基于自监督学习的卷积神经网络在CT 图像中的肝脏自动分割研究
2021-01-22刘祥强何多魁王文瑞黄建民
刘祥强 李 强 何多魁* 王文瑞 黄建民
( 兰州财经大学 信息工程学院,甘肃 兰州730020)
1 概述
肝癌目前是世界第四大致死癌症,在肝脏的临床诊断治疗中常常需要有经验的医生勾画出肝脏及肝脏肿瘤的轮廓等等信息,及其耗时耗力,因此此类工作亟需一种全自动的方法能帮助医生减少工作量。现有肝脏肿瘤分割方法中,都将肝脏分割作为肿瘤分割的前提工作,因此精准的肝脏分割可以有效的提高肝脏肿瘤的精确性。
由于肝脏在CT 图像中与邻近组织灰度值接近且形状相似,精准的分割肝脏成为了十分具有挑战性的任务[5]。传统的基于机器学习的方法例如阈值法、区域生长法[6]及其他一些方法,并没有完全摆脱人工参与,例如在区域生长法中的种子点选择对最终分割结果影响往往很大[3]。与自然图像相比,医学图像往往数据更难获取尤其是金标准的获取,解决医学影像任务的深度学习模型缺少类似于Imagenet 那样可供预训练的数据集,自监督学习这种利用数据本身的结构或者特性解决一些前置任务的学习办法可以让模型得到一个较好的预训练参数[9]。
2 相关介绍
2.1 基于深度学习的方法
2006 年深度学习理论被提出后以及计算机硬件条件的提升,由于其强大的特征学习能力,卷积神经网络迅速发展。2015年提出的U-net[7]网络结构将图像分割领域的精度推到的一个新的高度,Ben-Cohen[2]将卷积神经网络应用于肝脏与肝脏肿瘤的中,取得了不错的效果。H-densenet[8]将三维特征与二维特征融合。以上网络都有一个共同的特点就是都没有权重的初始化或者采用预训练模型,无法让网络从一个更优的起点开始训练。
2.2 自监督学习
自监督学习属于无监督学习方法中的一个分支,利用数据本身特有信息和结构,设置不同的辅助任务,让模型尽可能拥有更多的知识储备。计算机视觉当中主流的自监督学习任务主要分为两类,生成式任务和对比式任务。
3 方法
3.1 训练自监督模型
如图1 所示,同时输入三张相邻切片,每一次输入模型的图像大小以及通道数为256×256×3,随机打乱相邻切片排列顺序,模型通过预测被打乱的切片的顺序,学习到每张切片的特征,。连续三张图片顺序打乱的方式有六种,随机生成一种顺序打乱方式并将该打乱方式对应的编号变成one-hot 编码形式作为金标准,将被打乱顺序的三张切片图像放入分类器,这个分类器由U-net 网络的下采样部分以及一个MLP 层组成,MLP层的作用是将CNN 网络学到的图像特征映射到一维空间,代表着对于改组数据顺序排列的预测结果,得到的结果与对应打乱方式的编号的one-hot 编码求交叉熵损失之后反向传播同时优化这个分类器,交叉熵损失函数公式如下:
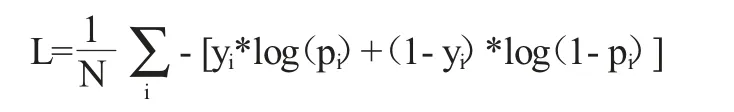
其中pi表示第i 个样本属于正例的概率,yi表示第i 个样本的金标准,由此可以看出当金标准为正例时,pi值越大,总体损失L 的值越小,以此达到优化网络的目的。本文实验中的顺序预测属于多分类问题,一共有六类,每一种连续三张图片顺序排列方式算一类。

图1 自监督训练流程
3.2 参数迁移
在分类器训练完毕后,将该分类器的权重迁移到分割模型当中。在分割肝脏的时候,为了利用到CT 图像数据中z 轴上的部分信息,依然采用连续输入三张相邻切片,金标准以中间一张切片对应的金标准为准。在将分类器参数迁移到分割模型中的时候,由于分割模型无全连接层,分类器中的MLP 层被丢弃。
4 实验与结果
4.1 数据预处理
本文实验所使用的数据来自于2017 MICCAI LiTS 肝脏肿瘤分割挑战赛公开数据集。该数据集CT 图像数据由多部机器产生,所以CT 图像之间的差异变化较大,层内分辨率的变化从0.55mm 到1.0mm,序列层间距离从0.45mm 到6.0mm。该数据中共有131 例数据拥有标签,每例数据从拥有三百多张到一千多张切片不等,在数据集划分中,我们将前106 例数据作为训练集,将后25 例数据作为测试集。
4.2 评价指标
Dice 系数是一种集合相似度度量函数,通常用于计算两个样本的相似度,取值范围在[0,1]。
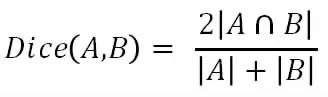
在本实验中,A 代表医生手动标注的属于肝脏区域的像素点集合,B 属于模型预测的属于肝脏区域的像素点的集合。由公式可以看出,当A 与B 集合之间的误差越小时公式中的分子越大且分母越小,从而Dice 值越大。
4.3 实验参数设置
在本实验中,分类器训练使用交叉熵损失函数,优化器选择Adam 优化器,学习率为10e-5。在分割模型训练中损失函数选择Dice 损失函数,优化器选择SGD 优化器,学习率为10e-3,将验证集上表现效果最好的权重保存用于测试。
4.4 实验结果展示与分析
由于加入了自监督学校过程中学到的额外语义信息,让肝脏分割网络从一个拥有一定知识储备的起点开始训练,从模型的预测结果来看如图2,经过自监督的模型在预测结果上在一些细节的地方相对于没有经过自监督学习的模型表现要更加优秀,模型的精度得到了一定程度的提高。其中SSU-Net 代表我们本文中所提出的模型。
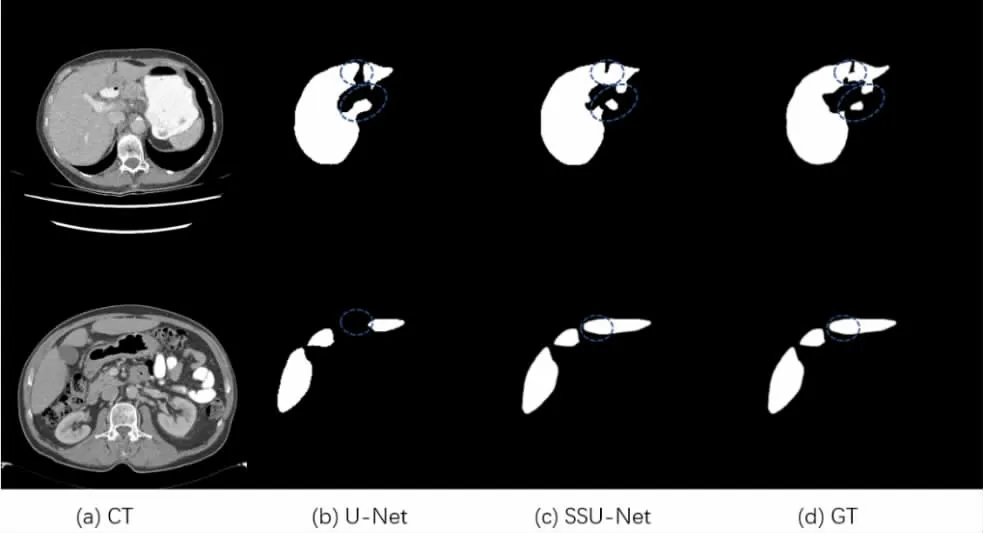
图2 a 代表输入模型CT 图像,GT 为该CT 的金标准
为了验证本文提出方法的有效性,我们将不同模型分别在同一测试集上进行验证,结果如表1,。结果表明,利用预测切片顺序这种自监督方法可以有效的提升模型的性能。

表1
5 结论
本文所提出的利用预测切片顺序来进行自监督的方法为模型预训练提供一种通用的思路,虽然在肝脏分割中与世界最好的实验结果相差一段距离,但通过使用更好的网络结构和一些数据增强操作还是可以继续提升指标的。
