一种面向硬件实现的二值化模块方案∗
2021-01-19
(江苏自动化研究所 连云港 222061)
1 引言
HEVC[1~2]熵编码器的二值化是将头信息和量化残差系数转化为一系列语法元素,实现对输入数据的预处理和预压缩过程。相比于上下文建模和二进制算术编码[3]来说,二值化的复杂度较低,但仍然存在数据依赖性[4],会影响编码效率以及硬件编码器的实际性能。本文针对二值化在硬件设计过程中存在的问题,提出一种面向硬件实现的二值化模块方案,并验证该方案的可行性,为相应的硬件设计提供参考。
2 二值化过程浅析
HEVC规定的一系列语法元素多以4×4子块为单位,按照头信息、量化残差系数的位置信息、符号信息和幅值信息的顺序依次产生。二值化过程有截断莱斯方法(TR),k阶指数哥伦布方法(EGk)和定长方法(Fixed Length)几种,个别语法元素还采用查表或组合的方式。其中k阶指数哥伦布编码是变长码的一种,具有很好的结构性,由前缀和后缀两部分构成,都依赖于指数哥伦布编码的阶数k。表1列出了帧内编码过程中相关的语法元素及其对应的二值化方式,其中coeff_abs_level_remaining[5]作为最后一个相关语法元素,采用了TR和EGk组合的方式,是二值化过程中的研究重点。
二值化的预处理作用体现在,通过扫描[6]的方式能将二维量化残差系数转化为一维数据,有对角、垂直和水平三种扫描方式[7],并将非零系数尽量靠近排列,为后续处理做准备。这种基于4×4子块的扫描技术适应于所有大小的TU,有利于编码器的模块化[8]。二值化的预压缩作用体现在,硬件设计中一个4×4子块的原始数据可能需要256(16×16)bit的存储空间,二值化后,这个数值将大大减小。经统计,一个4×4子块转化为二元符号bin后,其平均长度远小于输入数据的数据量。

表1 帧内编码的相关语法元素
二值化的数据依赖性主要体现在语法元素coeff_abs_level_remaining的后缀部分的二值化过程中:参数param随着非零量化残差系数的幅值进行自适应更新,幅值越大,param值越大,具体计算公式如下,其中coeff_abs为非零量化残差系数的绝对值:
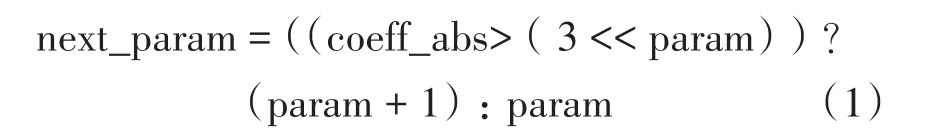
HEVC熵编码器的硬件设计由于其复杂性和数据依赖性等原因,一直是研究的热点,二值化过程也同样如此。以16并行度的硬件系统为例,虽然param的自适应更新能够提高压缩效率,但是硬件系统在一个cycle内要处理16个量化残差系数,需要多次进行式(1)的计算和判断,如果设计不合理,就会造成关键路径过长,影响硬件处理速度,不仅如此,当二值化过程随熵编码过程不断重复计算执行时,会进一步加剧延时的问题。
针对上述问题,本文的目标就是简化二值化的硬件设计,提高硬件效率,基于对二值化的研究分析,提出将参数param由自适应改为固定值,以期待在不过多影响压缩性能的前提下,降低数据依赖性,同时又利于硬件实现,提高硬件处理效率。
3 方案性能验证
本文针对二值化硬件设计过程中遇到的问题提出了一种简化方案,为验证该方案是否可行,对系统的性能影响如何,本文基于HEVC软件参考平台 HM[9]开展了验证工作。
3.1 HM参考平台
HM采用C++语言实现HEVC的完整编解码过程,本文重点关注其中的熵编码部分。经分析,HEVC熵编码器主要有两个作用:一是计算率失真优化选出最优划分和最佳预测模式,二是对选出的最佳组合再进行一次编码。前者需要遍历多种CU、PU、TU大小以及多种预测模式[10~11],针对每一个组合都要进行一次熵编码计算,计算重复率高,如果熵编码模块设计不合理,将大大影响遍历过程的速率,限制硬件编码效率;后者通过编码得到实际的二进制码流,用于后续传输、存储和解码[12],该过程只需要执行一次,但是必须遵循HEVC标准,否则码流不能被正常解码。
3.2 算法修改
通过上述分析,熵编码算法改进需要在遍历选择和最终编码上有所区分,这也为硬件设计提供一种思路:为了加快遍历选择过程,同时又不影响最终的码流结构,在硬件设计时,可以牺牲一定的逻辑开销,设计两套熵编码器,一套用于遍历选择计算率失真优化,包括本文提出的简化方案等优化或者是算法改进都可以在此基础上进行;一套遵循标准算法,位于整个硬件系统的最末端,用于编码生成二进制bit流,其性能对前期过程影响较小。
本文的主要工作在于分析HM中熵编码器的实际调用关系,构造新函数以及修改遍历选择过程中的二值化实现部分。我们采用HM16.0版本来进行算法的修改和性能验证,如果方案可行,该平台还将作为硬件设计的参考,指导硬件模块的实现。
图1(a)为HM中熵编码的相关函数调用关系示意图,HM的遍历选择与最终编码分别位于函数compressSlice和encodeSlice中。compressSlice主要完成遍历选择过程,选出最优划分和最佳预测模式,encodeSlice对最优划分和最佳预测模式执行最终的编码。两者均调用底层函数codeCoeffNxN,二值化就位于该函数中。但是如果仅简单修改函数codeCoeffNxN的二值化部分,会导致最终生成的二进制码流不能被正常解码。为了避免该问题,本文将遍历选择和最终编码时的熵编码处理区分开来,为函数encodeSlice重新构造了一系列新的子函数,具体调用关系如图1(b)所示。
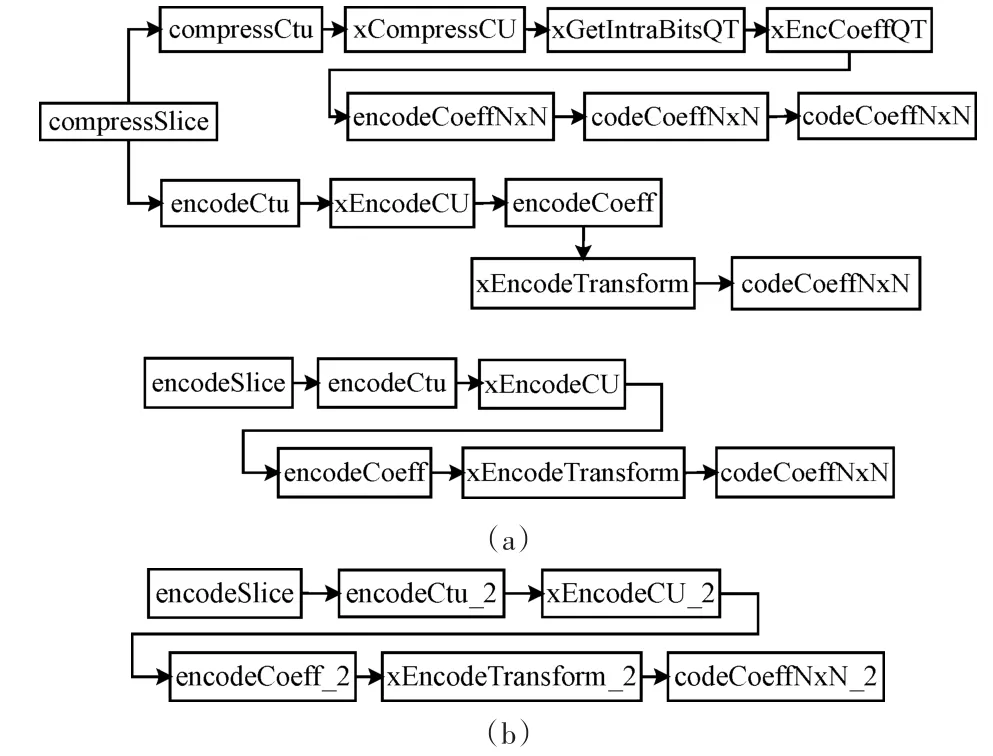
图1 熵编码函数调用示意图
新构造的函数用于执行最终的实际编码,其中底层函数codeCoeffNxN_2在二值化过程中保持采用自适应更新param参数。此外,encodeSlice过程中涉及的大量的函数递归调用,也可以参考原始算法实现。函数compressSlice的子函数基本不变,但是需要修改函数codeCoeffNxN的二值化部分,采用固定param值即可。函数codeCoeffNxN和codeCoeffNxN_2虽然都是底层的实际编码函数,但是两者算法不同,输出结果也不同。
3.3 性能分析
在对HM16.0进行配置时,采用全帧内(All Intra,AI)配置文件,其余配置参数采用默认值,QP采用标准测试组(22、27、32、37)。我们选取了几种分辨率、纹理和运动特征不同的全灰度视频序列进行测试,具体如表2所示。
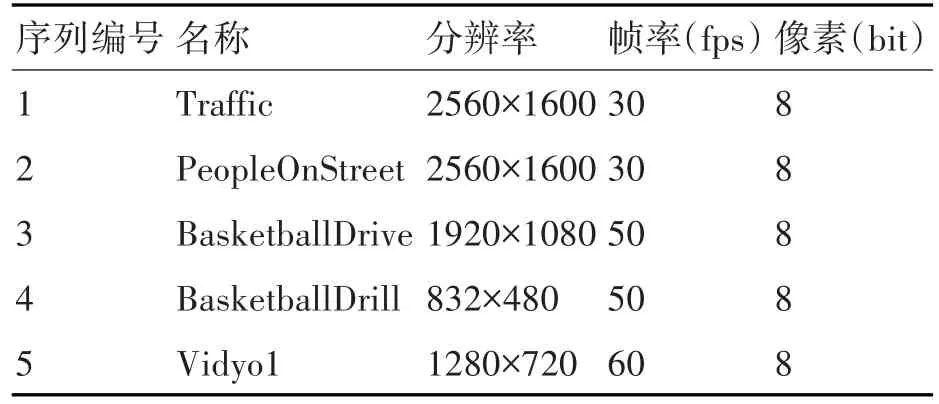
表2 仿真测试视频序列表
量化残差系数是熵编码过程的输入数据的主要部分,而语法元素remaining_value在量化残差系数相关的语法元素中所占的比例也较大,所以对remaining_value二值化的修改势必会影响到二值化结果,最终将会影响到二进制bit流的长度。本文分别统计了算法修改前后不同测试序列在不同QP情况下编码输出的二进制bit流的总长度,具体如表3所示。
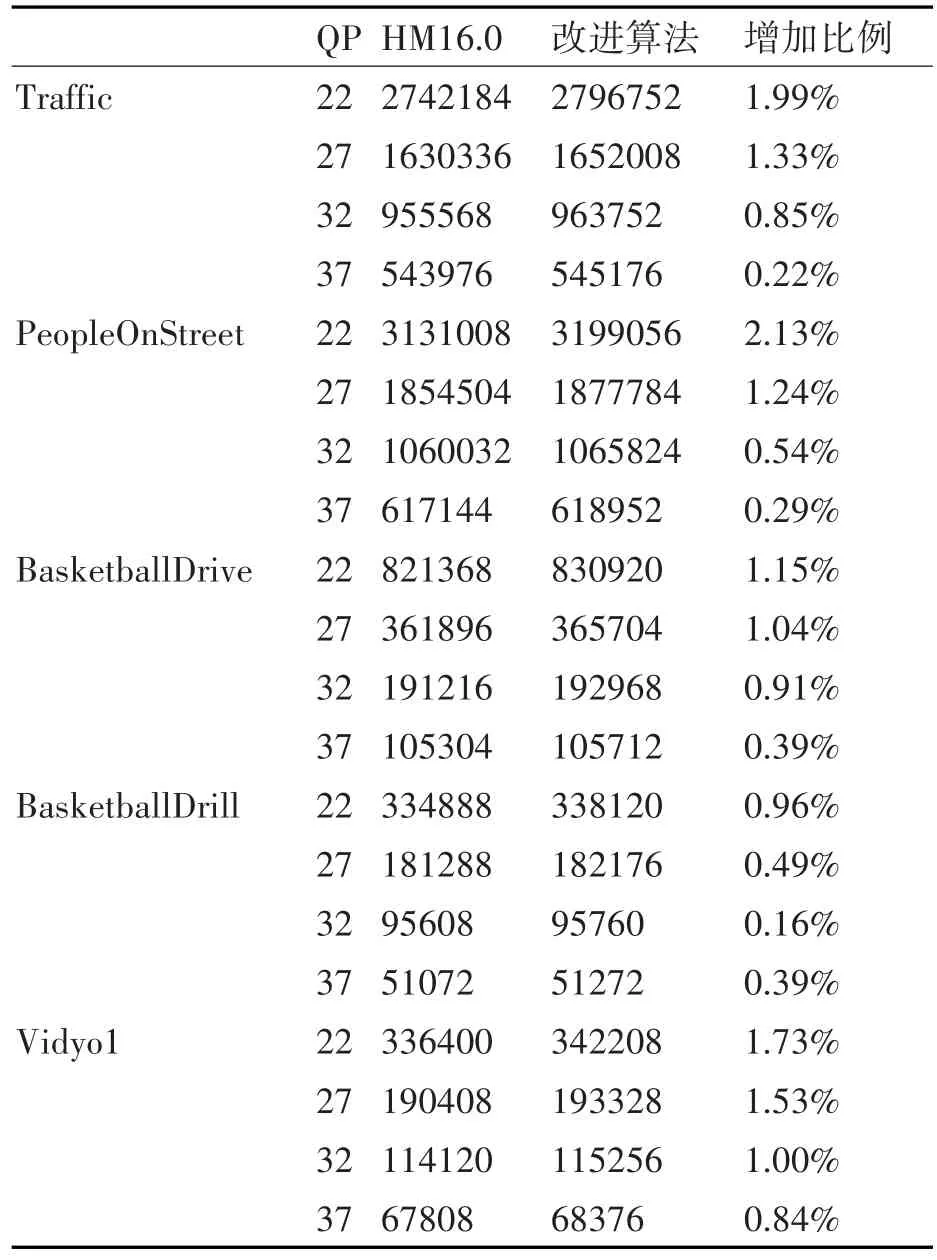
表3 仿真测试视频序列表
由表3可以发现,采用固定参数值会增加最终的二进制bit流长度,也因此反映出了采用自适应param参数进行二值化的优势,这种对最终的码流长度的影响是有限的。但是仅凭二进制bit流的总量变化不足以说明系统性能影响,为了比较算法修改前后的编码性能变化,本文通过BD-rate(Bjontegaard delta bitrate)[13]来评价该方案的整体性能。当BD-rate为正值时,表明在相同PSNR条件下,码率增加,系统性能有所下降,负值则表示码率减少,系统性能有所提高。统计结果如表4所示。
通过表4可以看出,相比于原始自适应更新参数,修改后的算法虽然会导致系统的性能有所下降,但是这种影响很小,在可以接受的范围内,但是该方案却能大大简化硬件的实现,所以该方案具备可行性。
基于上述结论,HM平台还将用于硬件系统的功能验证。硬件系统的输入数据由软件平台打印得到,硬件设计中熵编码的输出结果也将与软件平台进行比较,从而验证功能的正确性。此外,参数param的修改还可能会影响到CTU的最佳划分方式,可以通过专门的码流分析工具来协助验证软硬件的划分方式是否一致。

表4 原始算法与快速算法性能比较表
4 硬件设计思路
经验证,该方案具备可行性,能够为硬件设计提供新的设计思路。结合软件参考平台HM,可以从以下几个方面为硬件设计提供参考。
4.1 硬件整体架构
硬件熵编码器的整体架构可以参考软件算法的修改,采用两套熵编码器,分别用于遍历选择和实际编码。整体架构如图2所示。
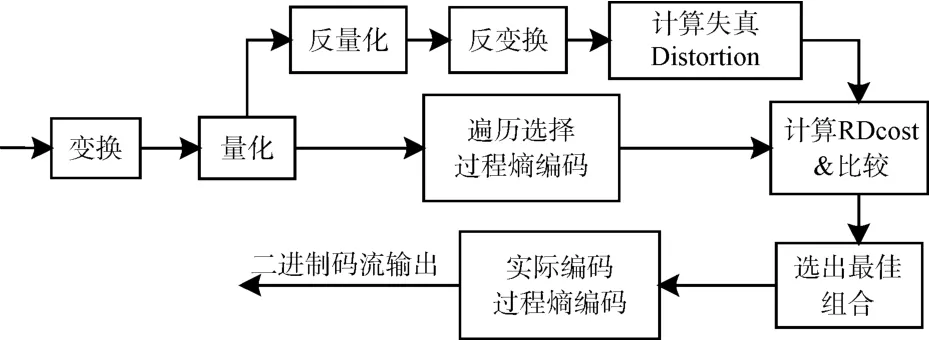
图2 整体硬件架构图
这种架构相比于一般设计来说额外增加了一套熵编码器。虽然增加了逻辑资源开销,但是能够将遍历选择过程与最终编码过程区分开,两者可以根据各自的优化目标进行相应改进,如简化遍历选择过程的二值化部分,提高编码效率,或者是上下文建模、二进制算数编码的优化和架构的改进等。此外,两套熵编码器可以共用的模块有很多,所以在硬件整体架构的修改上,逻辑资源开销的增加是可控的。
4.2 二值化模块
本文针对二值化的数据依赖性问题展开研究,提出了一种硬件友好的二值化方案,经验证,该方案是可行的。具体到硬件实现时,基于硬件整体架构的改变,在遍历选择过程中,语法元素remaining value的二值化采用固定参数param,量化残差系数之间消除了数据依赖性,只需要判断系数是否为非零,无需考虑自适应更新的问题。以16并行度为例,一个cycle就可以快速处理16个系数的二值化,大大加快了遍历进程。
而对于实际编码部分,虽然保持数据依赖性,但是可以通过合理的流水线设计来降低数据依赖性带来的影响,如采用四级流水线结构,每一级处理4个量化残差系数,其编码效率不会影响到前期的遍历选择过程,从而避免影响系统的编码效率。
4.3 并行度
前面均以16并行度为例进行说明,实际上,在硬件设计时可以灵活满足不同并行度的设计需求。但是由于二维量化残差系数以4×4子块为单位,在硬件设计时多采用8或16并行度,即一个cycle处理8或16个量化残差系数。针对遍历选择过程来说,熵编码器的并行度设计需要考虑前后模块的实际处理速度,不同大小的TU块的编码往往需要的时钟数不同,可以通过打拍的方式保持同步。
5 结语
本文针对二值化的硬件设计过程中遇到的问题提出了一种简化方案,不论是在算法修改还是在硬件设计中,都采用两套熵编码器,并改进遍历选择过程的二值化部分,同时保证实际编码过程遵循编码标准不能改变。随后本文基于HEVC软件测试平台HM进行算法修改和性能验证,为硬件设计提供参考。该方案的优势在于能够简化硬件设计,提高编码效率,同时对系统性能的影响基本可以忽略不计。后续还可以在本文的基础上进一步研究:
1)param的不同取值对编码性能的影响是否存在最佳;能否通过某种方式模拟参数param的自适应更新,如分段取值、设定动态阈值等方式。
2)在算法改进与硬件设计过程中,对遍历选择和最终编码两者的熵编码有不同的研究目标。前者在于如何能够更快更好地完成最佳组合的选择,后者在于如何在遵循HEVC标准的前提下优化架构设计。上下文建模和二进制算术编码两部分也是研究的重点,可以基于本文开展进一步的优化研究。
