基于自编码器和改进K均值聚类的光伏组件故障诊断
2021-01-23周皖奎
杨 君,林 翀,周皖奎
(杭州华电下沙热电有限公司,浙江 杭州 310018)
0 引 言
光伏发电光伏组件多部署于地势复杂、环境恶劣的场所,依靠人工巡检的方式排查和诊断故障时效性差,难以检出故障,影响电池寿命和发电效率,甚至会引发事故。因此,需采用有效的光伏故障诊断方法,以提高故障检出的时效性和检出率,降低人工成本。
目前,光伏组件的故障诊断主要有传统巡检和智能算法等方式。人工巡检诊断方式主要有热成像法、对地电容测量法以及经验观察法等。由于它的时效性差、巡检周期长以及成本高,光伏组件的故障诊断正逐渐地被智能分析法取代。陶彩霞针对光伏阵列的常见故障类型,提出基于深度信念网络,通过故障数据的样本积累度模型进行训练,从而诊断光伏的常规故障。但是,采用深度网络对少量的光伏故障数据进行处理,容易出现模型欠拟合和难以收敛的问题[1]。Kang B K利用环境温度、光伏组件电流以及电压,提出了基于卡尔曼滤波器的故障检测模型,但模型无法稳定数据的明显扰动,导致无法检出故障类型[2]。Ding H提出了一种决策树模型检测故障和识别故障类型,其监督学习方式针对小样本的效果并不明显,且忽视了环境扰动对模型带来的影响[3]。YI Z基于模式识别方法和模糊推理系统确定光伏是否发生故障,其模糊系统的建立依靠个人经验需反复试凑,主观性较大[4]。
针对以上问题,提出了基于AE和K-Means++的光伏组件故障诊断方法,利用AE表征学习少量样本的连续参数,进行去线性化,降低参数内部的耦合性,然后通过AE压缩降维后,采用K-Means++对AE生成的降维特征进行聚类。该方法能明显降低故障类别的混淆,有效分类故障模式。
1 基础理论
1.1 自编码器
自编码器是一种能够通过无监督学习学到输入数据并高效表示的人工神经网络。自编码器包含编码器(Encoder)和解码器(Decoder)两部分,如图1所示。自编码器隐含层神经元个数小于输入层神经网络个数即可进行数据压缩和降维,通过对已有无标签的数据学习数据之间的关键表征,舍弃一些数据间共有的无关紧要的特征,从而降低在高维空间下不同类型数据特征之间的混淆。

图1 自编码器结构
1.2 改进K均值聚类
K-Means算法是解决聚类问题的经典算法,简单快速。当结构集是密集的,簇与簇之间区别明显时,聚类算法的结果较好。在处理大量数据时,该算法具有较高的可伸缩性和高效性。
传统的K-Means算法拥有许多优势,同时存在K值需要事先指定、对初始聚类中心敏感、对噪声敏感以及只能发现球状簇的缺陷。其中,初始聚类中心敏感的特性对模型影响最大。若聚类中心选取不合理,聚类会出现偏差、空簇甚至计算失败的情况,影响聚类的稳定性。合理选择初始聚类中心可以加快算法的收敛,避免聚类陷入局部最优。多次K-Means聚类取平均的方法能够在一定程度上降低其影响。但是,对于多次聚类差异较大的聚类中心,其平均值会受较大的影响。因此,考虑采用K-Means++的方式进行聚类,改进传统K-Means算法随机选取K个点作为初始聚类中心的问题,实现步骤如下。第一步,随机选取一个点P1作为聚类中心。第二步,求样本中每个点与前n(1<n<K)个聚类中心距离的和。第三步,选择距离最远的样本点作为下一个簇的初始聚类中心。第四步,重复第二步和第三步,直到找出K个初始聚类中心。
2 光伏组件故障诊断分析
2.1 光伏故障诊断步骤
基于AE和K-Means++的光伏故障诊断方法需要获取故障样本数据,通过AE降维和K-Means++聚类分析获取聚类中心及对应类别,最后利用新的故障数据诊断故障。具体步骤如下:第一,获取光伏组件原始故障数据;第二,根据原始数据集训练AE,当AE模型收敛并评估达到要求后,保存AE模型、结构以及权重;第三,获取AE编码器部分层,通过保存的模型权重将数据降维为2维,以便聚类和可视化分析;第四,利用K-Means++聚类分析AE降维后的数据集,保存聚类中心,并将聚类中心与光伏故障类别相对应;第五,获取新的故障数据,通过AE进行降维后计算降维后的数据与保存的聚类中心的距离,距离最近的聚类中心对应的故障类别即为光伏当前故障类别;第六,通过新的数据集重新更新聚类中心,使模型不断地自省和完善,提升模型故障诊断的准确率。
2.2 数据样本选取
光伏组件内部特性的改变会引起如最大功率电压、电流以及输出功率等指标的改变。理论上,光伏组件发电量的计算式为:

式中,L为发电总量;Q为斜面总辐照量;S为光伏总面积;η为光电转换效率。由于辐照、温度、积灰、蒸发量以及气压等各种外部因素的影响,光伏发电量往往没有那么多。因此,为准确分析光伏组件的故障,需综合考虑光伏组件的内外影响因素。选取最主要的输出电流、输出电压、环境温度、净辐射瞬时值、蒸发量、气压以及输出功率等内外部参数作为输入,重点分析常见的短路、开路、老化以及遮挡故障类型。选取辽宁某光伏厂家SSM235P-60型多晶硅组件,分别采集不同季节、不同辐照以及不同温度条件下的组件故障数据。每种故障数据100条,共400条故障数据,其中320条数据用于自编码器训练,80条数据用于自编码器验证和分类测试,如表1所示。
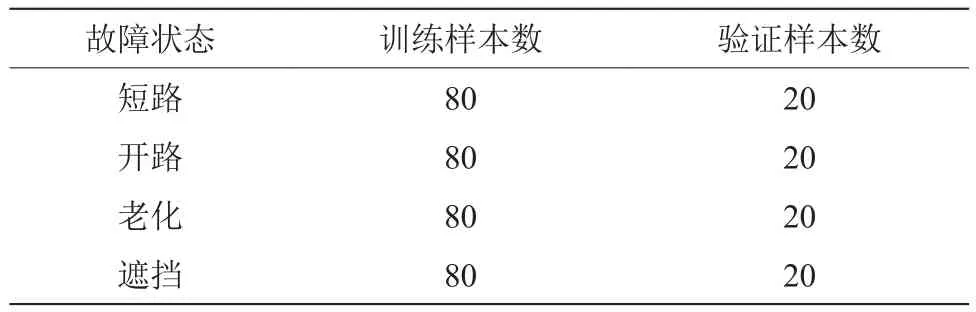
表1 光伏组件故障数据分布
2.3 自编码器训练集数据降维
光伏样本数据特征数为7。对于特征维度较小的数据样本,为防止过拟合,选取仅含一个隐含层的自编码器。为便于数据可视化和聚类分析,隐含维度为2作为数据压缩的维度。自编码器结构如表2所示。

表2 自编码器网络结构
为避免网络过拟合,提升网络的稳定性,在原始数据上增加随机扰动作为输入,原始数据作为输出,并增加L2正则化项,模型batch_size=8,epoch=100。经过100轮迭代后,网络训练结果如图2(a)所示。可见,在23轮前,模型训练损失急剧下降,随后趋于平稳。模型精度如图2(b)所示,由于添加了正则化项,验证集模型精度比训练集模型精度稍高,模型在训练集和验证集上模型精度均超过95%,验证集精度更是超过98%。由此可知,该自编码器满足对光伏组件数据特征的提取及降维要求。
2.4 故障聚类及结果分析
通过K-Menas++聚类分析主成分分析(Principle Component Analysis,PCA)降维后的数据,并利用轮廓图分析聚类的性能。如图3(a)所示,聚类分析在相应的数据集上,强行将数据分析指定对应的类别。由图3(b)可知,聚类轮廓系数远低于1,且平均轮廓系数不到0.43,说明聚类类别存在明显的重叠。
采用训练好的AE降维数据,将输入的7维数据降维为2维,利用K-Means++进行聚类,聚类结果如图4(a)所示。由图4(b)可知,它的分类内聚度总体较好,仅类别4分类内聚度较低,单聚类平均轮廓系数达到0.63,总体聚类效果较好。
取数据集中用于验证AE模型的80条故障数据验证模型,通过AE降维后求最近的聚类中心判断故障类别,其故障诊断具体信息如表2所示。除少量的开路和遮挡故障类别被分到其他类别外,该模型准确分类了短路和老化故障类别。由此可知,AE能够准确地提取故障特征,并且利用K-Means++进行聚类获取聚类中心,在光伏组件故障诊断应用中效果良好,结果如表3所示。
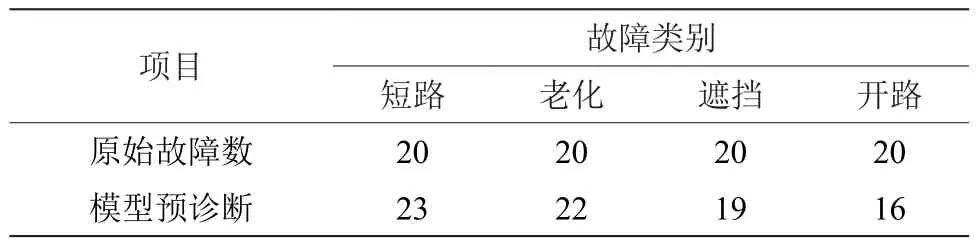
表3 模型故障诊断结果
3 结 论
本文基于AE和K-Means++算法诊断光伏组件的短路、老化、遮挡以及开路故障,分别采用AE对光伏组件这种非线性系统进行特征提取和数据降维,通过聚类可视化分析分类识别降维后的数据特征,以达到故障诊断的目的。通过数据试验和对比分析可知,AE对复杂的数据特征降维的表现明显优于PCA。通过AE降维,将电压、电流等连续呈条状的数据分布形式进行解耦和离散化,以充分满足K-Means++聚类的需求。利用改进的K-Means++,优化初始聚类中心的选取,进一步降低了不同类别之间的混淆,提升了故障诊断的准确率。
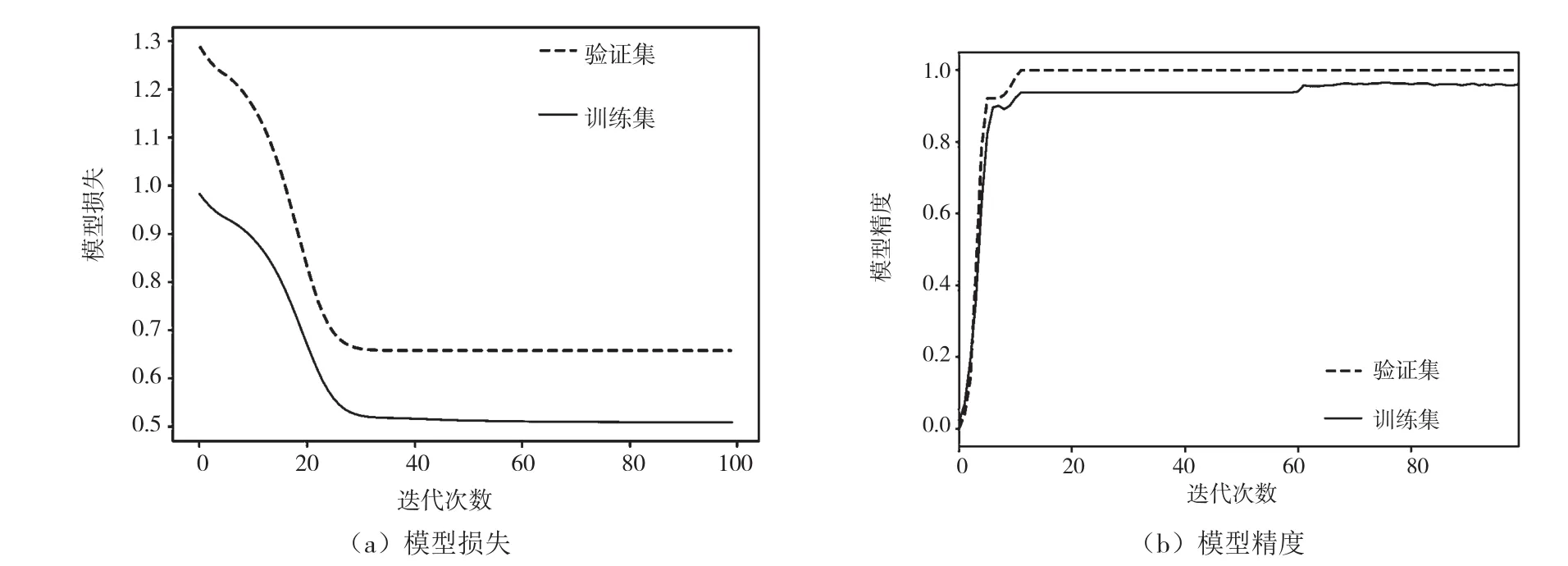
图2 自编码器训练结果
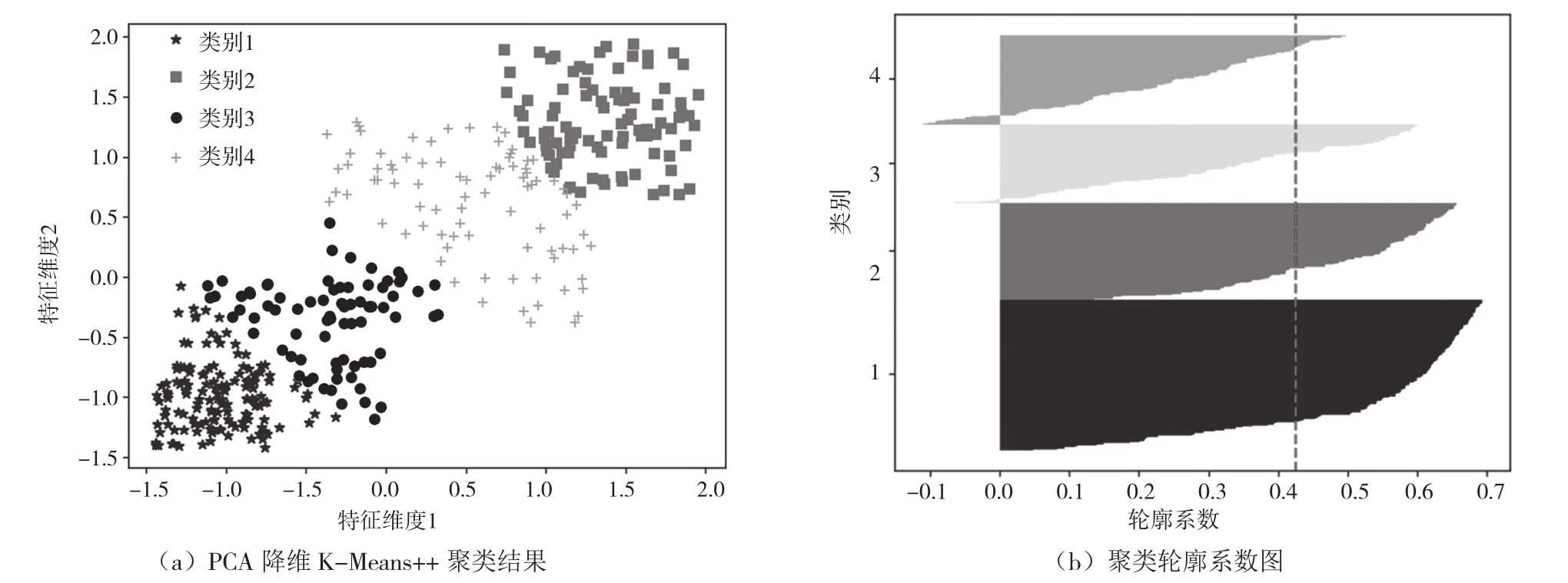
图3 数据PCA降维K-Means++聚类可视化
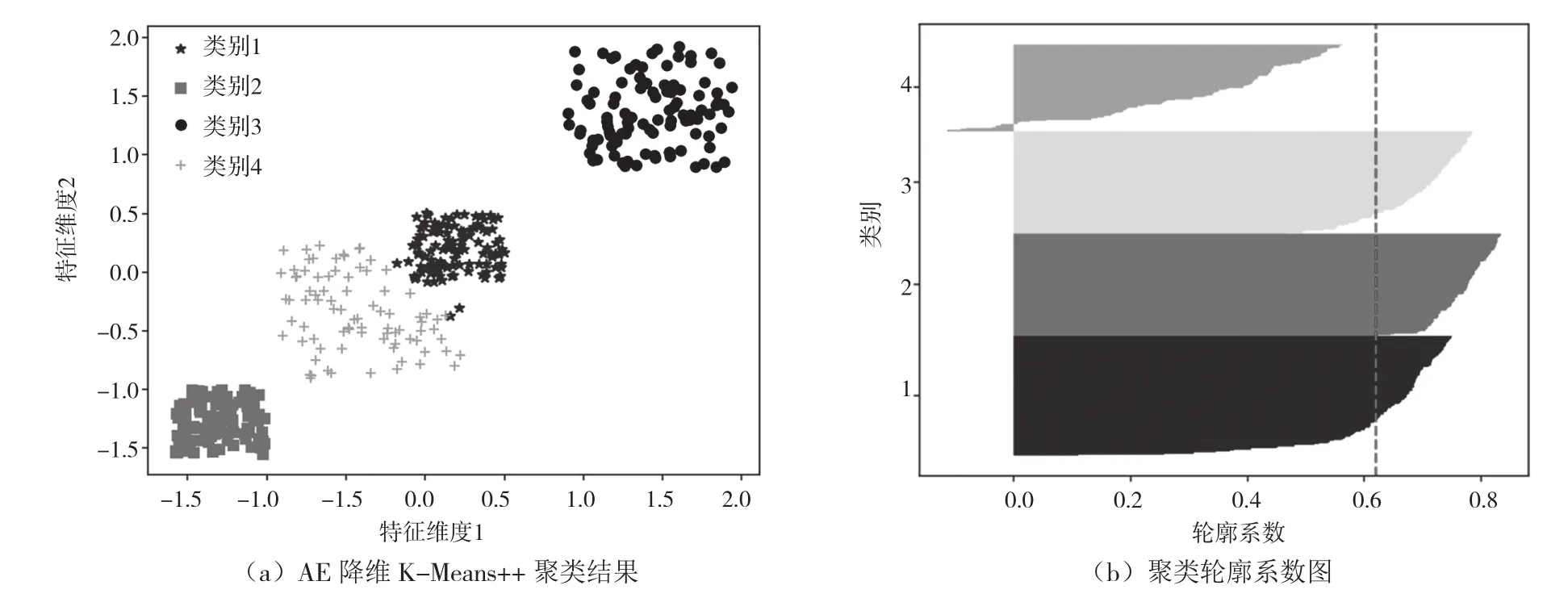
图4 数据AE降维K-Means++聚类可视化
