基于显著性语义属性的交互式非标人像检索方法
2021-01-15陈欣如
王 茜 陈欣如
1(上海市公安局刑事侦查总队信息中心 上海 200083) 2(国网上海市电力公司市南供电公司 上海 201199)
0 引 言
近年来人像识别技术在公共安全领域中得到了越来越多的应用,但许多在专业刑侦领域中对案件侦破起到决定作用的人像要素,如嫌疑人模拟画像[1]、目击者的头脑印象(mental image)[2]、被害人颅骨复原像[3]、描述者语义化的特征描述[4]等,由于无法进行常规人像比对和语义化属性检索,从而陷入只能依靠人工筛选的困境。同时在大量视频侦查应用中,许多非正面、残缺、超分辨率等未达到人像识别和检索质量要求的素材,而往往被现有的人像检索系统拒之门外。本文将上述非标准、非常规的人像检索问题统一归类为“非标人像检索”问题,尝试寻找可行的解决方法。
以往针对“非标人像”检索问题的研究相对较少,在专门对应算法方面的研究几乎空白,因此只能通过人脸角度纠正、超分辨率图像清晰化处理、人像补全等图像处理方法修正“素材”来达到检索的目的,耗费人工且效果不佳。近年来,少数学者开始着眼于该领域,文献[1]基于汤晓鸥教授早期的研究,通过将所有非标图像、头脑印象均绘制为模拟画像的方法实现了异质人像(Heterogeneous Image)比对方法,但效果极大地受制于目击者的描述能力以及绘制者的专业水平;文献[2]针对头脑印象进行了深入研究,并试图通过新兴脑科学中的神经影像学方法侦测出人脑中包含特征的相关人像;文献[5]提出了利用人类智能“告知”机器操作者倾向的交互式检索技术,可“根据用户需求突出显示最相关的结果”;文献[6]进一步提出了可运用交互式技术解决模糊图像、头脑印象搜索问题的观点,并构建了一套基于超图度量学习(HpyerGraph Metric Learning,HML)的交互式人像检索系统,为本文的研究奠定了基础。
本文针对非标人像检索的应用需求,首先引入公安行业标准化人像属性并通过多标签分类神经网络[7](Multi-label Classification Convolutional Neural Network, MLCNN)实现了人像属性分类。接着通过人工交互的方式区分显著性与非显著性语义属性,提出一种基于显著性语义属性的交互式非标人像检索方法,并最终根据该方法构建了一套循环少、收敛快的交互式人像检索应用。
1 前期工作
1.1 多标签属性神经网络
近几年来,多位学者提出了基于语义的多标签图像检索方案,其中,文献[8]构建了基于支持向量回归的机器学习方法(Support Vector Regressor based Machine Learning,SVR-L),以提升算法对高维人脸的分辨能力,并明确提出了该方法可用于“描述检索嫌疑犯”;文献[9]提出多标记收缩哈希方法,可以保留多标记图像的多水平语义相似性,使其更适用于更大规模的图像搜索;文献[10]提出了通过多标签属性神经网络解决多标记图像的快速行人分类检索方法。文献[10]和文献[11]将该方法运用于相似服装的精细化检索中,均取得了较好的效果,证明了多标签属性神经网络能较好地解决细粒度(fine-grained)图像的检索问题。
1.2 基于公安行业语义的人像分类属性
对于人像的描述和特征属性,我国公安行业已有现行的国级、部级标准(下简称行标)。较之现有CelebA(Large-scale CelebFaces Attributes Dataset)、LFW(Labeled Faces in the Wild Home)等已知的开放数据集而言,行标属性分类一是针对部件(主要指面部五官)的分类更细致,二是其关心的五官及整体面部特征与开放数据集不尽相同,如CelebA数据库中40种属性中仅有18种涉及到行标关心的五官及整体面部特征,三是属性值设定更加符合国人的表述方式,如三角眼、长方脸等。表1为本文采用的行标与CelebA中相关属性的比较(仅列出鼻部、前额部的相关属性)。本文通过多标签分类神经网络对人像库进行了基于行标分类标签,并生成了基于行标语义属性的人像分类表示集。

表1 本文采用的人像语义属性与CelebA中的属性设置的比较(前额部、鼻部)
1.3 交互式图像检索
交互式图像检索技术是将人的参与引入到检索过程中,以解决人眼视觉和机器视觉间很难跨越的“语义鸿沟”[7]的检索技术。近几年,学者们注意到该方法的优越性,尝试将该方法作为人工分辨环节(human loop)[12]与各类机器视觉算法结合使用,在人像检索领域中,获得了较好的应用效果。
在交互方式上,绝大多数交互式系统采用了更加便于机器理解的“是或否”的二进制(binary)选择方案,部分采用了选择式方案[6]、比较式方案[8]、问答式方案[13]。本文在交互式检索部分提出采用了“多选一”式的选择交互方案,以减少交互次数、提升算法效率,并通过分类排序和部分丢弃策略进一步解决单一交互式系统计算量大、收敛慢的问题。
1.4 引入显著性属性的交互式图像检索
图像显著性属性(也可称为视觉兴趣属性)的原理是让机器模仿人眼对图像不同区域的重视程度,提取出图像的主要特征属性[14]。其难点在于机器往往对何为显著性属性这一问题无法成功把握。对此,本文提出利用交互式系统“人机互动”的天然优越性,让操作者直接“告知”机器所寻找目标的显著性属性,从而大大降低了查找的范围,提升了算法的效率。
2 方法介绍
2.1 整体框架
基于显著性语义属性的交互式人像检索方法主要由以下几个步骤组成:基于行标语义属性构建一个多标签学习神经网络,将图像转化为各属性标签的表示集[15];进行第一次人机交互,标记显著性语义属性,分类及分类排序包含显著性属性图像集和剩余图像集,并根据策略获取下一步候选队列(candidates);循环进行第二步层进式人机交互,并根据人工选择结果进行再排序,生成下一循环的候选队列,直至操作者确认结束。本文提出的基于显著性语义属性的交互式非标人像检索方法的整体框架如图1所示。
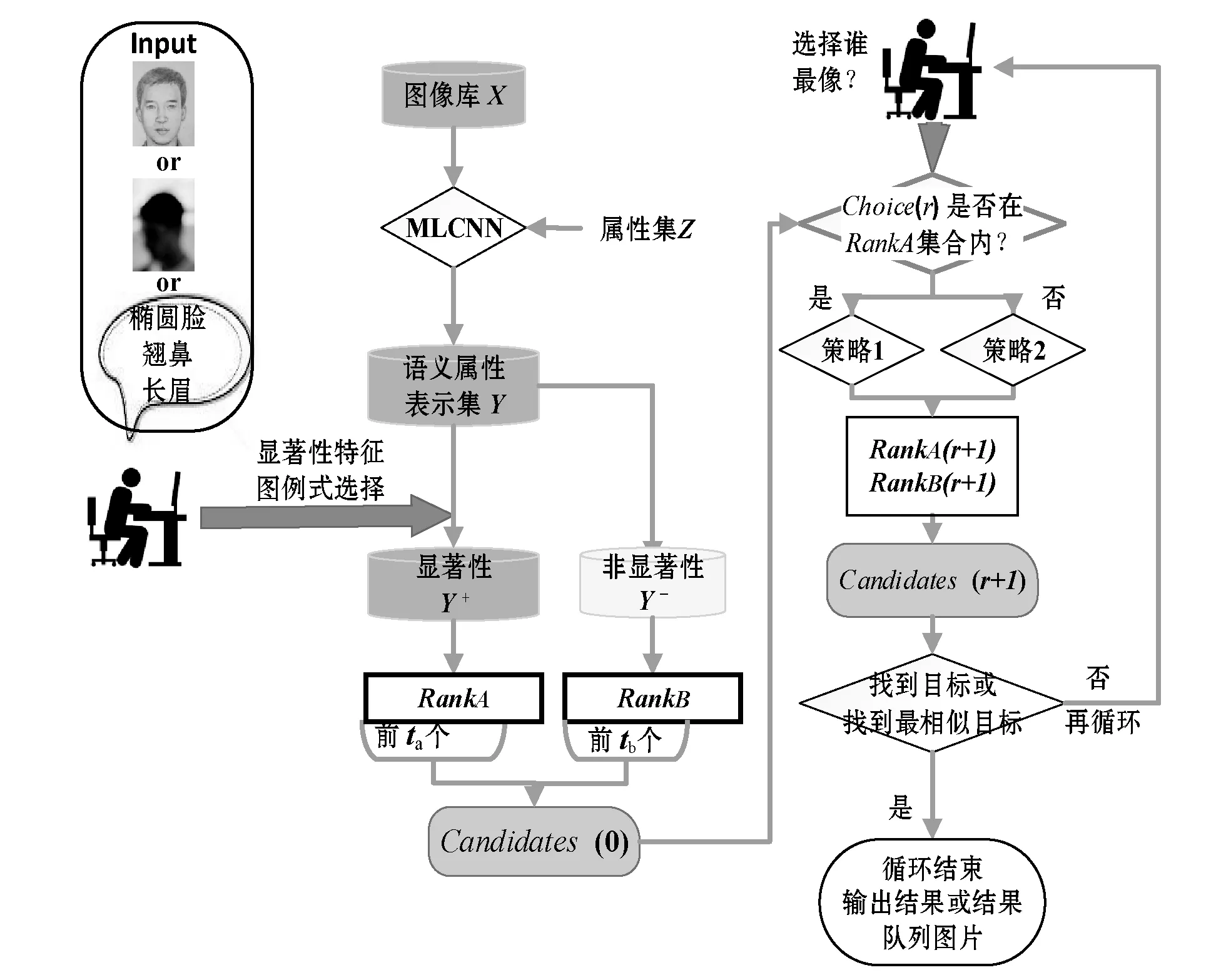
图1 基于显著性语义属性的交互式非标人像检索方法示意图
2.2 详细实施过程
方法的细化实施过程如下:
(1) 设I幅训练图像集为{xi|xi∈Xv},v为图像向量的维度。设共计L个行业规范化属性标签集合Z为一维二进制向量{zl|zl∈Z}。应用MLCNN神经网络,将训练图像集转化为v×L维的属性表示集,即:
yi,l=Rep(xi) 1≤i≤I,1≤l≤L
(1)
式中:Rep(·)为从Xv到Yv×L的转化函数。在假设每个属性的贡献(contribution)参数δ(i,l)一致的情况下,图像xi基于各属性的分值函数Score(xi)为yi,l个分属性损失函数C(i,l)的和,即:
(2)
C(i,l)为各有效属性的Softmax多标记损失函数值:
(3)
根据Score(xi),生成X的属性分值矩阵Si,从而生成各图像xi1和xi2间基于属性的距离函数Dis(xi1-xi2):
Dis(xi1-xi2)=(Si1-Si2)T(Si1-Si2)
(4)
(2) 交互式显著性属性获取及初排序。在每次初始化的工作界面上,系统通过交互界面,列出了属性Z中对应的属性值以供操作者选择。交互者仅需选择某几个印象深刻、确定属性的属性值,而对其他相对模糊、无法确定的属性选项予以留白。设每次循环操作者的选择为目标Qr,其中Q0为我们对初始化操作设置的目标,根据操作者对s个输入的人工选择集合记为GQ0,我们生成了s个人工属性集合GQr={g1,g2,…,gs}。根据GQr(r=0),我们将规范化属性标签集合Z中所有属性分类为显著性属性和非显著性属性,将属性集zl改写为zl,φ(l),并将显著性属性判断函数φ(i,l)置为:
(5)
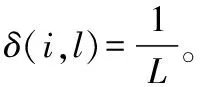
(6)
式中:α(r)表示当{φ(i,l)=1}即判断该属性为显著性,或{φ(i,l)=0}即判断该属性为非显著性时δ(l)会选用不同的属性贡献值;r是交互的循环次数。设初始值α(0)=0.9,且:
α(r+1)=min(0.5,α(0)-0.05r)r>0
从而使后续循环中,显性属性较之非显性属性优势逐渐衰减,直至r=10后,两者属性贡献值一致,从而保证算法在最为重要的前10次循环中达到快速收敛的目的。同时,显性属性优势不断衰减减少显著性属性选择不当所造成的损失。
将Y分为Y+和Y-是为了在下一步中实施不同的图像集缩小策略,以减少每次交互检索的计算量,而设置较大的α值,会使得初始排序中与目标相似属性越多的训练图像相似度排序明显靠前,快速接近目标图像。
将式(6)代入式(5)进行重新计算,获得了两个基于目标Qr按距离倒叙排列的基于显著属性距离的队列RankA(Qr,Ar)∈Y+和非显著属性距离排序RankB(Qr,Br)∈Y-。通过Top(·)取位函数分别取RankA和RankB的前ta和前tb位(本文设ta=15和tb=5)入选交互显示集Candidate(r),即:
Candidate(r)=Top(RankA(Qr,Ar),ta)∩
Top(RankB(Qr,Br),tb)
(7)
获取了初始候选人排序队列Candidate(0)。
(3) 混合相似度再排序交互式检索。为最大幅度减少人工误差,增加机器视觉的辅助判断作用,在这一步检索中,对每次人工选择Choice(r)∈Candidate(r-1)提取的LBP加HSV的整体复合特征Fu,并采用基于改进保持直接简单原则的度量方法(Keep it Simple and Straightforward Metric, KISSME)生成融合特征相似度距离矩阵A:
Dis(xi1-xi2)=(Ai1-Ai2)T(Vin-1-Vout-1)(Ai1-Ai2)
(8)
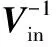
根据式(4)和式(8)生成融合距离函数,即:
D(xi1-xi2)=(1-μ)Dis(xi1-xi2)+μDis(xi1-xi2)
(9)
式中:μ为辅助特征权重函数,将这一权值设置简单化,即如果人工选择Qr+1落在式(7)中前一循环候选人队列中Top(RankA(Qr,Ar),ta)部分,则说明基于显著属性的检索效果好,执行策略1,μ=0.1;反之执行策略2,μ=0.5。
为避免无效循环和加速收敛,在每次循环的再排序步骤前,增加了聚类后的候选人转化操作Kmean():
Top′(RankA(Qr,Ar),ta)=
Kmean(Top(RankA(Qr,Ar),ta))
(10)
以Top(RankA(Qr,Ar),ta)为初始质心,对RankA(Qr,Ar)集合做k-means聚类操作,获取新质心最近图片集Top′(RankA(Qr,Ar),ta)。
同时,为减少每次循环的计算量,进一步加速收敛,当实施策略1时,将RankB(Qr,Br)丢弃,将RankA(Qr,Ar)按前后各一半分给RankA(Qr+1,Ar+1)和RankB(Qr+1,Br+1);反之在策略2中,将RankB(Qr,Br)的后一半丢弃,前一半加入RankA(Qr,Ar),并根据式(8)生成的倒序排列前后各半分赋值给RankA(Qr+1,Ar+1)与RankB(Qr+1,Br+1),再实施检索。
基于以上策略,不断地在进行生成Candidate(r)、候选人聚类转化、获取Qr、生成RankA(Qr,Ar)、生成Candidate(r+1)几个操作中进行循环,最终通过人工断定找到最终目标终止循环。
上述操作和权值设置既避免了仅依靠属性识别带来的弊端,又可以不断缩减矩阵大小,减少了每次交互循环算法的消耗,实现了提升识别效果和快速检索目标的双重作用,从而使算法可应用于中大型规模的数据集。
3 实 验
3.1 专业数据库生成
为贴近行业应用的需求,本文采用了行业内收集的人像样本,构建了30万人人均1.7幅正面照片库Df作为训练集。所有图像根据行标分为73个语义类别,合计315个属性。为避免某一属性下零样本和小样本的情况,本文手工挑选了Df中1 000人,以保证每个属性下的分类图像数DifN大于等于5,进行了专家级标注,该标准人像集记为Ds。通过MLCNN方法,生成了D的属性表示集Dfd。
验证人员UserS共计40人,他们被分为2组,UseA组20人为专业侦查人员,UseB组20人为一般测试人员。
3.2 实验方法构建
实验将兼顾算法本身性能和应用效果,围绕本文方法的重点,在算法收敛速度、精度、性能,以及应用适用性等方面进行验证。为此,本文构建实验方法如下:
1) 不同方法生成度量距离的效果比较。本文的检索性能通过查准率P(precision)、召回率R(Recall)和F1(F-measure)值衡量,实验结果如表2所示。
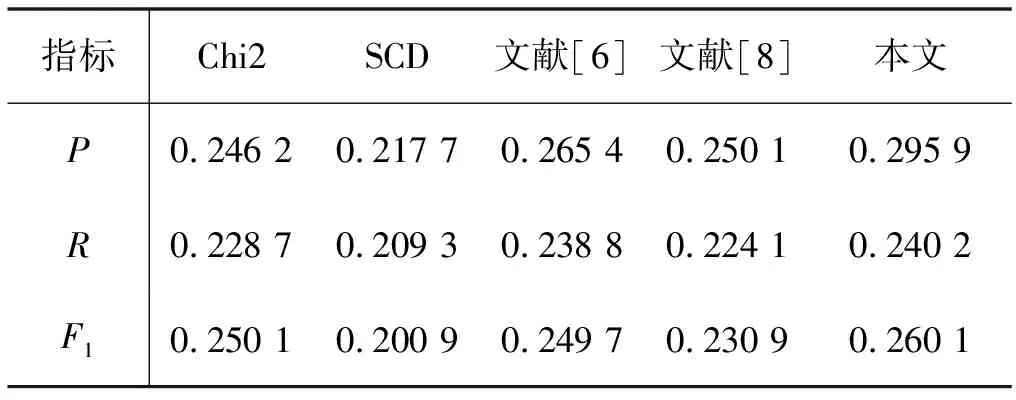
表2 各算法生成度量距离结果比较(r=1)
2) 引入显著性属性查询结果比较。通过计算累积精度值[8](cumulative precision)P(r)作为每次循环r可能成功的概率,精确评估算法的性能,结果如图2所示。其中,con为无显著性属性的结果,con+为添加显著性属性和非显著性属性分类的结果。由于本文算法在r=0时进行了初排序,故P(r)初始值不为0。
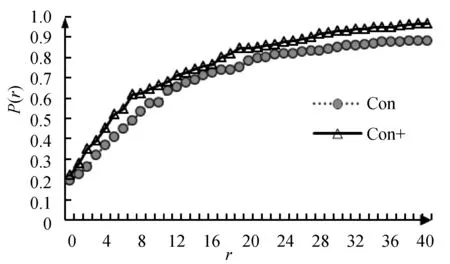
图2 添加显著性属性对算法P(r)值的影响
3) 用户能力对算法结果影响测试。已知交互式系统对用户的专业性、熟练度要求较高,且最终是否能检索成功存在一定随机性[6]。将用户组UseA和UseB用每种方法共10次进行分类结果记录,得到表3。最终成功数也参照设置HML方法,即60次循环为人可接受的最大交互次数,超过则视为失败;其他数值在统计中均去除了检索失败的情况。其中,本文方法在循环次数上均需要加一,这是因为本文方法循环次数上需要增加其他文献方法所没有的显著性属性交互初排序步骤(r=0)。
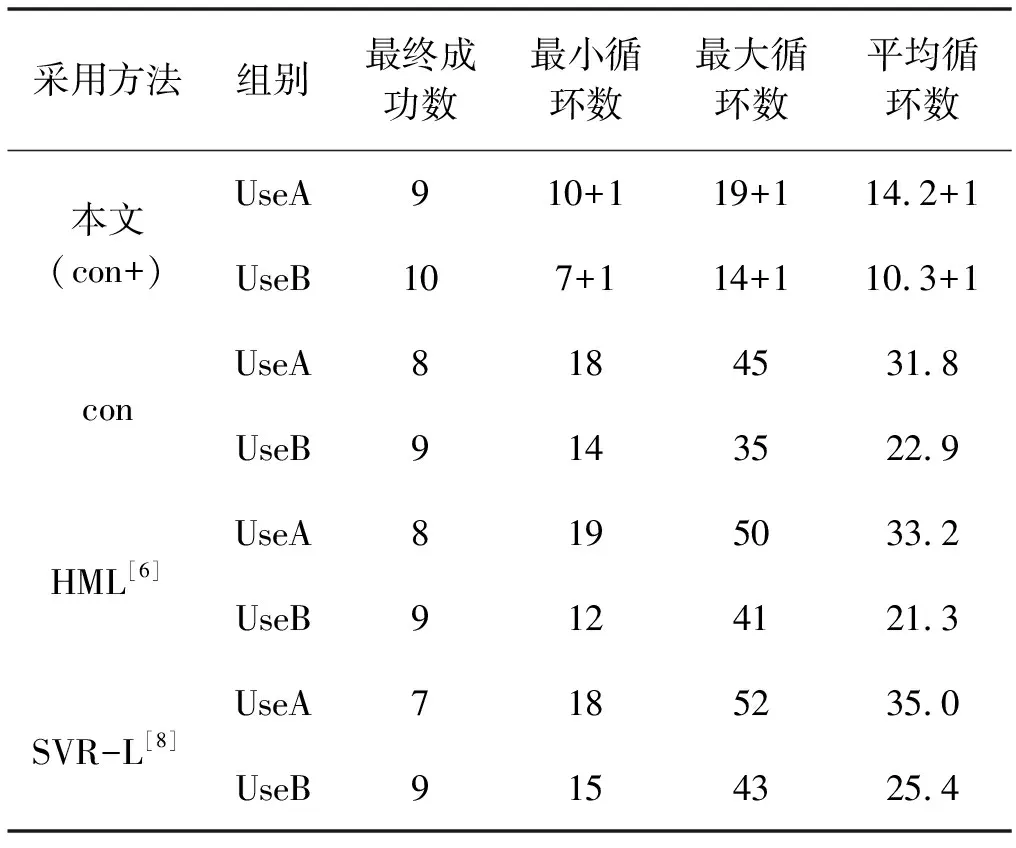
表3 各算法检索效能比较
4) 对不同应用适用性能力应用方法比较测试。从D中随机选出40幅目标图像作为目标集合,其中10幅人像记为Query1被转化为专业人像画家根据照片绘制的模拟画像,但操作时为全程可见;10幅人像Query2被进行模糊化或残缺处理(处理至类似低清视频中效果),也全程可见;10幅图像Query3未被处理,但仅允许操作者记忆3秒后隐藏显示;10幅图像Query4被转换成60度侧面照(无法完全看清全脸),且操作时为全程可见。由UseA、UseB用户组分别应用本文算法进行三种目标图像的各10次的检索,并绘制图3。
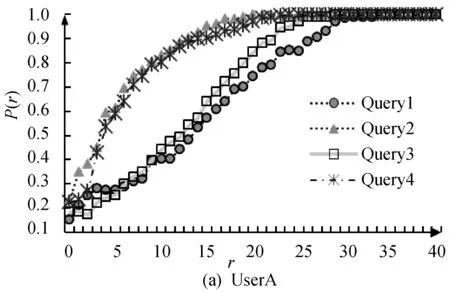
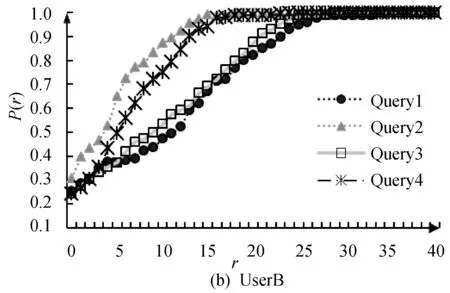
图3 不同用户组检索不同目标的P(r)值曲线图
3.3 实验数据分析
1) 根据表2可知,本文所用的度量距离方法,在查准率、召回率、F1值上均达到同类算法最优,尤其是查准率较之其他算法提高最多,提升了3到7个百分点,证明了算法在度量距离取值方法上的优越性。
2) 根据图2,未添加显著性属性的con曲线较之con+更加平滑;而添加显著性属性的con+升速较快,尤其在前10次循环中表现更甚,其在第5次达到了0.453,较之con第5次的0.369提升了8.4个百分点;在第10次达到了0.663,较之con第10次的0.577提升了8.6个百分点;而con+在最后极值达到0.966,较之con极值0.887提升了7.9个百分点。实验结果充分证明添加显著性属性的再排序方法对算法效能提升显著。
3) 根据表3,本文算法最终成功检索数较之其他算法多,平均循环次数上较其他算法有非常大的提升。未加入显著性的算法con整体上较SVR-L更优,略优于HML,但加入显著性属性后平均循环次数明显减少,平均循环次数仅为15.2和11.3,证明了本文算法在减少循环、快速收敛上的优异性。同时,实验结果表明,交互式系统的整体检索效果仍然与用户的判断能力有很大关联,但本文算法会帮助减弱非专业用户与专业用户之间的差距。
但针对本文唯一一次不成功的检索进行追踪分析,发现用户在r=0时显著性属性判定和r=2时相似人像选择连续两个步骤中均判定错误,正确结果被排除而导致了任务失败。这表明本文算法失败的主要风险集中于前期显著性属性判定步骤中,但这个是可控的。
4) 由图3可知,人脑无论针对模拟画像、模糊残缺人像,甚至是Query4仅看到侧面的情况下,也能较好把握人像的属性特征,尤其是专业人员,这些都是目前机器视觉很难实现的,进一步说明了在特殊应用中选择交互式算法而非其他仅机器视觉算法的正确性。同时,针对模拟画像Query1,我们发现非专家组UseB往往在后期循环交互过程中无法较好把握目标转化为真实人像的特征,导致了该组平均循环次数的骤然增加,但该情况在专家组UseA中得到了很大缓解,故本文建议针对模拟画像的应用,所提的方法更适合专家级的用户使用。
4 结 语
本文提出一种基于显著性语义属性的交互式非标人像检索方法,实现了一种人工工作量合理、检索成功率高、收敛速度快、应用面广、符合公安行业规范的非标人像检索应用。通过融合属性的距离函数设置,逐步减少距离函数计算量的图像集缩小策略,引入显著性属性的再排序方法,大大优化了算法效率。下一步,我们将进一步提升算法对人为判断错误的纠错能力,以及寻找针对模拟画像的检索应用更加行之有效的方法。
