基于监督信号增强的唇语识别模型
2021-01-22苏渝校
苏渝校
( 广东工业大学,广东 广州510006)
1 概述
随着近几年来深度学习的快速发展,唇语识别任务越来越成为当前学术界的研究重点。由于唇语识别任务的困难性,当前学界对于唇语识别的研究普遍集中于单词级别的唇语识别,该任务是通过一个讲话者的一系列嘴唇图片,来识别出他/她所讲的对应词语。当前基于深度学习的唇语识别算法大部分以独热编码作为监督信号,通过最小化模型输出与监督信号之间的交叉熵来完成训练。这导致唇语识别算法在推理时会遇到如下挑战:
(1)嘴唇运动的多样性以及讲话者不同的发音习惯和语速,都会给识别带来困难,尤其是对于两个发音相近的词语,如果不能在特征层面上使两者具备更好的辨别性,那么误判是很容易发生的。
(2)由于光照、人脸角度等变化,导致识别时的准确率受到影响,这要求唇语识别算法需要具有较好的泛化能力。
2 相关工作
基于深度学习的唇语识别方法,根据其卷积部分对图像特征的提取方式可以分为全2D 卷积、全3D 卷积(即时空卷积)和2D、3D 卷积混合的方式。在全2D 卷积方面,Noda 等人[1]利用VGGNet 提取嘴唇特征,之后经由循环神经网络(RNN),在特定数据集上面实现了44.5%的短语识别准确率和56.0%单词分类准确率。在全3D 卷积方面,Chungg 和Zisserman[2]提出了基于VGG 结构的时空卷积神经网络,进行单词的唇语识别,在BBCTV 数据集上取得了比传统唇语识别方法更好的准确率。在3D 和2D 卷积混合的方式中,Stafylakis 等人[3]结合了时空卷积网络和ResNet34,并使用了Bi-GRU 建模上下文信息,在LRW 数据集上识别准确率是83%。
可以看出,基于深度学习的唇语识别方法,算法的主要结构都是由卷积神经网络来提取图像初步特征,再由循环神经网络建模时序信息,最后使用全连接层进行分类识别,而这些方法都是使用独热编码作为监督信号进行训练的。
而当前在深度学习的一些其它领域的研究当中,已经提出了一些取代独热编码的监督信号。例如,人脸识别领域的最新研究方向是改进监督信号来最大化分类空间的决策边界,近两年也出现了诸多关于决策边界约束的研究成果,这些基于监督信号改进的方法可以使得深度网络所提取特征在类内紧凑,在类间可分,进而提升人脸识别的效果。而在知识蒸馏的研究领域中,近两年也提出了一些训练深度神经网络的暗知识的方式,相较于常用的基于独热编码的监督信号,结合了暗知识的监督信号可以使训练的网络具有更强的泛化力。
因此,本文结合人脸识别领域和知识蒸馏领域的方法,设计一种增强的监督信号,并应用到基于3D 卷积的唇语识别算法当中,有效提升唇语识别的准确率。
3 模型介绍
3.1 模型结构
本文的唇语识别模型为“主干- 脖子- 分类头部”的结构(如表1),模型的“主干”部分采用时空卷积的方式进行图片序列的特征提取,由3 个3D 卷积层构成;在这之后,搭建两个单隐层的GRU 作为模型的“脖子”,目的是将所有帧的图片特征整合联系起来。模型的“头部”是一层没有偏置的全连接层,实现唇语识别的多分类任务。此外,在“主干”和“脖子”中间接了两层全连接层,进行特征的降维。

表1 模型结构配置
k、s、p 分别代表卷积核尺寸、滑动步长和填充尺寸
3.2 监督信号增强
3.2.1 边缘裕度
目前的唇语识别模型基本上都是使用独热编码作为监督信号,配合以交叉熵损失函数进行模型的训练。但是使用交叉熵损失训练的模型来识别的时候,容易对发音相似的词语产生误判,例如本数据集的“知识”与“只是”这两个发音相近的样本。
通过分析发现,多数情况下模型在正确的类别上预测了一个数值第二大的概率输出,而在一个发音情况相近的类别上预测了最大概率输出。可以看出使用交叉熵作为损失函数时,模型对一些唇语图片序列的识别并不鲁棒,容易误判为发音相近的其它词语。这种错误识别的原因是因为模型没有能力可以有效地区分开发音相似的词语,即两个发音相似的词语,它们在网络的全连接层输入处的特征向量非常接近,所以对于这类型的样本,全连接层分类器的泛化力不足。
针对交叉熵损失函数学习到的特征分辨性不够强这一点,人脸识别领域的最新研究成果是边缘裕度[4],通过对损失函数引入边缘裕度,来增强模型训练的监督信号。同理,本文引入具有决策边界惩罚的损失函数,通过约束各类别的决策边界,可以使得各个类别的特征在类内紧凑,在类间可分,以此提高了唇语识别模型在识别发音相似的词语时的准确率。具体做法是将无偏置的全连接层输出WTyixi视为一个余弦值,通过求余弦函数的反函数,在决策面上添加一个角度m 的边缘惩罚,从而使得决策面更加规整。
3.2.2 软化标签
深度学习唇语识别模型使用独热编码的训练标签,由香农信息熵可知,标签值为{0,1}的独热编码信号携带的信息熵少于软化标签信号所携带的信息。当使用独热编码时,模型训练时只关注于是否将当前词语正确分类,但是无法关注到其它的发音相近词语的概率输出是否合适。在知识蒸馏领域的研究中,其它类别上的概率输出被称为暗知识[5]。
为此,本文使用知识蒸馏的策略得到软化的训练标签,使用带有暗知识的软化标签作为新的监督信号,训练一个再生的唇语识别模型。本文设计一种“课程学习”的方式进行暗知识的迁移:
步骤1:以加入了边缘裕度的交叉熵作为损失函数训练模型T;
步骤2:训练再生模型S。具体方式为,训练时对于同一个样本,以模型T 的输出概率分布作为监督信号,以L1 损失训练模型S 的输出分布;
步骤3:使用加带边缘裕度的交叉熵损失继续训练模型S,得到最终的模型。
本文通过先行训练好的模型T 作为教师,将教师的输出分布作为软化标签,训练学生模型S,这样可令模型S 在训练初期就关注学习暗知识的部分(即其它词语的输出概率),使得模型最终可以到达一个更好的极值点。
本文通过边缘裕度和软化标签得到的监督信号增强的唇语识别模型如图1 所示。
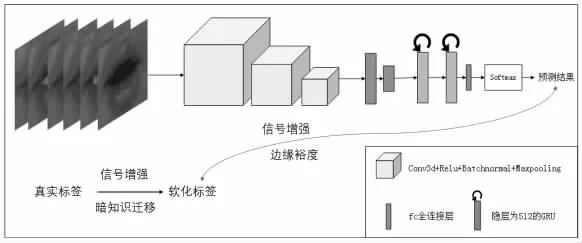
图1 监督信号增强的唇语识别模型
3.3 实验结果
本文使用DataCastle 平台的中文唇语识别数据集进行实验,该数据集采集了10 个讲话者讲313 个不同的中文词语的视频并截帧作为样本,样本序列的最长长度为24 帧。实验结果如下:

表2
4 结论
唇语识别是一项颇具难度的任务,光照、人脸角度的变化,讲话者嘴唇形状、说话习惯的不同给唇语识别任务的准确性带来挑战。基于深度学习的唇语识别模型在识别一些发音相近的词语时容易发生误判,本文通过引入知识蒸馏技术获得软化训练标签,加入边缘裕度获得增强的监督信号,有效提升唇语识别的准确率。
