基于光流网络模型的岩心CT序列图像裂缝分割
2021-01-15谢杨灏滕奇志
谢杨灏 滕奇志
(四川大学电子信息学院图像信息研究所 四川 成都 610065)
0 引 言
岩心CT序列图是对真实岩心进行CT扫描得到的,使用岩心CT序列图并通过一系列算法可以重构出数字岩心,进而研究岩心的孔隙微观结构[1]。岩心CT序列图的分割是数字岩心重构的关键步骤,主要目的是提取孔隙、颗粒和裂缝等感兴趣的区域,分割的优劣直接决定了数字岩心的重构质量。岩心中的微裂缝对于研究岩心连通性和渗流特性具有重要意义,但由于目前CT成像的对比度往往不够理想,且易受到噪声影响,导致分割难度增大,一些细的裂缝提取困难,且容易断裂。
常用的图像分割方法主要有基于阈值的分割方法、基于区域的分割方法和基于边缘的分割方法。由于CT序列图的目标具有多样性,往往无法使用一种单一的方法来实现分割。常用的裂缝分割流程需要首先进行边缘增强,然后进行阈值分割[2],最后通过区域生长来实现最终的提取。这类方法在处理岩心CT序列图时无法很好地解决对比度低以及噪声干扰等问题,得到的裂缝很容易出现过分割或者欠分割的情况,如果要得到好的分割结果,则需要大量的手工修补。
而在实际应用中,CT序列图往往以数以千计的形式出现,如果每一幅图都需要人工进行修补,将会耗费大量的时间。找到一种分割效果好且自动化程度高的分割方法则成为解决裂缝分割的重要目标。
文献[3]提出了一种利用层间相关性的半自动分割方法,该方法利用相邻图像直方图的相似性,选取分割区间并使用区域生长对分割区域进行修复,在一定范围内能够高效、自适应地分割。该方法主要针对孔隙目标进行分割,分割效果取得了进步,但相对孔隙而言,裂缝在图像中的对比度更差,且目标形态较细,容易断裂,因此该方法在裂缝目标的分割上效果并不理想。
由于CT序列图的层间相关性较强,本文把岩心CT序列图看作一个连续变化的视频序列,利用光流进行帧间像素运动的预测,通过叠加光流网络模型获取光流数据,使用首帧标定、位置迭代、区域聚类和光流阈值分割实现目标区域更新以及噪声抑制。实验结果表明,本文方法在分割效果以及自动化上均有较大提升。
1 算法描述
将岩心CT序列图看作一个连续变化的视频序列后,主要的问题是如何实现对帧间关系的检测以及通过像素的移动实现目标区域的分割。
1.1 光流网络模型
光流指的是时变图像中像素点的瞬时运动速度。光流根据需要检测的像素个数可以分为稀疏光流和稠密光流,稀疏光流是对指定的一组像素点进行跟踪,一般是特征明显的点,如角点;而稠密光流则是对整个图像的像素点进行跟踪。如果要实现对移动目标的分割,则必须实现像素级的光流预测,即上述的稠密光流。目前,稠密光流的求解方法主要有Gunnar Farneback算法[4]、Horn-Schunck算法[5]等传统方法和基于神经网络的深度学习方法[6-8]。由于近年神经网络的高速发展,在很多方面深度神经网络已经超越了传统算法,本文在FlowNet[6-7]的基础上,根据岩心CT序列图的分割进行了优化。
FlowNet依据的是传统的CNN网络模型框架,采用端到端的训练模式。目前根据输入的方式有两种基本模型,分别是FlowNet Simple(FlowNetS)和FlowNet Correction(FlowNetC)。FlowNetS将图片先叠加再输入网络,FlowNetC则是将图片直接输入网络再在第三级卷积后再进行融合,两个网络的卷积层数相同,只是图像合并的网络层不同。网络结构的差异导致了两种网络结构在光流估计的表现也不完全相同,通过大量的实验可以得出:FlowNetS在全局光流估计上有较大的优势,FlowNetC在对特征点的光流估计上有较大的优势。图1和图2分别为两种FlowNet的网络结构。

图1 FlowNetS网络结构

图2 FlowNetC网络结构
从理论上来说,网络深度的增加可以提高网络学习能力[8]。文献[6,8]通过叠加网络的形式提升了光流场的检测精度。考虑到两种FlowNet模型在光流估计上的不同表现,本文使用了FlowNetC和FlowNetS构成的两层叠加网络,以同时发挥两种网络结构的优势,实现更好的估计效果,结构示意图如图3所示。为了实现两个网络的叠加,需要在两个网络中间增加一个扭曲层,扭曲层将输入图像的后帧图像按照前级网络输出的光流估计场进行位置变换,再输入到下一级网络,依此类推可进行多次叠加。但是考虑到训练的效率以及应用的复杂度,本文采用了两级叠加网络。
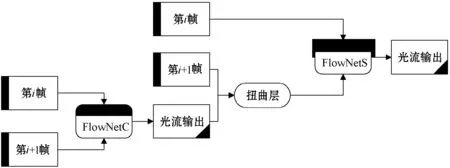
图3 两级叠加网络结构
扭曲层的操作是通过将光流的移动叠加到i+1帧上完成的:

(1)
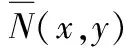
1.2 分割算法描述
光流网络模型得到的光流数据不能直接用于裂缝分割,另外在进行裂缝分割之前需对裂缝的形态进行分析以设计出相应的分割策略。
裂缝在岩心中通常可分为垂直缝和水平缝。垂直缝主要是由于地质运动引起的地层断裂产生的,如图4(a)中垂直于底面的切面;在岩心CT图像一个切片上表现为一条细长的线条,如图4(b)所示;水平缝通常是在地层受到挤压后形成的地层缝,如图4(a)中平行于底面的切面;在CT序列中的表现为线条较粗的区域,如图4(b)所示的右上角区域。
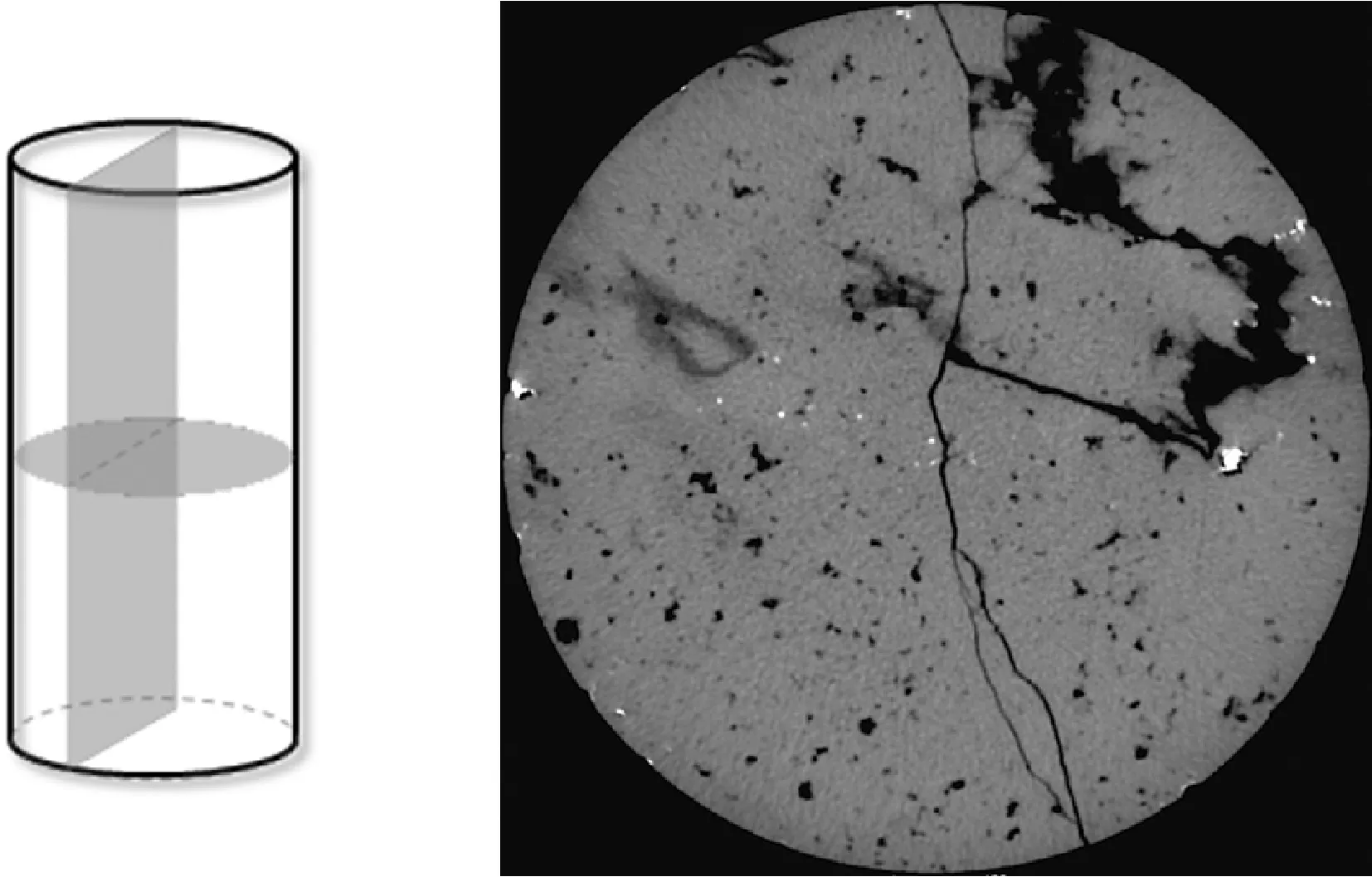
(a) 岩心裂缝示意(b) 岩心CT图像图4 水平缝与垂直缝展示
垂直缝大多能够贯穿整个CT序列图,以细小的线条为主,而水平缝往往只出现在CT序列图中的某些区段中,主要表现是位置变化迅速。本文通过对比光流和裂缝的变化规律后,整合了垂直缝和水平缝的分割流程,通过位置迭代实现垂直缝的分割,利用光流剧变解决水平缝的分割,设计出如图5所示的分割流程。其中,垂直缝的初始位置通过首帧标定实现,标定位置由传统分割方法并辅以人工手段得到,标定目标的判断即为首帧标定的判断,用来确定垂直缝是否存在。
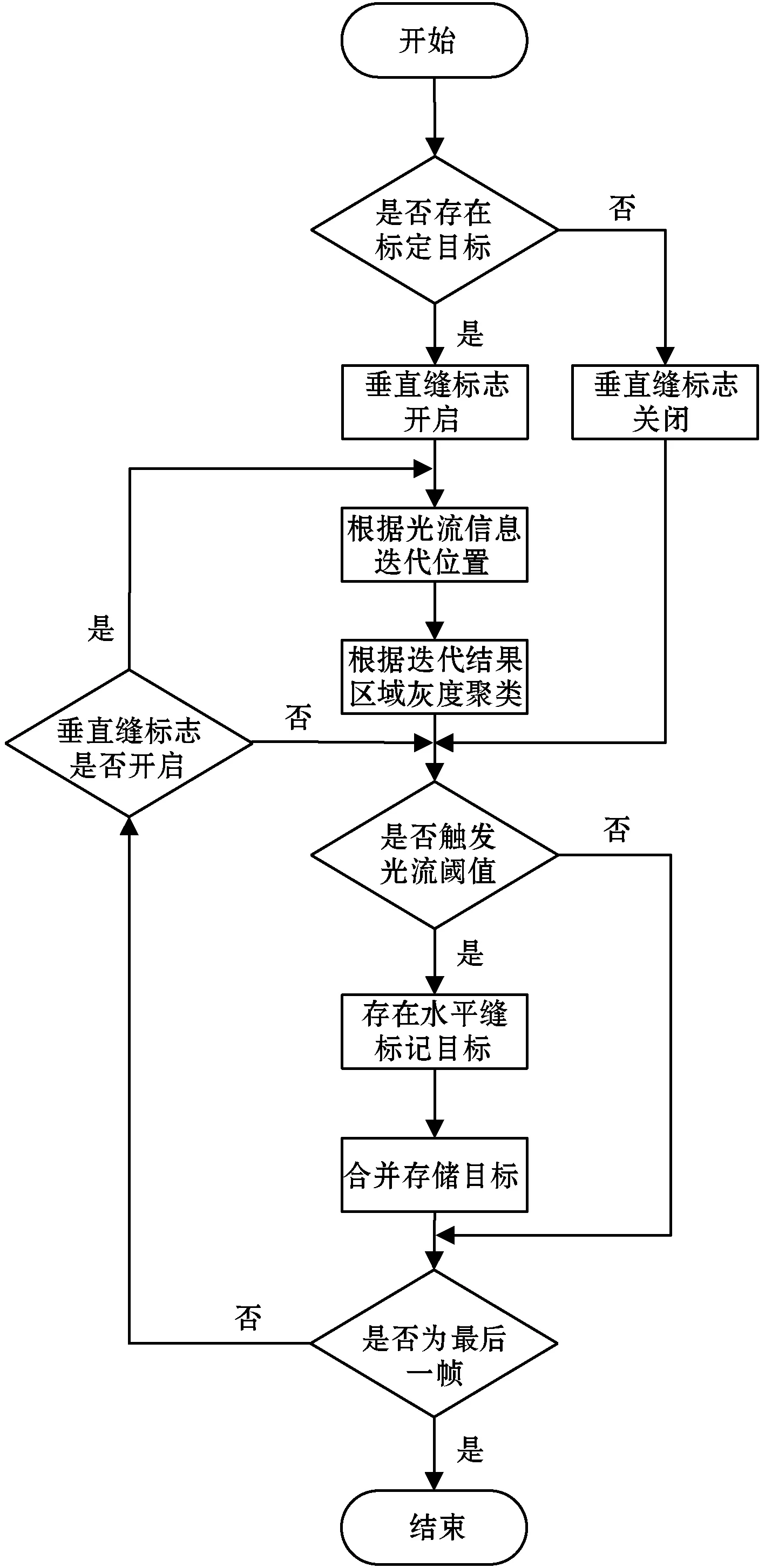
图5 分割算法流程
现假设Ti(m,n)为当前帧分割目标的集合,(m,n)表示目标出现的位置,i为当前帧号。首帧标定即i=0时的分割目标。
在前帧分割目标已知的情况下,根据光流信息进行位置迭代:
(2)
式中:u和v分别代表m和n方向的光流向量变化量,进行叠加后可以得到新的目标位置。由于目标位置更新后,部分目标点已经移出了图像区域,同时又有新的目标引入,因此区域聚类实现了目标区域的更新。区域聚类使用2×2的模板,首先将目标位置映射到原始图片中:
Ii+1(m1,n1)=f(Ti+1(m1,n1))
(3)
然后按照模板大小通过式(4)计算临近点的灰度差值,以图6的聚类示例图为例,白色表示未知目标,灰色表示已知目标。
(4)

图6 聚类示例图
式(4)的后半部即当前区域的类心,再通过灰度阈值判断是否为目标,如果为目标则归并到Ti+1中,随后再次进行迭代,直到目标不再增加为止。经过大量实验可得,灰度阈值设为5时能够满足大部分情况,但是对于一些较特殊的图像则需要重新进行设定。区域聚类算法的具体描述如算法1所示。
算法1区域聚类算法。
输入:已进行位置的迭代的目标Ti+1,当前帧Ii+1(w,h),w、h分别为图像的长和宽。
输出:区域聚类后的目标Ti+1。
1. 初始化停止标志flag=TRUE,迭代次数cnt_iterate=0。
2. WHILE(flag){
3. 初始化更新计数cnt_update=0。
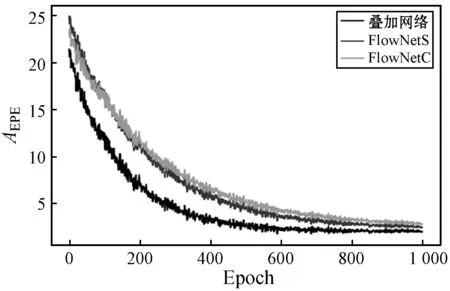
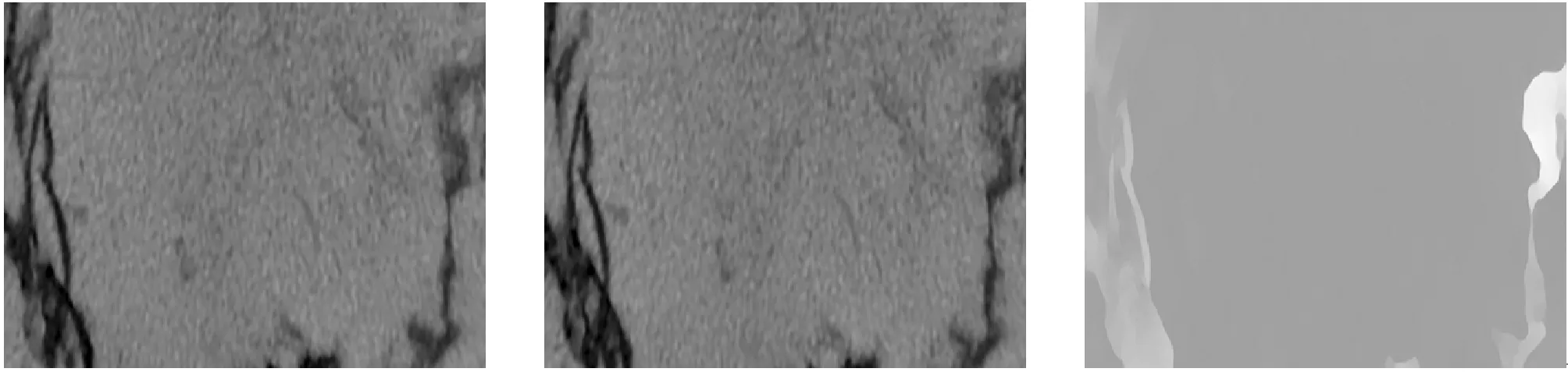
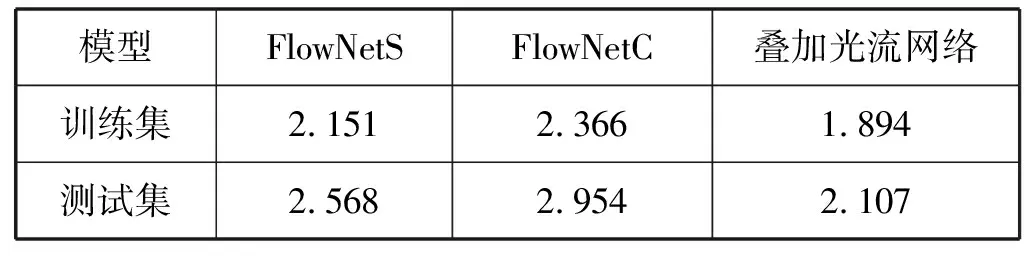
4. FOR(i=0;i 5. FOR(j=0;j 6. IF(Ti+1(i,j)是目标){ 7. 根据式(4)计数临近区域差值。 8. IF(区域需要更新){ 9. 更新区域Ti+1。 10. cnt_update++; 11. } 12. } 13. } 14. } 15. cnt_iterate++; 16. IF((cnt_update==0)||(cnt_iterate>100)){ 17. flag=FALSE; 18. } 19. } 光流位置迭代和区域聚类是用于垂直缝的分割,而水平缝的分割主要采用光流阈值进行分割。使用光流阈值进行分割可以很好地抑制噪声对分割造成的影响,得到的水平缝的分割结果有显著提升。阈值分割计算光流的变化量,将两个方向光流变化量的绝对值进行叠加。 S(x,y)=|U(x,y)|+|V(x,y)| (5) 式中:U(·)、V(·)为图像在(x,y)处的像素点沿水平方向和垂直方向的光流变化。根据大量实验,光流阈值设定为10时分割效果较好,也可根据特定的情况设置光流阈值。得到的阈值分割目标为Ti+1(m2,n2)。 将新得到的两个目标区域进行合并便得到新的目标区域,目标区域即为裂缝的分割图像。 Ti+1(m,n)=Ti+1(m1,n1)+Ti+1(m2,n2) (6) 光流网络模型的参数更新是通过比较网络得到的估计光流值与真实光流值的误差来实现的。本文模型训练的数据集选取了FlyingChairs数据集[6],以及为了能够适用于岩心CT序列制作的岩心CT序列数据集,从FlyingChairs数据集选取了10 000幅图像,以椅子为检测目标,岩心序列数据集共制作了1 000幅图像,以裂缝为检测目标,图像大小均为 512×384,灰度级为256级的灰度图像。岩心CT序列数据集选取的图片以低噪声为主且主要噪声来源为高斯噪声,并进行了对比度提升和平滑滤波处理。最终数据集的分配为:训练集占90%,验证集占5%,测试集占5%。 由于真实光流值的获取具有一定的难度,在制作光流数据时使用了迁移学习的方式进行生成,用已训练完成的网络直接生成光流数据。然后通过对光流的可视化进行光流数据的验证,并对偏离严重的数据进行修正。在经过多次修正后,得到的数据集基本满足训练要求。 网络所有层的权重使用均值为0、方差为2/n的高斯分布进行初始化,衰减系数为0.000 4,偏执衰减系数为0[9]。网络参数的更新方法为Adam自适应优化算法[10],学习率采用0.000 1,一阶矩估计的指数衰减率(beta1)和二阶矩估计的指数衰减率(beta2)分别为0.9和0.999。由于显存限制,每批次读取8组图片,使用8个线程进行训练,训练结束条件为1 000个Epoch,并在训练过程中记录最佳训练结果。 实验的硬件环境为 Intel i7- 7700K 4.2 GHz的CPU、16 GB内存和单块GIGABYTE GTX1060显存6 GB的显卡,操作系统为版本Ubuntu16.04的Linux操作系统,模型的搭建使用0.4.1版本的PyTorch框架。 本文选取平均端点误差(average end point error,AEPE)作为网络训练的质量评价,即通过比对计算网络的最终输出光流估计与实际光流估计的差异实现对训练结果的评价,并给出如下定义: |vr(x,y)-vc(x,y)|) (7) 式中:M×N为图像的大小;ur(·)、vr(·)为真实光流数据;uc(·)、vc(·)为模型生成光流数据。先对目标的所有光流差值绝对值求和,再除以总像素数得到平均端点误差。以此误差作为损失函数代入网络进行网络参数的更新。 另外,为了实现光流数据的可视化,以图像大小创建一幅空白的RGB图像,并初始化所有像素点的数据为1.0,再进行如下操作: (8) r、g、b分别代表各通道在(x,y)位置处光流位置的叠加。最后,通过数据等长拉伸,使得各通道的数据均在[0, 255]内,存为通用格式的图片,即可实现数据的可视化。 图7为FlowNetS、FlowNetC和本文的两层叠加光流网络在训练过程中AEPE变化图,叠加网络在经过600个Epoch后趋于平稳,FlowNetS和FlowNetC在800个Epoch后趋于平稳,因此本文选取了1 000个Epoch作为训练的结束条件。 图7 叠加网络和FlowNetS及FlowNetC损失值变化图 图8分别展示了连续的两帧原始图片,目标光流数据以及使用FlowNetS、FlowNetC和叠加光流网络生成了光流预测数据的可视化图像。表1展示了在训练了1 000个Epoch后的最佳训练结果和测试结果。 (a) 原始图像1(b) 原始图像2 (c) 目标光流 (d) FlowNetS(e) FlowNetC(f) 叠加网络图8 不同网络模型生成光流对比 表1 模型训练测试AEPE结果 实验验证网络叠加的确可以提升效果,从图6中可以看出叠加网络平均端点误差比其他两个网络要低,输出的光流可视化效果明显优于其他两个网络,而FlowNetS和FlowNetC的颗粒感比较严重,并且对噪声信号的光流判断比较混乱,而叠加网络的判断较为准确,噪声信号的光流可以被抑制到一个较低的水平。由表1可以看出,叠加光流网络的表现要明显优于其他两个网络。在测试集的表现中,叠加光流网络的AEPE达到了2.107,而FlowNetS和FlowNetC的AEPE相对较高,还无法达到具体应用的水平。通过以上结果对比可以得出目前的网络已经能够较为精确地得出光流估计数据,为下一步的分割奠定了良好的基础。 针对传统分割选用了典型目标阈值分割和大津阈值分割。典型目标阈值分割是选取对比度较大的区域进行直方图统计,然后再选取分割点,能够对典型目标进行最大限度的分割。大津阈值分割能够使用全局最佳阈值进行分割,在前景与背景有明显差异时分割效果较好。图9展示了不同方法的分割结果。 (a) 原始图片(b) 双阈值分割(c) 大津阈值分割(d) 本文方法图9 分割结果对比 可以看出,原始图像存在大量的噪点且分辨率较低,而且右上角有一片目标区域跟噪声混合在了一起。双阈值分割如果要提取到完整的目标,就会引入大量的噪声,需要的填孔、去噪、开闭合运算操作就会多很多,如果这些操作过多会导致裂缝的断开,而如果操作不足会导致噪声过多。要实现一个好的分割就需要人为地进行尝试,直到得到一个较理想的结果。如果第一帧的分割效果已经不理想了,依据同样的分割策略进行自动分割的后续图像的分割效果往往会越来越差。大津阈值分割也存在同样的问题,由图9可以看出,在提取到完整的右上角区域后也会引入大量的噪声信号,但是相对于双阈值分割要少一些。本文算法的第一帧也是使用典型目标阈值分割的方法,然后通过必要的填孔、去噪、开闭运算等操作完成目标的提取,把分割目标控制在一个较理想的范围内,最后根据光流移动进行分割。从分割效果看,本文算法在图中的右上角区域能够提取到完整的目标,并且能够保证连续性和较高的性噪比,同时在小位移目标的检测上也能取得较好的结果,如图中间区域的垂直缝。总体来说,本文使用的分割结果明显优于双阈值分割和大津阈值分割。 图10分别展示了两组CT序列中连续帧的分割效果,第一组图首帧使用了典型目标分割、去噪滤波、形态学变换等操作提取到需要跟踪的目标,输入到算法中输出相应的分割图,并且从后续帧可以看出,分割能够依据光流预测的方向进行更新,并在有大范围变化时能够会将此区域认定为目标区域。图10(c)、(d)展示了另一组图,这组图没有进行首帧分割,由于目标运动范围较大,通过光流阈值可以直接分割出目标区域,并能在接下来的帧中迭代更新目标区域。 (a) 序列图一 提取CT序列图的裂缝其主要目的是重建裂缝的三维模型,并对三维裂缝的倾角、厚度和波及面积等进行数据分析。图11展示了图10(c)的裂缝三维模型。 图11 序列图二的三维模型展示 根据上述实验,岩心CT序列图分割在使用光流模型进行帧间运动预测后能够明显地提高对噪声的抑制能力,提升分割的效果和效率,并提高三维裂缝分析的准确性。 本文对岩心CT序列图的裂缝分割进行了深入研究,通过序列图到视频帧的思维转换,提出了一种基于光流网络寻找帧间相关性的分割方法。本文在光流预测中使用了叠加光流网络模型,并通过对比FlowNetS、FlowNetC,发现叠加网络在光流预测的能力有了极大的提高,测试集的平均端点误差达到了2.107,验证了光流预测模型在CT序列图运动预测的可行性。通过对比传统的分割方法,发现本文方法能够提高裂缝提取的完整度以及对噪声的抑制,并提高自动化水平和裂缝三维分析的准确性。2 模型的训练与评价
2.1 数据集
2.2 网络训练参数及环境描述
2.3 训练质量评价
2.4 训练结果分析

3 实验结果分析



4 结 语
