基于偏好免疫网络和SVM算法的油茶果多特征识别
2021-01-19陈泽君李立君谭季秋吴发展
李 昕,陈泽君,李立君,谭季秋,吴发展
(1.湖南省林业科学院,长沙 410004;2.中南林业科技大学机电工程学院,长沙 410004;3.湖南工程学院机械工程学院,湘潭411104;4.株洲丰科林业装备科技有限责任公司,株洲 412000)
0 引 言
油茶是中国南方重要的经济作物之一,其籽粒可以榨油后食用及工业用,具有巨大的经济价值。中国油茶种植面积和产量有了较大的提升。在油茶全产业生态链中,油茶果实的采摘、脱壳、榨油等环节已经产业化,成为了乡村农业振兴的重点工程与支柱产业。在油茶产业链自动化研究领域,中南林业科技大学与湖南省林业科学研究院课题组在油茶果采摘、脱壳自动化升级环节做了大量的工作。课题组研发了油茶果采摘机器人[1-4],油茶智能脱壳设备[5-6]等自动化产品,为油茶果产业链的自动化进程打下了坚实的基础。
目前国内外学者在农产品的智能分选识别领域已经做出了大量的研究与应用[7-24],Wang等对樱桃图像的RGB特征值进行了分析,设计了一套基于RGB的樱桃色选分级系统[25];Pearson等分析了RGB,HSV,Lab 3种颜色模型,提出了一套基于多特征颜色模型的玉米色选系统[26];赵吉文等对瓜子的灰度特征参数进行了分析,采用灰度带比例作为瓜子的分选特征参数进行分选[27];宋彦等采用了基于形状特征直方图的LS-SVM模型识别并分类了 7个等级的祁门红茶[28]。高震宇等使用卷积神经网络对鲜茶叶进行了分选与分级[29]。王丹丹等将深度卷积神经网络应用于机器人视觉系统之中,进行苹果目标的识别[30]。
上述研究均集中于农业智能分选领域,并取得了一定的成果。油茶果壳与籽粒具有颜色、形态特征区分明细的特点,本研究内容集中于油茶果脱壳设备的智能分选环节,即在油茶果采摘脱壳后,如何针对油茶果的特点利用分选技术将油茶果壳与籽粒有效地区分出来。
本文研究内容基于油茶智能识别算法的研究基础[31-33],结合前人在农林业的分选领域的研究结果,充分利用油茶果壳籽粒形态与颜色特征的区分,提出了一种基于偏好免疫网络与SVM结合的智能分选算法用于油茶果壳、籽粒的分选。本研究提出的智能分选算法可为油茶的果壳、籽粒智能分选提供参考。
1 试验材料与方法
1.1 试验材料
试验采用的图像采集时间为2019年10月至11月的油茶果脱壳后图片,采集地点为湖南株洲丰科林业装备科技有限责任公司内,分别选取存储期为3、12 d的油茶果,经过油茶生产线进行脱壳后的图片。油茶果脱壳后,对油茶果壳籽粒进行分析,从脱壳后油茶果图片分析可以得出,存放3 d的油茶果经脱壳后的,果壳、籽粒特征区分较为明显,而存放12 d的油茶果由于湿度和温度等原因,果壳开始逐渐转变为黑色,逐渐接近籽粒颜色。试验共采集待分选图片 350幅进行分析,像素分辨率调整为 1 682×1 430。
油茶果壳和籽粒的颜色形态特征有一定的不相同,从形态特征区分来看,油茶果壳相较籽粒偏长、呈扁状,而油茶籽粒则较果壳更多偏向类圆形。从颜色特征区分可以得出,油茶籽粒颜色呈暗黑色,油茶果壳颜色特征则趋于浅白色,油茶果壳籽粒的形态颜色特征区分如图1所示。本文对脱壳后的油茶果图片进行采集并进行颜色与形态参数提取,建立油茶果壳、籽粒的颜色形态参数的SQL数据库。

图1 脱壳后油茶果壳、籽粒形态及黑白颜色特征Fig.1 Morphological and black white color features of the shell and seed of Camellia after shelling
本研究对图片中油茶果壳、籽粒目标进行人工选取后建立颜色形态数据库后,得到待识别的样本目标特征图如图2所示。

图2 提取的油茶果壳籽粒目标样本Fig.2 Target sample of Camellia shell and seed
1.2 油茶果智能脱壳分选系统
本文采用的整体分选脱壳设备为揉搓型油茶果分类脱壳生产线,生产线由湖南省林业科学院与湖南株洲丰科林业装备科技有限责任公司联合研制生产。生产线的脱壳环节采用揉搓以及挤压原理,通过利用分类滚动筛筛选大小不同的油茶果进入油茶果脱壳装置,在运输带和柔性搓板相互配合运动的揉搓作用下进行脱壳。这种设备装置可以有效对油茶进行分类脱壳、在保证果壳和籽粒分选的基础上,同时不会对油茶籽粒造成破损。经过试验,揉搓型生产线技术指标已经达到了:脱壳脱净率>97%,碎籽率<5%,整体损耗率<1%。全套油茶果脱壳分选设备如图3所示。
经过揉搓脱壳后,油茶果壳、籽粒被传送带送往分选箱的第一层分选区,工业相机实时采集脱壳后的目标图像,识别设备采用日本 computar-3s工业镜头。第一层分选区使用多特征形态免疫算法识别果壳物料,识别后,控制对应位置的喷气嘴进行喷气,改变果壳在传送带上的运行轨迹,吹飞油茶果壳物料。剩余的油茶果壳籽粒继续进入第二层分选区,使用SVM算法识别剩余目标的颜色参数,再使用喷气嘴吹飞剩余物料中的果壳物料,最终实现果壳与籽粒的区分。分选设备的工作与识别如图3所示。
识别的效率对于分选系统来说至关重要,为了达到实时识别率要求,本研究选用安晶龙分选机作为分选识别设备,分选机结合脱壳传送带的输送、识别能力,目前分选效率已经达到了毫秒级,已经广泛应用于塑料分选、花生分选、辣椒分选、中药材分选等领域,是一种十分成熟稳定的实用分选设备。安晶龙分选机的工控机分选软硬件设备采用VC6.0系统与MATLAB2020仿真系统,工控机硬件升级为为Intel至强E5-2670 8核心16线程CPU,内存80 GB。软硬件设备稳定且识别效率较快,适用于本研究的实时性要求。安晶龙分选机在本研究中具体承担软件视觉实时辨别分选工作,本文的研究算法是基于安晶龙分选机作为硬件搭载系统进行的二次开发与应用。

图3 全套油茶脱壳分选设备Fig.3 Equipment of Camellia shelling and sorting equipment
2 基于偏好人工免疫网络的形态特征分选
2.1 形态特征提取
油茶果实经过脱壳机脱壳后主要存在果壳、籽粒 2种目标物体,相较于自然环境下的图像处理,分选设备的封闭环境下识别脱壳后的的油茶果壳、籽粒目标相对识别率更高、图像的处理效果也更好。在封闭的环境中使用经典 OTSU分割算法足够可以满足图像后续处理的要求,在分割后的图像的基础上,图像的后期处理采用腐蚀膨胀的图像形态学操作,在操作中设定图像结构元素形状为平坦型圆盘结构元素,半径参数为 5像素。并对个别目标添加孔洞填充、中值滤波、边缘优化等操作,后续也会根据图像形状和质量的变化对结构元素的形状和大小进行动态调整。以得到更好的果壳、籽粒、树叶杂质等目标物的形态学效果
在脱壳后目标的形态学分量分析中,本文采用的基础特征要素为伸长度L,宽度W,周长S,面积A,形态学参数选取了延伸率S1,圆形度S2,圆满度S3共3个分量作为输入分量。如式(1)~(3)所示。选取油茶果壳目标对象的延伸率S1、圆形度S2、圆满度S3属性图如图4所示,通过对典型油茶果壳籽粒进行形态学测试分析得到的果壳籽粒目标形态学参数范围如表1所示。为保证数据的范围与辨识多样化,本文设定了圆形度参数ε=1.25与圆满度参数ω=1.98,后续可以根据实际图像质量对参数进行调整,使输入特征数据具有更强的自适应性。
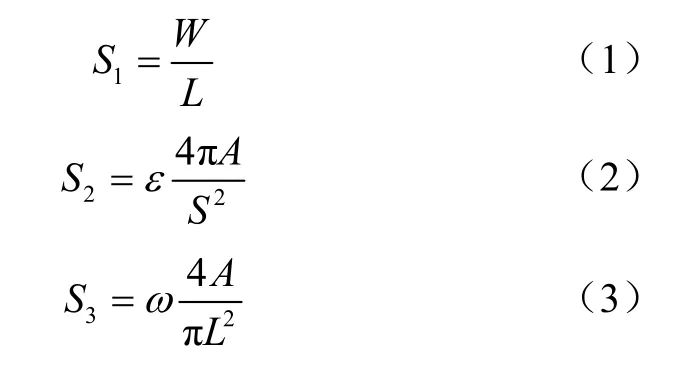

图4 油茶果壳目标形态学特征Fig.4 Morphological feature of Camellia shell

表1 油茶果壳籽粒形态分量范围Table 1 Morphology component range of Camellia seed shape
2.2 多形态特征偏好免疫识别
本文采取偏好免疫网络算法[33]对油茶果实的形态特征进行多特征识别,输入特征参数为油茶果壳目标延伸率、圆形度、圆满度3项参数作为形态偏好分选参数。形态偏好参数为前期采集的具有典型形态特征的目标图片中的参数,选择后将其输入算法,在算法中,采用油茶脱壳后的果壳籽粒作为样本参数作为算法中的初始细胞进行训练,最终得到待识别的目标果壳样本后进行喷气嘴吹飞,本研究中的偏好免疫网络算法分选流程如图5所示。
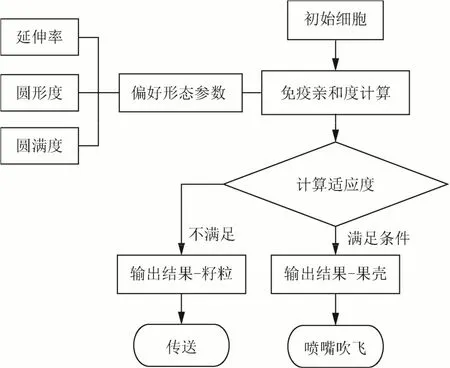
图5 多形态特征偏好免疫算法分选流程Fig.5 Multi-features preference immune sorting process
本文按照亲和度计算公式添加免疫亲和度计算模块,并计算其适应度,如式(4)所示。
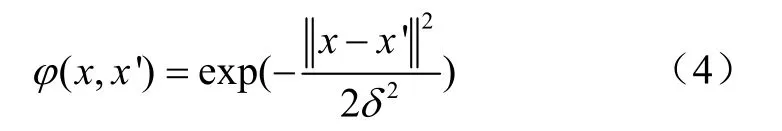
式中x'设定为输入的油茶果延伸率、圆形度、圆满度3项特征参数。x为待识别的油茶图像数据矩阵,δ为亲和度函数。设定抗体x'与抗原x的亲和力越小, 待识别油茶数据与输入数据越匹配。
在算法流程中,将待识别的油茶脱壳后的图像数据作为初始细胞,油茶果壳的 3项典型形态学参数作为偏好参数,将 3项参数代入免疫程序中进行亲和度与适应度计算,当满足果壳参数阈值时,定义目标为果壳,并在生产线上使用喷嘴进行吹飞。当不满足阈值时,定义目标为籽粒并在传送带进行后续传送与颜色辨识。
多特征融合免疫算法的具体流程如下:
从样本选择待处理的3项形态学参数大数据,并在参数中选择一部分具备典型形态学特征参数,并把这些典型参数定义免疫学中的抗原细胞,将其输入免疫网络进行运算分析。
1)将3项形态学参数输入免疫网络,对各抗原细胞之间的亲和力水平进行运算比较。
2)按照算法中设定的克隆规则对网络中的数据细胞进行克隆。
3)按照式(5)~(6)的方法对经克隆运算后的细胞进行变异操作,最后保留父代群体于网络中。

式中C'为细胞C产生变异后形成的新细胞,N(0,1)是均值为0,偏差为1的高斯随机变量,β为调节函数的指数衰减变量,f为经标准化处理后的细胞适应值,α为根据算法自设定的变异系数。
变异后,重新运算免疫网络细胞亲和力。
4)选择亲和力最高的网络细胞组成新的网络,并计算新网络的细胞亲和力。
5)计算网络中所有细胞的亲和力,如果小于阈值则且亲和力高的细胞予以保留,其他细胞则进行抑制。
6)输入一定比例的随机网络细胞数据,返回第二步。
7)输出产生的网络细胞数据。
免疫网络算法流程图如图6所示。在输入3项形态学参数的基础上算法的平均识别时间为410 ms级,

图6 人工免疫网络流程图Fig.6 Flow chart of aiNet (Artificial Immune Network)
3 基于Support Vector Machine(SVM)算法的颜色特征分选
3.1 颜色特征提取
从外部颜色特征得出,油茶果壳与籽粒差别较明显,机器视觉分选系统原理基于同步人眼识别的要素对目标特征并进行区分,通常目标依据识别要素区分为形态、颜色、纹理、光谱特征等,本研究综合生产线运行速度、图像处理计算机计算量与计算效率决定分选方案,因此第二层分选区在第一层分选区选取形态特征的基础上,进一步选取油茶果壳籽粒的颜色特征进行分选区分,以得到最优的综合分选结果。
1)颜色特征选取
油茶果壳籽粒的RGB分量颜色特征如图7所示,在采集的图片中,油茶籽粒呈现为暗黑色,像素点的RGB分量颜色偏向于黑色至象牙黑之间,而暗绿色与白色则为果壳、树枝叶等颜色特征,其他的颜色特征像素范围可转化为背景或杂质做全零像素处理。
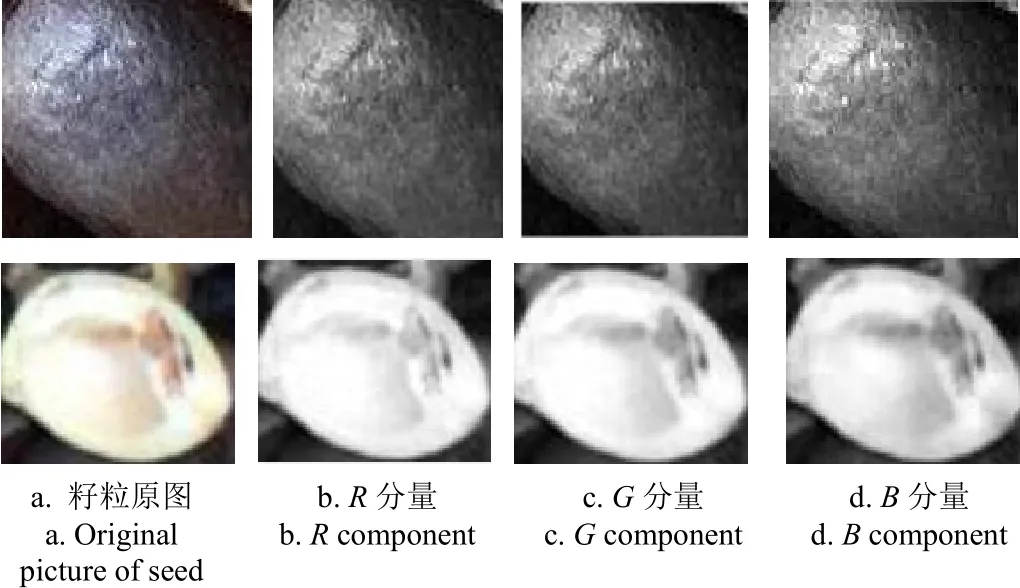
图7 油茶果壳籽粒的RGB分量Fig.7 RGB components of Camellia shell and seed
2)颜色特征值确定
选取颜色向量三维矩阵,依据油茶籽粒像素块的RGB特征分量构造3个输入颜色特征向量值。在RGB分量中,训练样本颜色选取原则依据油茶籽粒与果壳颜色,籽粒颜色,本文选取 0~114范围之内的黑色像素区间作为籽粒区间,范围区间为a= [ (0- 1 02),(0- 1 12),(0- 1 14)].而果壳区间数据范围则依据样本的RGB颜色特征值设定为b= [ (140 - 2 40),(140 - 2 40),(140 - 2 40)],a,b中的数值分别对应油茶籽粒与果壳中的R分量、G分量、B分量的灰度值范围,识别目标颜色特征范围数据如表2所示。

表2 油茶果壳籽粒RGB分量范围Table 2 Color feature components range of Camellia seed shape
为利于油茶果颜色识别,将提取的油茶果壳颜色特征数据输入支持向量机算法进行颜色二分,作为颜色特征算子进行训练,以便于为后续的图像颜色特征识别。
3.2 SVM颜色特征分类
支持向量机算法是一种成熟的图像识别处理算法,其算法特点是间隔最大化,能够寻找分开 2类样本数据且具备最大分类间隔的最优分类超平面。其优秀的分类特征特别适用于基于颜色特征的二分类处理或多分类处理。本研究以油茶果壳的颜色特征数据库为训练模板,并运用模板训练所得的分类器对目标油茶籽粒与果壳进行再次颜色特征的再次分类处理。
在图像处理中支持向量机的工作原理如下:假设存在向量集D={ (fi,li) } ,i= 1 ,2,...,k,li∈{-1,1},其中,f为特征向量,l定义为样本标签,k为数据样本的总数。对于可以通过线性区分的假设,可以让最终结果最大间隔或求解凸二次规划最优解获得下面公式

式中w为权重参数,b1为偏移量,i= 1 ,2,...,k,C为惩罚因子,ξ为松弛变量。通过建立拉格朗日中值以获得最优解的SVM分类器,并对参数模型进行训练。同时,本文选取线性核函数作为训练核函数。
给定支持向量机的颜色训练样本集和核函数,本研究选取油茶果壳的RGB 3个参数样本作为支持向量机的输入训练样本,即选取表2的果壳之间的颜色像素区间,本研究选取的训练样本 RGB像素集合与范围区间为b= [ (140 - 2 40),(140 - 2 40),(140 - 2 40)].
SVM算法识别颜色特征的流程步骤如下:
第一步,输入油茶果壳的RGB训练样本集合,选取训练样本 RGB像素集合与范围区间为b= [ (140 - 2 40),(140 - 2 40),(140 - 2 40)]。
第二步,针对油茶果壳目标样本的颜色特征进行SVM算法训练。
第三步,油茶果壳样本颜色特征训练完毕后,进入第二层分选区,对目标数据进行SVM二分,以获取目标油茶果壳籽粒目标,如图8所示。在下一步使用喷气嘴进行吹飞。

图8 油茶果壳籽粒颜色特征区分Fig.8 Color feature difference of Camellia shell and seed
4 试验与结果分析
本文采用偏好人工免疫算法及 SVM 算法对油茶籽粒、果壳目标进行了分选,用 2种分选算法进行综合分选增加了整个分选系统的适应性,因为只用色选法虽然可以对颜色差异进行辨识,但是在颜色分别不明显,色选不能完全识别样本的情况下,形选可以弥补色选在颜色识别上的的分选缺点。同样,果壳和籽粒的重叠、粘连可能造成形态误识别,而色选可以在不同形态区域进行细分。因此,色选与形选结合的分选算法可以最大程度增加整个系统的实用性,提炼出 2种方法的优点,以增强整个系统的自适应性。
为计算本文提出算法的有效性,本研究编制MATLAB分选代码并在油茶果脱壳生产线工控机设备上进行测试分析。
4.1 试验结果
在仿真试验阶段,本文先选取形态、颜色特征数据库的数据进行算法训练,再选取脱壳后的油茶果壳、籽粒图片进行分选本文算法的分选测试,测试图片选取存放周期为3和12 d的图片各10张,综合2种算法模型的分选测试得到了不同存放时间下图片的组合算法识别时间、识别率数据。由于最终喷气嘴的吹飞目标为油茶果壳,因此应用算法模型将每幅图片中的果壳个数、成功识别个数、识别率、识别时间进行了统计,最终得到了图片中油茶果壳的各项识别参数,识别结果如表3所示.

表3 存放期3、12 d脱壳后油茶果壳识别效率Table 3 Recognition efficiency of Camellia shell after stored for 3, 12 days
由表3得到,存放期为3和12 d的油茶果壳识别率有较大的差别,存放期为3 d的识别率平均值为94.6%,远大于12 d的识别率均值76.6%,识别率的差异的原因在于采摘后的油茶果实存放越久,其果壳收到温度与湿度等外界因素影响,其颜色将逐渐呈现暗黑色,与籽粒的颜色差别逐渐变小,因此造成存放期12 d后的果壳识别率普遍降低,最低达到了 66.6%。而由于算法结构的原因,识别时间则基本不受颜色干扰影响,一般平均识别时间为600 ms左右。因此,为保证识别效率,油茶果采摘后不宜放置过久,应尽快进行后续的脱壳以及分选过程。
4.2 形态多特征免疫网络聚类分选效果
在得到整体综合算法识别效率后,对油茶果壳、籽粒的 3种形态特征的免疫网络进行三维仿真以验证目标形选的特征不变性。分别对上文中10张3 d存放期与10张 12 d存放期后脱壳的油茶果图片进行形态多特征聚类,应用本研究的多特征偏好免疫网络算法进行聚类,得到的籽粒、果壳多特征偏好免疫 3特征三维聚类效果如图9所示。

图9 存放期3、12 d果壳籽粒形态特征聚类效果Fig.9 Clustering effect of morphological feature stored for 3, 12 days
从图9中可以得出,由于形态学特征不受油茶果颜色变化的影响,输入形态特征参数后,经过多特征免疫网络聚类识别后,3天存放期与12天存放期的油茶果壳、籽粒均可实现较好的形态特征聚类效果,这也证明了通过形态学参数分选目标可以不受果壳颜色变化干扰影响,进而增加了算法结构的自适应性。
4.3 不同算法分选对比
本文使用多特征免疫网络与支持向量机的联合算法解决了油茶果壳、籽粒在传送带上的动态多特征识别问题,本研究进一步使用了形态颜色特征融合的多特征人工免疫算法[26]、多维SVM算法[34]、传统的色选阈值分选方法、传统形态单特征阈值分选法在分选效率与分选时间上的进行了对比试验,以测试本文分选算法的有效性。
试验所选用的对比数据为上文试验中使用的存放周期为3与12 d的的油茶果实、籽粒图片各10张,提取SQL数据库中的6个的形态与颜色参数进行试验,上文已经使用了本文的算法进行了试验,在对比试验中,使用6特征免疫算法、6特征SVM算法、传统颜色阈值法、传统形态单特征法进行分选对比,得到的各算法平均分选效率与平均运算时间如图10所示。
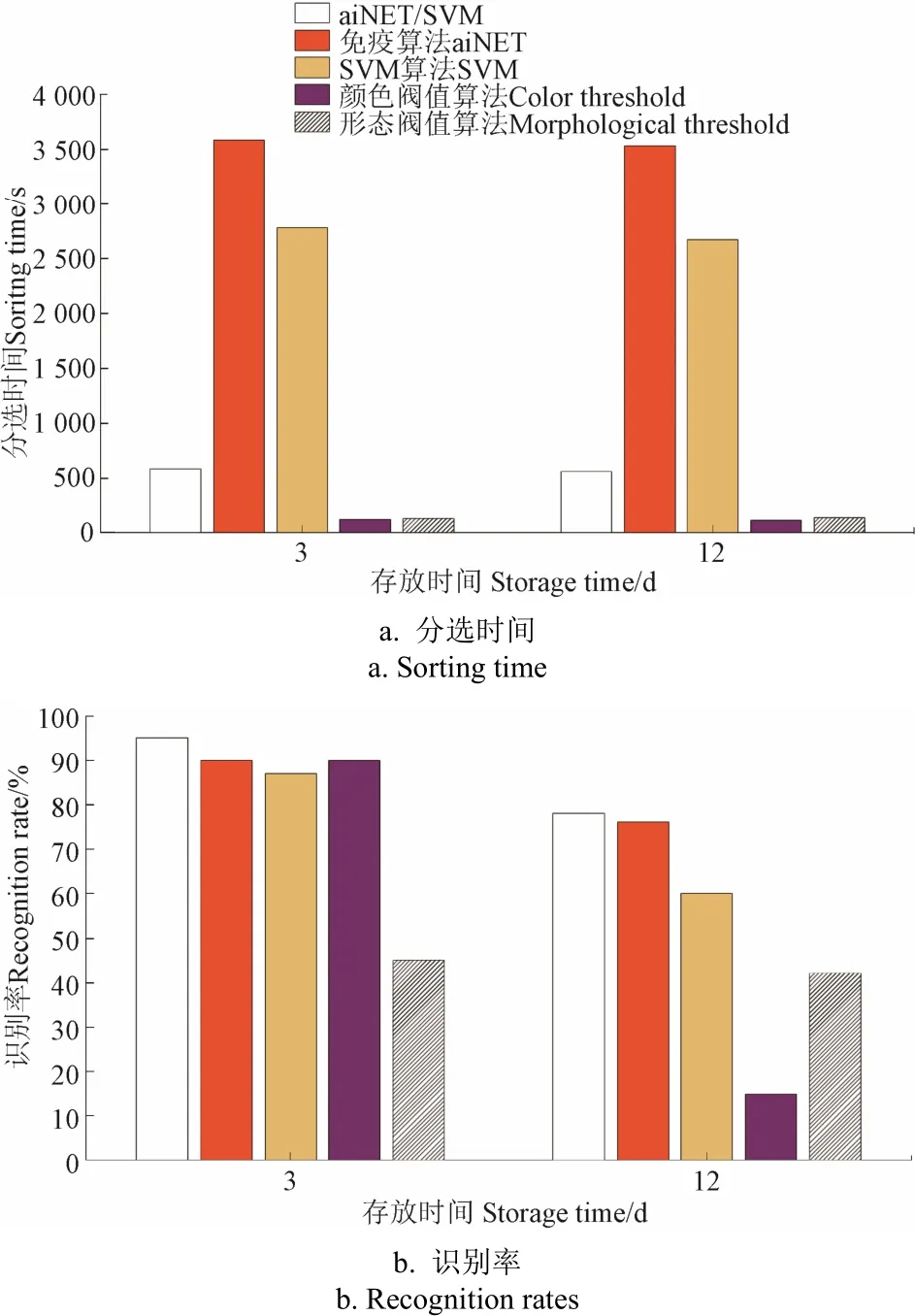
图10 不同算法分选时间及识别率对比Fig.10 Comparison of sorting time and recognition rates in different algorithm
从图10中可以得出,由于算法结构与输入数据的因素,5种算法在3和12 d的分选时间上基本一致,其中传统颜色阈值法与传统形态单特征阈值法的分选时间最短,最低达到了平均 110 与 133 ms。传统的阈值色选算法虽然执行时间较短,但由于其算法结构简单,不具备多特征自适应性,导致识别率较低,当油茶的存放期达到 12 d,果壳与籽粒的区分已经不明显时,传统颜色阈值分选方法的识别率大幅度下滑,降低到了15.2%,基本不具备可用性;传统形态单特征阈值法采用了判断目标延伸率来判断目标的方法,受到颜色变化的影响较小,但由于待识别目标的形态特征多样化,导致整体识别率较低,平均只有 35%左右。而单独使用多特征偏好免疫算法对形态、颜色的 6个特征进行识别容易造成识别时间过长的“维数灾难”[35],即当数据的输入维度造成算法内部相关维度增大时,算法的整体运行时间会随指数型增长,这在实时率要求较高的实际分选工作环境中是不适用的。即使识别效率达到了要求,但也会导致识别时间过长,不适用于生产线的实时识别率要求;SVM算法由于其算法结构的二分特性不适于多特征识别,改进的算法也会由于结构过于复杂导致分选时间长的问题,同时在12 d存放期颜色区分不明显的情况下也会造成识别率的下降。而本文采用的多特征偏好免疫网络与SVM结合的算法缩减了多维运算的复杂性,节省了运算时间。在缩小运算时间的基础上,同时保证了分选效率,使油茶果在 3与 12 d的分选识别率分别达到了 97.4%和76.6%,识别时间达到了平均值600 ms,最低值510 ms,识别时间为 2种算法的消耗时间之和,其中免疫算法和SVM算法消耗时间的比例为2.3∶1,证明了本文的算法较其他算法在时间与效率上的优势。
5 结 论
1)本研究通过人工免疫网络与支持向量机的结合算法,使油茶果分选生产线实现了形态与颜色特征综合判断分选的效果。特别针对于存放时间较长导致果壳与籽粒颜色区分不强的油茶果实,本研究可以通过增加形态学识别的方法增强系统的可用性,进而增加了油茶分选生产线的鲁棒性与实用性。
2)通过改进的自适应免疫算法进行了综合识别,综合识别算法综合了2种识别算法的优点,试验得到3 d存放期的平均识别率达到了97.4%,12 d存放期的平均识别率为76.6%,识别时间平均值为600 ms,最低值达到了510 ms。结果满足了生产线的实用效率要求,进一步增加了分选系统的可用性。
本文在实地生产线上实时对油茶果分选的效率与速率进行试验检测,通过检测验证了本研究的计算方法的有效性。事实证明,本研究提出的多特征识别算法的应用,将使油茶果分选系统更加经济,更加实用。
针对识别对象目标重叠后产生的实效问题,本研究先采用偏好人工免疫网络对油茶果壳、籽粒的目标进行形态特征的识别,由于油茶果堆叠摆放较为密集,因此只采取形态学特征识别不可避免会对重叠目标产生误识别,进而降低目标识别率。而第二步采用的SVM颜色分类识别则可以较好地利用颜色特征将形态特征误识别的目标提炼出来,从而解决对象目标重叠、连接的问题。
