基于注意力机制的商家招牌分类研究
2021-01-15郑雨薇魏少玮胡克勇
李 兰,郑雨薇,魏少玮,胡克勇
(1.青岛理工大学 信息与控制工程学院,山东 青岛 266520;2.西安电子科技大学 人工智能学院,西安 710071)
0 概述
商家招牌作为商家标志,其识别和分类问题虽然耗费大量时间及人力,但是对于传统营销的网络涉入、消费者的线上线下互动、商业信息的挖掘与电子商务数据库的管理等实际应用场景有重要作用[6-8]。本文以在自然环境下拍摄的商家招牌图像为研究对象,采用基于卷积神经网络(Convolutional Neural Network,CNN)的深度学习算法对商家招牌进行分类,利用卷积块注意力模块(Convolutional Block Attention Module,CBAM)改进现有网络结构,并联合使用余弦间隔损失函数对其进行训练。
1 相关工作
根据使用的监督信息不同,细粒度图像分类可分为基于强监督的细粒度图像分类与基于弱监督的细粒度图像分类。其中,基于强监督的细粒度图像分类方法主要利用如Part-RCNN[9]的目标检测思想,先在图像中检测出目标的所在位置,再检测出目标中有区分性区域的位置,接下来将目标图像(即前景)以及具有区分性的目标区域块同时发送至深度卷积网络中进行分类。然而,基于强监督信息的细粒度图像分类需依赖更多的人工标注信息,如目标物体的边界框信息和关键点信息,且在实际应用中,这些标注信息的获取耗时耗力,使得其应用受到限制。因此,研究人员开始关注基于弱监督信息的细粒度图像分类方法,该方法仅需使用标签信息,而无需额外的标注信息,且通常采用如AlexNet[10]、VGG[11]、GoogleNet[12]与ResNet[13]等常见的深度卷积网络直接对图像细粒度进行分类。由于上述分类网络具有较强的特征表示能力,因此在常规图像分类中能够取得较好的效果。然而在细粒度分类中,不同类别之间的差异通常十分细微,直接将常规图像分类网络应用于细粒度图像进行分类时,效果并不理想。在文献[14]提出的Mask-CNN 中,借助全连接神经网络学习一个部件分割模型。该网络对图像进行精确的部件定位预测并将其分割出来,且经过3 个子网络处理后,级联得到整幅图像的特征表示,以增强特征的表达能力。文献[15]提出一种SWFV-CNN 模型,该模型利用CNN 选择性地挑选出对于某些模式敏感的滤波器,并将滤波器作为初始化权重,从而训练一个对任务更具判别性的模型。
虽然基于弱监督信息的模型在细粒度图像分类问题上已取得显著效果,但是其特征表达能力仍需进一步增强。由于不同类别之间的差异更加细微,包含足够区分度的信息往往只存在于很细微的局部区域中,如图1 所示,因为乌黑信天翁和莱桑信天翁的区别仅在于鸟喙和腹部的颜色,所以在细粒度图像分类问题中捕获具有判别性的局部特征至关重要。

图1 乌黑信天翁与莱桑信天翁对比Fig.1 Comparison between black albatross and lessonia albatross
现有研究通过引入一些不同的注意力机制模块来学习更加具有判别性的局部特征。文献[16]提出的双线性CNN 模型较早引入了注意力机制思想,该模型利用2 个相同的CNN 分支关注不同区域的特征,通过向量外积的方式聚合2 个分支的特征,从而得到最终特征表示。然而这种方式需要同时训练2 个CNN,且通过向量外积的方式汇聚特征信息会导致最终得到的特征向量维度呈指数级增长,因此造成模型参数量增大,且存在冗余的问题。文献[17]提出利用残差注意力网络(Residual Attention Network,RAN)解决大规模图像分类任务。该网络采用一个编解码结构的注意力模块,利用注意力机制对特征图进行精细化学习,使得网络的表现性能良好,且对输入的噪声鲁棒性更强。RAN通过编解码方式对中间特征图进行处理,直接得到一个三维注意图。然而,本文使用的CBAM 不是直接计算三维注意图,而是对三维注意图进行解耦合,分别计算空间注意力(Spatial Attention)及通道注意力(Channel Attention),这种分离注意力机制生成过程相比三维注意图具有更小的参数量和计算量。CBAM 分别学习特征图的通道注意力和空间注意力,通过对学习到的注意力与原特征图进行加权,可强调关键局部特征,抑制无关特征,极大地增强特征的表达能力。与CBAM 类似,文献[18]提出注意力机制SE(Squeeze-and-Excitation)模块,该模块使用全局平均池化层计算通道注意力,忽略了空间注意力。然而,空间注意力对于特征定位起重要作用,且在本文可视化分析实验中验证了该结论。
2 基于注意力机制的分类网络
2.1 ResNet50 网络结构
由于CNN 具有强大的特征表达能力,因此在计算机视觉任务中应用较为广泛。当网络层数加深时,存在一个难以解决的梯度消失问题。本文采用文献[14]提出的ResNet50 网络模型作为基线模型,该模型通过使用跨层连接极大缓解了深度网络训练中的梯度消失问题。
ResNet50 网络采用一种重要的残差模块,其结构如图2 所示。其中,残差模块的输入为x,期望输出的潜在映射为H(x),则残差定义为F(x)=H(x)-x。如果利用网络直接学习期望输出的潜在映射H(x)存在困难,则ResNet 50 网络不再学习一个完整的输出,而是学习H(x)和恒等映射x之间的差值,即残差F(x),最终仅需对H(x)和x的元素进行加法运算即可得到期望输出。图2 所示的x恒等快捷连接表示跨层连接,这是一条从输入直接到输出的通路,在输出之前将x与经过学习的残差值F(x)相加,可得到期望映射结果H(x)。由于跨层连接的存在,梯度在往前传播时,后一层的梯度信号可以无损传递到前一层,文献[13]已经通过实验验证了学习残差而非直接学习映射的优势所在。

图2 残差模块Fig.2 Residual module
2.2 基于卷积块注意力模块的ResNet50 网络
人类的知觉系统中存在有重要作用的注意力机制,这使得人类在日常生活中处理视觉信息时仅需关注有用信息,不必在某一时刻处理整个场景信息[19]。研究人员受到人类处理视觉信息注意力机制的启发,提出多种应用于计算机视觉的注意力机制模型。为关注重要的局部细节区域,并过滤掉不重要的局部信息,本文采用CBAM。CBAM 和其他注意力机制有相同的出发点,即关注重要的特征信息,过滤掉不重要的特征信息[20]。然而,以往研究提出的模型均是在所有维度上应用残差注意力网络[17]或者只是在某一特定维度上使用注意力机制SE 模块[18]。CBAM 是依次使用通道注意力模块和空间注意力模块得到特征图,因此模型可分别在通道和空间上学到“是什么”与“在哪里”。针对图像识别和分类问题,这种协调通道信息和空间信息的方式可以关注到图像间更加细微的局部差异,放大局部特征的代表性。
营改增的实施使得税法税率等发生了改变。该背景下财务、销售、采购等部门应相互配合,整理各类合同,使其保持规范,对合同中的各类价格是否含税具备清晰地认知,既要了解税率,又要明确发票类型,并厘清与规定不符的发票引发的赔偿责任,优先选择一般纳税人作为供应商,最大程度争取进项税抵扣。采购过程中因涉及到供应商优惠问题,存在普通发票的情况。现实情况很难达到如此力度的优惠,酒店仍需供应商提供专用发票。
CBAM 的结构分为通道注意力模块与空间注意力模块,具体如图3、图4 所示,且其数学形式分别如式(1)、式(2)所示。
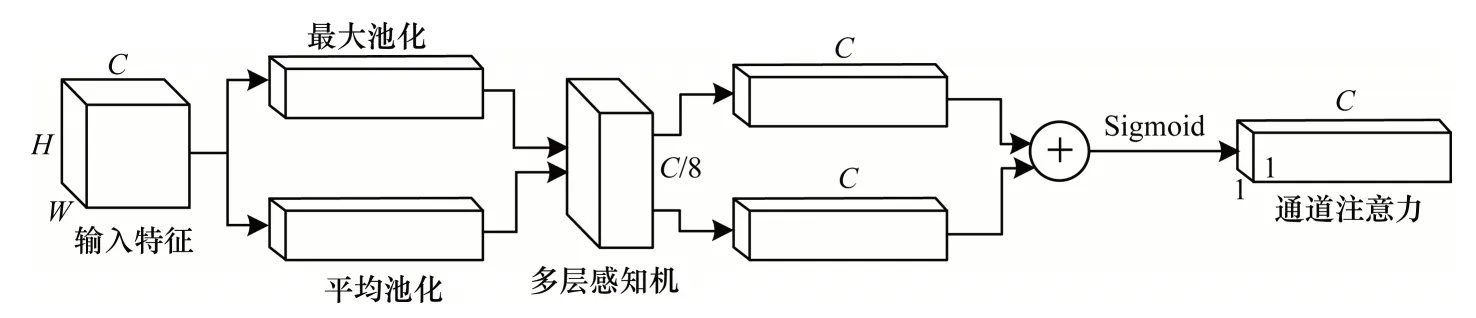
图3 通道注意力模块Fig.3 Channel attention module
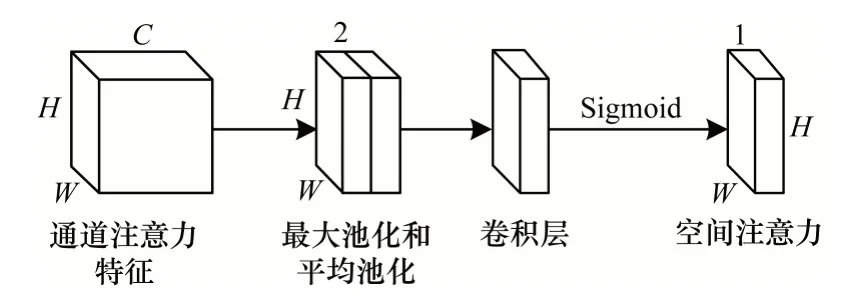
图4 空间注意力模块Fig.4 Spatial attention module

由图3 可知,通道注意力模块先利用最大池化层和平均池化层分别汇聚空间信息,使特征图变为2 个1×1×N的特征向量,再将2 个特征向量输入包含一个隐藏层的多层感知机(共享参数)。接下来将2 个输出的特征向量通过元素求和合并在一起,并经过Sigmoid 激活函数后得到最终通道注意力。通道注意力可以理解为通道的权重,且包含重要信息的通道权重大,包含不重要信息的通道权重小。将通道注意力特征向量以广播的形式输入到输入图像的每个通道上,即可得到需要输出的通道注意力模块特征图。与SE 模块利用全局平均池化学习通道注意力相比,CBAM 同时利用全局平均池化和全局最大池化学习通道注意力,且平均池化考虑特征图中每个通道上的平均信息,而最大池化则考虑通道上的显著性信息,通过将两者相结合使得CBAM 学习到的特征更具有判别性。
空间注意力模块是先在通道维度上使用最大池化和平均池化,然后将2 个汇集了通道信息的W×H×1 的特征图串联为一个W×H×2 的特征图。再使用一个包含7×7×2×1 卷积核的卷积层进一步提取特征,此时的特征图变为W×H×1。接下来经过Sigmoid 激活函数后得到空间注意力特征图。空间注意力特征图可以理解为一个通道上每个像素的权重,且包含重要信息的像素权重大,包含不重要信息的像素权重小。将空间注意力特征图以广播的形式输入到开始输入空间注意力模块的特征图上,即得到整个卷积注意力模块的最终特征图。由此可以看出,将通道注意力和空间注意力分开使用,可以从通道和空间2 个维度上关注到重要特征,并过滤掉不重要特征。CBAM 分别学习了通道注意力机制和空间注意力机制,通道注意力机制通过共享的全连接层实现,且由于池化层没有引入可学习参数,从而大幅减小了使用注意力机制需要的参数量,使CBAM成为一个轻量级模块,且其训练过程更加高效。
按照如图5 所示的方式在每个残差模块中插入注意力机制,结果表明,采用在原来输出的特征图后先后插入通道注意力模块与空间注意力模块的方式效果最好。直观解释是,先使用通道注意力模块强调了该特征是什么,然后使用空间注意力模块强调了该特征位置在哪。此外,从图5 可直观看到,相比联合计算通道注意力与空间注意力,本文使用的CBAM 分别计算通道注意力和空间注意力所需参数及计算量更小,可以忽略不计。因此,本文方法在达到良好效果的同时,并未造成参数量及计算量的增加。
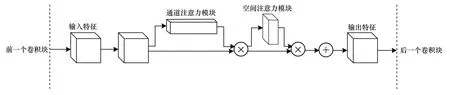
图5 残差模块中插入注意力机制流程Fig.5 Procedure of inserting the attention mechanism in the residual module
2.3 余弦间隔损失函数
在网络的优化过程中,损失函数是不可忽略的部分。细粒度图像分类属于多分类问题,应用最广泛的损失函数为Softmax 交叉熵损失函数。然而,传统的Softmax 交叉熵损失函数仅关注于类间距离,忽略了类内方差,因此对于噪声点和边界点更敏感。
近年来,研究人员提出NSL(Normalized version of Softmax Loss)[21]、A-Softmax 损失函数[22]等基于Softmax 交叉熵损失的损失函数。其中,NSL 是对Softmax 交叉熵损失中的特征向量和权重向量进行正则化,而A-Softmax 是在NSL 的基础上给特征向量和权重向量之间的夹角添加一个系数,从而达到增大类间间隔的目的。虽然上述损失函数的形式有所不同,但是它们的目的都是增大类间间隔、缩小类内方差。然而,这些损失函数仍存在不足之处,如它们可实现缩小类内方差,但其在增大类间间隔上仍达不到预期效果,不能实现更好的分类效果。此外,损失函数还存在优化困难的问题。因此,本文提出一种优化简单且可充分增大类间间隔的余弦间隔损失函数。相比Softmax 交叉熵损失、NSL 和ASoftmax 损失函数,余弦间隔损失函数能更大程度地增大类间间距和缩小类内方差。传统Softmax 交叉熵损失函数的数学描述如式(3)所示:

其中,给定输入向量为xi,yi是其对应的标签,N和C分别代表训练样本数和类别数。fi是最后一个分类层的输出,表示为将偏置项设置为Bj=0,即可得到fj的表示形式,具体如式(4)所示:

其中,θj是Wj和x的夹角。
从式(4)可以看出,正则项和角度都对损失函数存在影响。文献[21]从余弦的角度重新思考Softmax 交叉熵损失,为了只保留角度对损失函数的影响,通过L2 正则化将设置为,并将设置为,因为实验证明对最终的评价指标没有影响,所以损失函数可表示为:

通过将权重以及特征进行L2 范数归一化,使得每个样本的特征被映射到一个超球面中,而r是该超球面的半径。在这个超球面上,同一类的特征向量分布聚集在一起,不同类别的特征向量之间存在一定距离。假设一个数据集有三类特征,则这三类特征在超球面上的分布如图6 所示。其中,θi表示特征向量x与权重向量Wi之间的夹角。

图6 三类特征在2 种损失上的分布Fig.6 Distribution of three characteristics on two losses
从图6 可以看出,决策边界附近的特征点很容易被错误分类,因为类别与类别间的距离为0,这意味着边界十分模糊,模型的容错率较小。为增大类间间距、缩小类内方差,通过引入超参数余弦间隔m到式(5)中,得到本文提出的余弦间隔损失函数,具体的数学形式如式(6)所示:

如图6(b)所示,针对相同的三类别特征,余弦间隔损失函数将决策边界由cosθ1-cosθ2=0、cosθ2-cosθ3=0、cosθ3-cosθ1=0 调整为cosθ1-cosθ2=m、cosθ2-cosθ3=m、cosθ3-cosθ1=m。原始的Softmax Loss 以及余弦形式的Softmax Loss 不同类别之间没有间隔存在,而本文使用的余弦间隔损失则为不同类别之间引入一个余弦间隔m。本文为了更好地理解间隔项的作用,在经典的mnist 手写数字体分类任务上采用不同的损失函数进行实验。为方便在三维空间进行特征可视化,将倒数第二个全连接层的输出单元个数设置为3,每个输入图片将得到一个三维特征向量。利用传统的Softmax Loss 函数的优化准确率为97.3%,利用余弦间隔损失函数的优化准确率为99.1%。
在mnist手写体数字分类上,本文对不同损失函数优化后得到的特征向量进行可视化,结果如图7 所示。图7(a)表示传统的Softmax Loss 的特征分布,由此可以看出,虽然类间具有良好的间隔,但是类内的距离仍然很大。与此相比,图7(b)不仅类间距离更大,且每个类簇也更加紧凑,这说明余弦间隔损失函数不仅显著增大类间距离,而且还显著减少类内距离,使得学习到的特征向量更加稳定且鲁棒。

图7 不同损失函数在特征空间中的特征分布Fig.7 Feature distribution of different loss functions in the feature space
3 实验方法与结果
3.1 实验数据集
实验用到的数据集共包含3 725 张彩色图像,图像是从真实环境拍摄的照片中裁剪所得。经整理后,将图像分为100 个类别,且2 725 张用于训练,1 000 张用于测试。数据集样本类别多样且每类样本数据多样,具体如图8 所示。

图8 样本类别及样本数据Fig.8 Sample categories and sample data
3.2 实验过程
将训练集2 725 张图像中的1/10 划分出来用作验证集,训练结束后保留验证集上准确率次高的模型,并用其在验证集上继续训练网络,微调网络参数,观察损失值和准确率。为防止过拟合,采用数据增强技术来扩充数据,具体使用的技术包括水平和竖直方向随机移动、随机放大、剪切变换、颜色抖动和随机旋转。在训练过程中先把每张图像缩放到256×256像素,然后随机裁剪224×224 输入到网络中,且进行测试时,以中心裁剪224×224 的图片作为输入。本文对图片进行[0,1]归一化处理,采用ImageNet[23]预训练权重,以Adam 为优化器,初始学习率设置为0.001,训练100 个epoch,当验证集准确率不再继续增大时,将学习率衰减10 倍。实验在Windows10系统、Spyder 编辑器与基于Keras 框架的NVIDIA GeForce MX150 GPU 上进行。
3.3 实验结果分析
本文采用准确率(Accuracy)、精确率(Precision)、召回率(Recall)与F1 值4 种评价指标对结果进行评估,且其计算方法分别如式(7)~式(10)所示:

其中,TP 表示被正确预测的正例,TN 表示被正确预测的负例,FP 表示被错误预测的负例,FN 表示被错误预测的正例。
为分析每个模型的效果,本文在商家招牌数据集上分析并验证ResNet50 模型中每个模块的性能,结果如表1 所示。其中,最优结果加粗表示,“√”表示模型所选择的不同模块,“—”表示模型未选择的模块。

表1 不同模块的结果对比Table 1 Comparison of results of different modules %
从表1 可以看出:与原始ResNet50 相比,当使用注意力机制CBAM 后,分类准确率提高1.4 个百分点,F1值提升0.8 个百分点,这是因为CBAM 引入的通道注意力机制极大增强了特征的判别性,起到特征选择的作用,从而提高分类效果;对比表1 中的第一行和第二行可知,由于网络在优化过程中不但增大类间间隔,而且减小类内方差,这说明相比传统的交叉损失函数,基于间隔的余弦损失函数取得了更优性能;当本文将注意力机制和余弦间隔损失函数相结合时,相比原始的ResNet50,本文方法的准确率与F1 值分别提高了2.2 个百分点与2.0 个百分点,且分类性能达到最优。
3.4 对比实验分析
实验比较了以ResNet50 为基础的双线性卷积神经网络模块、残差注意力模块、SE 模块与本文所提CBAM 等4 种不同注意力模型的性能,结果如表2 所示。从表2 可以看出,CBAM 在模型参数量和性能上均达到最优。
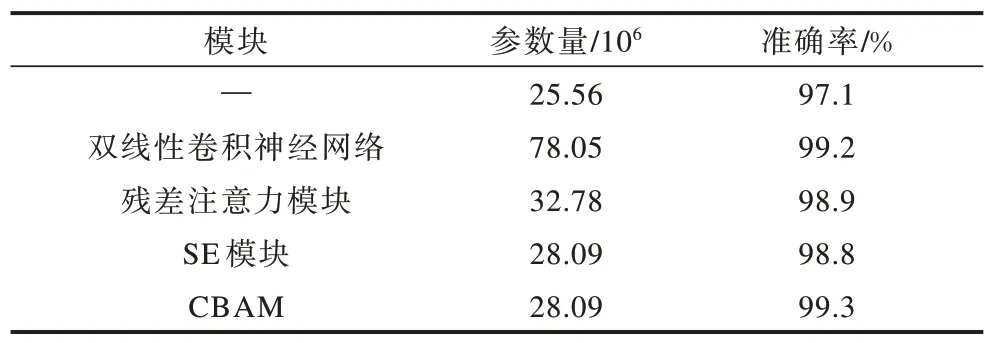
表2 4 种不同注意力机制模型的性能对比Table 2 Performance comparison of four different attention mechanism models
3.5 可视化实验分析
为进一步分析注意力机制的效果,本文使用类别激活映射技术(Grad-CAM)对输入的图片进行注意力可视化。如图9 所示,左边的一列是原始的输入图像,中间一列是原始的ResNet50 可视化图,最右边的一列是使用CBAM 的可视化特征图。通过对比(尤其是第二行和第三行)可以看出,通过引入CBAM 使得网络更加关注在招牌字符以及图像区域的特征,并忽略其他不相关的特征区域,从而增强特征的判别性,有效改善分类效果。

图9 注意力机制可视化结果Fig.9 Results of attention mechanism visualization
4 结束语
针对商家招牌的分类问题,本文提出基于端到端深度学习的卷积神经网络方法。该方法通过在原始ResNet50 网络结构的基础上插入注意力机制CBAM,构造一种新的余弦间隔损失函数,并利用数据增强技术对数据集进行扩充,使得模型准确率达到99.3%。实验结果表明,与传统方法相比,该方法省略了特征提取等步骤,不仅节省大量时间与人力,而且可在较短时间内达到较高的准确率。由于本文使用的数据集仅有3 725 张图像,因此后续将采用二叉神经树与循环学习率相结合的方法对ResNet50网络结构进行改进,以适应更大规模的数据集。
