结合RGB-D视频和卷积神经网络的行为识别算法*
2021-01-19李元祥谢林柏
李元祥 谢林柏
(江南大学物联网工程学院物联网应用技术教育部工程中心 无锡 214122)
1 引言
近年来,人体行为识别被广泛应用于人机交互、视频检索和视频监控等日常生活场景中,利用人体行为识别算法可以有效自动地提取视频数据中高层语义,从而大大降低人力成本。目前,基于传统RGB相机的人体行为识别算法对环境要求较为苛刻,如光照、对象遮挡等因素。随着3D体感传感器的推出,如微软的Kinect,许多研究者开始利用Kinect提供的多源信息,如深度图序列、骨骼位置信息,降低环境因素对行为识别算法的影响,提高算法的鲁棒性。
目前,传统的行为识别算法主要集中对RGB视频序列的处理,包括分类器或特征提取算法的设计,如Laptev等[1]提出使用哈里斯角点检测器在时空3D空间检测兴趣点,取得了一定的识别效果。随着低成本Kinect深度传感器的推出,许多研究者开始尝试利用深度数据或骨骼位置数据解决人体行为识别遇到的挑战,Bulbul[2]等通过DMM计算轮廓梯度方向直方图特征(CT-HOG)、局部二值模式特征(LBP)和边缘方向直方图特征(EOH),并利用分类器KELM进行分类识别,一定程度上降低光照变化和物体遮挡等不利环境因素的影响。
随着卷积神经网络在图像领域取得了巨大的成功,受此鼓舞,研究者将卷积神经网络应用到行为识别领域并取得了显著的效果。Tomas[3]等利用二维卷积神经网络和堆叠编码器(SAE)分别学习RGB视频序列和骨骼位置信息序列的高层语义,其中RGB视频序列被预处理为运动历史图像序列(MHI)以提取其长时域运动信息。宋立飞[4]等在经典双流网络结构上,利用2D残差网络和多尺度输入3D卷积融合网络提取视频的时空维度信息,并决策融合两路神经网络的预测分数。
行为识别与静态图像识别最主要的区别是视频序列包含行为的时域信息,因此人体行为识别难点之一就是如何从复杂场景的视频序列中,有效提取动作行为的时域信息。Hochreiter[5]等在传统递归神经网络(RNN)进行改进,提出了长短期记忆递归神经网络(LSTM),能够有效提取视频序列的时域特征。Imran[6]等利用RGB视频序列与深度图序列分别计算MHI和DMM,并输入到多路独立的卷积神经网络训练,最后分别比较了均值法和乘积法这两种决策融合策略的识别效果。
本文主要贡献为以下三个方面:
1)为了提取RGB视频序列中静态表观与短时域运动信息,以及深度图序列中长时域运动信息,提出了一种结合RGB-D视频序列和卷积神经网络的人体行为识别算法。
2)在深度图序列中,通过引入表示能量大小的权值变量,对不同深度图进行加权,从而保留视频序列中更多的细节信息。
3)为了有效融合多路卷积神经网络的预测分数,基于常用的决策融合方法,提出一种改进的加权乘积融合策略,实现端到端的行为识别算法。
2 数据预处理
卷积神经网络在静态图像识别任务中,表现出远超人工设计的特征提取算法识别效果,但在行为识别任务中一直较难取得显著的效果,其中一个主要原因就是用于训练神经网络的行为数据集偏小,使得网络模型参数很难达到最优,且在训练过程中网络模型易出现过拟合。为了解决该问题,首先,使用预训练网络模型初始化神经网络参数。其次,针对于深度图序列,除了采用常规的尺度变换和裁剪翻转等手段,同时利用仿射变换[7]模拟数据集在相机视角变化的情况,从而进一步扩大数据样本量。为了保留视频的更多细节信息,在将深度图序列压缩到一帧DMM图像时,引入表示能量大小的权值变量,同时将改进的深度运动图进行彩虹编码[8]处理。
2.1 相机视角扩增
为了扩大数据样本量,可以利用仿射变换得到不同相机视角下的深度图像,如图1所示。假设Kinect相机从P O位置移到P d位置,此过程可以分为以下两步:首先,从位置P O绕y轴旋转θ角度到位置Pt,然后再由位置Pt绕x轴旋转β角度到P d。

图1 相机视角变化
设点(X,Y,Z)为P O的位置坐标,则P d位置坐标(X1,Y1,Z1)可以由下式得到:

其中T r y和T r x分别表示位置P O到位置P t、位置Pt到P d的的变换矩阵,可表示为

其中R y(θ),R x(β),T y(θ),T x(β)为
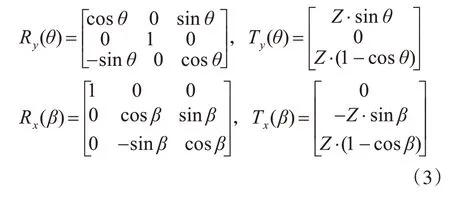
2.2 速度扩增
为了模拟出同一个动作序列下不同实验者执行效果,需要对给定的动作序列以不同采样间隔进行下采样,其计算公式如下:


图2 下采样示意图
2.3 改进的深度运动图
近年来,卷积神经网络在图像分类、目标检测和人脸识别等计算机视觉领域都表现出卓越的性能。本文利用二维卷积神经网络善于处理静态图片分类与识别的特点,尝试将深度图视频序列分别投影到三个正交平面(正平面、侧平面和顶平面)上,然后在每个投影平面上将深度图序列处理为一帧深度运动图像。
为了克服动作速度和幅度对动作识别的影响,在将深度图序列压缩到一帧DMM时,引入表示能量大小的权值变量来保留深度图序列更多的细节信息。在速度扩增中,不同的采样间隔能够得到对应不同时间尺度的采样序列。表示在采样间隔为l的下采样序列中,累计计算到第i帧的深度运动图,其中ε(i)v∈{f,s,t}表示第i帧的能量,表示第i帧深度图投影到正平面、侧平面和顶平面得到的投影图像。
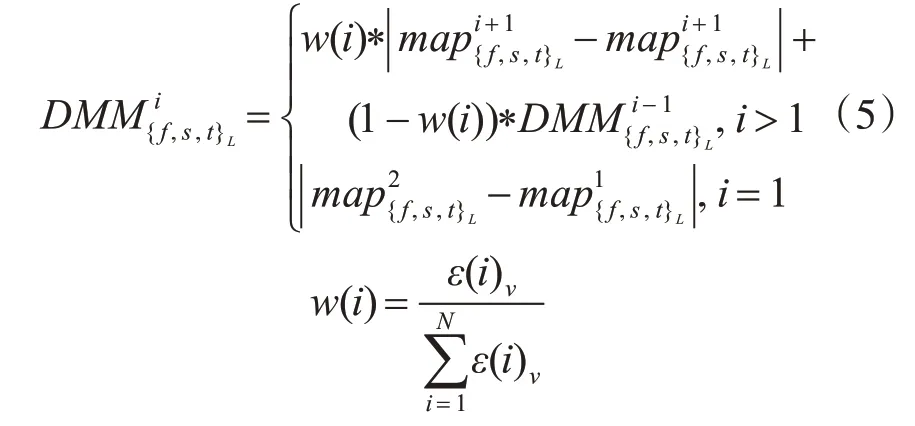

其中ξ为设定的阈值,sum(.)为计算二值图中非零的个数。

图3 “right hand draw circle(counter clockwise)”动作在不同模拟速度下DMM图像
3 多路卷积神经网络结构
为了提取RGB视频序列中静态表观、短时域运动信息和深度图序列中长时域运动信息,本文提出了一种结合ResNet(2+1)D[9]和GoogLeNet InceptionV2(BN-Inception)[10]的多路端到端卷积神经网络结构。四路网络结构相互独立训练,其中三路BN-Inception网络参数共享,分别用于训练DM M f,DM M s,D MM t数据。为了避免直接融合神经网络高层特征带来的特征维度高、计算复杂等问题,采用后期分数融合方式计算最终行为视频序列的预测分数。
3.1 ResNet(2+1)D网络层
对于给定一段RGB视频序列V,在提取视频序列短时域运动信息时,首先将动作视频可重叠地分割为K个子序列片段{ }T1,T2,...,T k,利 用ResNet(2+1)D对其训练,最后对K个子序列片段聚合得到视频级的预测分数,其过程描述如下:

其中R(T1,T2,...,T k)V表示视频序列V最终的预测分数,(T1,T2,...,T k)代表子序列片段,f(T k,W)函数表示基于模型参数W的ResNet(2+1)D网络在子序列片段Ti输入下得到的类别得分,g函数为采用均值法的聚合函数,以融合T1,T2,...,T k子序列片段的类别分数。

图4 多路卷积神经网络结构
ResNet(2+1)D网络是在3D ResNet[11]网络结构基础上,将3D卷积分解为2D空间卷积和1D时间卷积。在与3D ResNet网络保持相同参数量下,通过在2D空间卷积与1D时间卷积之间引入非线性激活函数ReLu,同时分别优化2D空间卷积和1D时间卷积,使得ResNet(2+1)D的训练错误率比3D ResNet更低。本文采用连续32帧图像作为片段T i,并基于R(2+1)D结构的ResNet-34网络下训练子序列片段。
3.2 BN-Inception网络层
对于一段给定的深度图视频序列,首先分别投影到正平面、侧平面和顶平面,并根据不同的采样间隔l,得到对应的下采样序列和。然后分别计算得到多个深度运动图作为三路BN-Inception网络的训练集。
GoogLeNet Inception V1[12]是Google在2014年提出一种22层网络的深度学习架构,通过对卷积神经网络的传统卷积层进行修改,提出了Inception结构用于增加网络模型的深度和宽度,并在减小网络参数数量的同时提高了神经网络的学习能力。BN-Inception是在Inception V1基础上进行了改进,一方面使用两个3×3卷积代替Inception结构的5×5卷积,另一方面增加了Batch Normalization层,进一步降低网络的参数数量,同时提高了网络训练速度。
3.3 多分类器融合
对于多个独立分类器融合(Multiple Classifier Fusion MCF)[13],常分为有监督分数融合[14]和无监督分数融合。其中有监督分数融合是将每个分类器的输出作为另一个分类器的输入再次进行训练,为了设计一个端到端的行为识别算法,本文基于无监督分数融合方式设计多分类器融合算法。
设V为卷积神经网络的输入(子序列片段或深度运动图),{ }1,2,...,c为设定数据集的类别标签,M为独立分类器的数量,Pi,j(V)表示在第i个分类器下类别标签为j的预测分数,则决策矩阵可表示为
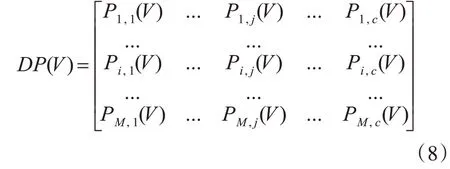
目前常用的多分类器无监督分数融合有加权求和融合(weight sum rule)、乘积法(product rule)和投票法(majority voting)。
1)加权求和融合
对于一个测试深度图序列V,首先利用求和法得到三路BN-Inception网络的融合分数B NV,然后使用不同的权值融合ResNet(2+1)D网络和BN-Inception网络的预测分数,得到视频序列V在多路卷积神经网络结构下的预测分数scoreV:
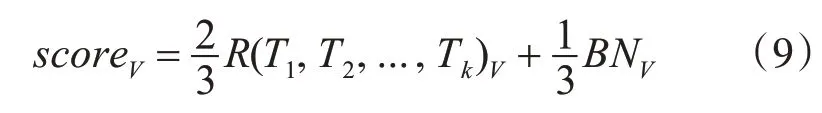
2)乘积法
设类别标签j在M个分类器下得到的预测分数矩阵DV(V)如下:

根据product rule,类别标签j的融合预测分数如下:

3)投票法
对于视频序列V,传统投票法是分别统计各个分类器给出的类别标签,最后选择类别标签重复次数最多的标签作为最终的分类结果,如果存在多个相同重复次数的标签,则会在相同次数标签中随机选择一个标签作为最终的分类结果。
基于多分类器融合方法中的均值法和乘积法,提出一种改进的加权乘积融合法(weight product rule)。对于任意一个测试深度图序列V,利用均值法求得三路BN-Inception网络下类别标签为j的预测分数:
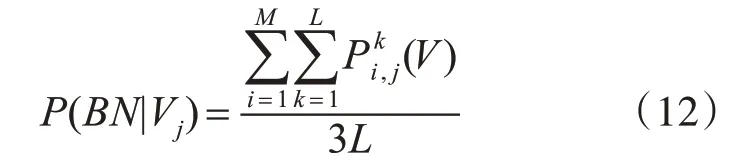
其中M=3表示三路BN-Inception网络对应的softmax分类器,L表示时间尺度,(V)表示在第i路BN-Inception网络对应的softmax分类器下,时间尺度为k且类别标签为j的预测分数,P(BN|V j)表示在三路BN-Inception网络下,类别标签为j的均值融合分数。
在多路卷积神经网络下,类别标签为j的乘积融合分数如下:
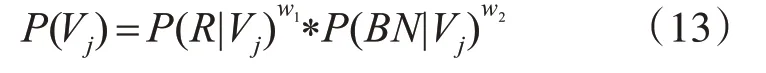
其中P(R|V j)由式(7)计算得到的类别标签为j的分 数,w1,w2为 对 应 的ResNet(2+1)D网 络 和BN-Inception网络的权值,最后测试视频序列V的类别标签判定如下式所示:
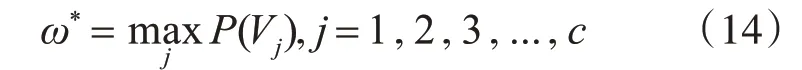
其中ω*表示最终识别的类别标签,c为设定的类别标签。
4 实验结果与分析
4.1 参数设置
在数据预处理中,时间尺度L设为5,即采样间隔l取值分别为1,2,3,4,5。在三路BN-Inception网络中,网络模型采用基于动量值为0.9的批处理随机梯度下降法和误差反向传播进行模型参数更新,网络训练参数设置如文献[15],同时使用在ImageNet[16]的预训练模型,批次次数设置为64,学习率设置为0.001,训练的最大迭代次数设置为20000次,其中每5000次迭代学习率下降0.1倍。在ResNet(2+1)D网络中,网络训练参数设置如文献[9]。利用caffe2实现ResNet(2+1)D网络结构,同时使用基于Kinetics[17]的预训练模型,批次次数设置为4,学习率设置为0.0002,训练的最大迭代次数设置为40000次,其中每10000次迭代学习率下降0.1倍。在改进的加权乘积融合法中,权值w1=w2=1 2。
4.2基于UTD-MHAD数据库的行为识别
UTD-MHAD是由Chen[18]等利用Kinect和可穿戴式传感器制作的RGB-D公开行为数据集,该数据集中存在一些相似动作,如“顺时针画圆”,“逆时针画圆”,因此在该数据集进行行为识别仍有一定的难度。
在上文相机视角扩增中,θ,β分别从[-30°,30°]区间中等间隔取5个离散值,速度扩增中,时间尺度L设为5,同时在UTD-MHAD数据集中,选择序号为奇数的数据作为训练集,其余作为测试集。最后,对所有类别动作的分数使用算术平均法计算最终的识别率。
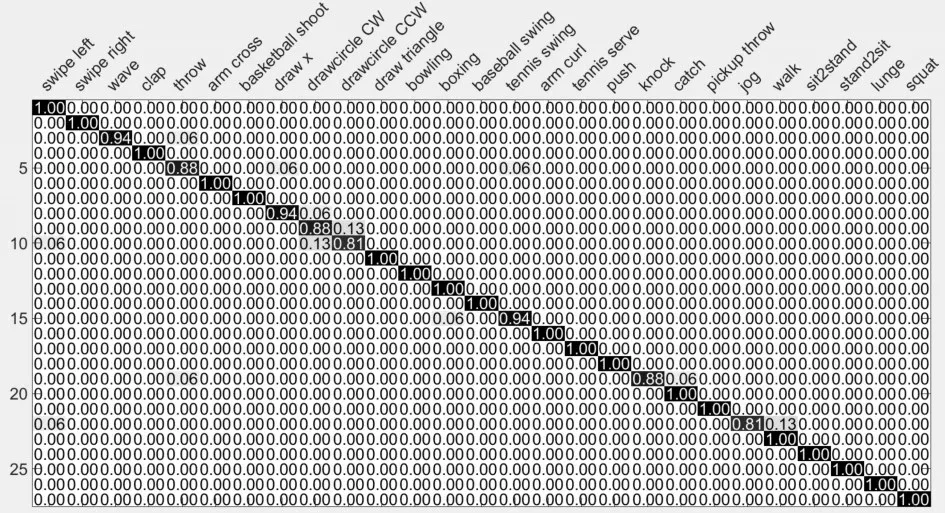
图5 混淆矩阵:平均识别率为96.49%
图5 为本文算法在UTD-MHAD数据集上得到的混淆矩阵,可以看出:本文算法在很多动作上都取得了优异效果,但对于一些相似动作依然存在误识别。表1对比了不同输入流以及不同融合策略的识别效果。可以看出,在不同输入流下,D MM f对应的Softmax分类效果优于DM M s和DMMt对应的Softmax,主要由于将深度图视频序列分别投影到侧平面和顶平面计算得到的深度运动图,会损失部分动作时域信息;在不同融合策略下,结合各个分类器分数的加权求和融合法、乘积法和本文提出改进的加权乘积融合法,优于基于分类器标签的投票法。同时改进的加权乘积融合法相对乘积法提高了0.63%,主要原因是乘积法要求各个分类器都具有较好的分类效果,才能得到较高的识别率,但从表1可以看出DMM s和DMMt对应的Softmax分类效果远低于DMMf对应的Softmax。表2将本文算法与近几年的其他优秀方法进行了比较,相比文献[2]、[6]和[20]分别提高了8.09%、5.29%和3.23%,主要由于R(2+1)D网络结构能有效提取RGB视频序列短时域运动信息,同时在计算DMM时引入能量权重,并且采用改进的加权乘积融合多分类器的结果。
4.3 基于MSR Daily Activity 3D数据库的人体行为识别
MSR Daily Activity 3D[21]数据库是采用Kinect深度传感器录制的人体行为公共数据库,该数据库包含骨骼关节位置、深度信息和RGB视频三种数据。在本实验中我们仅使用了该数据库中的深度信息和RGB视频序列,同时采用和UTD-MHAD数据集相同的数据扩增方式和实验参数。

表1 UTD-MHAD数据库,不同输入流或融合策略的识别率比较

表2 在UTD-MHAD数据库上,现有方法与本文方法的识别率比较
在该数据库上的混淆矩阵如图6所示。可以看出在一些相似动作依然存在误识别,如“看书”与“写字”。表3比较了不同输入流及不同融合策略的识别效果,其中改进的加权乘积融合法相对乘积法提高了1.36%,主要原因是DM M s和D MM t对应的Softmax分类效果远低于D MM f对应的Softmax,因此对三路BN-Inception网络的输出分数采用均值融合要优于乘积法融合策略。表4将本文算法与近几年的其他优秀方法进行了比较,相比文献[23]和[3]分别提高了6.87%和2.45%,相对于UTD-MHAD数据库,MSR Daily Activity 3D数据库背景更为复杂,同时很多动作存在与物体交互的情况,因此识别率提升相对较低。

图6 混淆矩阵:平均识别率为93.75%

表3 MSR Daily Activity 3D数据库,不同输入流或融合策略的识别率比较
5 结语
为了提取行为动作的静态表观和时域运动信息,同时解决行为特征在融合时存在计算量较大,融合后特征维度高等问题,提出了结合RGB-D视频序列和卷积神经网络,并实现端到端的行为识别算法。首先利用ResNet(2+1)D网络提取RGB视频的静态表观和短时域运动信息,三路独立BN-Inception网络提取深度图序列的长时域运动信息,最后利用改进的加权乘积法融合上述四路网络的输出分数,得到最终行为动作的类分数。在两个公开数据集上实验表明,我们的算法对相似动作具有一定的判别性,但如何在样本背景复杂、动作交互的情况下,有效提取行为动作的长时域运动信息,这将是我们下一步的工作方向。
