一种基于极端尺度变化的船舶识别方法研究
2021-01-15郭延华马世超
郭延华 孙 磊 马世超 何 宏
(天津理工大学电气电子工程学院 天津 300384)
0 引 言
随着经济全球化的发展,海上运输日益繁忙,交通事故时常发生,因此能否对船舶进行有效识别是一个极具挑战性的问题。随着目标检测技术日益完善,船舶识别[1]技术领域得到快速发展,已然成为目标检测[2]方向的一个研究热点。但是海上识别环境较为复杂,输入数据前/背景可辨识度较小且含有大量极小船舶目标,导致目标检测器不能对船舶进行有效识别,为识别任务增加了难度。
目前,基于计算机视觉的深度学习算法[3]在目标识别领域取得了较好的效果。Krizhevsky等[4]首次将ReLU、Dropout和CUDA等技术应用到卷积神经网络中,极大地提高了图像分类的正确率,并掀起了深度学习研究的热潮。Girshick等相继提出基于区域问题的选择性搜索算法[5]、感兴趣池化结构[6]以及区域候选网络[7],将目标特征与整个网络进行权值共享,减少了网络计算成本,极大地提高了识别速度和精度,但是对于船舶实时检测仍是巨大的挑战。为平衡识别速率和准确率的问题,Redmon等[8-10]提出基于回归的快速检测算法,直接回归预测出船舶目标的边界框坐标及类别,且满足实时性的要求,但对于船舶目标相邻较近且目标极小时,易出现漏检、错检、重复识别的问题。黄于欣[11]利用OpenCV结合智能算法提取船舶运动轨迹,挖掘潜在特征,实现船舶轨迹的监控与跟踪。朱广华[12]将BP神经网络与卡尔曼滤波算法结合,通过估计船舶运动参数来自适应识别船舶坐标,但是由于海上环境复杂,图像像素较低,不能够对极小船舶目标进行良好的识别。
针对上述问题,结合船舶识别任务的高速率和高精度的要求,本文提出一种基于极端尺度变化下的目标识别算法——YOLO-G算法,如图1所示。该算法采用残差连接方式构造深度卷积神经网络,使用了65层卷积层构建特征提取器Darknet-65网络,进行二维卷积操作提取船舶特征,输出4个不同尺度的特征图,分别为13×13、26×26、52×52、104×104。在每个特征图尺度内,通过卷积核的方式进行特征图的局部交互,构成模型的特征交互层YOLO层,从而输出目标的中心坐标及类别标签。网络中引入先验框机制并对传统的交叉熵函数[13]进行改进,选用调制函数作为模型的损失函数。该损失函数不仅降低了简单负样本在训练中所占的权重,完成了困难样本的挖掘,使网络收敛得更快,鲁棒性更好。通过大量对比实验验证了YOLO-G网络的有效性。
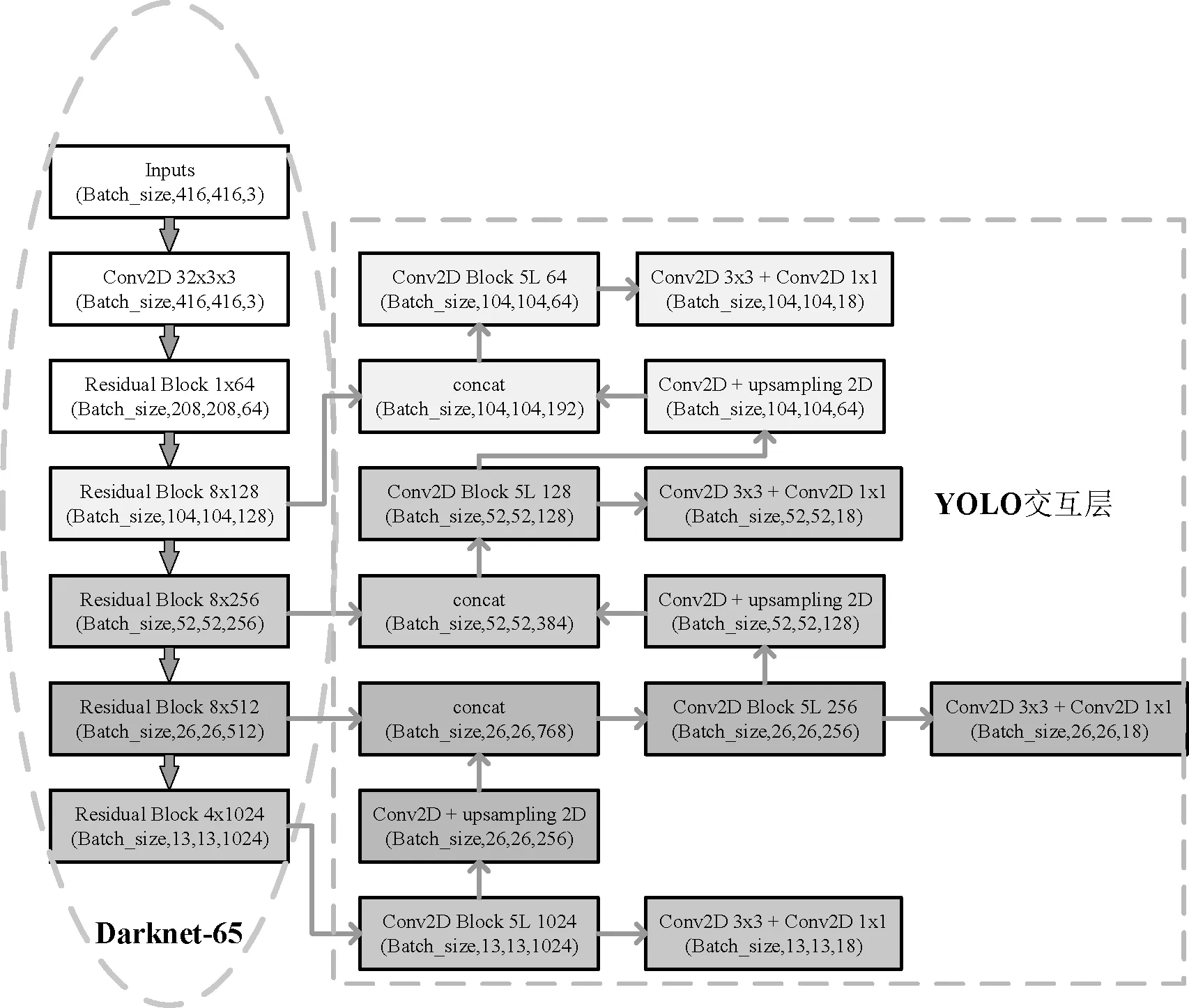
图1 YOLO-G结构示意图
1 深度卷积神经网络
1.1 经典卷积神经网络
快速检测算法将目标识别问题转化成回归问题,对于输入数据可以一次性将目标类别和位置信息预测出来。该算法弃用候选区域操作,而是选用整幅船舶图片进行迭代,大幅度提升了检测速率,满足目标识别的实时性。快速检测算法YOLOv3主要由两部分组成,分别是特征提取器Darknet-53和多尺度YOLO层。
Darknet-53网络由一系列的1×1和3×3的卷积层构成,每个卷积层后都连接着批量归一化层(Batch Normalization,BN)和局部响应归一化层(Leaky ReLU)[14]两个神经网络结构单元,其中两个卷积层构成一个残差卷积组,卷积组之间采用残差连接方式,如图2所示,构成残差结构层(Residual,res)。通过这种新型神经结构单元连接方式,使Darknet-53有效地减少了参数计算量和网络的复杂程度,能够有效地提取目标的深浅层特征,并避免发生过拟合。
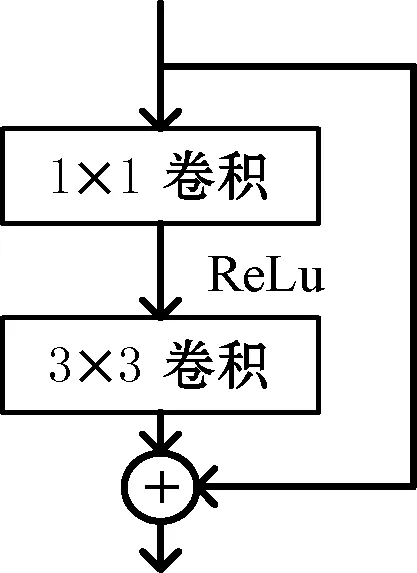
图2 残差单元结构示意图
多尺度YOLO层使用三个尺度的特征图进行高度特征融合[15],构成特征金字塔网络,提取图像深层语义信息,有效提高了对于不同尺度的目标识别的检测效果。在网络训练时,采用多种图像增强技术[16],扩充数据集的多样性和丰富性,增强了网络泛化能力及鲁棒性。
1.2 改进的YOLO-G算法
为实现船舶实时识别分析和小目标高识别准确率的要求,本文对YOLOv3的网络结构和识别算法进行改进,改进后的网络命名为YOLO-G。该模型结构主要分为特征提取器Darknet-65和YOLO交互层两部分(见图1)。
1.2.1特征提取
Darknet-53网络输出3幅不同大小的特征图,最大特征图尺寸为52×52,可以完成常规尺寸船舶目标识别任务,但对于识别样本分辨率较低,船舶目标尺寸极小等情况时,无法完成船舶目标检测任务。因此,本文对原始网络Darknet-53的网络结构进行改进,在深层特征图较大的深层结构处,加入12个卷积层和6个res层,构建网络输出4个不同大小的特征图,最大特征图尺寸为104×104,进行极小船舶目标的识别。改进后的基础网络命名为Darknet-65。
Darknet-65基础网络为全卷积网络,通过网络矩阵节点获取目标的基础特征和深层语义信息,具体网络结构参数如图3所示。输入尺寸为416×416,通道数为3的图片,每个卷积层都会对输入数据进行批量归一化操作和激活函数计算,第一个卷积层中通过32个3×3的卷积核,对船舶输入信息进行提取,将其输出作为第二层的输入,再通过64个3×3、步长为2的卷积核进行遍历图像,实现下采样操作,其后采用YOLOv3的残差连接方式。
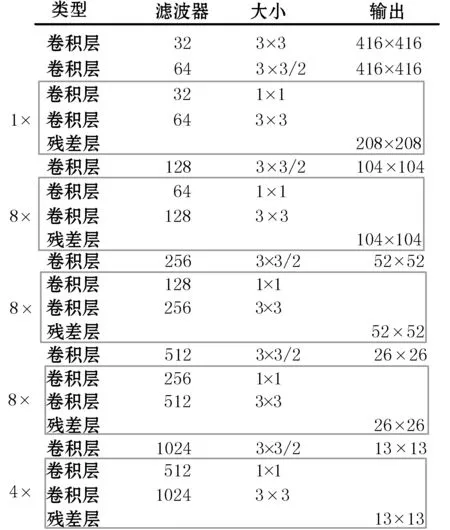
图3 特征提取网络结构图
将3×3,1×1的卷积层构成残差卷积组,输出208×208大小的特征图。在残差卷积组中:
Si=Gi([S0,S1,…,Si-1])
(1)
式中:S0为网络输入的特征图;Si为第i层的网络输出,[S0,S1,…,Si-1]表示特征图间的拼接;Gi()为批量归一化、激活函数及卷积操作的组合函数,实现第i层的非线性变换,Gi()操作为Conv(1,1)-BN-ReLU-Conv(3,3)-BN-ReLU。
接下来采用上述结构组成方法及下采样操作,构建8×、8×、8×、4×的4组残差卷积组,在该网络的4倍、8倍、16倍、32倍降采样处,分别输出104×104,52×52,26×26,13×13大小的特征图,并通过上采样层进行特征图融合,构建特征金字塔网络,实现极小船舶目标识别。
1.2.2多尺度检测
由于深层卷积神经网络,其浅层结构输出的语义信息较少,但其目标坐标信息准确,深层结构输出的语义信息较为丰富,但其坐标信息较为粗略。YOLO-G通过多尺度预测直接在图像上回归出船舶边界框和类别标签,如图4所示。
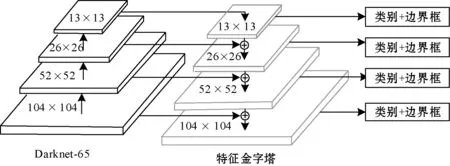
图4 多尺度检测示意图
YOLO交互层被分为4个独立的检测分支,每个分支含有6个卷积层,并进行2倍的上采样操作来提高特征金字塔的学习能力。将每个分支通过张量拼接(Concat)的方式与上采样层进行连接,实现各级特征图之间的特征交互,完成船舶图像的浅层位置信息和深层语义信息的高度融合,使网络学习到更加细粒度的特征,获得更有价值的语义信息。多尺度特征融合公式为:
Xf=θf{Ti(Xi)}
(2)
(3)
式中:Xi为需要进行融合的特征图;Ti为上采样操作;θf为同尺度下的特征图张量拼接;Xf为融合后的特征图;θp为对得到的特征图重构识别。
经过多尺度特征融合后,YOLO层最终输出4个尺度分别为13×13、26×26、52×52、104×104的特征图。由于特征图越大感受野越小,故而其所对应的识别目标尺寸为大、中、小、极小尺寸。在检测阶段,以S×S特征图为例,网络将船舶图像分成S×S个网格,若目标中心坐标处于某个网格中,则由该网格进行目标检测,其中每个网格会输出4个坐标信息和类别标签。
1.2.3先验框机制设计
为了使网络快速准确地预测出目标的边界框,本文对船舶数据集采用K-means[17]聚类算法,计算出合适的先验框(anchor box),其中聚类分析使用候选边界框与真实边界框的交并比(IOU)。聚类公式为:
d(box,centroid)=1-IOU(box,centroid)
(4)
网络输出4个特征图,每种特征图设定3种先验框,总共聚类出12种尺寸的先验框,经聚类计算后,得到的先验框尺寸分别为(4,5)、(9,8)、(11,18)、(22,11)、(15,29)、(46,25)、(25,64)、(93,57)、(52,127)、(86,197)、(141,261)、(260,313)。为每个特征图每个网格分配三个先验框,采用三个先验框中与真实边界框(Ground True,GT)的交并比(IOU)最大的先验框来检测目标。计算流程如图5所示。YOLO-G通过直接预测相对于网格的位置信息,计算目标的边界框坐标信息。边界框计算公式为:
bx=σ(tx)+Cx
(5)
by=σ(ty)+Cy
(6)
bw=pwetw
(7)
bh=pheth
(8)
式中:tx、ty、tw、th是网络预测的边界框坐标;bx、by、bw、bh是真实边界框坐标;Cx、Cy为相对于最上角网格的偏移量;σ()为逻辑函数,将数据归一化为0到1之间;Pw、Ph为先验框的宽度和高度。
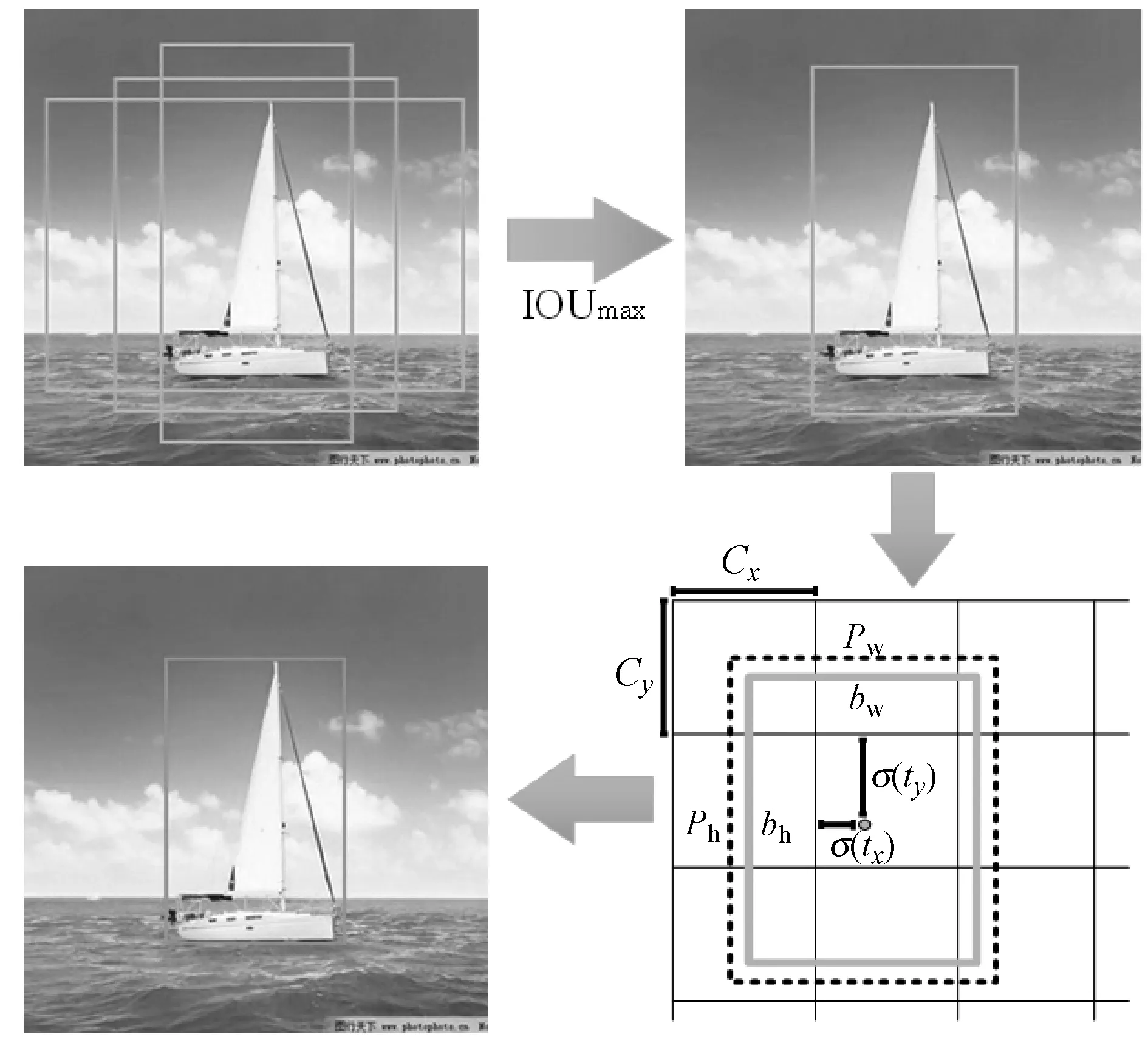
图5 船舶坐标计算示意图
1.2.4损失函数设计
针对船舶小目标识别问题分析,发现输入数据的前/背景较难区分,并且目标所占图像比例远小于背景所占的比例,数据集以负样本为主,使网络无法学习有用信息导致模型功能退化。针对以上情况,本文选用调制函数来处理样本不平衡[18]的问题。
本文从YOLOv3的交叉熵损失函数(L)引入到调制损失函数(Modulation Loss,ML)。交叉熵函数公式:
L=-[mlog(n)+(1-m)log(1-n)]
(9)
把交叉熵函数整理之后可得:
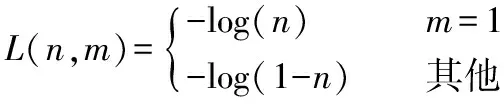
(10)
式中:n的值是+1或-1;m是标签(label)等于1时预测的概率,其值范围为0到1。为方便计算用nt代替n,公式如下:
(11)
对交叉熵的改进,增加了一个系数αt,跟nt的定义类似,当label为1时,αt=α;当label为-1时,αt=1-α,α的范围是0到1。公式如下:
L(nt)=-αtlog(nt)
(12)
在大量数据训练过程中,便于分类的负样本构成了损失值变化的主要部分,尽管αt有效地解决了样本失衡问题,但是对于难/易样本分类仍具有一定难度。故提出在交叉熵函数中加入调制函数:(1-nt)γ,γ>0,由此可知,当样本类别失衡时,nt是很小的,当m=1时,n小于0.5被定义为类别失衡,反之亦然,因此调制系数就趋于1,交叉熵函数没有太大改变;当nt无限接近1时(类别正确),调制系数接近于0对总损失值影响较小;当γ=0时,调制损失函数就是传统的交叉熵,当γ增加时,调制函数也会相应的增加,如图6所示。调制损失函数不仅解决了样本失衡的问题,还有效减少梯度消失的情况并加快网络收敛速度。
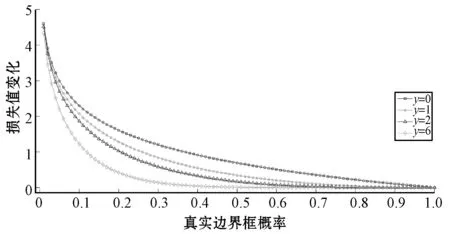
图6 γ参数对损失值和边界框概率的影响曲线
调制损失函数不仅能修正样本权重,而且能调节困难样本和简单样本的权重,损失函数公式如下:
ML(nt)=-αt(1-nt)γlog(nt)
(13)
本文首先通过构建特征提取器Darknet-65及多尺度交互层完成目标特征提取,获得目标的坐标位置信息和类别标签。其次引入anchor机制和改良损失函数,提高网络模型的识别精度和识别准确率,从而构成新型单级检测器YOLO-G。
2 实 验
2.1 实验环境
为验证YOLO-G网络目标识别性能及实验数据对比的公正性,本文在BOAT船舶数据集和公开数据集COCO[19]上评估YOLO-G网络的性能。实验基于Darknet[20]框架进行识别操作。具体实验环境如表1所示。
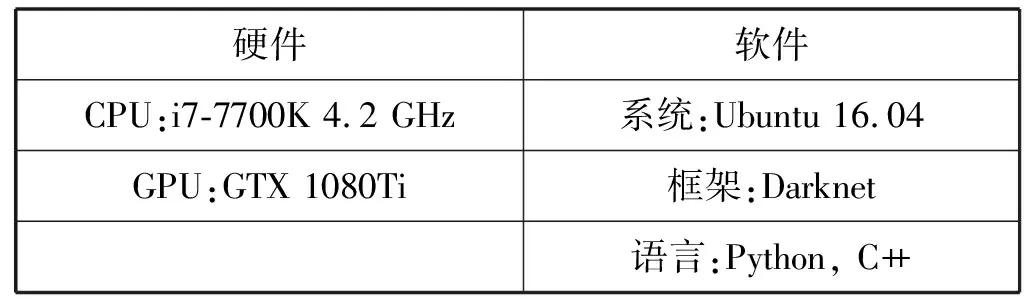
表1 实验环境
2.2 数据集制作
船舶目标大多为非合作目标,很难通过网上现有船舶图像建立大规模船舶数据集BOAT。除了通过搜集网络船舶图片和海上实际船舶图片外,本文通过SolidWorks 3D[21]软件制作6类宽高比为2∶1的船舶目标模型,并引入CST电磁仿真软件,CST参数设置如下:位置方向角为-90°~90°,仰俯角为0°,角移动速度为1°;雷达中心频率为12 GHz,带宽为200 MHz,选用垂直极化作为极化方法,采样率为512,选用默认网络分析模型尺寸,通过射线追踪算法进行计算。最终仿真了6类船舶目标的181个方向角的BOAT样本数据。
训练样本多样性的缺失,容易导致模型发生过拟合。单单通过上述的数据样本数量对于进行小目标的船舶识别,还未达到识别标准。因此对船舶数据集进行扩充,具体步骤如下:
(1) 加入噪声。对原始船舶数据依次加入服从高斯分布的噪声ki~K[0,θi],共进行3次,将原本数据样本扩充了3倍。
(2) 数据增强技术。修改输入数据的曝光度,色调和饱和度,利用数据抖动以及随机旋转、翻转、平移策略生成更多的训练数据,在数据集中加入大量含有极小目标的图像以丰富数据集的多样性,提高网络模型对不同尺寸输入样本的鲁棒性和泛化能力。通过上述2种技术手段,增强了BOAT数据集的多样性。
BOAT数据集由10 000幅船舶图片组成,船舶类别包含客船、渔船、帆船、军舰、游轮、公务船等6类船舶。数据集将采用VOC数据集格式,在BOAT中选取70%的数据作为训练集,将剩余数据作为测试集来验证模型的识别性能。
2.3 实验与分析
2.3.1模型性能指标计算
本文使用YOLO-G和YOLOv3算法对BOAT数据集进行训练,根据训练过程中的损失值变化和P-R曲线来验证网络性能。P-R曲线的样本插值算法采用VOC2007标准,也就是11点插值法(eleven-point interpolation)。其中准确率(precision)为被识别出来的真实船舶目标数量占所有被标识的目标数量,召回率(recall)是被识别出来的船舶目标数量占图像中所有目标数的比例。先验框与真实框的交并比(IOU)阈值标准设置为0.6。
准确率(precision)公式为:
(14)
召回率(recall)公式为:
(15)
式中:Tp为大于阈值0.5且被识别的目标数量;Fp为小于等于阈值0.5识别的目标数量;FN为未识别的目标数量。
2.3.2训练结果分析
通过随机梯度下降算法[22]对网络进行端到端地训练,整个训练过程进行50 000次迭代,训练平均损失值趋于0时停止训练,得出相应的船舶识别模型,两者的训练损失变化及P-R变化分别如图7和图8所示。

图7 训练过程损失值变化曲线
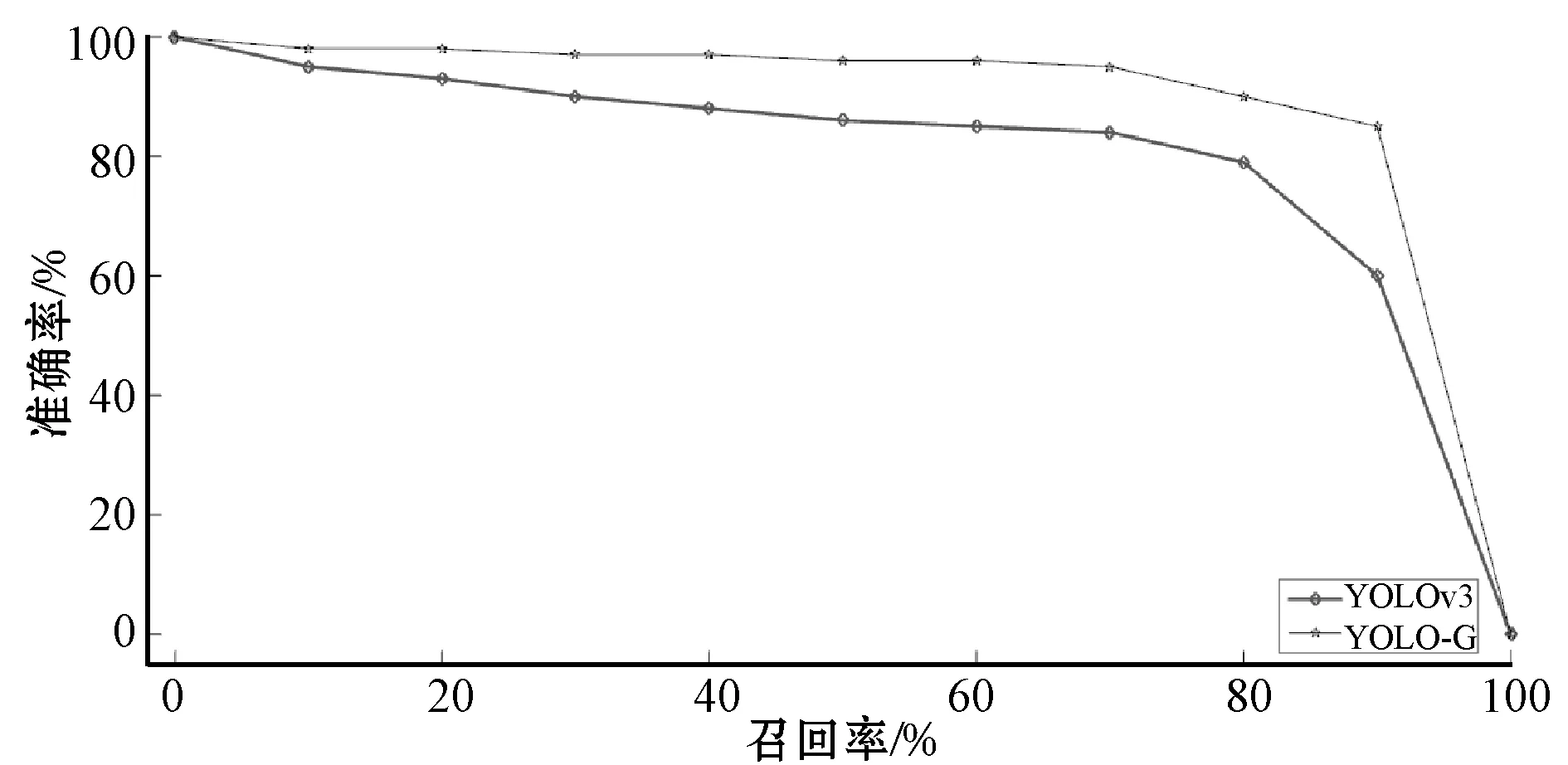
图8 P-R函数关系曲线
可以看出,YOLO-G模型训练损失变化曲线和P-R曲线更加平稳,在相同训练迭代次数下,其平均损失值远小于YOLOv3模型,训练结束后,当YOLO-G模型召回率较高时,依然取得较好的平均精度均值。
YOLO-G和YOLOv3模型训练的参数基本一致,动量和权重衰减系数分别配置为0.9和0.000 5,批量大小设置为32,初始学习率设置为0.001,并依次降低为 0.000 1与0.000 01。15 000次迭代后,网络模型处于局部最优化,即使通过减小学习率也无法使平均损失值显著下降。YOLO-G和YOLOv3模型训练的平均损失值(avg-loss)、最大召回率(max-recall)及最高平均精度均值(max-mAP)如表2所示。
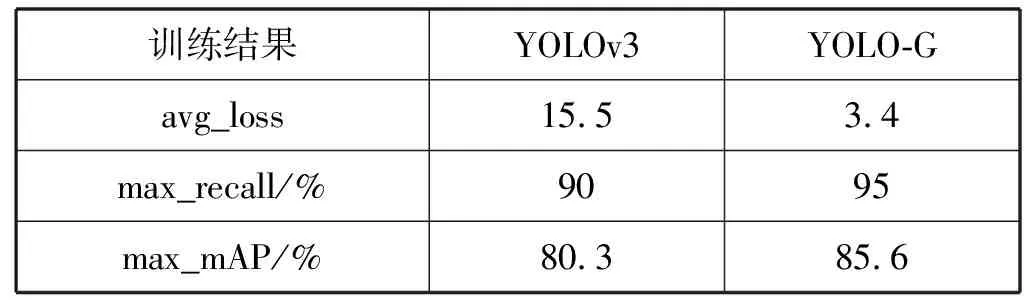
表2 YOLOv3和YOLO-G训练结果
由表2得知,YOLOv3网络训练的船舶识别模型的平均损失值为15.5。本文通过重构网络架构和改进损失函数使平均损失值减少了12.1,最终平均损失值为3.4。模型训练结束之后,在测试集上对比YOLO-G和YOLOv3的平均精度均值(mAP),mAP变化曲线如图9所示。相同训练迭代次数下,YOLO-G的平均精度均值会比YOLOv3高很多,YOLO-G模型的最高精度值出现在16 000迭代处,mAP值为85.6%(YOLOv3为80.3%),相比于YOLOv3模型增加了6.6%,且精度曲线更加平稳。这证明本文提出的网络结构和损失函数算法进行模型训练,很大程度上提升了模型的识别性能。
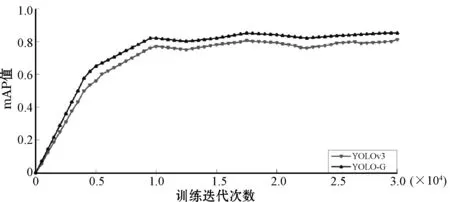
图9 YOLOv3和YOLO-G的mAP变化曲线
2.3.3分类结果分析
为验证YOLO-G算法的有效性,将通过与常用的单级检测器算法对BOAT数据集6类船舶进行分类实验。采用SSD513、DSSD513、YOLOv2、YOLOv3等单级检测器算法与YOLO-G算法进行不同船舶的分类对比实验,实验结果如表3所示。实验环境如表1所示,操作系统为Ubuntu 16.04,深度学习框架为Darknet,GPU为GTX 1080Ti。
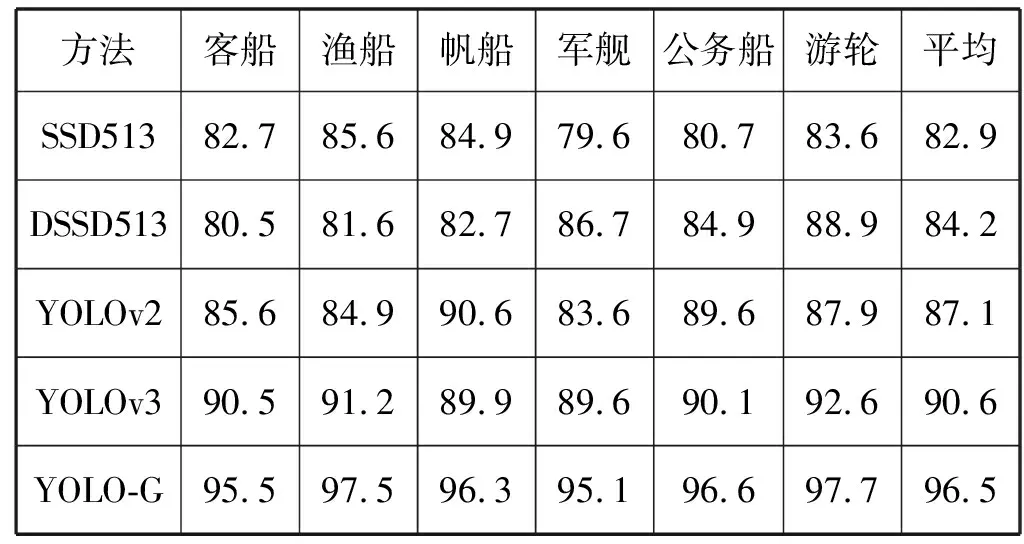
表3 单级检测器分类结果对比 %
表3给出了不同检测算法对BOAT数据集的分类正确率。可以看出,SSD系列算法的分类正确率普遍较低,与YOLO系列算法的正确率差距较大,其中SSD513分类正确率最低,平均正确率为82.9%,其军舰的分类正确率仅为79.6%,分类效果不好。YOLOv2算法的分类平均正确率为87.1%,军舰的分类正确率为83.6%,与SSD系列相比具有较大的提升,可知YOLO网络性能比SSD网络更加优越,具有更高的分类检测性能。YOLOv3的平均正确率为90.6%,略高于YOLOv2的正确率。本文算法YOLO-G的平均分类正确率为96.5%,较难分类的军舰样本正确率也达到了95.1%。相比于其他几种分类算法,YOLO-G船舶分类的正确率得到大幅度的提升,可知YOLO-G算法可以很好地获取船舶的边缘特征,进而提取船舶的深层特征信息,可以很好地将不同类型的船舶区分出来,从而证明该算法的有效性及优越性。
2.3.4船舶识别分析
船舶目标占据比太低(目标尺寸是原图像的0.1),输入图片分辨率低(目标像素小于32)、船舶目标特征遮挡等问题,依然是目标检测器普遍存在的识别难题。针对以上问题,本文进行船舶目标识别研究,来验证YOLO-G模型和YOLOv3模型在实际目标识别任务中的检测性能,实验结果如图10所示。

(a) YOLOv3识别 (b) YOLO-G识别图10 遮挡环境下的目标识别对比
图10测试样本目标特征部分被遮挡,有效识别信息重叠。图10(a)识别结果中,将3个船舶部分特征重叠的目标标识为一个边界框,同时将识别背景易区分的3个船舶小目标漏检;图10(b)中图像特征遮挡部分,船舶目标都被准确识别,剩余较小船舶目标全部被识别,得出YOLO-G模型具有更高的召回率。可以看出,YOLOv3和YOLO-G都能识别船舶目标,但是YOLOv3训练出的船舶识别模型具有较大的识别误差和较小的召回率,可知新型单级检测器YOLO-G具有较高的目标识别性能。
图11测试样本远处目标与背景的颜色相近,前/背景不易区分,且小目标船舶相距较近,提升了识别难度。图11(a)识别结果中,将背景处的高楼标识为船舶边界框,同时对船舶目标产生重叠边界框的情况。相反,图11(b)中,将所有船舶目标都正确的识别出来,不存在漏标、错标的情况。这证明了YOLO-G在图像目标与背景较难区分时,可以良好地处理数据,提取目标特征,完成困难样本的数据挖掘,对测试样本的船舶目标进行精确定位及标识。YOLO-G模型有效地提升了困难样本识别率低的问题,虽然在识别精度上仍有提升空间,但是YOLO-G模型在单级检测器中具有较高的研究意义和识别性能。

(a) YOLOv3识别 (b) YOLO-G识别图11 前/背景难区分的小目标识别对比
图12测试样本分辨率较低,且存在大量的极小船舶目标,增大了检测器识别难度。图12(a)识别结果中,半数以上的小目标未被标识边界框,处于样本中间区域的目标被正确识别。相反,图12(b)中样本所有船舶小目标均被正确识别出来,该模型在识别极小目标时具有较大的优越性。这表明YOLO-G模型的多尺度特征检测,能够较好地处理尺度变化如此之大的样本,且保持较高的识别准确率。

(a) YOLOv3识别 (b) YOLO-G识别图12 前/背景难区分的小目标识别对比
图10-图12的实验结果表明,本文的YOLO-G模型能够应用于多种识别环境的目标检测,证明YOLO-G模型对于目标检测具有极大的作用。
2.3.5先进的单级检测器进行比较
为验证YOLO-G网络在目标识别上的性能及实验数据对比的公正性,本文在具有挑战性的COCO数据集上对YOLO-G进行模型定量评估,MS-COCO数据集具有类别丰富、场景复杂、小目标数量多的特点。通过COCO的标准数据指标AP、AP50、AP75(参数AP50, AP75代表阈值分别为0.5、0.75时进行检测的精度值)对各算法进行对比实验,并将实验结果与最先进的单机检测器算法进行比较。
将本文算法YOLO-G与SSD513、DSSD513、YOLOv2、YOLOv3算法进行精度比较,结果如表4所示。YOLO-G算法的平均精度值为34.9%,保持较高的识别率,与其他检测器相比较,也占据一定的优势,从而验证了YOLO-G网络识别的有效性。YOLOv3算法具有较高的识别水准,平均精度值为33%,但是由于其自身网络结构限制,导致对于船舶小目标不能有效识别。YOLOv2网络层数较少,不含有特征金字塔网络,因而其平均精度值为21.6%。SSD513、DSSD513[18]分别取得了31.2%、33.2%在精度上表现良好,但是由于网络层数较多,导致网络计算量大,易出现收敛速度慢的情况。
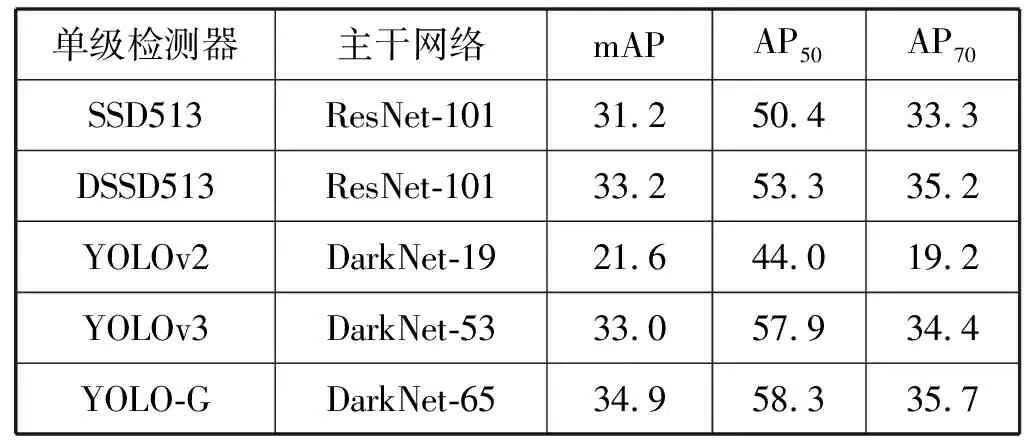
表4 单级检测器精度对比 %
3 结 语
本文提出一种应用于船舶目标识别的检测算法YOLO-G。该算法将深度卷积神经网络和多尺度特征图进行特征融合,提取目标的坐标信息及类别,并通过先验框机制和调制损失函数进一步提高模型的识别精度。将YOLO-G算法在BOAT数据集和MS-COCO数据集上与其他先进检测器进行性能对比测试,证明了该模型比其他检测器具有更高的识别精度和准确率,极大地提高了单级检测器的目标识别性能。但是通过实验数据可以看出,YOLO-G模型的识别精度仍具有一定的提升空间,接下来将通过扩充船舶数据集和“迁移学习”优化模型性能,提升YOLO-G的目标识别精度。
