基于判别分析算法的共享单车需求波动趋势预测研究
2021-01-19蔡梦琴王艳敏柯文娟石志颖
蔡梦琴 王艳敏 柯文娟 石志颖




【摘 要】从地铁站、公交站等到目的地的“最后一公里”的问题,一直困扰着人们。共享单车的爆发式增长与“放养式”发展带来了一系列问题,引起了社会各界的广泛关注。文章基于南京市共享单车借还数据,利用线性判别分析、k-近邻、贝叶斯判别分析、随机森林、支持向量机等方法构建不同区域共享单车需求波动趋势预测模型,基于模型预测结果,为南京市共享单车区域管理提供建议。
【关键词】共享单车;判别分析;支持向量机;随机森林;需求预测
【中图分类号】U491.225 【文献标识码】A 【文章编号】1674-0688(2021)12-0076-03
1 研究意义
共享单车平稳、有序、健康、绿色、持续发展的关键是实现供需平衡,即共享单车的投放比与用户的需求度相匹配。用户的需求是一个动态的变化过程,受多种因素影响,故通过对各个因素进行分析,用户需求可呈现出一定的可预测性。动态调整共享单车区域投放数量,降低运营成本、协调资源、提升用户体验、增强服务质量,对共享单车行业的可持续发展具有重大意义。
关于共享单车的需求预测,国内外学者已进行了大量研究。例如,宋鹏等[1]构建了基于不同核函数支持向量机的共享单车需求预测模型,并进行仿真模拟。苏影[2]以北京市摩拜单车的出行数据为基础,使用K-means聚类法对共享单车的投放区域进行了划分,并利用Xgboost算法对各区域内共享单车用户需求进行动态预测,建立了共享单车动态调配优化模型,得到动态调配方案。焦志伦等[3]探讨了共享单车短期(基于小时)需求预测的主要影响因素,并对不同模型的预测效果进行比较分析。史越[4]分析了共享单车需求特征,提出了共享单车调度网络构建方法,建立了共享单车需求量预测模型,并进行了实例研究。
基于此,本课题以南京市为例,调查与研究共享单车的需求波动,分析预测共享单车供需之间存在的问题,了解供需不平衡的原因,从而提出具有针对性、可操作性的解决对策,以促进共享单车长久发展。
2 共享单车需求预测的基本原理与方法
2.1 共享单车需求现状和波动分析
自行车共享世界地图网站曾对世界范围内的自行车规划进行统计,结果显示,截至2019年底中国自行车共享项目已投放约47万辆公共自行车,全球排第一位。
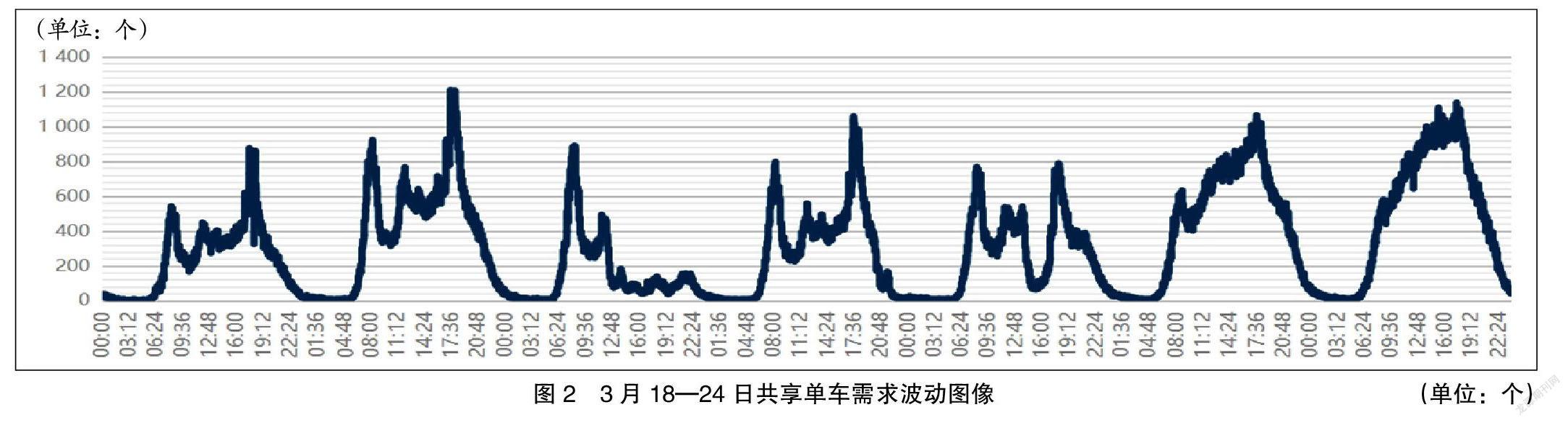
基于南京市2019年3月18—24日共享单车需求数据绘制共享单车借还数据折线图(如图1所示)。
由此可以看出,共享单车的需求具有明显的时空特征和呈周期性变化。上午9时为集体早高峰时期,下午6~7时为集体晚高峰时期,晚7时以后共享单车需求量整体下降。共享单车白天的需求量明显大于夜晚,同时存在高峰期和低谷期,呈现两个波峰、两个波谷,需求波动变化特点显著。
2.2 共享单车需求波动影响因素理论分析
共享单车是当前人们重要的出行方式之一,影响共享单车需求的因素有很多,比如时间、季节、天气、温度、风速及节假日等,都对共享单车的需求产生影响。
3 基于判别分析的共享单车需求波动趋势预测模型的构建与应用
3.1 分类结果的评价指标
分类算法通过预测变量可以很好地将类别进行分离,混淆矩阵汇总了正确分类和错误分类的数量,当数据量足够大,并且两个类别都不稀少时,这种估计是可靠的。
对于分类效果的评估,使用几种常用的预测精度测算指标(见表1)。
定义错误率:
FN+(1)
准确率:
TP+(2)
召回率:
reall==(3)
精准率:
precision=(4)
F1得分(使用调和平均结合召回率和精度的指标):
F1=(5)
其中,P為精准率,R为召回率。
3.2 数据选取及样本分析
选取2019年3月18—24日的南京市共享单车需求量作为样本数据(如图2所示)。
计算样本数据的描述性统计量:样本总量为5 040个,样本均值为311.467 658 7,标准差为291.425 311 5,样本最小值为0,最大值为1 208,下四分位数为510,上四分位数为31,可得出共享单车需求量离散程度较高。从分布形状来看,计算得到选取样本的偏度为0.714 939,峰度为-0.509 132,可得出共享单车需求量数据呈现右偏分布,并且数据分布比标准正态分布平坦。
3.3 预测结果分析
分别利用线性判别分析(LDA)、k-近邻(k-NN)、贝叶斯(Bayes)判别、随机森林(Random forest)、支持向量机(SVM)对一周内的共享单车需求波动趋势进行预测。
3.3.1 训练集与测试集结果分析
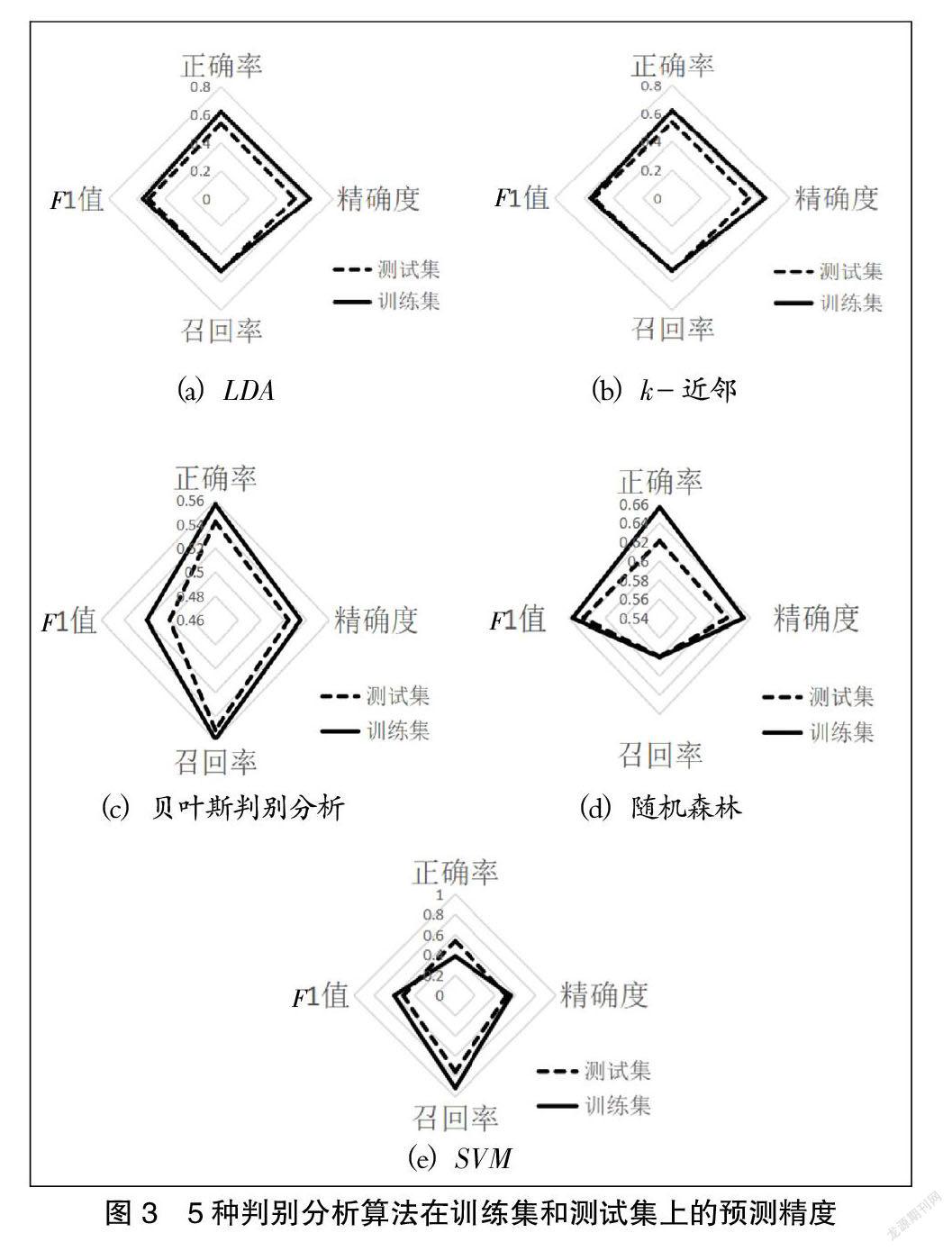
在每个样本区间内将80%的数据划分为训练集,20%的数据划分为测试集,利用Python软件进行仿真。我们给出上述5种判别分析算法在一周期的样本区间内训练集预测精度指标和测试集预测精度指标的对照结果(如3图所示)。
由图3可以看到,运用5种判别分析算法预测共享单车需求波动趋势,在训练集上的预测精度指标均优于测试集上的预测精度指标,这是符合常理的。
3.3.2 5种预测模型测试集结果比较分析
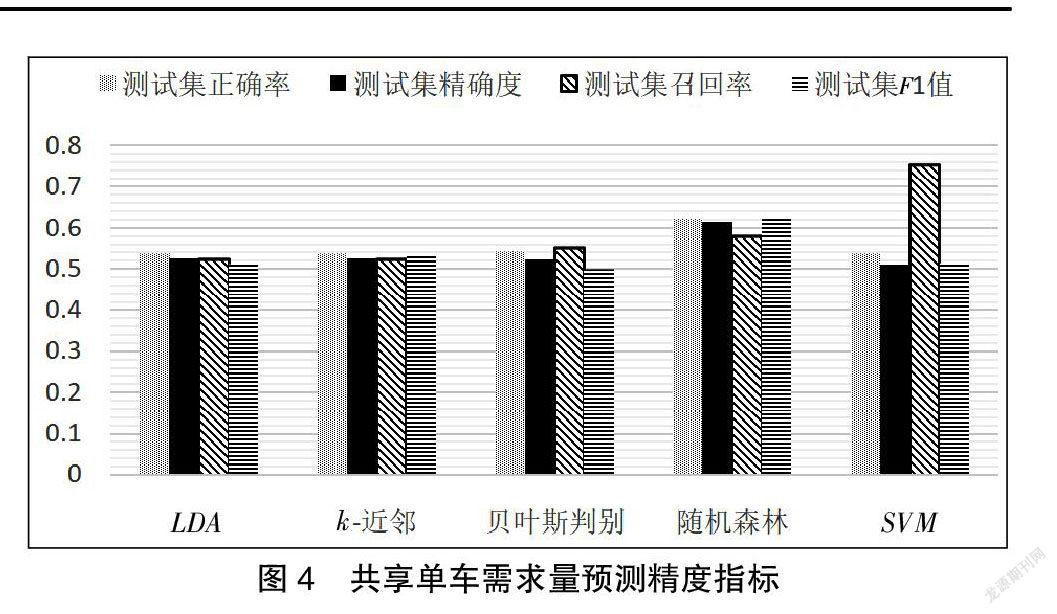
评价一个预测模型的优劣主要看其在测试集上的预测精度指标,对共享单车的需求量的预测结果进行分析,得到基于5种预测模型的预测精度指标对比结果(如图4所示)。
对5种预测模型进行对比,模型预测精度按从高到低依次排序:从测试集正确率角度来看,随机森林>贝叶斯判别>k-近邻>LDA>SVM;从测试集精确度角度来看,随机森林>LDA>k-近邻>贝叶斯判别分析>SVM;从测试集召回率角度来看,5种预测模型预测精度从高到低依次排序为SVM>随机森林>贝叶斯判别分析>LDA>k-近邻;从测试集F1角度来看,随机森林>k-近邻>SVM>LDA>贝叶斯判别分析;从5个精度指标的平均值角度来看,随机森林>SVM>k-近邻>贝叶斯判别分析>LDA;从预测模型的稳定性角度来看,5种预测模型预测结果稳定性程度从高到低依次为k-近邻、LDA、随机森林、贝叶斯判别分析、SVM。
因此综合来看,随机森林预测模型预测精度最高且预测结果的稳定性较好,得到如下结论:随机森林预测模型在共享单车需求量预测方面具有最好的效果。
4 研究结论及预测结果
4.1 研究结论
本文在对共享单车的需求波动特征进行系统梳理的基础上,针对共享单车的需求波动趋势预测问题,把样本分为2个部分,80%为训练集,20%为测试集,分别构建LDA分析、k-近邻、贝叶斯判别分析、随机森林、SVM 5种预测模型。对得到的预测结果,分别利用训练集的正确率、精确度、召回率、F1值,以及测试集的正确率、精确度、召回率、F1值等预测结果精度指标进行分析,得到如下结论。
(1)对比5种预测模型在共享单车的需求波动特征训练集和测试集上的预测结果,5种预测模型整体预测效果表现良好。
(2)在预测共享单车的需求波动时,SVM预测模型预测精度最高且具有最小的预测波动性,随机森林预测模型具有次高的预测精度且预测结果的稳定性较好,但SVM 模型易出现过拟合现象。因此得到如下结论:在预测共享单车的需求波动时,随机森林预测模型在预测共享单车的需求波动趋势预测方面效果最好。
4.2 随机森林预测及结论分析
4.2.1 模型建立
将时间、共享单车需求量作为输入变量,下一个星期的共享单车需求量作为输出变量,建立随机森林的预测模型,使用pycharm运行,得出下一个星期的共享单车需求量。
4.2.2 模型求解分析
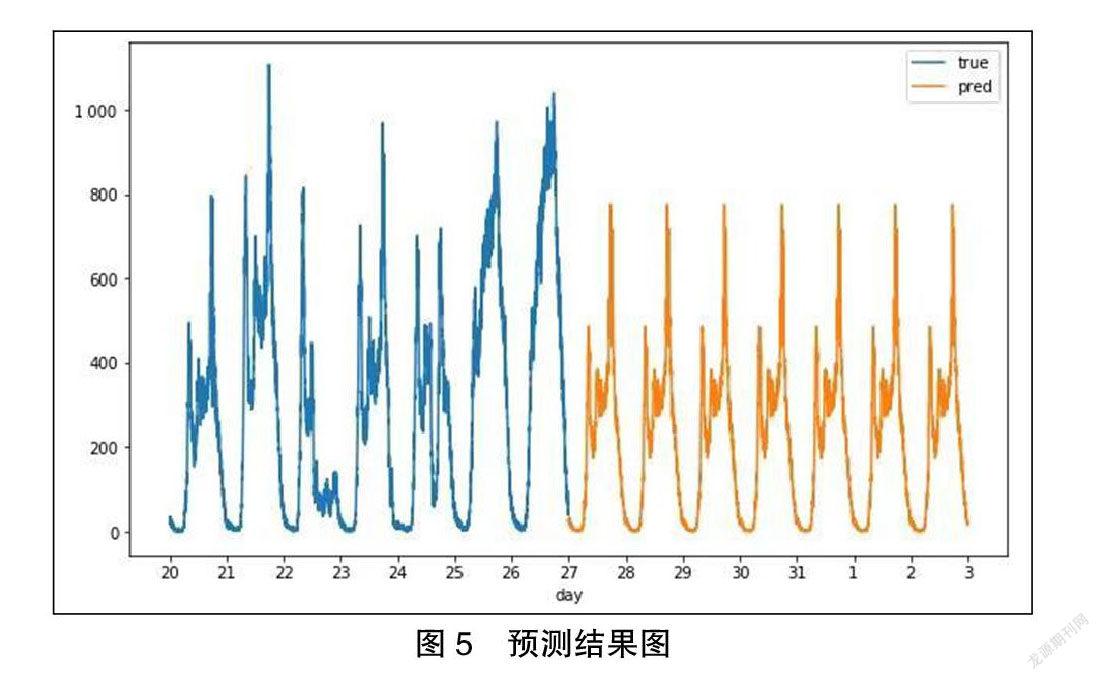
运行代码得出图像如图5所示。
由图5可知,2019年3月25—31日的共享單车预测的需求波动规律相同,相比3月18—24日的共享单车需求量下降的趋势,3月25—31日在上午9时左右达到第一次需求高峰时期、下午6~7时达到第二次需求高峰时期,但是整体高峰、低峰及平峰时期的共享单车需求量都比上一个星期少,由此得出下一个星期的共享单车需求量下降。通过对实际数据进行分析得出,理论结果与实际相符。
参 考 文 献
[1]宋鹏,黄同愿,刘渝桥.基于SVM的共享单车需求预测[J].重庆理工大学学报(自然科学),2019(7):187-
194.
[2]苏影.基于数据分析的共享单车动态调配优化研究[D].北京:北京交通大学,2019.
[3]焦志伦,金红,刘秉镰,等.大数据驱动下的共享单车短期需求预测——基于机器学习模型的比较分析[J].商业经济与管理,2018(8):16-25,35.
[4]史越.共享单车需求预测及调度方法研究[D].北京:北京交通大学,2019.
