自然语言处理在智能座舱中的应用
2021-01-30蒋彪蒋炜金鑫
蒋彪 蒋炜 金鑫
(1.南昌大学信息工程学院计算机与科学技术系 江西省南昌市 330031)(2.福特汽车工程研究(南京)有限公司车联网事业部 江苏省南京市 210000)(3.福特汽车工程研究(南京)有限公司电子电器工程部 江苏省南京市 210000)
在传统的汽车消费场景中,用户买到的只是一个纯机械的驾驶工具,用户和车辆之间的互动是有限的,完全基于机械操控的。但是在移动互联网中成长起来的一代消费者,已经严重不满足于和汽车之间纯粹的机械互动,消费者希望自己无时无刻不被包围,在驾驶座舱内获得及时满足的服务。
随着5G 和整车以太网技术的发展,在新一代的智能座舱中,人工智能衍生的技术应用将进一步赋能智能网联汽车的多感官实时交互能力,预计在2020年自然语言处理场景中可进行最基础的人机互动,面临进一步提升的瓶颈,在2030 场景中随着自然语言处理技术的突破,智能座舱将与司机进行更人性化的互动。[1]
自然语言处理一般分成词性分析,语法分析,语义分析三个级别的工作,这三个级别上这些年学术和工程上都取得了很多长足的进步。特别是涌现出了很多基于自然语言问答的智能问答产品,比如很多智能音响中就落地了语义理解技术能力。但是智能座舱的场景和智能音箱这些消费类电子还是远远不同的,受限于车辆低算力的现状和汽车联网丢包率较高的现状,智能音箱中完全依赖云端高算力算法的解决方案就不能简单适用于车端。所以本文第2 节针对该问题提出了低算力下适用于车端运行的智能问答解决方案,并在真车上取得了不错的效果。
另外一个场景,互联网产品往往需要对消费者反馈数据做自然语言分类,识别出用户的核心投诉和意见用来反馈给产品设计部门,最后形成产品闭环。我们模仿这个思路,提出针对智能座舱的用户反馈采集和分析系统,在座舱中通过语音采集用户评论,然后将STT(Speech to text)结果传给云端做文本分类,最后推送给车辆生产制造的各个部门,达成车辆设计和质量反馈的消费闭环。在这个过程中,我们需要解决车厂标注数据少冷启动,和文本分类类型歧义性的两个困难。所以本文第3 节提出了基于低数据样本的整体架构方案,并在真车上取得了不错的效果。
1 基于自然语言理解的智能问答
1.1 业务需求
根据福特的消费者调查,80%的消费者从不会阅读车辆使用手册,75%的消费者拨打400 客服电话询问的都是使用手册中的常见知识。这个时候,基于自然语言处理的智能问答机器人技术就显得非常重要,它能够极大的减少运营成本,也能够很好地提高用户体验。
传统的智能问答系统技术发展已经走过了很长的道路,常用的技术有检索技术、知识网络、深度学习三种。在美国,智能问答技术代表性的平台是苹果Siri,谷歌的GoogleNow 和微软的Cortanna,这三家都是通过深度学习模型实现。而受限于中文的语法复杂性,语义的歧义性,国内主流的智能问答产品主要都基于人工模板和智能搜索完成,比如百度度秘,小i 机器人等。

图1:车联网智能问答系统架构
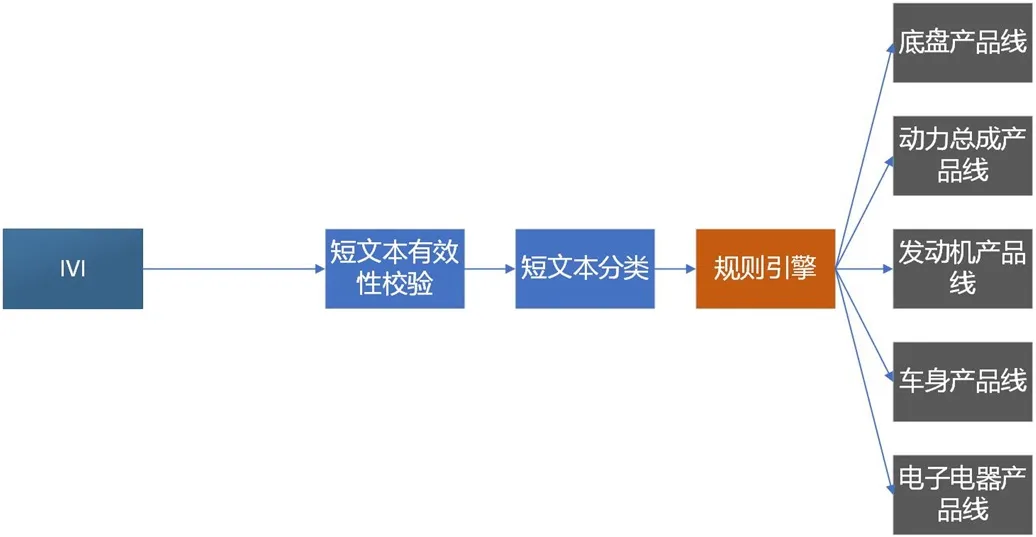
图2:智能座舱反馈分析系统架构
和传统智能问答技术相比,车联网环境下会有以下几种不同特点:
1.1.1 车内场景和其他消费场景相比,环境比较嘈杂
我们通过收集福特车主行为数据发现,86%的用户在和智能座舱语音交流的时候,是出于高速运行或者打开车窗的情况,此时的车辆胎噪和外界声响会严重影响STT(speech to text)的准确度。
1.1.2 相比其他物联网设备,车辆网络和硬件能力较弱
汽车由于一直在移动,其网络的连接可能是不稳定的,比如经过郊区、隧道等,会导致网络连接完全丢失,丢包率非常高。另外,汽车的环境场景差异非常大,比如同样一辆车,可能销售到最北端的漠河,常年零下20-30 度,可能销售到在最南部的海南,常年零上20-30 度,所以车厂在选择硬件的时候通常优先稳定性忽视性能,导致汽车的智能硬件普遍比居家用的智能音箱的硬件性能要差一些。并且由于用户买车之后通常接下来的3-5年甚至8-10年可能不换车,导致车上面的一个处理器性能就远不及日常家用电器。
本论文中针对以上问题,提出了一系列工程手段加以解决,具体请参看1.3 节。
1.2 系统架构
构建智能问答系统最关键点有两个,一个是给定问题,理解语义,返回精确的答案。另一个是收集相关原始数据,清洗加工,生成知识库。
图1 展示了针对车企的业务场景,提供一整套端到端的智能问答系统架构。该系统分成四个层次,应用层、接入层、分析层和数据层。
1.2.1 数据层
车企内对用户有价值的知识主要散落在车辆使用手册,人工客服的话术,车辆设计部门在整车设计中的设计文档。其中车辆使用手册文档结构化比较好,但是有效知识含量比较低。人工客服的话术结构化一般,有效知识含量也一般。车辆设计文档结构化比较差,很多设计部门提供不出来结构化文档,只能提供设计图纸,但是其中蕴含的有效知识含量非常丰富。
1.2.2 分析层
分析层的核心功能是分析用户传入的自然语言问题,提取意图,搜索知识库,对答案排序并且返回。
1.2.3 接入层
接入层的核心功能是将算法能力服务化,做到Inference as a service(IAAS)[2],此处不光要考虑用合适的技术将算法服务化,还要考虑大并发下服务的弹性伸缩能力,服务的鉴权和计费管理。
1.2.4 应用层
应用层的核心功能是将算法在业务场景中落地,常见的业务场景包括In-Vehicle infotainment(车机)、移动端APP、400 客服电话,让消费者以多触点访问算法能力,如图1所示。
1.3 核心技术
1.3.1 车联网嘈杂环境下的意图识别
因为前文所述,车辆行驶环境中,环境嘈杂,STT 的结果往往是不准确的。常见的工程处理办法通常是在训练数据中加入噪音来训练深度学习模型,比如别人的交谈(及回音),城市的喧闹声,自然的瀑布声等,以此来提高人工智能在这种比较嘈杂环境中的识别率[3]。
但是车企受限于法律法规问题,自然语音训练数据的采集难度和成本比互联网公司高很多。所以本文不采用在STT 环节去噪识别,而采用在文本意图识别中解决本问题。
常见的文本意图识别有基于规则模板解析、基于过往日志匹配(适用于搜索引擎)、基于深度学习分类模型三种。基于深度学习分类的模型常见有基于LSTM + attention,BERT 网络等,他们共同的特点是模型召回率很高,但是在有噪音情况下预测精度较低。而规则模板算法在小规模数据集上容易实现且构建简单,精确率和召回率也不错。[4]
1.3.2 弱网络情况下的算法本地化
为了解决汽车网络连接比较差的问题。常用的方案是,基于整车以太网架构,把算法模型部署在车内中央网关。如果网络环境比较好的话,用户语音流就直接连接云端;如果网络环境不好,将车内语音流直接传输给中央网关,在中央网关计算和推理。需要注意的是,主流车厂为了提高硬件稳定性,往往会在中央网关中选用定制的人工智能推理芯片。

表1:意图识别算法

表2:深度学习问答和规则模板问答对比
但是该方法只能适用于全新平台下设计的纯电动汽车。对于已经量产的车型,硬件架构已经无法改变,即使是后装,成本和线束变更的成本也太高。
所以,针对这些车型,我们只能基于现有算力运行本地算法包。在这些传统车型上,算力最强大的就是车载娱乐系统,以福特的Sync+车载娱乐系统举例,其硬件规格是高通820A 芯片,4 核,主频1.2G,内存4G,硬盘32G。在日常使用中,我们能发现其算力仅仅能支持简单的资讯娱乐APP,无法支持深度学习神经网络的在线推理。
因此结合以上两点,我们设计了如表1 的基于规则模板的意图识别算法,能够在低算力下运行,同时在规则中引入纠错机制[5]。
1.4 实验比较
我们利用福特Escape 车型(高通820A 芯片,4 核,主频1.2G,内存4G,硬盘32G)做真车实验,用自己设计的车内场景的问答数据七百多条做验证,如表2 比较了在不同驾驶场景下深度学习问答算法和本文推荐的规则模板算法的精确度。
我们可以看到,在地上情况下,因为网络丢包率比较低,深度学习模型在云端的准确率较高。但是当到了隧道之类的地下空间,因为网络丢包率大幅提高,车辆采用IVI 内置模型计算时,因为IVI 硬件能力受限,导致深度学习模型准确率大大降低,而规则模板算法因为算法模型轻量级,所以无论是在联网还是断网情况下准确率始终如一,效果非常稳定。
2 智能座舱短文本反馈分析
2.1 业务需求
如何收集消费者,潜在消费者和社会大众对某款车型的反馈,并且进行文本分析,将分析结果用以指导车厂车型设计和研发一直是行业内的一个重大问题。

表3:基于词性的N-Gram 文本有效性校验算法

表4:应用L2-RLR 算法分类中的偏差

表5:人工与系统处理反馈的比较
在这方面,鲍佳娜[6]和卢兆麟等[7]都针对采集互联网论坛数据做短文本分析类似的场景做过非常多详实的研究。
但是在智能座舱场景中针对车辆的反馈数据,往往会出现以下几种不同之处:
2.1.1 反馈文本中无效数据比例较高
一般来说,用户在互联网消费类网站中的评论(比如淘宝/天猫),往往命中主题,有效性非常高。但是因为车内场景的随意性,比如4S 店试驾体验,副驾驶尝试操作等原因,采集到的无效评论占比超过50%。
2.1.2 反馈文本普遍很短
因为用车环境的高速化和快捷化,我们观察到用户在车内操作评论时,留言的70%不会超过十个字。可以说是超短文本数据集。
2.2 系统架构
图2 展示了针对车辆的业务场景,提供一整套端到端的短文本分信息系统架构。
2.2.1 IVI
我们通过车载娱乐系统(IVI)收集用户反馈。具体做法是通过在语音唤醒中添加特殊的唤醒词,比如“我要吐槽”,当车载娱乐系统的麦克风捕捉到该唤醒词之后,就捕捉用户的语音流,然后调用内置的STT 算法,将语音流转译成文本,发送给云端。
2.2.2 短文本有效性校验
云端收到用户评论文本之后,首先调用短文本有效性算法,检验该文本是否有效。过滤掉无效评论。将有效评论转发给下一流程。
2.2.3 短文本分类
收到有效评论之后,做短文本多分类,将分类结果转发给下一流程。
2.2.4 规则引擎
规则引擎在收到短文本和其分类结果之后,根据业务逻辑,将该评论文本转发给各条不同的产品线,形成工单流转到具体的负责人,专人专门处理。
2.3 核心技术
2.3.1 短文本有效性校验
以下是一些福特在生产环境收集到的用户无效评论。
我打开巴巴七飞机
可特特特特怕了客厅哦QAQ 嘟嘟
可高兴没关系刚下班明显吗v 想
看了这些错误的句子之后,我们首先想到基于语法规则来解决这个问题的方案。但是发现很难建立完善的语言规则也缺乏相关的语言学知识,实现这么完整的一套规则也不简单,因此就放弃了该方案。
接下来我们想到可以基于N-Gram 的算法来学习句子通顺与否的特征,常见的做法是基于N-Gram 算法学习经过人为标注的有效文本,即按长度 N 切分原字符串得到的词段,然后分别求它们的N-Gram,那么就可以从它们的共有子串的数量这个角度去定义两个字符串间的N-Gram 距离,如此这样,就可以统计出有效文本和无效文本之间的N-Gram 距离差异,最后用于推理。[8]
但是基于词的N-Gram 算法需要海量的已标注数据集,对于数据量较少需要冷启动的车企并不合适。于是结合福特的业务场景,我们设计出了如表3 的基于词性的N-Gram 算法,通过训练数据学习词性互斥的特性来做文本有效性分类,词性种类数目很小,需要的训练数据较低,训练出的模型非常轻量级,非常适用于数据量较少需要冷启动的车企,而且对车辆运行硬件的资源要求较低。
2.3.2 短文本分类
针对短文本分类,我们直接选型采用L2-regularized Logistic Regression(二阶正则化逻辑回归SVM)算法[9],具体算法不在此赘述。
需要注意的是,在应用该模型训练的时候,我们发现,因为中文短语的歧义性,人工给训练数据打标的标准和尺度很难统一,这样会给模型训练造成数据污染。比如表4 的第2~4 行,这三条数据算法分类和人工分类都出现了偏差。究其原因,我们人为不是算法分类不准确,而是人工分类的维度不统一,导致同一句话可能会落在不同的分类区间内。
因此,我们结合福特的业务场景出发,我们不主张按照客服部门角度讲文本分类为用户问题类型,而主张将短文本分类按照车辆工程逻辑分类成,“底盘”,“动力总成”,“车身”,“车联网”等,这样有助于提供统一的尺度人工标注训练集,也助于人类对算法的理解。
2.4 实验比较
我们通过OTA 升级将该系统能力更新到福特某批次3000 多辆已售汽车上,通过采集用户反馈数据,如表5 比较了人工处理用户反馈和该系统自动化处理用户反馈的差异,可以看到该系统在较低的技术成本下取得了远远超过人工处理的准确度和业务价值。
3 总结和展望
车联网环境下的自然语言处理落地,受限于车辆硬件能力和使用环境的影响,需要海量标注数据训练,高算力推理的深度学习模型往往无法落地。因此本文提出了词典模板加关键词匹配的车内智能问答算法,基于SVM 的短文本评价分类算法等一系列轻量级模型。并且已经在福特的若干车型上落地,取得了不错的表现。
未来从工程手段上,更好的解决智能座舱下自然语言处理场景,还需要做以下几个工作:
(1)需要在整车设计中,按照全新的电子电器架构,在整车中央网关中预留出具备GPU 资源的高算力芯片,为深度学习模型落地做好硬件准备,在这方面福特下一代整车电子电器架构做了许多卓有成效的成绩
(2)引入深度学习模型压缩技术,将重量级模型按照一定规则裁剪,压缩到适合在低算力IVI上运行的合适尺寸。关于这个方向,常见的压缩技术都会对Inference(推理)精度有影响,所以如何选择适合智能座舱场景下符合业务场景需要的压缩技术是福特下一步的研究方向
