结合类别偏好的协同过滤推荐算法
2021-01-15张紫嫣
张紫嫣 周 驰
1(同济大学医学院 上海 200092) 2(浙江大学软件学院 浙江 杭州 310027)
0 引 言
近几年来,随着网络技术的快速发展,用户数量急剧增加的同时数据信息也大量增多,出现了信息过载、信息迷失等现象,推荐系统应运而生。为使人们能够更加有效地利用资源,接收更符合用户需要的信息,主要采用个性化推荐系统方法解决此类问题。最常见的方法有协同过滤算法[1]、基于内容的推荐算法[2]、二部图网络结构推荐算法[3]、混合推荐算法[4]。
最近邻协同过滤技术[5]是当前应用最为广泛的个性化推荐算法之一,但其存在难以处理稀疏数据、算法较低的可扩展性、推荐结果的难解释性等缺点。针对以上问题,国内外学者们进行了各种深入的探讨和研究,提出了不同的解决方案。早在1994年,基于用户的协同过滤算法[6]就被应用在了新闻过滤中。2003年,亚马逊公司提出了基于Item的协同过滤方法[7]。文俊浩等[8]提出了一种基于标签主题的协同过滤算法,从语义层面上计算了用户对项目的偏好概率。林建辉等[9]利用有向网络图构建出用户之间的信任关系,提出一种融合信任用户的协同过滤推荐算法。赵红等[10]通过融合初始资源配置以及协同过滤,形成了更为有效的组合推荐算法。李龙生等[11]将用户行为和物品标签与协同过滤相结合,更好地解决了物品冷启动问题。廖志芳等[12]采用了随机森林来处理用户的属性特征,从而构建出一种新的混合相似度计算模型。卫泽等[13]将用户评分一致频次与评分项目数之比作为惩罚函数引入到相似度的计算中,从而提高了推荐质量。李雪等[14]提出了一种系统主题生成算法,将主题相似度引入到相似度的计算中。但是,如何在海量的数据资源中将信息准确地推荐给用户,依旧是我们目前所面临的一个难题。
由于用户对类别的偏好会导致一定的喜好倾向,所以结合用户类别偏好的相似度计算会比原来的相似度计算更接近真实情况。比如某用户喜欢运动品牌李宁,则他的鞋架上该品牌的鞋子可能会明显多于其余品牌,有相同类别喜好的用户的相似度也会较高。针对此种情况,本文提出一种结合类别偏好的协同过滤算法,通过计算用户对不同类别的偏好程度来得到用户之间的相似度,并结合原有的用户相似度来获得推荐结果,同时还需要对过于热门的类别进行惩罚,避免热门类别的影响,从而提高推荐效果。
1 传统的协同过滤推荐算法
传统的协同过滤算法包括基于用户的协同过滤和基于项目的协同过滤。二者除了相似度计算有所差异之外,本质上都是基于邻域的协同过滤。下面以基于用户的协同过滤为例:
步骤1计算用户相似度。计算用户相似度是协同过滤算法的核心部分,有多种不同的方法,如余弦相似度、Pearson相关系数、Jaccard相似性度量等。
步骤2根据步骤1中的相似度计算方法得到用户相似度,进而得到用户的近邻集合,近邻集合的大小通常可以设置为K,而K的取值一定程度上影响了推荐效果。

(1)
式中:rvi表示用户v对项目i的真实评分;sim(u,v)表示用户u与用户v的相似度。
传统的协同过滤算法在计算用户相似度时,往往会受限于数据稀疏的问题,其中的原因是两个用户之间共同喜爱的项目很少甚至没有,这导致了计算用户相似度的时候会与真实的情况存在偏差,从而影响了推荐系统的效果。
2 结合类别偏好的协同过滤
本文通过将协同过滤与用户的类别偏好相结合,来计算用户之间的综合相似度,进而从近邻用户得到推荐结果,来提高推荐的效果。
2.1 余弦相似度
协同过滤算法中经常使用余弦相似度来计算用户相似性。余弦相似度计算方式如下:
(2)
式中:N(u)、N(v)分别为用户u和用户v有正反馈的项目集合。
2.2 类别偏好
某用户对某一类别的偏好一定程度上会影响用户对item的评价结果,可以通过F(u,t)来表示用户u对类别t的偏好程度。
(3)
式中:Item(u)为用户u有正反馈的item集合;I()为指示函数,用于判断项目i是否为类别t的项目。
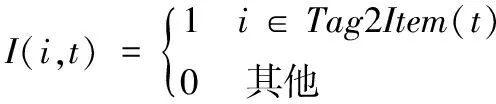
(4)
式中:Tag2Item(t)表示类别t所包含的所有item集合。
Ct为对热门tag的惩罚系数:
(5)
这里还额外引入了平滑项,避免出现分子为0的情况。
不同的用户有不同的类别偏好,通过计算用户的类别偏好,从而可以依据余弦相似度或其他相似度度量方法来得到用户之间的类别偏好维度上的相似度Simtag。
2.3 综合相似度
在得到用户的类别偏好后,同样可以用余弦相似度来计算在类别偏好维度上的用户相似度Simtag。在原有的余弦相似度的基础上结合类别偏好的相似度,得到用户综合相似度Sim():
Sim(u,v)=α×Simcos(u,v)+(1-α)×
Simtag(u,v)
(6)
式中:α为权重因子,用来平衡综合相似度中两种不同的用户相似度。
3 实 验
3.1 测试数据集
本实验采用Movielens-100k数据集,这是推荐系统的一个经典数据集。该数据集包含了943名用户、涵盖了19个类别的1 682部电影以及100 000条评分记录。其中:将80%的数据划分为训练集, 剩余20%的数据划分为测试集。
3.2 评价指标
本文采用精度(Precision)和召回率(Recall)来评价算法的推荐效果。
(1) 精度:指在推荐结果中,用户真正喜欢的项目数所占的比例。
(7)
(2) 召回率:指在个性化推荐算法产生的推荐结果中,用户喜欢的项目数占用户真实喜欢项目总数的比例[15]。
(8)
式中:TP为真正例;TN为真负例;FP为假正例。
3.3 实验设计及结果分析
实验发现,选取的α因子约为0.8时,推荐效果最好,所以以下实验的α因子均设置为0.8。
由于不同大小的K值会影响推荐的效果,所以对于不同的近邻个数K,我们取了不同的值来验证算法的有效性。图1为在不同K值下,结合类别偏好的协同过滤算法在测试集上的精度。
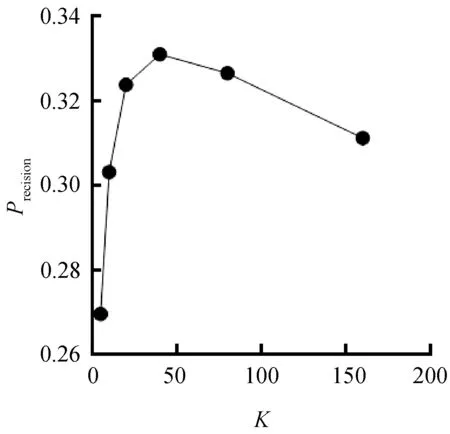
图1 精度与最近邻个数K的关系
图2为不同K值下,结合类别偏好的协同过滤算法在测试集上的召回率。
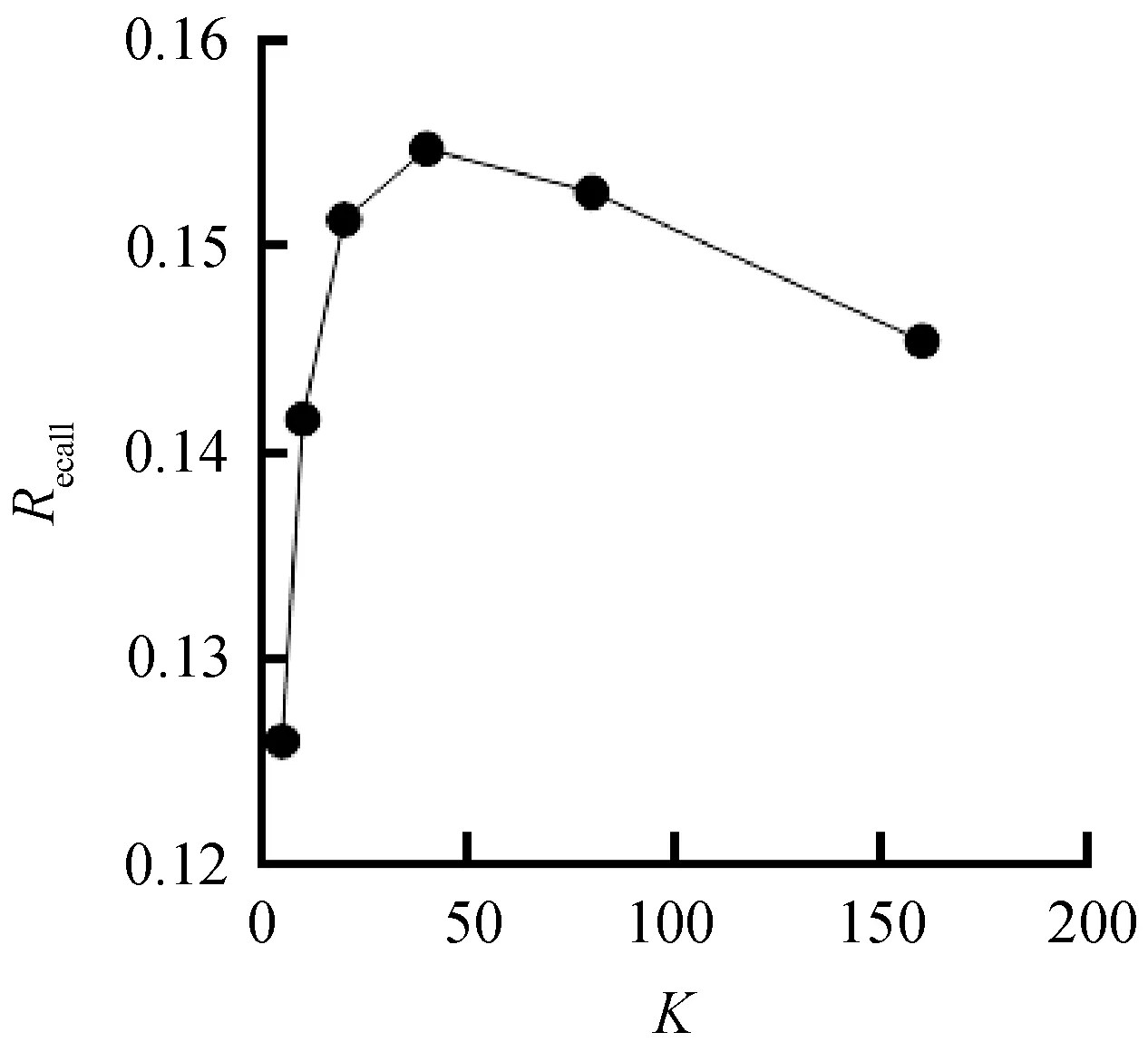
图2 召回率与最近邻个数K的关系
结果表明,当K在20~80之间时,精度和召回率均表现较好,说明K值在这个范围内的推荐效果较好。而在实际应用中,如果K值过大,会导致计算时间的大量增加,从而影响用户的体验,所以选取一个合适的K值在推荐系统中极为重要。因此,本文针对小K值,选取了3~30之间的多个K值来进行实验,将算法改进前后的精度和召回率进行对比。图3、图4是协同过滤算法改进前后的精度和召回率的对比。
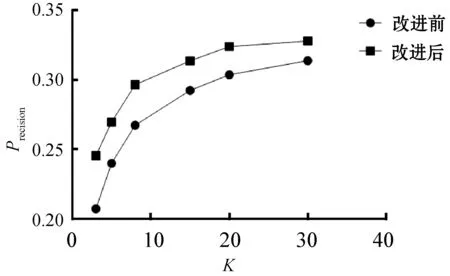
图3 算法改进前后精度对比
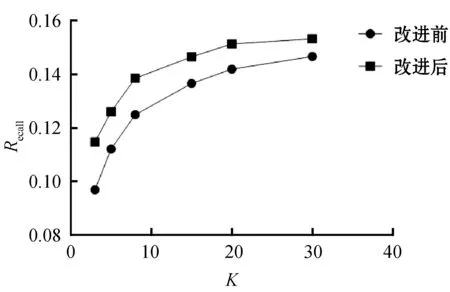
图4 算法改进前后召回率对比
实验结果表明,在相同K值的情况下,结合类别偏好的协同过滤与传统的协同过滤相比,在精度和召回率这两个评价指标上均有较为明显的提升,这表明了改进后的算法能较好地结合用户的类别偏好,使得近邻计算更为合理,从而提高推荐效果。
4 结 语
推荐系统是针对信息过载现象的一种常见处理手段,而协同过滤算法则是其中最为基本的技术之一。本文提出一种结合类别偏好的协同过滤推荐算法,在原有的计算用户相似度的基础上结合了用户的类别偏好相似度,使得算法对用户相似度的计算更为准确,也更能反映真实情况。实验表明,该方法能够有效地结合类别偏好,提高推荐效果。
