基于LSTM和LightGBM组合模型的商户异常交易行为检测模型构建
2021-01-22陈泽瀛陶森林蔡朝辉
陈泽瀛 陶森林 蔡朝辉
(银联商务股份有限公司,上海 201203)
0 引言
近年来,我国经济快速发展,居民消费水平也日益增长,商户数量也在急剧增长,尤其是中小微商户的数量不断提高。但是,伴随着消费金额、消费笔数的连续上升和支付方式的不断丰富,消费欺诈行为也呈现多样化发展,主要表现为套现、挪用POS机从事赌博等非法行为和刷单等不同形式。每年该类产业链造成的金融损失超过千亿元,同时还导致了一系列的社会经济问题[1-3]。
目前主流的风险防控方法主要包括黑名单系统、专家规则系统和机器学习特征模型。然而,黑名单系统强依赖于黑名单数据库信息和外部数据,对于新的风险案例识别效果较差;专家规则系统主要依赖于金融机构的业务人员经验积累,好处是因为是经过不断迭代验证的专家规则,一般效果不错,但是对于新业务的迁移性较差,规则的积累需要较长的时间周期和较高的人力成本,且专家规则监控的特征维度有限、泛化能力较弱;机器学习特征模型是目前比较热门的风控研究领域,已经成为金融反欺诈的主要手段之一,具有特征覆盖广、数据处理能力强、对业务能力的要求也相对较弱的优势。文献[4]提出了一种基于滑动时间窗口的互联网金融反欺诈检测方法,并在网络支付的数据集上验证了其有效性;文献[5]介绍了兴业银行基于大数据技术,提取业务特征,将移动互联、大数据、人工智能等新技术与欺诈风险防范有效结合,提升了欺诈风险的侦测能力及处理效率;文献[6]提出了将GBDT算法应用于银行卡欺诈侦测领域,并以Bagging的方式对模型进行了组合,实验表明模型效果显著;文献[7]通过建立图拓扑特征体系框架和机器学习的异常检测算法,对营销欺诈团伙化网络进行了智能化侦测,模型效果比传统模型具有较大提升。
在风险欺诈检测机器学习算法的有监督学习建模中,大多数处理方法主要以提取业务特征,然后训练某个机器学习算法建立模型为主,常用的机器学习算法有决策树、随机森林、SVM、XGBoost等。我们的目标是学习一个在各个方面都表现良好的稳定模型,但是实际情况通常并不理想,上文提到的研究都取得了良好的欺诈侦测效果,但是对于一些临界样本的数据关注较低。另外,目前常见的机器学习风控特征模型多不关注样本数据之前的时序关系,直接对样本shuffle处理后训练模型,忽略了样本数据之间很重要的时序特征。
近年来,以长短期记忆网络(LSTM)为代表的深度学习算法在时间序列领域取得了较为广泛的应用,LSTM网络可以充分挖掘时序数据之间的内在关联,与CNN组合后的深度学习网络具有更加强大的特征提取能力和分析推理能力,但当特征为非连续数据时,预测精度不高[8]。此外,梯度提升机(GBM)模型的相关改进算法也有着不错的效果,例如,LightGBM算法具有速度快、效率高、占用资源少、支持并行处理等优点,但缺乏对时间序列的整体感知能力[9]。
为了克服单一模型在预测精度上的不足,组合模型的建模方法应运而生。组合模型的思想是综合所有模型的预测结果,如果一个模型对于某个样本的预测给出了极高的概率值,这样即使另外一个弱分类器得到接近阈值的错误预测结果,前一个模型的强预测结果也可以纠正此错误。
本文采用循环神经网络LSTM+LightGBM组合模型的方法,将海量的商户交易数据(交易金额、交易笔数、交易时间、是否周末或者节假日、历史同期数据等信息)按照信用卡、移动支付等交易方式处理特征组后作为输入特征,分别输入神经网络模型和LightGBM模型进行训练,在预测阶段则综合两个模型的预测结果。该组合模型能够结合两种模型的各自特点,既可以挖掘时序数据之间的内在联系,又可以避免非连续性特征对预测结果的影响。测试结果表明,本组合模型能够降低单一模型在特殊场景下的误差,具有更加稳定的预测效果。
1 基于LSTM网络的时序交易异常检测模型
1.1 LSTM网络模型
LSTM网络(长短记忆的时间递归神经网络)是RNN网络(循环神经网络)的改进版本,RNN网络虽然也可以学习序列模型,但是因为在RNN中损失传递不仅存在于层与层之间,也存在于每一层的样本序列间,随着层数的增加,反向传递的损失数值会越来越小,所以RNN无法学习太长的序列特征。LSTM通过刻意的设计来避免长期依赖问题,其结构示意图如图1所示。
LSTM的网络结构引入了一个叫做细胞状态的连接,这个细胞状态用来存放想要记忆的东西,同时在里面加入了3个门:遗忘门、输入门和输出门。
遗忘门:该门决定模型会从细胞状态中丢弃什么信息,计算方法如下:

图1 LSTM网络结构

输入门:输入门其实可以分成两部分功能,一部分是找到那些需要更新的细胞状态,另一部分是把需要更新的信息更新到细胞状态里,计算如式(2)和(3)。
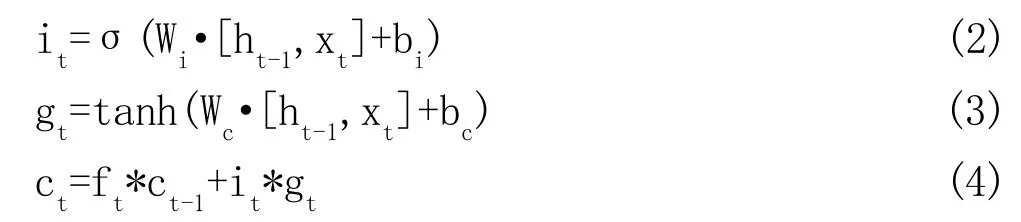
输出门:在输出门中,通过一个Sigmod层来确定哪部分的信息将输出,接着把更新后的细胞状态通过Tanh进行处理(得到一个在-1~1之间的值)并将它和前面提到的Sigmod门的输出相乘,得到最终的输出。

1.2 基于LSTM网络的交易异常检测模型
LSTM网络作为一个对时序敏感的神经网络,可以弥补大多数机器学习算法和CNN网络对于时序数据处理的缺陷。鉴于商户当天的交易和前一段时间的交易趋势有较强的关系,因此我们选取预测当天前30天的交易数据作为输入序列,为了能够得到更好的模型效果,我们从多维度提取每日交易信息特征,主要包括:交易金额、交易笔数、交易时间等信息,具体如表1所示。
考虑到模型准确性和数据样本的不均衡,如果一个商户在某天发生了异常交易,则在30天的滑窗过程中,只要包含了该天的样本数据,则都认为是正例样本。此外,在训练之前还需对所有特征进行归一化处理,对于笔数、金额数据直接采用min-max归一化处理:

对于日时间和月时间直接根据自然规律最大值归一化,对于是否周末和节假日特征采用哑变量处理,即0表示非,1表示是。
鉴于CNN在特征提取方面的优势和激活函数在非线性方面的良好表达能力,以及众多经典神经网络模型在CNN+LSTM组合后的良好效果,因此在LSTM网络之前增加了三层CNN网络用于提取特征,激活函数都选择ReLU函数。最后,在LSTM层后,添加一个Dense输出层和Softmax完成二分类任务。网络结构如图2所示。
2 基于LightGBM算法的交易异常检测模型
2.1 LightGBM算法
LightGBM(Light Gradient Boosting Machine)是一个基于决策树算法的提升框架,因为其采用了Histogram和Leaf-wise决策树优化算法,具有训练速度快、准确率高、支持分布式、内存占用率低等优点,能够处理规模庞大的数据集,可用于排序、分类、回归以及很多其他的机器学习任务中。
2.2 基于LightGBM的交易异常检测模型
因为LightGBM不同于LSTM的时序敏感特性,在1.2节列出的特征提取基础上,LightGBM补充了一些其他的统计特征,主要包括:过去一个月的日平均交易金额和平均笔数、过去一周的日平均交易金额和平均笔数。
为了确认提取的特征信息是有意义的,同时降低计算成本,需要剔除意义不大或者高度相关的特征。通过计算不同特征之间的相关性,对于两个特征之间的相关系数大于等于0.75,则认为两个特征之间存在高度相关,保留业务解释上更合理的特征,筛除其他高相关特征。

表1 日交易流水信息初始特征
3 交易异常检测组合模型实验
3.1 加权组合模型
在第2章和第3章中,我们分别建立了两个基于CNN+LSTM和LightGBM的检测模型,在合并预测结果的过程中,鉴于两种模型在处理数据过程中的不同优势,我们设置了一个权重系数α来将两个预测结果进行线性组合:

其中o1是CNN+LSTM模型的预测概率,o2是Light GBM模型的预测概率,o是最终的预测结果,α的值有最终的评价指标确定,即选择在验证集上表达最好的α值。组合模型的训练和预测流程如图3所示。
3.2 实验数据
考虑到行业差异的影响和数据连续性,本文从银联商务在江浙沪地区的餐饮行业收单商户中随机抽取了部分商户在2017~2019年间的部分交易流水约100万条样本数据作为实验数据,考虑到节假日等特征要素,主要抽取了1~5月和9~12月的流水数据。数据划分按照7∶2∶1的比例分为训练集、验证集和测试集。
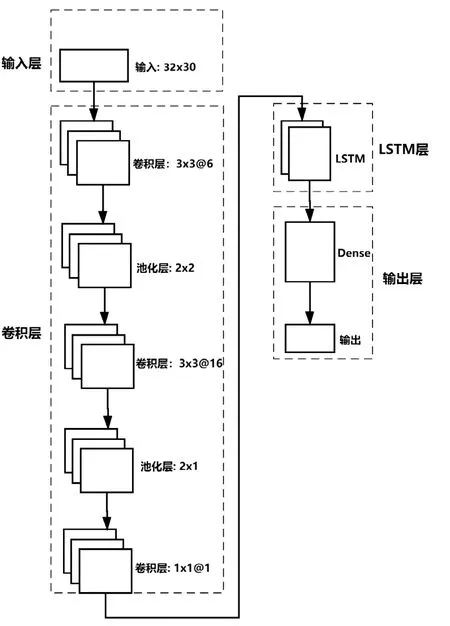
图2 基于LSTM网络的交易异常检测模型网络结构
3.3 特征筛选
LSTM模型因为有CNN作为特征提取基础,因此不需要做太多处理。LightGBM模型在训练之前需要做相关性分析,丢弃高度相关的特征数据。
计算发现,交易总笔数X9和移动支付笔数X24的相关性为0.81,这也与移动支付方式在市场上的逐渐流行现象吻合,尤其是在长三角地区,考虑到在以后的时间移动支付方式会更加普及和数据表达能力,剔除了移动支付笔数特征数据。
3.4 模型训练
LSTM模型迭代次数为300,初始学习率为0.01,每100个epoch学习率衰减10倍,训练loss衰减如图4所示。LightGBM模型的训练通过大数据环境的PySpark组件完成,Apache Spark是一个快速的分布式实时处理框架,它通过内存计算(区别于传统Hadoop的MR方式)以实现实时分析数据。
3.5 组合模型系数α
在训练集上完成模型训练的任务后,就可以在验证集上调试组合系数α了,本文选取F1值作为评价指标。F1值是综合P(precision)和R(recall)两个指标的评估指标,用于综合反映整体的效果。

图3 组合模型流程

其中TP(True Positive)为真正,即实际值为1,预测值也为1;FN(False Negative)为假负,即实际值为1,预测值0;FP(False Positive)为假正,即实际值为0,预测值为1;TN(True Negative)为真负,即实际值为0,预测值为0。在验证集数据集上的实验组合系数α和F1值变化曲线如图5所示,实验结果发现当α为0.31的时候F1值最大。
3.6 测试对比
本文共选择了十万条测试数据作为测试样本,单独使用LSTM模型、单独使用LightGBM模型和组合模型的测试结果如表2所示。
从表2中可以看出,与独立模型相比组合模型的F1值最高,也比传统专家规则的效果更好,且不仅对时序敏感,也可以处理大批量数据,可作为金融机构风控系统的补充模型。
4 结语
本文提出了一种基于LSTM网络和LightGBM算法组合模型的商户异常交易行为检测模型,组合模型不仅可以弥补传统专家规则和机器学习算法对于时序不敏感的不足,而且可以批量处理多维特征数据,与独立模型相比,也取得了更高的预测精度,尤其是对于临界样本的识别更为有效。但模型效果仍然有很大的提升空间,尤其是获取更加精准的训练数据(负例样本中隐藏了许多未知的正例样本)。另外,探索更多模型的多种组合方式也值得我们进一步挖掘。

图4 LSTM模型的训练loss
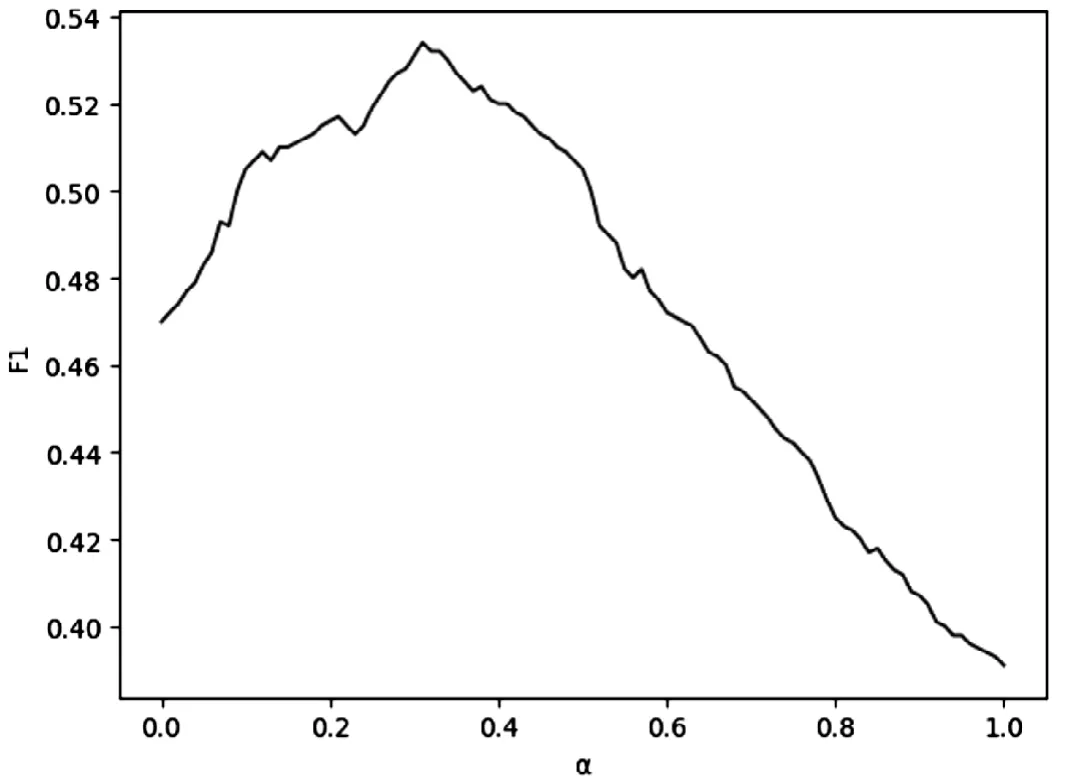
图5 α-F1曲线

表2 不同算法测试结果
