多关系网络上的社区发现
2021-01-17李丛正
李丛正,梁 垒,周 强
(1.青岛大学 数据科学与软件工程学院,山东 青岛 266000;2.浙江大学 计算机科学与技术学院,浙江 杭州 310027)
0 引 言
本文研究的多关系网络的边的类型有多种,其属于异构网络的一类[1]。社区发现是在网络上进行数据分析时的重要工作,它的目的是对网络上的节点进行划分,使得划分在一个组内的节点间联系尽量紧密,不同组的节点之间联系相对稀疏[2]。其在挖掘网络结构,揭示群体行为等方面有着重要意义,因此近些年来有大量相关方面的研究。传统的方法一般是基于单关系网络,例如基于遗传算法的方法[3]、基于信息熵的算法[4]、谱聚类算法[5]、基于模块度的算法[6]等。在多关系网络的社区发现方面,文献[7]提出的CDMN 算法建立了多关系网络模型并定义了节点影响力,实现多关系网络社区发现。文献[8]使用RCA 技术对多关系学术网络进行建模并在此基础上进行社区发现。MultiNetCom 算法将原多关系网络拆分成多个单关系网络,在每个单关系网络上分别做聚类操作后再依据节点对各个类的从属关系将多个单关系网络融合成一个单关系网络进行社区发现[9]。文献[10]使用关系贝叶斯模型对多关系网络进行建模。以往的工作或是对原网络做转换,或是考虑不同关系间的相互影响及关系强度对网络进行重新建模再进行社区划分,并没有直接在多关系网络上利用节点间的各种关系对节点进行划分,网络的多关系信息存在丢失。
针对上述社区发现中存在的不足,本文提出基于机器学习的多关系网络社区发现算法,在考虑到不同类型边之间的差异的前提下,使用本文定义的方法计算不同类型边的权重,再利用本文设计的多关系网络数据采集策略直接在多关系网络上提取训练数据,然后利用采集到的数据训练多关系网络节点表示模型,得到网络上每个节点对应的向量表示,最后对向量空间中的向量进行聚类,同一个类中的向量所对应的网络上的节点则属于同一个社区。
1 相关工作
Mikolov 等提出的word2vec 在自然语言处理领域有着重要的地位,它利用深度神经网络模型,基于大规模语料进行训练,然后用低维且稠密的向量表示语料中的单词。其中一个深度模型是Skip-gram。Skip-gram 是在一个句子上用滑动窗口w采样,然后最大化出现在同一个窗口w中的中心单词和邻居单词的共现概率。
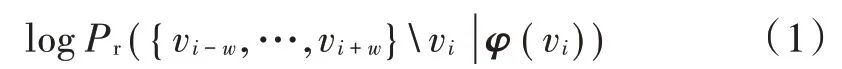
式中:vi是窗口内的中心单词;vi-w~vi+w是其上下文单词;φ(vi)是节点vi映射在向量空间中的向量。通过梯度下降等方式更新φ(vi),得到最终的向量表示。由式(1)可知,单词的上下文集合相似时,它们的向量表示也是相似的。从几何角度讲,这些向量的距离更相近。例如,图1 所示的例子中表示的是一些经过训练的词向量在二维空间中的可视化表示。

图1 词嵌入的实例
语义相近的词(例如动物类中的COW 和LION)因为在训练的语料中有着相比于其他类中的词(例如ASIA)而言更加相似的上下文单词集合,所以在经过大量数据训练后,它们的表示向量也会更加相似,在二维可视化的展示中表现为更加“临近”。用K-means 等聚类算法对这些词的表示向量进行聚类则可以将上下文相近的词(例如COW 和LION)归为一类。
2 基于机器学习的多关系网络社区发现算法
定义多关系网络G=(V,E,W),式中的V={V0,V1,V2,…,Vn}为节点集合,E={E0,E1,E2,…,Em}为边的 集 合 ,W={W0,W1,W2,…,W m} 为 边 的 权 重 。node2vec[11]等算法设计了先在网络上游走,得到游走的节点序列,然后将序列类比自然语言中的句子,序列中的节点类比单词,再计算节点的表示向量。本文设计了面向多关系网络社区发现的游走采样策略,得到节点序列,利用滑动窗口从节点序列中生成训练数据,然后对本文提出的节点表示模型进行训练,进而得到节点的向量表示。因为社区划分的定义为将网络中相互联系比较紧密的节点划入到同一个社区,如果用滑动窗口在游走得到的节点序列上滑动取得训练数据时,联系紧密的节点有相似的上下文集合,那么这些节点的向量表示也会相似,而且出现在同一个节点序列上的两个节点A和B,即使不能在滑动窗口取得训练数据时有相似的上下文集合,由于同一个节点序列上其他节点的影响,A和B的向量表示在经过更新计算后相比于未和A,B出现在一个节点序列的其他节点也会更相似。
如图2 所示,在节点序列<a,b,c,d,e,f,g,h,i,j,k,l>上使用长度为5 的滑动窗口获取训练数据。当c为中心节点时,其上下文为集合{a,b,d,e},j为中心节点时,其上下文节点集合为{h,i,k,l},两个集合无交集,可知c和j的上下文节点集合无相似性。但是在g为中心节点时,其上下文节点集合为{e,f,h,i},与c及j的上下文的交集分别为{e}和{h,i},所以c和j的表示向量会在一定程度上与g的表示向量相似,进而可得c和j的向量表示也会在一定程度相似。由此可以证明,如果能让联系紧密的节点有更高的频率出现在同一个游走得到的序列上,同时训练时选择合适的滑动窗口(在保证对模型训练量不会过大的情况下窗口越长越好)来提取训练数据,在经过大量训练数据训练后,它们的向量表示就会更加相似,再进行聚类后它们就更有可能分在同一个类中,由此实现将联系紧密的节点划分入同一个社区中。
本文提出的MLCDM 算法计算节点的向量表示的流程如图3 所示。
首先在原网络上进行面向社区发现的游走,并将游走得到的路径集合P={P0,P1,P2,…,Pm}记录下来,然后计算在滑动窗口w里,中心节点vi与其上下文节点vj的共现概率,使用梯度下降方法进行更新计算,训练节点的表示模型,最终得出网络上节点的向量表示。

图2 节点序列上提取训练数据
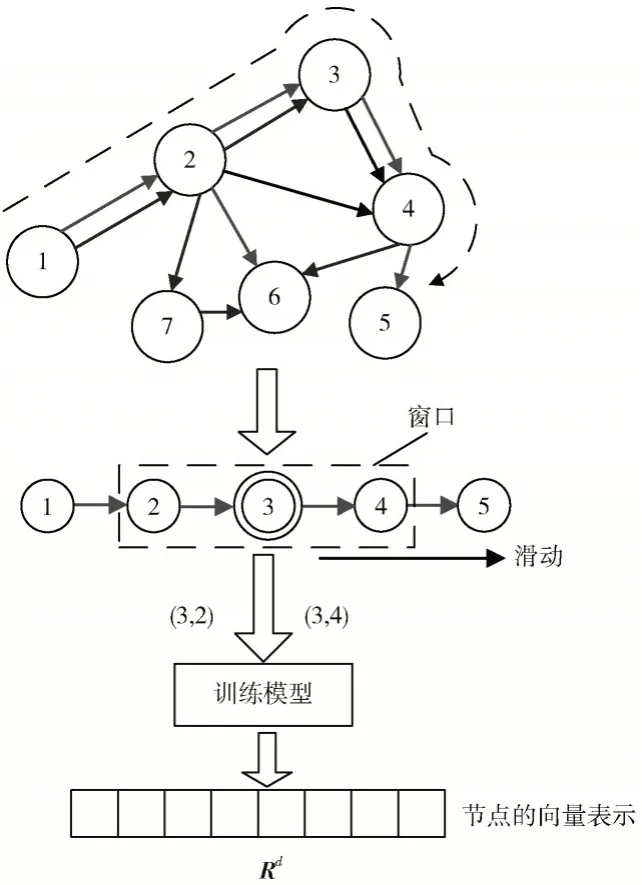
图3 节点的向量表示的计算流程
2.1 游走采样
游走的目的是得到若干条面向社区发现的游走采样路径的集合P={P0,P1,P2,…,Pm}。每条路径的形式为一个节点序列<v1,v2,…,vk>,在同一个序列中相邻两点间游走的边是图上的同一类边。
GN 等算法指出,介数中心性大的边更有可能是社区之间的连接边,所以本文设计的游走策略更倾向于选择介数中心性小的边,这样就会有更大的概率是在同属一个社区同时联系紧密的节点间进行游走,所以在游走采样前先对每条边的介数中心性进行计算。
针对多关系网络,第一步游走要确定这条采样路径要游走的边的类别,第一步选择边时是在当前节点的临边中随机选择,未考虑介数中心性。

式中:Enow是当前节点的集合;Pr(e)是此节点的每条临边被选中的概率。
在接下来第二步、第三步等进行游走时,当前节点的某条临边被选到的概率用式(3)计算。首先选出和上一步游走一样种类的边,然后对其依据介数中心性从小到大进行排序,将其中的前50%(符合要求的临边数不是2 的倍数则选择前(符合要求临边数+1)×50%)条边存入集合ET,然后在ET中随机选择一条边进行游走。

算法1:面向社区发现的多关系网络游走
Input:多关系网络G,网络节点数N,节点按照0,1,2,…,N-1进行编号,游走路径的最大长度D,以每个节点作为开始节点进行游走的次数C,边的种类数Q
Output:游走采样得到的集合Walk
1. 初始化节点序列的集合Walk={Walk0,Walk1,…,WalkQ}
Walkm是游走类型为Em的边时得到的节点序列集合
初始化 Walk0,Walk1,…,WalkQ都为空
2. fori=0 toNdo
3. //以节点Vi为起点开始游走
4. forc=0 toCdo
5. ford=0 toDdo
6. if(d==0)then
7. 按照式(2)得到临边被选到的概率,选择第一步游走的边(Em),记录游走到的节点
8. else
9. 按照式(3)得到临边被选到的概率,选择下一步游走的边,记录游走到的节点
10. END for
11. 将节点序列按照游走的边的类别(Em)存入相应的集合(Walkm)
12. END for
13. END for
14. return Walk
2.2 计算每个节点对应的向量表示
在上一步游走采样得到的路径上用长度为k的窗口从路径的起点开始滑动,依次对窗口当前中心点的向量表示进行更新计算。例如在图3 中的第二步,游走得到的节点序列为<v1,v2,v3,v4,v5>,其长度为5,滑动窗口的长度取3,当中心节点为v3时,上下文节点为{v2,v4}。节点vj作为节点vi上下文的概率,即共现概率可以被定义为:
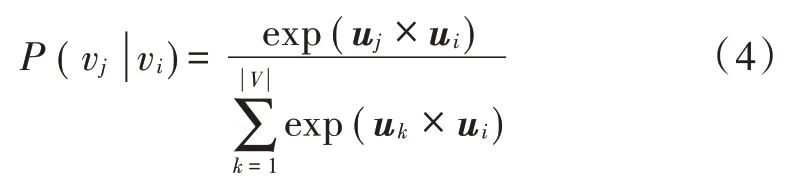
式中:uk为节点vk的向量表示为图上所有节点的数量。当把网络上的不同类型的边同等看待时,可以得到目标函数:
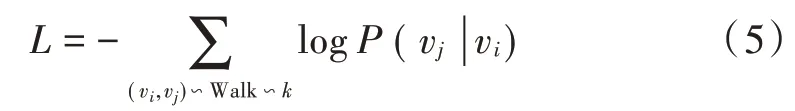
通过更新计算式(4)中节点的向量表示,最小化式(5)。其中:Walk 是所有的游走路径的集合;k是滑动窗口的长度;(vi,vj)∽Walk∽k表示在游走路径上滑动长度为k的滑动窗口滑动到某一个位置时,窗口的中心节点为Vi,而Vj为其上下文节点集合中的节点。为了更好地实现多关系网络的社区发现,在开始计算向量的表示前先计算不同类型的边在社区发现时的权重。本文定义权重的计算方法为式(6),在已知正确社区划分结果的网络上计算不同类型边的权重,然后将权重应用到边类型相同的另一个网络上进行社区划分。设有n+1 类边,编号为 0,1,2,…,n,em表示编号为m的边落在社区内部的数量,Em表示编号为m的边在网络上的总边数,W m为编号为m的边的权重。则:

当使用Walkm(算法1 的输出)中取得的数据更新计算节点的向量表示时,将式(6)结合式(4)和式(5)得到目标函数为:

使用Walkm中取得的数据更新计算节点的向量表示时,对应的中心节点与邻居节点的共现概率为Pm。
2.3 模型优化
按照2.2 节中的方法计算上下文节点与中心节点的共现概率P时,计算量比较大而且花费的时间长。为了提高计算效率,缩短计算时间,本文引入负采样的计算方法[11]。例如式(7)中的某一个中心节点Vi和它某一个上下文节点Vj组成的节点对(vi,vj),可得目标函数为:

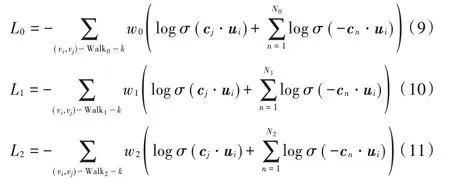
节点的向量表示是用梯度下降法(SGD)计算的。例如,利用在Walkm中的路径上用滑动窗口取得的数据(vi,vj)对vi的表示ui更新计算时为:
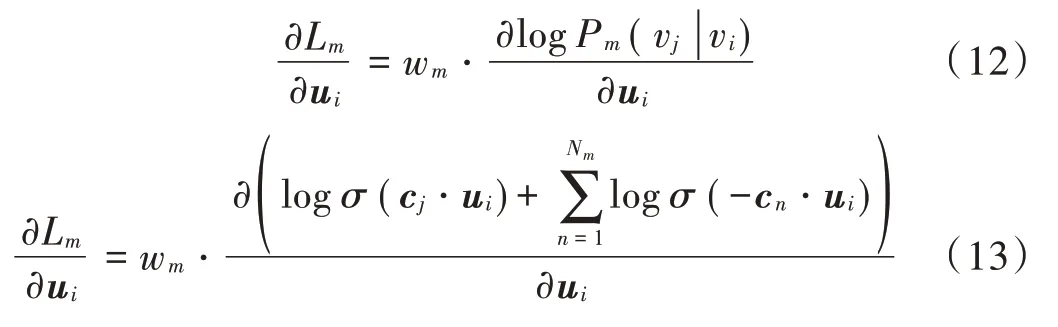
2.4 聚 类
本文使用的聚类算法是K-means。K-means 有很多优点,例如收敛速度快、聚类效果优、模型可解释性强等。但它也有不足,原算法初始簇中心点是随机选择的,聚类时簇中心点的选择会直接影响最终的聚类结果。本文在聚类前先对节点的接近中心性进行计算,选择接近中心性较大的作为中心点,以达到更好的聚类效果。
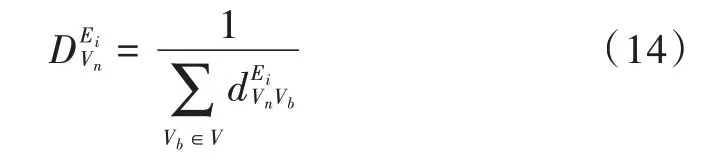
算法2:MLCDM
Input:多关系网络G1,与G1的边的类型相同的先验数据集G2,网络G1的节点数N,游走路径长度D,滑动窗口的长度k,以每个节点为起始节点进行游走的次数C,节点表示向量的维度dim,边的种类数Q,社区数目A
Output:社区划分结果R={R0,R1,R2,…,RA-1}//Ra为属于社区a的节点集合
1 利用先验数据集G2及式(6)计算不同种类的边的权重
2 在G1上执行算法1,得到节点序列集合Walk={Walk0,Walk1,…,WalkQ}
3 forq=0 toQdo
4 fora=0 to Size Of(Walkq)//遍历Walkq中每条路径
5 在Walkta(Walkt中的第a+1 条路径)上把长度为k的滑动窗口从头滑动到尾,提取训练数据,并用式(13)对节点的向量表示进行更新计算。
6 END For
7 END For
8 利用式(14)计算节点的中心性,并选取中心性较大的作为簇中心
9 使用K-means 对节点的表示向量进行聚类,同一类中的向量对应的节点被分到一个社区,得到R
10 returnR
3 实 验
为了验证MLCDM 算法的性能,本文分别在单关系网络和多关系网络上进行实验,本实验共使用6 个数据集,2 个单关系网络,4 个多关系网络。
3.1 单关系网络上的实验
首先在有已知正确社区划分结果的单关系网络上进行实验。在这里选择两个常用的单关系网络社区发现的数据集、Zachary 俱乐部网络和Dolphin 社交网络。Dolphin 网络有62个节点、160条边,Zachary 网络有34个节点、78条边。这两个数据集的官方公布社区数均为2。将本文提出的MLCDM 算法与CDCDA 算法[12]及MNDP算法[13]进行比较。在这里使用标准化互信息NMI 衡量实验中社区划分的效果。NMI 衡量当前算法划分结果和官方公布的划分结果的相似程度,其范围为0~1,这个值越大则实验结果与官方结果越接近,算法的效果越好。

式中:N是节点的数量;C是指示矩阵;Ci表示在算法A划分中属于社区i的节点数;Cij表示在算法A 的结果中属于社区i,同时,在算法B 的结果中属于社区j的节点数量;CA(CB)表示应用算法A(B)后得到的社区数目。图4 是在Zachary 和Dolphin 网络上的实验结果。

图4 单关系网络上的实验结果
表1 是在单关系网络上的实验结果对比,可以看出本文提出的MLCDM 算法相比于对比算法有较好的划分效果。
3.2 多关系网络上的实验
在多关系网络的实验中使用4 个多关系的twitter 网络:politicsIe、politicsUK、football 和 rugby[14],这 4 个网络都有已知的官方正确社区划分。首先从原始的twitter信息中提取出用户之间的“关注”“转发”“提及”三种关系,然后将三种关系作为三种类型的边,用户作为节点,建立多关系网络,见表2。

表1 单关系网络上的结果对比

表2 多关系网络数据集
因为5 个数据集都是twitter 网络,属于同种网络且关系的类型相同,所以可以使用式(6)在某一个有先验知识的数据集上对不同关系在社区发现中的权重进行计算,然后在其他数据集上利用得到的权重进行社区发现。在politicsIe 上用式(6)计算在twitter 网络中不同类型的边在社区化分中的权重。在其他数据集上使用MLCDM 算法,其中不同种类的边的权重即为在politicsIe上计算的值。通过在politicsIe网络上应用式(6),得出在twitter 网络中“关注”的权重为0.42,“转发”的权重为0.14,“提及”的权重为0.23。然后在另外3 个多关系网络上利用MLCDM 进行社区划分,通常使用纯净度衡量多关系网络社区发现结果。定义官方公布的正确社区结构为C={C0,C1,C2,…,Ck},当前算法计算得到的社区结构为

式中:n是网络上节点的总数目是Ci与Cj的交集。纯净度越高则算法的社区划分效果越好。
将本文提出的MLCDM 算法与MultiNetCom 算法[9]、Jiang’s 算法[9]及 NCFCM[15]进行对比,结果见表 3。

表3 多关系网络上的结果对比
通过表3 可以看出在多关系网络上进行社区发现时,本文提出的MLCDM 算法的纯净度和其他几种算法相比较高,与官方公布的社区划分结果更接近,划分效果更好。
4 结 语
实际的网络上通常存在着多种关系,将所有关系等同看待或者将原网络进行拆分后再进行社区发现都会使多关系信息有所丢失,为了更好地完成多关系网络上的社区发现任务,本文提出基于机器学习的多关系网络社区发现算法MLCDM。主要贡献点有综合考虑多关系网络上的不同类型的边,定义了计算各种类型的边在社区发现时权重的方法,设计了面向社区发现的多关系网络数据采集策略,用采集到的数据对节点的表示模型进行训练,得到节点的表示向量,再对其进行聚类以实现社区发现。最终实验结果表明本文提出的MLCDM 算法和近几年的几种算法相比,在单关系网络和多关系网络上都有较好的效果。今后主要研究的问题有两个:解决当多关系网络结构随时间动态变化时的社区发现问题;改进边的权重的计算策略,使得其可以根据社区发现的结果反馈进行动态更新。
注:本文通讯作者为周强。
