基于异构多核平台的数据传输方法研究与实现
2021-01-20付建国
谭 磊 李 益 付建国
(中车株洲电力机车研究所,湖南 株洲412000)
1 概述
变流器控制平台作为一个高性能实时控制系统,其硬件架构中通常包含多块不同的控制芯片,一块控制芯片往往又包含多个内核。而整个控制平台通常只有一个网口与外界进行交互,这就必然使得数据需要在多个内核之间经过冗长的数据链路大范围迁徙。
然而,众多不同架构的CPU 一起工作,并且它们的系统频率、程序周期、通信接口各不相同,如何保证各个CPU 之间数据实时可靠传输成为一个关键问题。
变流器控制平台的数据在控制器正常高速运行时周期性的产生和传输;主要包括控制字、波形监视和故障记录等数据;其特点是,单包数据尺寸小,传输频率快,对实时性和同步性要求高。
2 核间数据传输方案设计
核间通信是多核芯片和多芯片平台设计都必然会考虑的问题,通常,核间和芯片间的物理通信链路已经由芯片厂商或者硬件设计人员铺设好。
对于变流器控制平台而言,CPU 多数都在运行实时控制程序,并且控制周期各不相同。如何利用已有的物理通道,设计合适的数据传输方法,在不中断CPU 实时控制时序前提下,满足大量数据在不同时钟域之间的可靠同步传输是问题的关键。
2.1 IPC 传输机制
在多核芯片中,通常厂商会集成IPC 作为内核之间的通信途径。IPC 结构图如图1 所示。
IPC 模块通常是单向通信的,要实现两个CPU 之间相互通信需要两组对称IPC 模块相互配合。当CPU1 需要向CPU2 传输数据时,其流程如下:
2.1.1 CPU1 先将数据写入IPC_RAM中。
2.1.2 设置相应的IPC_Reg 寄存器组。
2.1.3 中断通知CPU2 数据已经发送完成。
2.1.4 CPU2 响应中断,并从IPC_RAM中读取数据缓存至本地等待程序使用。
2.1.5 CPU2 清标志,告知CPU1 读取完成。
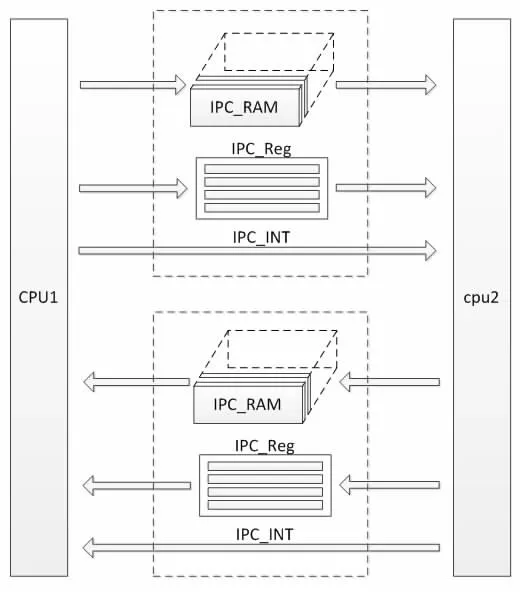
图1 IPC 结构图
由于不同CPU 的程序运行周期不同步,当CPU1 发完数据之后,CPU2 并不能立刻将其读走,所以有可能造成旧数据被覆盖或者新数据无法更新。对于该问题,IPC 是以中断的方式进行处理的,CPU1 可以通过中断使CPU2 立刻响应并将数据读走。
然而,变流器控制平台作为一种实时控制平台,CPU 内部运行的控制程序的优先级无疑是最高的,不允许被其它任务打断,从而影响控制时序。并且,IPC 只存在于同一芯片中不同内核之间的通信,而异构多核变流器控制平台中,存在多块芯片多个内核,更多的时候需要在不同芯片的内核之间进行通信,而芯片之间并不存在IPC 机制。故而,单纯的使用IPC 通信,并不能解决多芯片、异构多核的变流控制平台跨时钟域内核之间通信问题。
2.2 传统FIFO 传输机制
随着半导体工艺的发展,单片SOC 上集成的电路越来越多,很多芯片都在CPU 外围集成了多种外设接口,然而高速的CPU 与低速的外设接口之间也同样存在速率不匹配的问题。
为解决高速CPU 与低速外设之间的速率不匹配问题,芯片厂商通常会在两者之间引入FIFO 缓冲区机制。当CPU 需要发送数据时,只要发送缓冲区未满,则直接往里填充即可,无需考虑外设接口的当前状态。而外设只需判断发送FIFO 里是否有数据,然后不断的往外发送即可。接收也是同理,外设将接收到的数据先存入接收FIFO 中,而CPU 只需在空闲时来读取即可。
FIFO 的引入,很好的解决了CPU 与外设间速率不匹配问题。但是该机制是以单个字节或者字为单位,不能实现多路数据之间的同步传输,并且需要硬件FIFO 控制器支持,不能直接用于异构多核变流器控制平台中内核间数据互传。
3 基于块操作的FIFO 缓冲区
对于多核芯片的CPU 之间通常存在共享存储区域,这使得两个CPU 之间可以进行数据交互。对于不同芯片之间,通常会采用双口RAM进行粘合,或者通过EMIF、UPP、EMB 等总线访问FPGA 构建的共享存储区来进行数据通信。
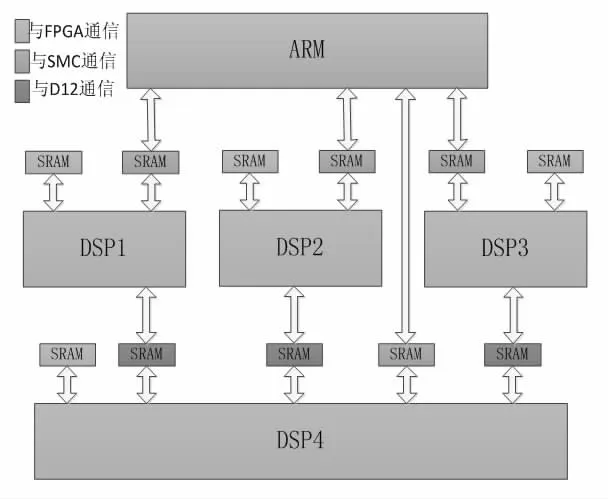
图2 某控制平台A 结构图
如图2,列举了某种控制平台结构。不同的平台、不同的芯片、不同的接口使得通信方式五花八门,很难完全统型。
并且,在实际应用中,共享存储区域两侧CPU 的读写权限并不是完全对等的。这些特点都导致很难使用一个统一的数据传输方法以适应所有的平台。
然而,通过研究每一种通信方式的特点以及总线接口的特性可以发现,无论CPU 采用的何种总线接口,包括EMIF、UPP或EMB 等,忽略它们的各自的物理特性,他们的通信数据最终都将映射到CPU 的内存区域。
基于此,本文提出了一种异构多核平台跨时钟域数据传输方法——基于块操作的FIFO 缓冲区。该方法适用于不同的物理接口,可实现不同运行周期CPU 之间的数据稳定传输,并且不需要通过中断打断接收方实时控制任务。在具有乒乓操作的优点基础上提高了存储空间利用率和传输效率。
如图3 所示,在共享RAM 区域开辟n 个缓冲块,缓冲块的大小取决于CPU 每个周期传输的数据量,n 的值由通信双方最大执行周期的倍数决定:

其中:
Tr_max为接收CPU 程序最大执行周期;
Tt_min为发送CPU 程序最小执行周期。
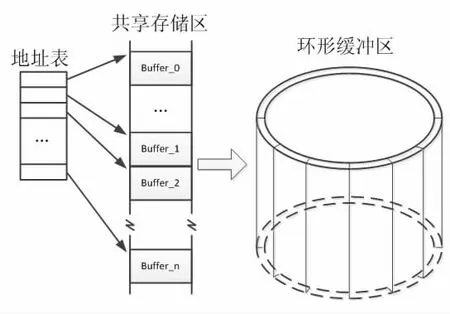
图3 环形缓冲区
n 个缓冲块不需要连续,只需将他们的首地址存入地址表即可,这样即可利用内存中零散的空间,避免了开辟连续大缓冲区造成的空间不足。每次读写操作时,从地址表中寻找地址,当操作到地址表中最后一个成员时,即返回到首地址,如此就可以利用零散空间形成环形缓冲。
在没有硬件FIFO 控制器的情况下,为了实现先入先出FIFO 功能,必须采用软件构建读写指针和满空标志等。并且为了兼容共享RAM两侧权限不对等的情况,不能由双方对同一存储单元进行操作,必须采用读写标志分离,如图4 所示。
当CPU1 向CPU2 进行数据传输时,CPU1 的操作流程如下:
(1)判断满标志是否为1,若是,则放弃写入。若否,则根据写指针的值查找地址表,然后将数据写入对应的地址;
(2)操作完成之后将写指针加一,若大于n,则令其等于0。
(3)然后判断是否与读指针相等,若相等,则置位写满标志,若不等,则满标志清零。
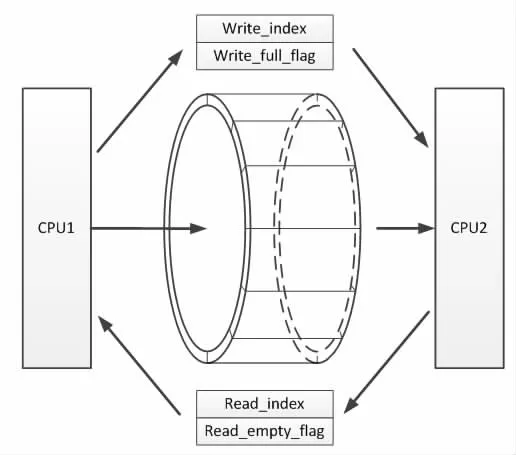
图4 环形FIFO 机制
由于采用缓冲机制,CPU2 并不需要在CPU1 发送完成之后立刻读取,只需在空闲时将数据取走即可,CPU2 的读操作过程如下:
(1)判断FIFO 当前是否为空状态,若是,则放弃读取,若否,则根据读指针查找地址表,找到对应的位置进行读取。
(2)操作完成之后将读指针加一,若大于n,则令其等于0。
(3)然后判断是否与写指针相等,若是,则置位读空标志,若否,则将标志清零。
需要说明的是,FIFO 初始状态时,读指针等于写指针,都指向FIFO 的第一个缓冲块,且空标志为1。
读操作与写操作类似,其基本单元都是一个缓冲块,即一个周期所需传输的数据,这样的机制保证了各路通道之间的同步,有利于现场调试和故障分析。
本文提出的基于块操作的FIFO 数据传输机制不依赖于具体的接口总线,将其归一化到地址空间进行处理,并且适用于共享存储区域两侧CPU 读写权限不对等的情况。解决了跨时钟域、不同运行周期CPU 间的数据传输速率匹配问题,保证了数据不丢包、不重包,并实现了波形监视和故障记录中各通道数据之间的同步。
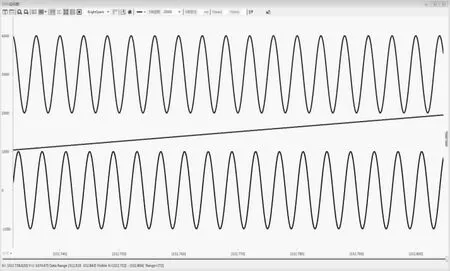
图5 监视数据波形
4 结论
本文针对变流器控制平台中异构多核跨时钟域实时通信需求,充分研究了典型核间通信方法特点后,在现有乒乓操作的基础上提出了基于块操作的FIFO 缓冲区机制。该方法无需中断接收方的实时控制程序,实现了异步时钟下的数据可靠传输;并且该方法不依赖于具体硬件接口,可在不同的硬件平台通用。基于该机制,在新的控制平台中成功实现波形监视和故障记录功能。
