基于3D CNN的道路视频交通状态自动识别
2021-02-01张媛媛蔡晓禹孟繁和
彭 博 ,唐 聚 ,张媛媛 ,蔡晓禹 ,孟繁和
(1. 重庆交通大学山地城市交通系统与安全重庆市重点实验室,重庆 400074;2. 重庆交通大学交通运输学院,重庆 400074;3. 安徽科力信息产业有限责任公司,安徽 合肥 230088)
为了准确有效地获取交通信息,许多城市在道路设施中布设了感应线圈、视频检测器、RFID (radio frequency identification)卡口等设备. 其中,视频检测器具有直观可视化、信息量大、不影响道路交通等优势,在交通监管中广泛应用,成为交通研究的重要手段.
近年来,人们基于视频数据主要展开了车辆检测、交通参数检测、交通状态识别[1-3]等方面研究,这些方法大多以单帧图像为输入,而很少直接基于视频展开研究. 例如,Wei等[1]基于图像纹理分析技术构建了城市道路交通拥堵快速检测算法,Shi等[2]基于感知特征和随机森林分类器构建了视频图像交通状态估计模型,崔华等[3]利用 FCM (fuzzy C-means)对静态图像进行交通状态识别. 这可能导致帧间运动信息缺失,因此,有必要考虑多帧图像运动特性,据此判断一段视频反映的交通状态. 不过,这需要解决复杂的多帧图像时空信息提取与建模问题.
直到 2013年,基于二维卷积神经网络 (如LeNet[4]、AlexNet、GoogleNet、VGG16[5])在大规模图像解析与分类方面的卓越表现,Ji等[6]拓展出了一种三维卷积神经网络(3D convolution neural network,3D CNN),可对视频作卷积运算,自此,3D CNN视频处理获得了广泛关注:Tran等[7]构建了在所有层使用 3 × 3 × 3 卷积核的视频处理 C3D (convolutional 3D)模型;Xu等[8]以C3D为基础提出了针对连续未修剪视频流行为检测的区域卷积3D CNN模型R3D(region convolutional 3D network);Tran 等[9]进一步把三维时空卷积分解成二维空间卷积和一维时间卷积,提出了更易训练的视频动作识别模型R(2+1)D(resnets adopting 2D spatial convolution and a 1D temporal convolution).
综上所述,3D CNN可同时学习空间和时间维度特征,在识别视频动作趋势方面优势突出、成效显著,有望解决视频交通状态识别问题. 本文尝试以C3D网络框架为原型构建视频交通状态识别3D CNN模型,建立交通视频数据集,进行训练、验证及测试分析.
1 C3D模型简介
C3D模型是以3D CNN网络为基础,进行卷积核尺寸与深度优化而得. Tran等[7]利用3D CNN进行大规模视频时空特征学习时发现,所有卷积层使用 3 × 3 × 3 (深度 × 高度 × 宽度)的卷积核效果较好,并结合线性分类器提出了C3D模型.
C3D直接将具有图像通道、深度(图像帧数)、高度(帧图像高,单位:像素)、宽度(帧图像宽,单位:像素) 4个维度的视频作为输入、输出视频行为类别. C3D网络包括8个卷积层(conv)、5个池化层(Pool)、2 个全连接层(fc)和一个输出层(Softmax).其中,所有卷积层都设置了3 × 3 × 3的3D卷积核,卷积核数量值设为64、128、256及512. 为了保留前期时间信息,除了 pool1的池化核为1 × 2 × 2,其余池化核都设置为 2 × 2 × 2.
2 视频交通状态识别C3D模型改进
2.1 调整卷积层
C3D网络研究主要面向化妆、骑车等人类动作识别,其卷积层对于交通视频状态识别不一定适用.为了有效改进模型,本文采取试错和循序渐进的思路逐步增减卷积层,测试方法如下:1) 针对conv1~conv5b等8个卷积层,在每两个相邻卷积层之间增加 1~2 个卷积层;2) 针对 conv3a/conv3b、conv4a/conv4b、conv5a/conv5b等3组连续卷积层,每组减少0~1个卷积层. 结果显示,增加或减少1~2个卷积层对模型性能改进有较明显的影响,相应可增减的卷积层位置及名称如图1虚框部分所示.

图1 调整卷积层Fig. 1 Adjustment of convolutional layers
2.2 优化平面卷积尺寸
交通视频场景复杂多样,为了获取能有效表达交通状态的视频图像特征,需要寻找合适的感受视野进行卷积运算. 平面卷积尺寸r越大,每次卷积的范围越广,计算量越大,反之,卷积范围越小,计算成本越低. 以卷积深度(每次卷积参与运算的视频帧数等于3) 为例,图2展示了平面卷积尺寸优化方法:通过改变值,每个卷积层同时以3 × r ×r的卷积核对(第帧图像,进行卷积,卷积核沿着单帧图像滑动卷积的步长.

图2 优化平面卷积核尺寸Fig. 2 Optimizing size of plane convolutional kernels
2.3 优化视频卷积核深度
3D CNN不同的卷积核深度提取的时空特征各不相同,为了提高模型精度,可适当增加卷积核深度,提取更多的历史信息. 此外,为了有效提取二维图像静态信息,也可降低卷积核深度,将二维卷积()与三维卷积()相结合.
本文卷积核深度调整方法如下:通过改变d值,每个卷积层同时以d × r × r的卷积核对帧图像~为该视频总帧数)进行卷积,沿着深度方向的卷积步长.
3 实验数据
本文视频数据来源于重庆及青岛城市干道交通监控视频,覆盖拥堵发生及消散全过程,视频分辨率为704 × 576像素. 将视频剪裁为6 s左右(约125帧)的avi格式短视频,并根据车辆密度及人工经验划分为3类典型交通状态:畅通、缓行、拥堵,分别记为4 个数据集,其中、及的并集用于模型训练和测试,,每类交通状态有48个视频;用于改进模型测试,含161个畅通视频、148个缓行视频、100个拥堵视频. 数据集制作如图3所示.图 3 中:表示第个数据集的视频数量.

图3 交通视频数据集制作Fig. 3 Making datasets of traffic videos
4 模型训练与测试分析
4.1 模型说明
本文以C3D为原型进行卷积层、平面卷积尺寸、卷积核深度的增减调优,获得了37个备选模型.对这些模型及C3D、R3D、R (2+1) D进行训练、测试和对比分析.
4.2 三维卷积模型训练

4.3 模型性能评价指标
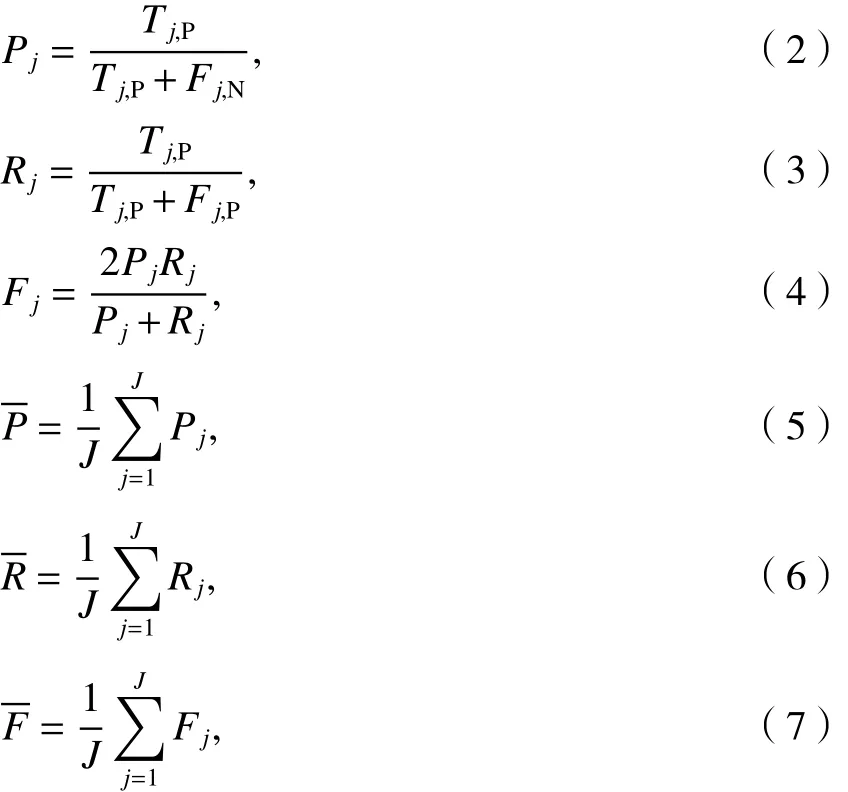
4.4 模型改进测试分析
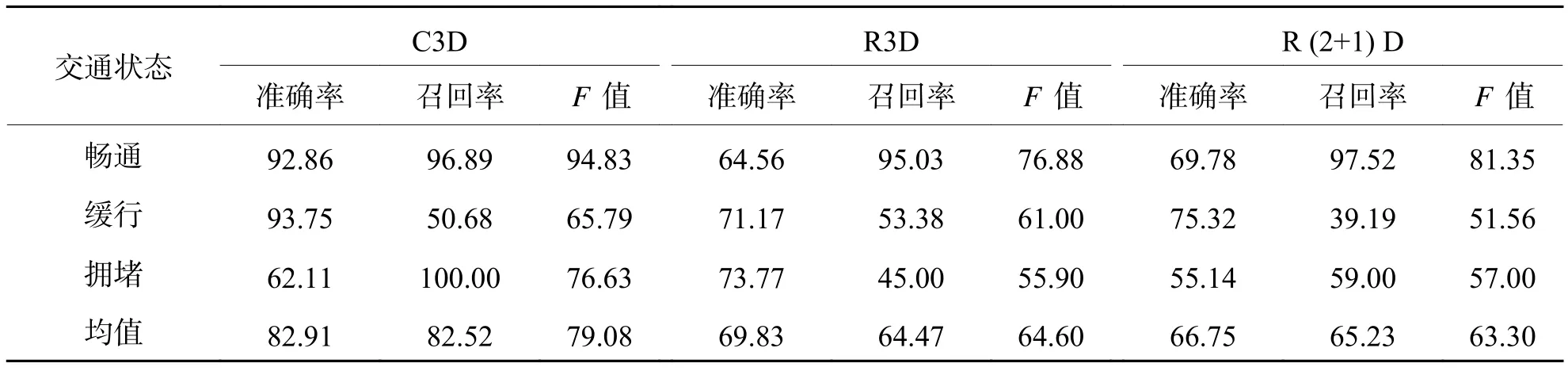
表1 既有三维卷积模型测试指标Tab. 1 Test indexes of existing 3D convolutional models %
结合表1及视频分类结果统计情况发现,C3D畅通状态识别良好(),但缓行误判为拥堵的样本较多,导致缓行召回率(50.68%)和拥堵准确率(62.11%)较低. 由此推断,优化缓行状态识别效果,将有效改善模型整体性能,后文即以此为切入点展开改进研究.
4.4.1 卷积层调整测试分析
卷积层增减是深度学习网络结构优化的首选方法之一. 本文基于C3D,尝试减少1~2个卷积层、增加1个卷积层,形成了9个备选模型,并利用数据集首先测试缓行状态识别情况. 结果显示:删减2个卷积层;增加1个卷积;删减conv3b后的模型或conv5b后的模型F值较为接近,分别为74.07%、72.78%,优于C3D的F值65.79%. 因此,删减conv4b或conv5b可提升缓行状态识别效果.
进一步测试C3D删减conv4b或conv5b后的效果,结果显示(见表2):删减conv4b后各类交通状态识别的准确率均值、召回率均值、F均值比删减 conv5b分别高出 4.33%、5.53%、4.87%,比 C3D分别高2.95%、3.38%、4.25%. 因此,后文在C3D删减conv4b的基础上进行优化.
4.4.2 平面卷积尺寸优化测试分析

表2 C3D删减conv4b或conv5b后识别结果Tab. 2 C3D recognition results without conv4b or conv5b %
图4展示了前5个较优的模型测试结果,可以看出:conv5a (3 × 5 × 5)、conv5a (3 × 2 × 2)对所有交通状态识别准确率、召回率及值大都排名前二,表明优化conv5a的r值更有提升模型性能的潜力;从F均值来看,优劣排序为 conv5a (3 × 5 × 5) >conv5a (3 × 2 × 2) > conv2 (3 × 5 × 5) > conv4a (3 ×5 × 5) > conv5b (3 × 2 × 2). 最终,conv5a (3 × 5 ×5)准确率、召回率及F值的均值分别达到86.44%、87.15%、86.02%,在C3D删conv4b的基础上进一步提升了0.58%、1.25%、2.69%.
4.4.3 卷积核深度优化测试分析
与改进平面卷积尺寸的思路一致,考虑对某一层单独增减卷积核深度进行交叉试验. 为了与二维卷积形成对为了验证增大卷积核深度的效果,取两个具有代表性的值形成了14个备选模型.

图4 平面卷积尺寸优化结果Fig. 4 Optimization results of plane convolutional size
图5 为排名前三的模型测试结果雷达图,半径方向对应各指标值,取值0~100%. 可以看出:对于3种交通状态识别的准确率、召回率、值乃至指标均值,高低排序几乎均为 conv5a (1 × 3 × 3) > conv5a(4 × 3 × 3) > conv5b (4 × 3 × 3),表明 conv5a (1 × 3 × 3)较优. 最终 conv5a(1 × 3 × 3)的均值达 91.32%,较上一步获得的最优模型 conv5a (3 × 5 × 5)高出 5.3%.
4.5 调优模型性能分析
4.5.1 视频识别效果分析
前述测试表明,C3D删减conv4b且conv5a卷积核设为1 × 3 × 3可从整体上有效提升视频识别效果,将其作为最终改进模型C3D*. 利用数据集对C3D、R3D、R (2+1) D及C3D* 进行视频交通状态识别(结果见雷达图6),可以看出,C3D* 除了缓行准确率、畅通召回率及值略低于C3D,其余指标均优于C3D;R3D与R (2+1) D各类评价指标十分接近,但明显低于C3D* 和C3D. 根据均值,模型优劣排序为 C3D* (91.32%) > C3D (79.08%) > R3D(64.60%) > R (2+1) D (63.30%).
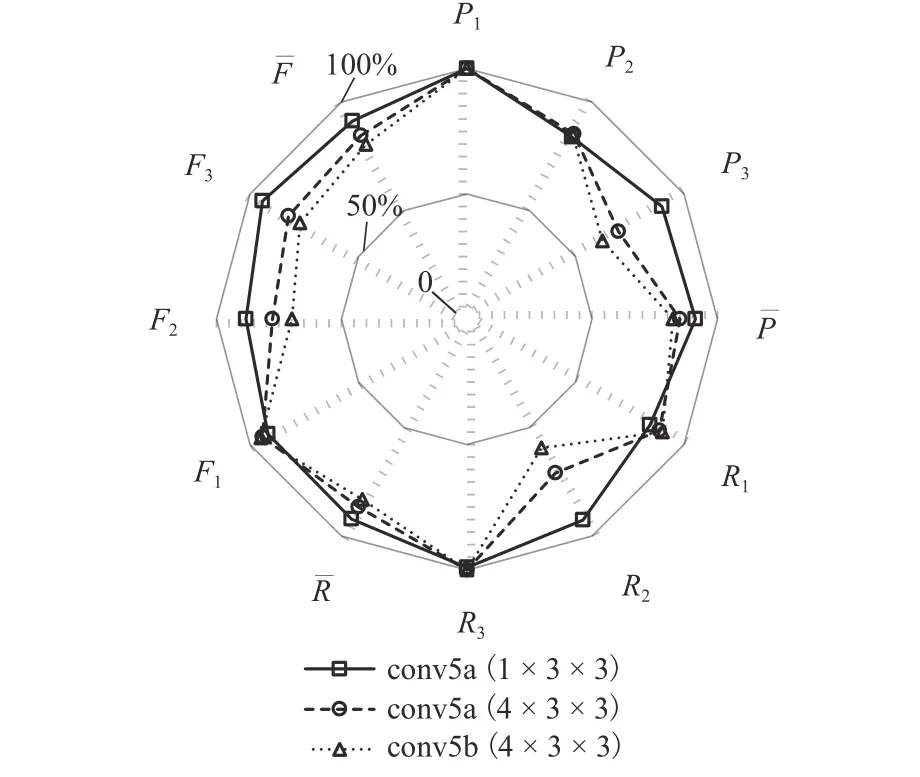
图5 卷积核深度优化结果Fig. 5 Optimization results of convolutional depth
模型识别结果如表3所示(表3中Pr为判定概率),可看出,C3D* 与C3D总体上对视频交通状态识别比较准确. 在同样准确识别交通状态的情况下,C3D* 对该状态的判定概率更大.

图6 视频测试指标对比Fig. 6 Index comparison of video tests
对比C3D* 与C3D视频识别指标(见表4)可看出,C3D* 畅通召回率、畅通F值、缓行准确率、拥堵召回率降低了1.00%~12.42%,但缓行召回率、拥堵准确率大幅提升了41.89%和27.89%,最终,C3D*的F均值较C3D提高了12.24%,表明改进效果比较显著.
4.5.2 C3D* 与二维卷积模型对比分析
利用测试集Q4对C3D* 及常见的二维卷积网络 LeNet、AlexNet、GoogleNet、VGG16 进行交通状态识别,并根据每帧图像的识别结果计算图像识别准确率、召回率和F值,见表5.
从表5可以看出,C3D* 对3类交通状态的平均识别准确率、召回率、F值为86.06%、98.49%、91.86%,F均值比LeNet、AlexNet、GoogleNet、VGG16分别高32.61%、69.91%、50.11%、69.17%,表明C3D* 识别效果显著优于这几类二维卷积神经网络模型.

表3 视频检测样例Tab. 3 Samples of video detection results

表4 C3D*指标提升(相对于C3D)Tab. 4 Index increase of C3D* compared to C3D%

表5 C3D*与二维卷积模型对比Tab. 5 Comparison between C3D* and 2-d convolutional models%
5 结束语
本文提出了3D CNN交通状态识别模型C3D*,通过调整卷积层数量和位置、优化平面卷积尺寸与卷积核深度等手段,提升视频特征检测与交通状态识别性能. 由于有效结合了图像二维信息与多帧图像三维卷积运动信息,C3D* 交通状态识别效果良好,优于 C3D、R3D、R (2+1) D等 3D CNN 模型及LeNet、AlexNet、GoogleNet、VGG16 等常用的二维卷积网络模型.
测试表明,C3D* 在道路视频交通状态识别领域具有一定的可行性与优势,但由于交通场景复杂多样,本文模型在网络结构及参数设置、与传统图像特征相结合等方面还有所不足,需进一步研究.
致谢:城市交通管理集成与优化技术公安部重点实验室开放基金(2017KFKT01)、山地城市交通系统与安全重点实验室开放基金(2018TSSMC05).
