基于Levenshtein距离的Word操作题自动评分算法
2021-01-18罗泉刘芝
罗泉,刘芝
(1.广西大学行健文理学院,南宁 530005;2.南宁师范大学,南宁 530001)
0 引言
《大学计算机基础》是大多数高校的通识必修课程,学生们通过学习后能熟练掌握Word、Excel、Power⁃Point等软件的常用操作,这就需要任课教师能督促学生完成课堂、课后练习并及时修改。但由于班级众多,任课教师需要大量时间进行批阅修改。为了减轻教师负担,众多学者对Office操作题的自动评分进行了研究,采用的方法主要有几种。
方法1:使用Office内嵌的VBA技术或Office提供的COM接口,读取考生文档每个元素的属性信息,依次与标准答案的属性信息进行比较,根据得分点自动计算出分数[1-3]。
方法2:通过计算考生文档与标准答案之间的文本距离,获得两者之间的相似度,实现操作题的自动评分[4]。
方法1依赖于Office软件,不适用于多线程、高并发情景;方法2适用于考生从空白文件创建答卷文档的情景,而不适用于从给定素材创建答卷文档的情景。例如,素材文件有文字“Hello”,题目要求在素材基础上添加信息,并得到最终文字“Hello World”。若考生将素材文件作为答卷提交,按方法2会得到50分,但实际应为0分。
依据上述分析,本文针对学生基于素材完成操作练习的场景,基于编辑距离实现了一种Word操作题自动评分算法,并对算法进行了测试验证。
1 Word OpenXML文件格式介绍
微软从Office 2007开始使用OpenXML[5]格式来存储信息,一个Office文档由多个XML文件构成,每个XML文件被称为部件,用于存储不同含义的信息。将Word文档后缀名改为zip并解压,可以得到如图1所示的目录结构。

图1 Word的OpenXML目录结构
图1中,styles.xml包含Word样式信息,分别存储在
2 Levenshtein距离
Levenshtein距离即文本编辑距离,提出于1965年,是字符串A通过编辑(添加、删除、修改)单个字符,最终修改为字符串B所用的最少步骤次数,主要用于度量两个字符串间的距离[7]。其公式如下:

在本文中,Levenshtein距离主要用于度量两个XML片段间的距离,如片段 A:
(1)定义innerNode类型,innerNode.label用于存储文本
(2)创建innerNode类型数组NodeArray
(3)依据片段的开始标签,构造innerNode对象,使 innerNode.label=”A”,添加到 NodeArray数组尾部
(4)依据片段的属性名attr1,构造innerNode对象,使 innerNode.label=”attr1”,添加到 NodeArray 数组尾部
(5)依据片段的属性值val1,构造innerNode对象,使innerNode.label=”val1”,添加到NodeArray数组尾部
(6)依据片段的文本abc,构造3个innerNode对象,使每个对象的 label分别为”a”、”b”、”c”,并依次添加到NodeArray数组尾部
(7)依据片段的结束标签,构造innerNode对象,使 innerNode.label=”/A”,添加到 NodeArray 数组尾部
当比较两个innerNode类型对象是否相等时,等价于比较对象的label值是否相等。经过转换,本节例子中片段A与片段B之前的编辑距离转成了计算Node⁃Array数组A和NodeArray数组B之间的编辑距离,计算过程与公式(1)一致,最终结果为1。
3 自动评分算法实现
课堂上,在Word操作练习时,教师为学生提供素材文档,学生基于素材,按照标准答案效果进行操作。因此,评分算法基于素材和答案文档进行度量更为合理。
(1)XML文件的特征节点向量
一个XML文件可以看成有序特征节点t[i]的集合,可表示为:
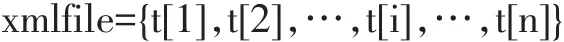
其中,t[i]拥有 name、NodeArray属性,name 表示当前特征节点名称,NodeArray表示该节点XML片段转换而成的innerNode类型数组。
设xmlfilename是xmlfile中所有name属性值相等的元素的集合,则有:
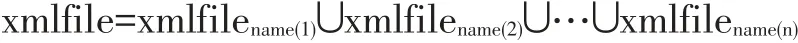
(2)XML 文件编辑距离 xdist(xmla,xmlb)
设A、B分别为文件xmla、xmlb的特征节点向量,Aname、Bname分别是A、B中所有name属性值相等的元素的集合。分别向A、B中添加NodeArray长度为0的元素,使|A|=|B|并且|Aname(i)|=|Bname(i)|,则两个 XML 文件的编辑距离计算方式如下:
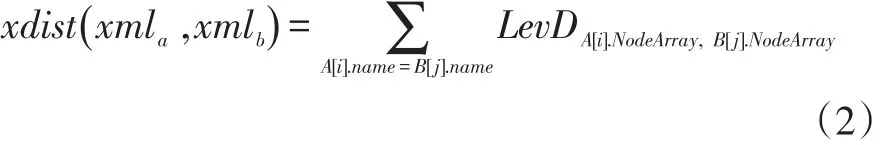
其中,A[i]属于 A,B[j]属于 B,A[i]、B[j]必须且只能参与一次LevD运算,A中的元素按顺序与B中name属性相同的元素进行LevD运算。
(3)Word文件距离向量
一个Word文件由多个XML文件构成,为此可表示为 docx={f[1],f[2],…,f[n]},其中,f[n]为一个 XML 文件,按短文件名顺序排列。
定义两个Word文件docxA和docxB之间的距离向量为两文件之间同名XML文件的编辑距离的有序集合 wVector(docxA,docxB),计算方式如下:
商务笔译,顾名思义,是针对商务文本的翻译。对于商务笔译的研究涉及两个关键词:一个是商务文本,另一个是翻译。关于商务文本,需要梳理清四个问题:1)什么是商务文本?即商务文本的涵盖范围和种类。2)商务文本的分类方式如何?3)商务文本的功能是什么?4)商务文本的文体风格是什么?关于翻译,需要梳理清三个“谁”的问题:1)作者是谁?2)译者是谁?3)读者是谁?只有理清了以上的问题,才能进入到下一步讨论,即什么样的翻译理论对商务笔译有切实的指导作用?本文将主要讨论文本类型理论视角下的商务笔译。
wVector(docxA,docxB)={v[1],v[2],…,v[n]},其中 v[i]=xdist(fa[i],fb[i]),fa[i]∈docxA,fb[i]∈docxB,fa[i]和 fb[i]的短文件名相同。
(4)Word操作题自动评分算法
有 Word 文件 d0、dx、d100,其中 d0 表示素材,dx表示学生答卷,d100表示答案。评分的基本思路为:以d0为基准,分别计算dx到d0的距离向量vx、d100到d0的距离向量v100,然后依据vx在v100上的投影计算分值。
①计算vx=wVector(dx,d0),vx为学生答卷与原始素材文件的文件距离向量。
②计算 v100=wVector(d100,d0),v100 为答案文件与原始素材文件的文件距离向量。
③计算两个向量vx、v100之间的余弦cosθ=vx·v100/(|vx|·|v100|)
⑤计算百分制成绩score=100*projection/|v100|
⑥将百分制成绩转换成等级成绩level,当score<60时为一等级,否则每10分为一等级,等级划分从高到低为 A、B、C、D、E。
4 实验验证
本文选用一套综合练习题,由48位学生在课堂上完成,使用等级成绩,以人工评分为基准,对比本文算法与文献[4]算法,验证评分效果。
该综合练习题提供基本素材文件,由学生在此基础上完成文字替换、字体颜色设置、段落格式设置、添加SmartArt图形等操作,限时30分钟完成。首先由教师课后人工评分,结果如表1所示,绝大部分学生能在限定时间内完指定练习,有3位学生讲所提供素材作为最终成果提交,人工评分应为0分,等级为E。

表1 人工评分结果等级分布
在人工评分之后,分别使用本文算法、文献[4]算法自动给学生作品评分,并与人工评分结果比较,使用聚类中常用的Precision准确度、Recall召回率、F1-Score等指标来评价两种算法哪一个更优[8];通过记录两种算法的运行时间来评价其执行效率。一般来说相关指标数值越大表明越优,实验结果如表2、表3所示。
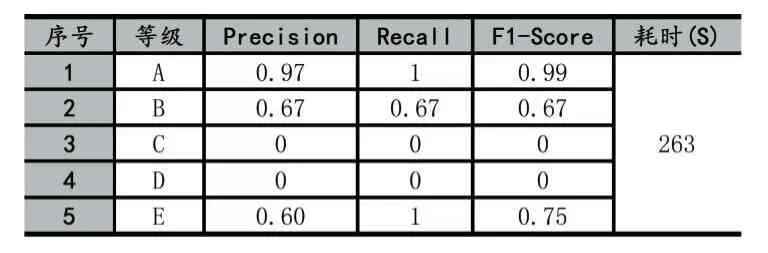
表2 本文算法实验结果

表3 文献[4]算法实验结果
从表2、表3中可以看出,在A等级中,Recall为1,说明人工评分中为A的所有成绩,在两种算法中均评定为A,表2的Precision指标比表3的相应指标略高,说明本文算法比文献[4]算法略优;对于人工评分判定为E等级的3位学生,表2的Recall为1,说明本文算法判定其成绩为E等级,表3的Recall为0,说明文献[4]算法判定为其他等级,因此本文算法更为准确合理;在执行效率上,本文算法所消耗时间263秒,比文献[4]算法少。综上所述,在所选测试样本数据下,与文献[4]算法相比,本文算法较优,且能满足日常练习的操作题评分要求。但由于本文算法忽略不同操作步骤的权重,因此无法根据作品所完成的步骤评分,尚未做到与人工评分完全一致。
5 结语
本文针对学生在素材基础上完成操作练习的场景,设计了一种基于Levenshtein距离的Word自动评分算法,通过计算学生作品文件与原始素材、答案文件之间的距离,通过一系列运算自动获得该作品分数等级。实验结果表明,该算法在为等级A、E的作品评分时有较高的精确率,日常的练习评分中有较好的应用效果,可有效提高老师的工作效率,但不足之处在于不能调整步骤分值,不能为操作的每一个步骤设置得分权重,而且测试样本容量较小,不能覆盖所有的操作测试,有待进一步完善。
