基于KNN-HMM的智能手语翻译系统
2021-02-02钟建敏李晓冬李家健陆任贵常子键
钟建敏 李晓冬* 李家健 陆任贵 常子键
(桂林电子科技大学电子电路国家级实验教学示范中心,广西 桂林 541004)
0 引言
我国是听障人口数量最多的国家,其人口已达2780万人[1]。作为听障者使用的主要沟通手段,手语在健全人群体中普及率非常低,这成为他们融入社会的巨大障碍。为了填补这一鸿沟,2016年8月,国务院印发了《“十三五”加快残疾人小康进程规划纲要》,强调了“残疾人服务科技应用等创新要素”的重要性。如何利用现代科技实现手语翻译,帮助听障者与健全人更好地沟通交流成为亟待解决的问题。
当前手语识别技术大体可分为三种技术路径:
(1)基于视觉的手语识别。该方案利用摄像头采集手语动作的图像信息后进行识别[2],其优点是无须穿戴,体验较好,但数据处理量巨大,实时性差,而且易受外界环境影响,在遮挡、强光、弱光或移动环境下识别困难,在日常交流过程中有很大的局限性。
(2)基于SEMG表面肌电传感器和惯性测量传感器的手语识别。该方案利用皮肤表面的肌电信号配合手部运动加速度信息识别手部动作,优点是穿戴的体验感较好,但成本较高,识别准确率与使用者手部肌肉信号强度关系紧密,个体差异较大。
(3)基于数据手套的手语识别。该方案利用数据手套上的弯曲度传感器和惯性测量传感器识别手部动作,识别率较高[3-5],而且成本较低。
听障人群大多处于社会底层,收入较低,在保证手语识别准确率的前提下,尽可能地降低成本是推广普及手语翻译系统的关键,因此,本文选择了第三条技术路径。
1 系统总体框架
系统由数据手套和手机App部分组成,如图1所示。数据手套分为左手和右手,右手为主端,左手为从端。从端将采集到的左手手部动作数据通过蓝牙发送给主端,主端将双手的动作数据融合后对手型进行初步判断分类再通过蓝牙发送到手机端,手机端App利用HMM模型中的Viterbi算法对接收到的数据进行二次分类最终确定手语类型,并显示文本、播放语音。数据手套实物及手机App运行界面如图2所示。

图1 系统总体框架

图2 数据手套实物及手机App运行界面
2 数据手套设计
2.1 硬件设计
2.1.1 主控模块
主控模块采用STM32l4R5处理器,该处理器基于标准的ARM架构,采用了为高性能、低成本、低功耗的嵌入式应用专门设计的Cortex-M内核,主频120 MHz,运算性能 150 MIPS,功耗 43 μA/MHz,配置了高达640KB的RAM和2 048 KB的FLASH,集成了12位的ADC、SPI等众多外设,此外还带有FPU单元和DSP指令集,足以满足手型分类相关算法对运算速度的要求。
2.1.2 手部动作采集模块
(1)弯曲度传感器
弯曲度传感器是一种用来测量弯曲程度的柔性传感器,利用其在弯曲过程中的阻值变化反映弯曲程度。弯曲度传感器固定在数据手套的5个手指位置,通过分压电路将变化的电阻信号转换为电压信号再经过AD采样电路即可获取手指弯曲数据。
(2)惯性测量传感器
惯性测量传感器采用MPU9250,与另一款常用的惯性传感器MPU6050相比,前者在内置三轴MEMS陀螺仪和MEMS加速度计的基础上增加了磁力计,有效解决了Z轴的漂移问题,精度更高。MPU9250的陀螺仪用于测量手部X、Y、Z三轴的角速度分量,加速度计用于测量三轴的加速度分量,磁力计则用于测量三轴的地磁分量,利用这9个量通过姿态解算就能得到手部的运动姿态信息。
2.1.3 通信模块
通信模块采用支持蓝牙5.0BLE(Bluetooth Low Energy)的nRF52832芯片,该芯片提供了一个UART接口,2个I2C接口和3个主动SPI接口,功耗仅为5 mA[6]。
2.1.4 电源模块
考虑到便携性和续航能力,数据手套选用了330 mAh、3.7 V的聚合物锂电池,尺寸仅为6 mm厚、22 mm宽、26 mm长。充电电路选择tp4056单节锂电池充电芯片,电路中各模块、芯片要求3.3 V供电电压而电池的输出电压范围为2.7~3.7 V,因此,需要稳压电路。电路如图3所示,左端为充电电路,右端为稳压电路。
2.2 软件设计
2.2.1 程序流程
系统初始化后进入数据采集循环,通过弯曲度传感器和惯性测量传感器获取的数据先分别归一化,再进行数据融合,然后采用KNN(K-最近邻分类)算法在样本集中找到与当前手势最接近的K个手势样本数据及其所属的m个分类,最后将这些分类编号及其概率(获得的投票数)通过蓝牙发送到手机端做进一步处理,流程图如图4所示。
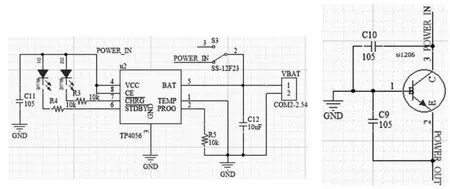
图3 电源电路
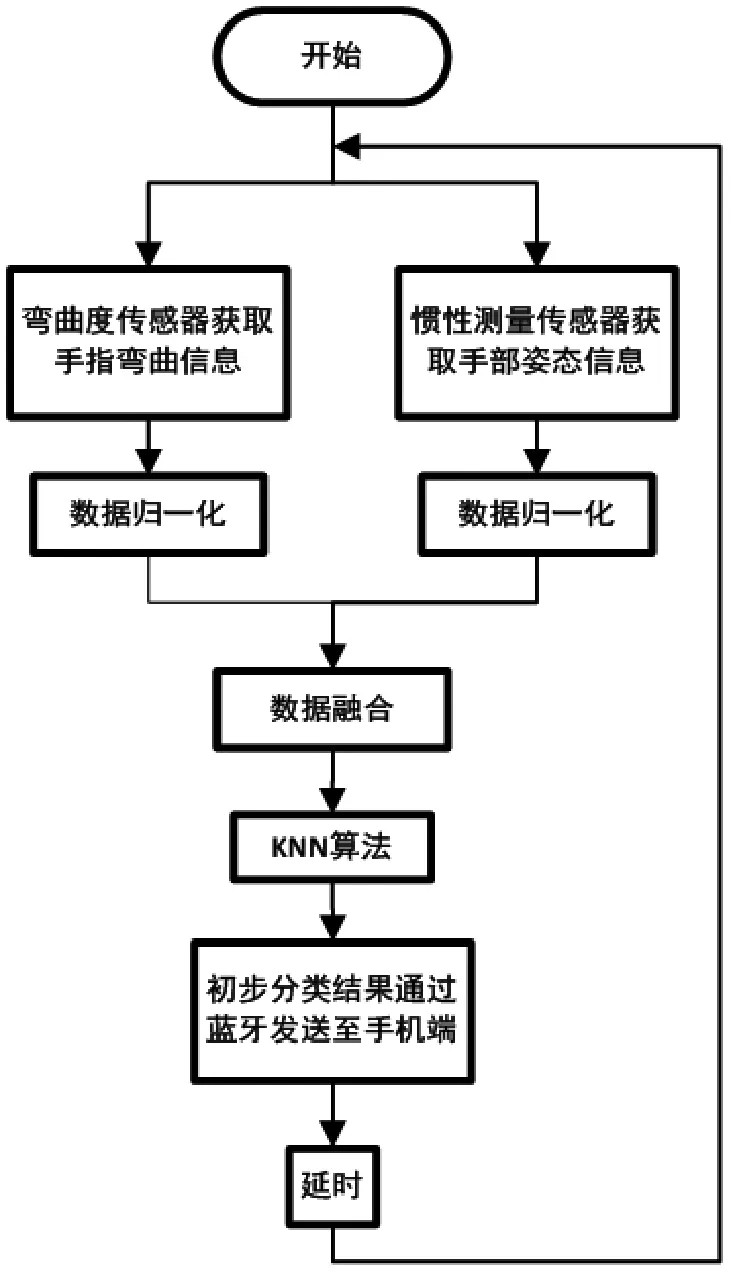
图4 数据手套端程序流程图
2.2.2 KNN算法
KNN算法是机器学习算法中最简单的分类算法之一,当要对一个新的数据进行分类时,根据与它距离最近的K个已有数据的类别来判断其属性,本文采用欧式距离,计算公式如下:

式中,xk为待分类数据,yi为样本数据,xkj为xk的第j个分量,yij为样本数据yi的第j个分量,n为样本及待分类数据的维数。
KNN算法只需简单增加样本集,即可应对词汇量的增加,无需进行大量参数调整就能获得不错的性能表现,分类准确率比较高。使用KNN算法前,需要为每一个手势采集多组数据,建立手势样本集,当样本集较大时,基于穷举搜索的KNN算法的时间复杂度将会很大,达到了O(N),因此,本文采用了基于KDTree的KNN算法,其时间复杂度为O(log2N)[7],同时K取值为3,这样可以在保证准确性的同时大幅度降低计算复杂度。当然,KNN算法也存在着无法解决手势的时间可变性问题:同样的手势,不同的人,在不同时间做出来会有差异,这会降低识别率,因此,初步分类结果还需在手机端采用其他算法作进一步分析。
3 手机Ap p设计
3.1 程序流程
系统初始化后,循环监听数据手套端发来的初判数据,并分析其连续状态是否结束,当连续状态结束时,表明使用者已经用一组手语表达完整一段话,程序调用Viterbi算法计算出这组手语最有可能表达的语句组合并返回每一个词汇的ID序列,最后播放这组ID对应的音频,显示其文字,流程图如图5所示。

图5 手机App程序流程图
3.2 HMM模型
手语属于自然语言,完整的表达通常需要连续的手语动作,是一种较为典型的时间序列,其上下文中相邻词间具有较大的关联性,因此,可以使用隐马尔科夫模型(HMM)对其进行建模以弥补KNN算法的不足。对于一段完整的手语,数据手套采集到的每个手语动作数据是一组已知的观察序列O={O1,O2,...OT},而这些动作数据所表示的含义则是隐藏序列S={S1,S2,...,ST};初始状态概率向量π是这段手语表达里首个手语动作可能的m个含义对应的概率组成的向量;状态转移概率矩阵A表示每一个手语词汇之间的语言统计关系,可通过语料库计算出来,这里使用NGram语言模型中的二元Bi-Gram模型,即一个词的出现仅依赖于它前面出现的一个词;发射概率矩阵为每个手语词汇可能对应的手语动作数据的概率关系,由KNN算法获得。 上述HMM 模型里,λ=(A,B,π)和观测序列O都已知,需要计算的是给定观测序列条件下,概率P(S|O,λ)最大的隐藏序列S,这是一个解码问题,可采用Viterbi算法实现。当手语词汇表比较大时,为减少检索时间,用哈希表建立状态转移概率矩阵的数据结构,理论上其时间复杂度只需O(1)。
4 测试结果分析
本设计选择了5位掌握手语的健康测试者对系统录入的30个手语词汇进行了测试,测试内容分为单一手语测试和连续手语测试两项。在单一手语测试中,测试者对每个手语动作分别操作10次;在连续手语测试中,测试者利用系统中的30个手语词汇随机表达300句话,测试结果如表1所示。
测试结果表明单一手语的识别准确率超过了93%,连续手语的识别准确率略低,但也超过了90%。
5 结语
本文设计的手语翻译系统采用了数据手套+手机App方案,实现难度相对较低,受使用环境影响较小;结合了KNN和HMM模型中的Viterbi两种算法,在识别精度上表现良好,且成本较低,手语词汇的可扩展性较好。输出端以手机为载体,普通人只需下载安装App即可与佩戴数据手套的听障人士实时交流,其便捷性不言而喻。
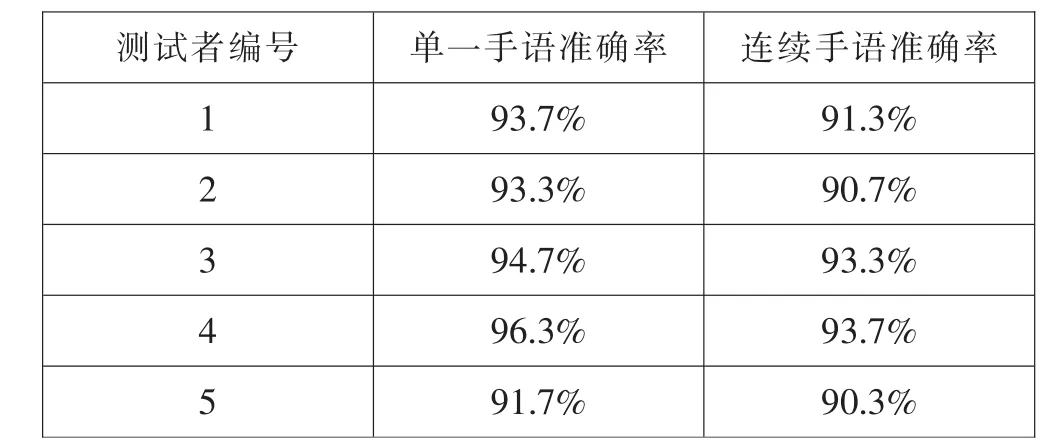
表1 系统测试结果
