要的特征。经过降采样层处理后的特征图的尺度会有一定程度的减小,在减小特征图像素点的同时也会大大减少后面相关网络权重参数的数量[14]。最大池化和平均池化是最常用的两种池化计算方法。无论是最大池化还是平均池化,均采用2×2的采样窗口,缩放因子常设为2,即以步长为2的速度来缩放图片。最大池化函数公式为
fpool=max(xm,n,xm+1,n,xm,n+1,xm+1,n+1)
(2)
(0≤m≤M,0≤n≤N)
式中:fpool——经过最大池化后的结果;
xm,n,xm+1,n,xm,n+1,xm+1,n+1——采样窗口里的4个值。
1.1.3 全连接层
在经过多轮的卷积层和降采样层的处理后,输入图片的信息被抽象成信息含量更高的特征,相当于自动提取了图片中的特征。特征提取完成后,使用全连接层进行分类。
1.1.4 SoftMax分类层
SoftMax层采用的分类器是SoftMax回归模型。SoftMax回归作为一个优化算法,将神经网络的输出变成一个概率分布,其输出标签y可以有k个不同的值,训练样本是由m组输入样本和输出标签构成:
T={ (x(1),y(1)),…,(x(m),y(m)) }
(3)
式中:x(i)——多组输入样本集合,x(i)∈{1,2,3,…,k};
y(i)——分类标签,y(i)∈{1,2,3,…,k}。
单个输入样本x(i)经过分类器模型后,对应一个具有一定概率值的识别类别j,因此可将假设函数公式设置为
(4)

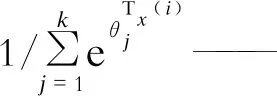
通过对训练集不断地训练和学习,SoftMax模型通过迭代优化的方法拟合出数据曲线,对θ的值进行调整,使损失函数值最小。SoftMax分类器模型的损失函数公式为
(5)
随着模型不断地迭代,SoftMax分类器的参数得到优化,使得对不同的输入样本有了识别分类的功能。
1.2 VGG-16网络模型
VGG-16网络是在传统CNN的基础上构建的,在网络的深度上有一定的提升,卷积核大小统一为3×3。3×3的卷积核能提取输入区域内更多的特征,并且通过卷积核的堆叠组合来实现5×5,7×7大小卷积核相同的大小,使用更少参数的同时也可以获取更好的非线性效果。图1是VGG-16网络模型结构图。该网络共有1个输入层,13个卷积层,5个降采样层,3个全连接层,1个输出SoftMax层。

图1 VGG-16网络模型
VGG-16网络是输入为224×224×3大小的RGB图像。所有卷积层使用的卷积核大小都是3×3的卷积核且步长为1。“conv3-64”表示这一层使用的卷积核大小为3×3,卷积核数量为64个。所有降采样层均采用最大池化的方法,采用2×2的池化窗口,且步长为2。全连接层有3层,每层对应的通道数分别为4 096,4 096,1 000个。SoftMax层对应输出的标签数量为1 000,所以网络中有1 000个通道数进行分类输出。
由于神经网络中只有卷积层和全连接层有激活函数的存在,因此有效层只包括卷积层和全连接层。这两层的总层数为16,故称为VGG-16。正是因为激活函数的存在,才使得神经网络具有非线性映射的能力。VGG-16网络的激活函数选择的是ReLu(Rectified Linear Unit)函数。相比sigmoid函数,ReLu函数对梯度消失问题有一定的缓解,并且能加快网络收敛速度,使得一部分神经元输出为零,使得网络变得稀疏,参数数量相应也会减少,对过拟合问题也有一定的缓解。
2 改进VGG-16网络模型
本文提出的改进VGG-16网络模型是在VGG-16网络模型的基础上改进而来的。VGG-16网络模型是在图像数据集ImageNet[15-16]中训练得到的参数和权重,具有较强的深度特征学习能力。其中,卷积层作为特征提取层,对图像的边缘、轮廓、纹理等提取能力较强。同时VGG-16网络的参数数量高达约6.5×107个,在此基础上改进的模型也具备大量的参数,且对于VGG-16网络的卷积层已经具备高层抽象特征的提取能力。这种特征提取能力不管是对ImageNet数据集还是对本文研究的变压器图像数据集,都存在共同特征,所以在同构空间下进行特征的迁移,能够节省网络训练的时间,提高网络的效率。
改进VGG-16网络模型将训练好的VGG-16网络模型中的卷积层和降采样层迁移到目标数据集的分类任务中。由于VGG-16网络的模型大量参数集中在全连接层中,且SoftMax层是按1 000个分类设计的,而本文只针对3个类别的分类,因此本文提出用含有512个神经元的全连接层代替第1个全连接层,用含有256个神经元的全连接层代替第2个全连接层,用含有3个神经元的全连接层代替第3个全连接层,SoftMax层的输出也变成了3个标签。这样在减少参数的同时也满足分类要求,从而加快训练的速度,提高模型的识别精度。
在VGG-16网络模型上使用迁移学习构建的改进VGG-16网络模型如图2所示。它主要包括两部分:一是由VGG-16网络迁移过来的卷积层和降采样层,加载了其训练好的参数;二是预先训练好的全连接层。

图2 改进VGG-16网络模型
改进VGG-16网络模型包含13个卷积层,均为3×3大小,步长为1的卷积核;3个降采样层,均为2×2大小,步长为2的池化窗口;3个全连接层。模型输入为224×224×3大小的RGB图像;第1~2层的卷积核个数为64个,第3~4层的卷积核个数为128个,第5~7层的卷积核个数为256个,第8~13层的卷积核个数为512个,第14~16层为全连接层,对应每层的神经元个数分别为512,128,3。
改进VGG-16网络模型的搭建、训练和测试共分如下6个阶段。
(1) 输入训练样本。从训练集中抽取待训练的数据,作为模型的输入。
(2) 对输入的数据进行预处理。使用高斯滤波尽可能地去掉噪声干扰,对图片进行缩放、旋转和裁剪,以保证输入图片具有相同的分辨率。
(3) 构建改进VGG-16网络模型。在VGG-16的基础上,重新构建全连接层神经元的个数,改进VGG-16的全连接层神经元个数依次为512个、128个、6个,并用3个标签的SoftMax分类器替换原1 000个标签的分类器。
(4) 微调迁移学习。通过迁移学习的方式,用VGG-16网络模型卷积层和降采样层的参数来优化改进VGG-16网络模型参数。
(5) 改进VGG-16网络模型训练。将处理好的数据作为已经训练好的VGG-16网络模型的输入,冻结VGG-16的卷积层和降采样层的参数,获取卷积层和降采样层的部分输出,再利用这部分输出训练改进VGG-16的全连接层的参数。
(6) 改进VGG-16网络模型测试。从测试集中抽取数据作为模型的输入,以验证模型识别的精确度。
改进VGG-16网络模型搭建、训练和测试流程如图3所示。

图3 改进VGG-16网络模型搭建、训练和测试流程
3 实验设计与结果分析
3.1 实验数据集
本文采用的实验数据集均来自于网络。一共有3种不同类型的变压器,分别为油浸式电力变压器、矿用变压器和箱式变压器。3种变压器器身均采用新型绝缘结构,铁心均由高质量冷轧钢片制成,高压绕组均选用无氧铜线为材料。3种变压器之间外观上虽有不同,但在不同拍摄角度下,相同变压器差异较大,这就增加了识别难度,故所有采用深度学习算法加以识别。数据集共1 500幅图片,每张图片都注释了边框,并标上了类别标签。全部图像分为训练集和测试集,在用数据集训练网络前,采用翻转、裁剪、缩放、旋转、平移等数据增强方式对图片进行处理,以增强数据集。本文所使用的数据集规模较小,属于小数据集,故采用ImageNet数据集作为源数据进行迁移学习。ImageNet数据集有1 000个类别的图像,种类丰富,数据量大,可以为深度学习模型迁移提供很大的支撑。
3.2 实验设置
采用2个对比实验,分别是基于深度神经网络(Deep Neural Network,DNN)变压器图像识别方法和基于CNN的变压器图像识别方法。实验中,CNN模型以及本文改进的VGG-16网络模型均在GPU(Graphics Processing Unit)上进行训练,GPU为Tesla K20(一块)。实验环境为Windows的TensorFlow。
3.3 实验结果与分析
采用不同的模型,针对训练集1 260张图片得到的训练误差和针对测试集240张图片得到的预测误差,以及训练时间和识别时间如表1所示。
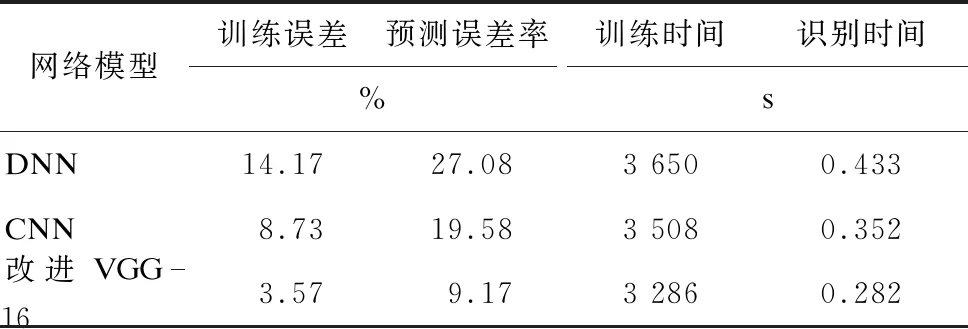
表1 几种方法的性能对比
由表1可知,无论是在训练集上还是在测试集上,本文所提出的改进VGG-16网络模型对变压器图像的识别误差都远低于普通DNN模型和CNN模型,具有更高的图像识别率。本文使用迁移学习的方式来训练改进VGG-16网络模型,迁移学习将VGG-16训练好的参数作为改进VGG-16网络模型的初始参数,在这基础上再训练VGG-16网络模型,从而缩短了训练时间。由表1可知,改进VGG-16网络模型训练时间少于DNN模型和CNN模型,识别时间也少于DNN模型和CNN模型。
每隔500次记录一次模型对测试集的识别误差率。随着迭代次数的增加,通过不同模型得到的预测误差曲线如图4所示。
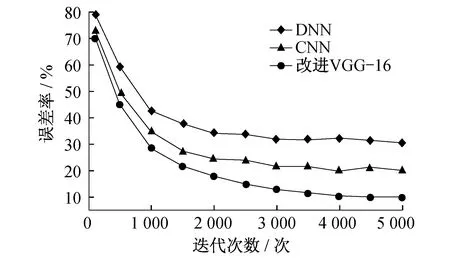
图4 不同模型得到的预测误差曲线示意
由图4可知,改进的VGG-16网络模型的误差率明显低于DNN模型和CNN模型,改进VGG-16网络模型的误差率基本上稳定在10%左右,而CNN模型和DNN模型的误差率分别在20%和30%左右。在训练次数相同的情况下,VGG-16网络模型的错误率比DNN模型和CNN模型都低,并且识别更加稳定,而DNN模型和CNN模型都存在一定的波动。由此表明,改进VGG-16网络模型具有识别率高和更加稳定的优点。
4 结 论
在VGG-16网络模型的基础上,改进的VGG-16网络模型更换原有3个全连接层的神经元数,同时用含有3个标签的SoftMax层更换了原有1 000个标签的SoftMax层。将迁移学习用于变压器图像识别,将在ImageNet数据集上训练好的VGG-16网络迁移到本文模型中来,缩短了训练时间,并降低了识别的误差率。由3种不同的变压器图像在不同模型上训练和测试的表现得到以下结论:
(1) 随着迭代次数的增加,模型更准确。当达到一定迭代次数后,模型识别误差变化波动不大。
(2) 本文提出的改进VGG-16网络模型,在相同的训练次数下,图像识别的误差率低于CNN模型和DNN模型,识别准确率更高,更加稳定,性能更加优越。
