云数据中心能量与热量感知的虚拟机合并与部署
2021-01-15张静
张 静
(常州信息职业技术学院 江苏 常州 213164)
0 引 言
云计算将传统的计算能力获取模式转变为当前的服务租用模式[1],基于资源的实际使用情况,按需以即付即用的弹性服务利用方式向用户提供资源。云数据中心是云服务的支撑基础设施。为了满足巨量规模云服务不断增长的计算需求,数据中心需要配置数以千计的服务器。然而,数据中心同时需要消耗巨大的能量提供云服务。根据美国能源部的报告[2],美国的数据中心消耗了其国家总能量的2%(约7×1010kWh)。数据中心不仅消耗能量,同时还会产生巨量的温室气体,导致很高的碳排放。具体地,每年有430亿吨CO2排放,每季度在以13%的速度增长[3-4]。因此,改进数据中心的能效对于云计算的可持续发展和营运代价将是至关重要的。
云数据中心的主要能耗来源于计算系统和冷却系统,基本上,冷却系统的能耗等于计算系统的能耗[5]。因此,数据中心资源管理系统需要同步考虑计算和冷却系统,从而实现全局整体能效的改进。
为了降低计算能耗,将负载合并至更少的主机上是一种有效方法,这样可以保持未使用的主机处于低功能状态[6-9]。然而,这种激进的合并可能导致局部热点的产生。热点主机的产生对于整个数据中心系统的可靠性具有很大的不利影响[10]。此外,若超过主机的温度阈值也会导致CPU硅组成的损坏,进而导致主机的失效。为了进一步解决散热问题,冷却系统会传输很多的冷空气进而增加冷却系统的代价。而通过最优的负载分布的热量管理方法可以有效避免热点出现,并同步降低数据中心的能耗。
数据中心的温度变化也与多个因素相关。首先,主机功耗所挥发的热量会分布至数据中心环境中[11],这种功耗与资源的利用率是成正比的。其次,机房空调系统CRAC所提供的冷空气本身也会携带一定温度,即所谓的供冷温度。最后,主机的入口温度具有时空现象[12]。从一台主机所挥发的热量会影响其他主机的温度。由于热空气热力学的特征,这种热量会在数据中心内循环存在。经过主机的空气并不会完全到达回流口,部分仍将留在主机所在空间。解决这种时空特征也可以优化能量使用。
此外,估算数据中心温度也有一定难度。目前主要有三种方法:(1) 计算流体动态模型进行精确预测[13],这种方法固有的复杂性使其应用在实时在线调度问题上计算代价太高;(2) 利用如机器学习的预测模型,这种方法极大地依赖于预测模型和数据的数量和质量;(3) 分析模型,主要根据热量的热力学特征和数据中心的物理属性进行预测。
动态虚拟机合并是数据中心节省能耗的有效手段,而这些合并算法对于实体布局和物理主机的位置并不可知。进一步,由于数据中心内部温度的分布,将负载合并至较少的主机上并不一定会节省能耗,这可能导致冷却系统的代价升高和创建一些热点主机,但部分合并的确能解决部分能耗问题。
相关研究中,文献[7]设计了一种功耗感知的PABFD算法。该算法是一种基于功耗感知的修改最佳适应算法,但仅仅考虑了合并过程中的CPU利用率,并没有考虑虚拟机合并和部署过程的主机热量问题。文献[14]在异构数据中心中提出一种功耗和温度感知的负载分配算法,但算法中没有对空调系统的制冷模型进行建模和考虑,导致最终的负载分配得到的能耗并不是全局最佳的。文献[15]提出基于DVFS的对偶时空感知的作业调度算法,但是这些方案均不能直接应用于虚拟云数据中心中。文献[16]提出一种GRANITE算法,该算法是一种以最小化数据中心能耗为目标的贪婪虚拟机调度算法,可以动态地进行虚拟机迁移,从而将负载均匀分配,使主机温度在确定的温度阈值以内。然而,贪婪算法的寻优解虽然可以控制主机温度不超过阈值,但实际温度距离阈值仍有距离,即主机利用率并未达到最优,总体能耗仍有下降的余地。文献[17]提出了一种TAS算法,该算法是一种温度感知调度算法,所选目标主机是温度最低的主机。文献[18]设计了一种二阶段启发式虚拟机部署算法,先降低主机利用数量,再进行虚拟机迁移。文献[19]提出一种能耗与性能协调的虚拟机重部署方法,同样使用了与上文类似的装箱思想对主机利用数量进行优化。以上两篇文献的问题在于仅仅以最小化主机使用量来降低总体能耗,没有考虑冷却系统带来的能耗问题,因此最终能耗并不一定是最优的。
本文使用温度状态的分析模型提出一种基于动态虚拟机合并的在线调度算法,同步考虑主机能量利用和冷却系统的能耗问题,利用贪婪随机自适应搜索机制求解能效更高的虚拟机合理部署方案,并通过在实际负载下的一系列仿真实验,验证算法在能效提高和性能提升上的优势。
1 系统模型
表1为本文涉及的主要符号和说明。
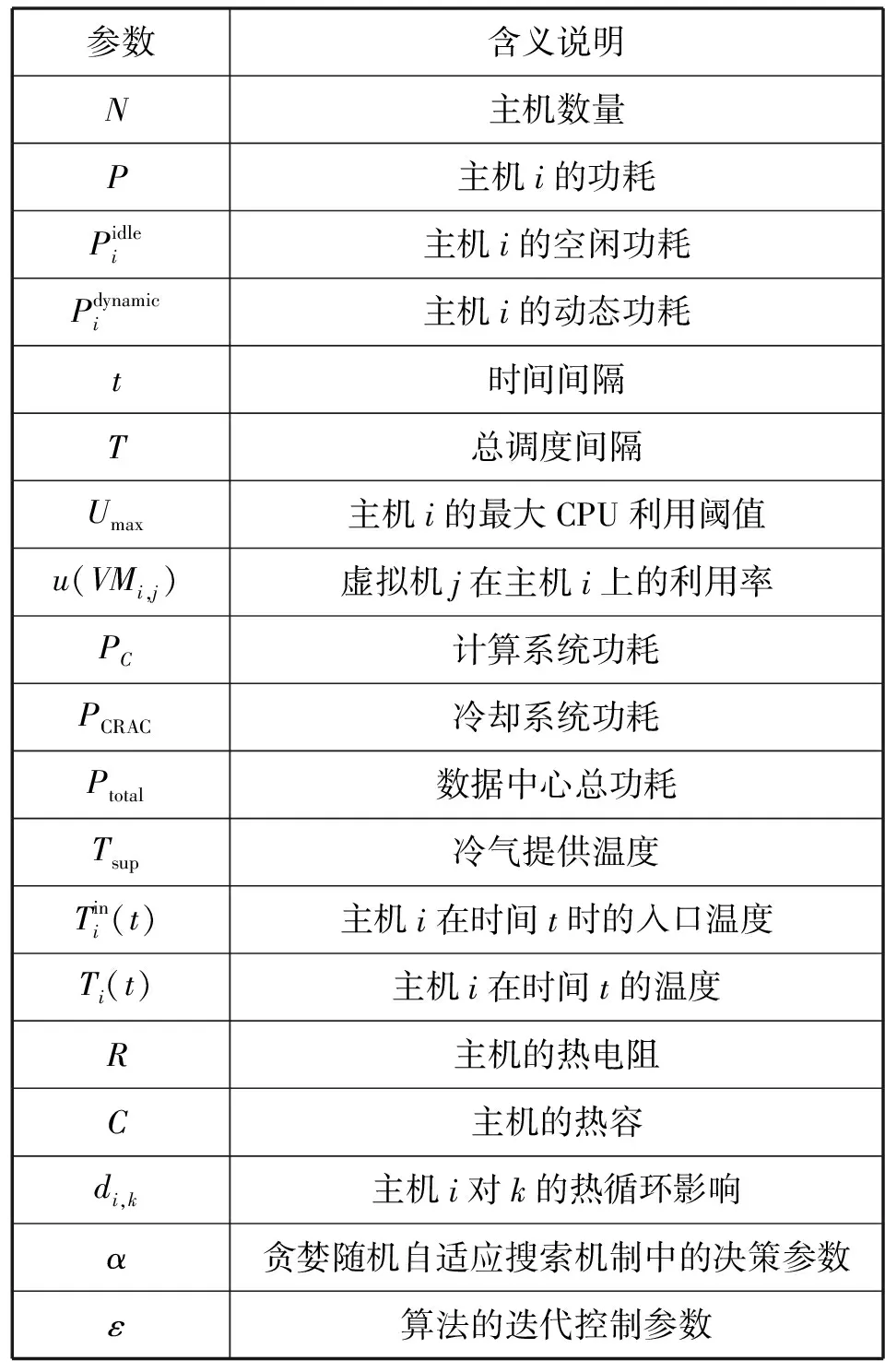
表1 参数说明
1.1 主机模型
数据中心由若干具有不同处理能力的异构主机组成,主机功耗主要由其资源利用等级决定,本文利用以下的线性功耗模型:
(1)
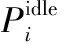
1.2 温度模型
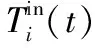
(2)
考虑到在数据中心内部以及主机的物理机架部署情况下热量再循环的存在,本文将这种热量再循环的影响量化为一种热量分布矩阵D,每个元素di,k表示主机i对主机k的进气温度的影响因子,这种影响因子为主机k的功耗Pk(t)的数量级。由式(2)可知,尽管机房空调系统CRAC能够传送类似的冷气温度至所有数据中心内的主机,但每个主机由于其物理位置不同和热量再循环的影响,其进气温度依然是变化的。
主机i的CPU温度由其CPU的散热决定,根据RC模型可定义时间t时的温度为:
(3)
式中:e为自然常数,Tinitial为CPU初始温度。根据式(3)可知,主机CPU温度不仅由功耗控制(主要因素,正比于CPU速率或负载级别),还由硬件特定量R和C以及进气温度决定,说明式(3)所使用的CPU温度分析模型可以捕捉主机温度的动态行为。
1.3 机房空调系统CRAC模型
数据中心的热量管理主要由机房空调系统CRAC进行。现代数据中心中,机架通常安排在通风口,冷空气从机架底部向上流通。假设数据中心由多个CRAC单元组成,表示为CRAC={CRAC1,CRAC2,…,CRACn}。考虑CRAC为数据中心内唯一可用的冷却来源。这种冷却系统的效率以性能度量系数CoP进行度量。CoP是冷气提供温度Tsup的函数,定义为计算系统的总体功耗与冷却系统的总功耗之比:
(4)
数据中心的CoP对于不同的数据中心环境配置也不相同,它取决于物理布局及数据中心热力学特征。本文使用HP Lab数据中心的性能度量模型:
(5)
式(5)表明,通过增加Tsup值,可以增加冷却系统的效率和降低冷却功耗。
1.4 负载模型
用户向云数据中心发送的请求可考虑为任务形式,假设n为任务总量,也可理解为任务执行请求n个虚拟机,将其表示为VM={VM1,VM2,…,VMn}。根据虚拟机建立负载模型,每个虚拟机可执行单个任务,每个任务拥有CPU请求Rcpu、内存请求Rmem、任务长度l。因此,每个任务可表达为三元组{Rcpu,Rmem,l}。为了解决动态虚拟机合并问题,实验中将一次性发送所有任务请求,在每个间隔中利用调度策略进行动态的虚拟机合并和部署,并分析算法性能。
2 能量和热量感知的虚拟机合并
2.1 问题描述
数据中心能耗主要产生于计算和冷却系统,计算系统由主机构成,其能耗可定义为:
(6)
根据式(6)计算系统能耗为所有主机能耗之和。变量xj表示:若主机j为活跃状态,则其值为1;否则为0。计算系统的能耗由所有活跃主机能耗组成,因此,在每个调度间隔中优化活跃主机的数量是至关重要的。
冷却系统CRAC能耗定义为热负荷与数据中心CoP之比。考虑到计算系统能耗基本随着热量消散至数据中心的周围环境,可将热负荷表示为PC。因此,冷却系统能耗可定义为:
(7)
式中:ThermalLoad表示热负荷。
根据式(7),冷却系统能耗可通过增加CRAC提供的冷气温度或降低热负荷的方式降低。因此,通过虚拟机合并,可以降低数据中心热负荷,并同步在给定冷气温度下主动地避免产生热点主机。数据中心总体能耗表示为:
(8)
虚拟机部署与合并算法需要同步感知计算系统和冷却系统能耗,由于过多虚拟机合并会导致热点主机,而负载过于分散又会导致过高的能耗。因此,本文的最优化问题可定义为:
目标函数:
(9)
约束条件:
u(hi)≤Umax
(10)
Ti(t)≤Tred
(11)
(12)
xj∈{0,1}
(13)
式(9)为最小化数据中心总体能耗;式(10)确保主机利用率需小于或等于占用阈值;式(11)确保主机温度需小于或等于最高温度阈值;式(12)确保主机必须具有满足需求的CPU和内存资源才可以进行虚拟机部署,即能力约束;xj为二进制变量,若虚拟机部署于主机i,则取值为1,否则为0。考虑到目标函数最优化求解在一定规模的数据中心内是一个NP问题,本文将设计一种基于贪婪随机自适应搜索机制GRASP的启发式算法进行虚拟机能效部署求解,并以合理的时间复杂度得到近似最优解。
2.2 算法设计
本节设计基于贪婪随机自适应搜索机制GRASP的虚拟机部署算法。GRASP是一种迭代式随机优化方法,其每次迭代由两个阶段组成:1) 贪婪构建阶段,即通过从解空间中随机取样的方式基于贪婪函数构建解列表;2) 局部搜索阶段,即从先前贪婪构建列表中通过邻居搜索方式寻找当前最优解。迭代过程到达确定的终止条件为止。GRASP的自适应特征可以动态地更新目标的贪婪值,而基于概率的取样特征则有机会完成近似最优解。同时,其解空间规模的灵活选择特征以及终止条件的设置也可以调整贪婪值和计算复杂性的程度。
动态虚拟机部署主要由三步构成:
1) 发现热点主机和低负载主机。
2) 从步骤1得到的主机中选择需要迁移的虚拟机。
3) 将所选虚拟机重新部署至新的目标主机上。
对于动态合并的前两个步骤,使用如下策略。为了发现超载主机,算法利用静态CPU利用率阈值Umax和CPU温度最高阈值Tred作为门限参数。若两个参数其一被超过,则视为超载主机。低载主机的发现思想是:对于所有未超载的活跃主机,如果这类主机上的所有虚拟机可迁移至其他主机上,则该主机视为低载主机。对于动态合并的第二个步骤,需要从超载主机选择虚拟机迁移至其他主机直到该主机不超载。算法主要思想是选择拥有最小迁移时间的虚拟机进行迁移,从而降低主机负载,由于这类虚拟机拥有更小的内存使用,在带宽有限的情况下,其迁移过程花费的时间更少。
假设在优化开始之前,数据中心已经到达稳定状态,即所有请求的虚拟机已经部署至主机上,且数据中心的温度状态已经达到稳定。算法1在每个调度间隔(5分钟)开始时执行,得到此时需要迁移的虚拟机以及目标主机。
算法1能量和热量感知的虚拟机合并算法
输入:VMList,hostList。
输出:energy,number of hotspot,SLA violation。
1. Initialize Tred,α,ε
2. for t=0 to T do
3. VMList←getVMsFromOverAndUnderUtilizedHosts()
4. for each vm in VMList do
5. allocatedHost=null
6. isSolutionNotDone←true
7. while isSolutionNotDone do
8. SolutionList←ConstructGreedySolution(VM,hostList)
9. newHost←LocalSearch(SolutionList)
10. δ=allocatedHost.τ-newHost.τ
11. if δ>ε then
12. allocatedHost←newHost
13. else
14. isSolutionNotDone←false
15. end if
16. end while
17. if allocatedHost==null then
18. allocatedHost=getNewHostFromInactiveHostList()
19. end if
20. end for
21. end for
算法1的第一步需要对红线温度Tred、GRASP中的约束候选解的规模α及解的改进质量控制参数ε进行初始化。在每个间隔中,步骤3对超载和低载主机上的所有虚拟机进行标识。对于来自于迁移列表中的每个虚拟机,步骤5将初始化待分配的主机为空,步骤7-步骤16则为贪婪随机自适应搜索机制中的贪婪策略。该阶段中,每次迭代有两个步骤:1) 在搜索空间中构建可行解列表,即一个容纳当前虚拟机的可能的主机列表;2) 执行局部搜索,寻找局部最优候选解,即子最优解。为了达到全局最优,在每次迭代中,所分配的主机需要根据步骤12中构建阶段的贪婪值τ进行更新。如果当前分配的主机和新分配的主机贪婪值τ之差大于预定义参数ε,则迭代过程继续;否则,终止迭代,将当前分配的主机返回为最终结果,即步骤11-步骤15。这里,ε是决定在先前解的基础上新解改进质量的参数。如果当前迭代中的新解比较先前迭代时的ε没有得到改进,则终止过程。若该过程无法找到容纳当前虚拟机的可用主机,则从空闲主机列表中启动新主机,即步骤17-步骤18。
算法2是贪婪构建解阶段。算法将虚拟机和主机列表作为输入,并输出可行部署解。过程第一步是构建RCL,它代表在有限解搜索空间中所构建的一个解列表。RCL的形成可以限制解空间中的搜索数量,降低算法时间复杂度。最后,需要排列不活跃主机,并从活跃主机中选择百分比为α的主机进入RCL,这可以确保搜索空间进一步降低。另外,通过随机取样方式选择活跃主机的百分比α进入RCL即为GRASP的概率机制。RCL中的每个主机的代价可表示为τ。
算法2贪婪构建可行部署解算法(Construct Greedy Solution)
输入:VM,hostList。
输出:SolutionList。
1. SolutionList←null
2. RCL←makeRCLFromActiveHostList
3. for each s in RCL do
4. if s is suitable for VM then
5. s.τ←(1+1/CoP(Tsup))Pi
6. end if
7. SolutionList←∪S
8. end for
9. return SolutionList
算法3显示了局部搜索机制,以寻找每次迭代中的局部最优解。基于所计算的贪婪值τ,最优局部候选解被返回为算法3的解。该算法不仅可以降低能耗,而且可以在满足资源能力在CPU、内存、带宽约束下避免温度高于阈值。算法2的步骤4即可满足式(9)的约束条件。并且,参数α和ε起到了调节参数作用,用于调整算法的贪婪程度和决策时间。若系统精确度要求较高,则可设置更大的参数值,但可能在搜索最优解时需要花费更长的时间。
算法3最优候选解局部搜索算法(Local Search)
输入:SolutionList。
输出:Host with local optima。
1. LocalOptimalHost←null
2. for each s in SolutionList do
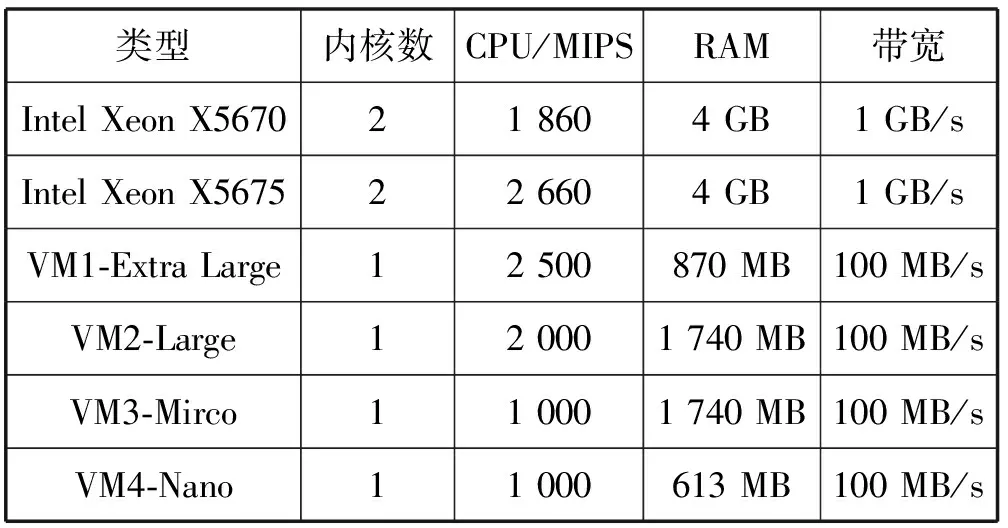
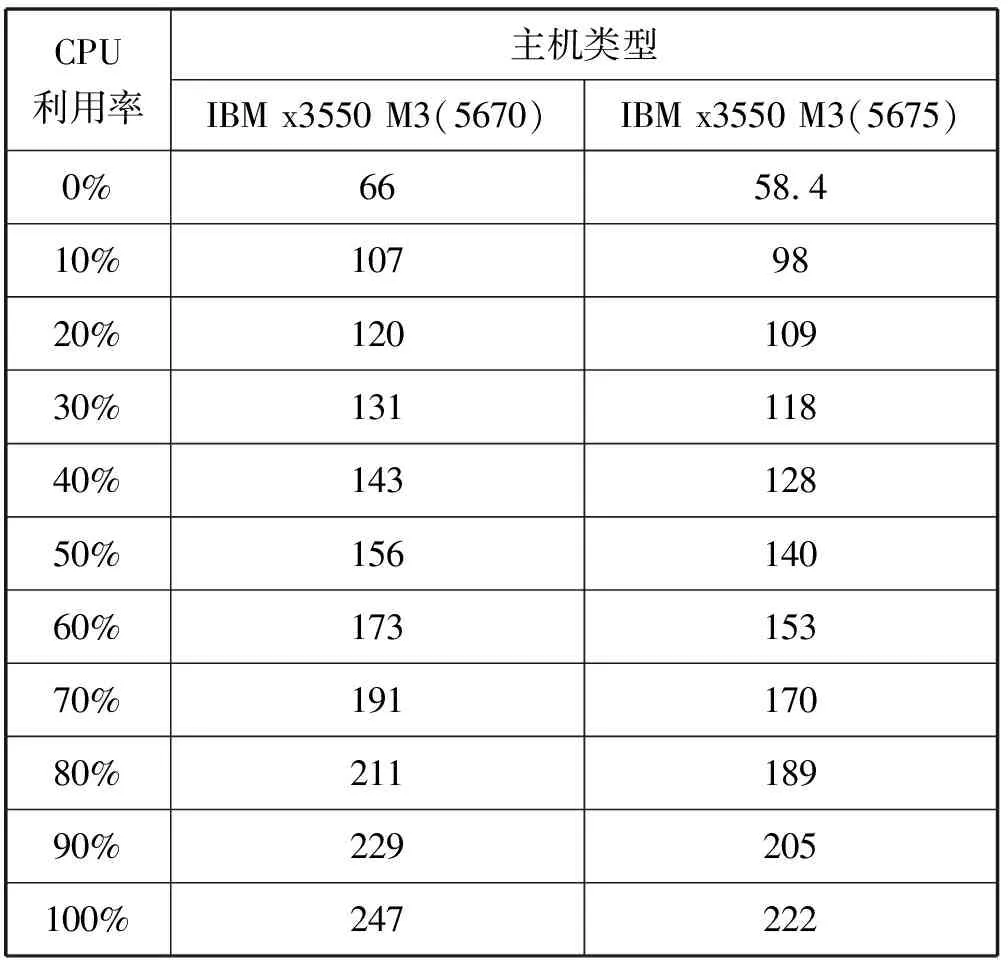
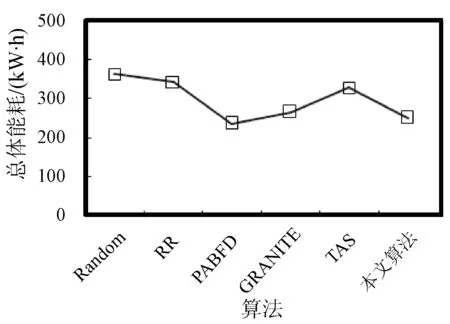
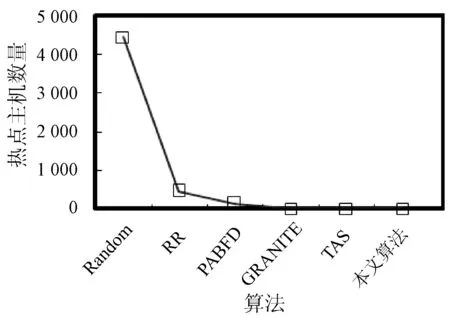
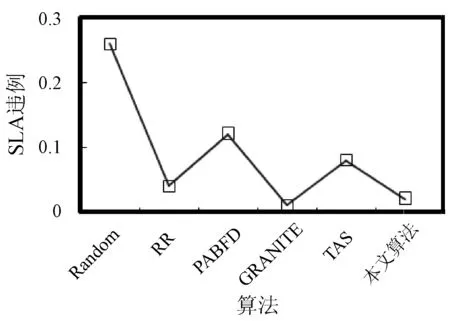
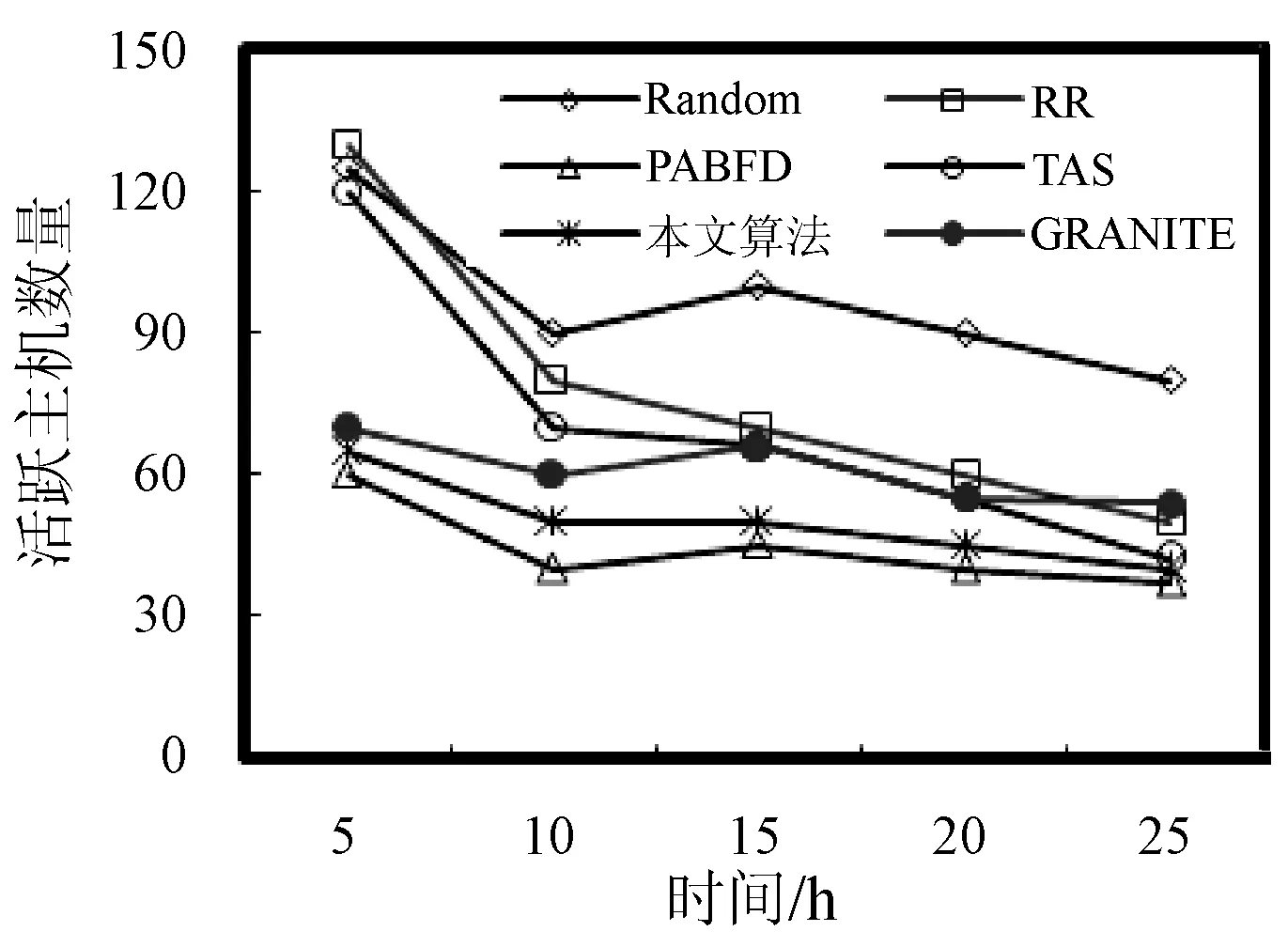
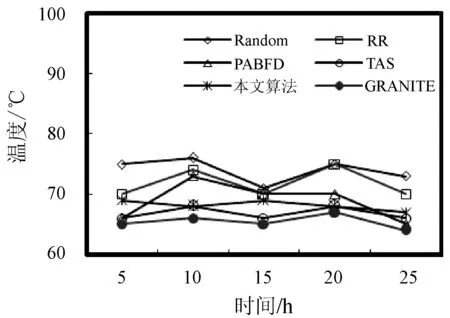
3. if s.τ 4. LocalOptimalHost=s 5. end if 6. end for 7. return LocalOptimalHost 本节评估算法可行性和性能,在cloudsim中构建仿真环境,模拟云计算系统。数据中心基础设施由1 000台异构主机组成,主机配置的处理能力参考IBM x3550 M3,处理器为Intel Xeon X5670和X5675,具体参数如表2所示。采用内核较少的CPU的原因在于可以展示在大量的虚拟机迁移下动态合并的效率。若内核较多,其容纳虚拟机数量也越多,则虚拟机迁移机会也会降低。系统功耗利用SPECpower实验床中的数据,它提供了在不同CPU利用率情况下对应主机的功耗情况,两种主机类型的功耗情况如表3所示。 表2 主机CPU和虚拟机类型和配置 表3 主机功耗情况 W 虚拟机参考AWS给出的配置,如表2所示。主机配置在机架结构上,机架安排在若干区域内,每个区域配置10个机架,总共10行,每行10台主机。假设在单个区域内存在热循环,但在不同区域间不存在。实验利用PlanetLab系统[20]生成仿真的负载流,该负载流统计了若干月份中数千台虚拟机的资源利用率状况,数据记录每5分钟进行一次,利用一天的数据流生成虚拟机的负载。 Random算法:将所有虚拟机随机部署在所选主机上,不考虑主机热量或功耗状态。 RR算法:轮转法,所有虚拟机以轮转方式部署至主机上,试图以均匀方式将负载分布至活跃主机上。 PABFD算法[7]:一种基于功耗感知的修改最佳适应算法,但仅仅考虑了合并过程中的CPU利用率,而没有考虑热量问题。 GRANITE算法[16]:一种以最小化数据中心能耗为目标的贪婪虚拟机调度算法,可以动态地进行虚拟机迁移,从而将负载均匀分配,使主机温度保持在确定的温度阈值以内。 TAS算法[17]:一种温度感知调度算法,所选目标主机是温度最低的主机。 式(3)中的热电阻和热容分别为0.34 K/W和340 J/K,初始的CPU温度设置为318 K,CRAC提供的冷气温度Tsup=25 ℃。主机最高温度阈值设置为95 ℃。需要注意的是,主机温度并不是CPU散热的唯一因素,还包括CRAC提供的冷气。将CPU的动态最大温度阈值设置为70 ℃。换言之,主机最大温度阈值为95 ℃,在排除静态部分Tsup之后,动态阈值温度为70 ℃。CPU静态利用阈值Umax设置为90%,参数α和ε设置为0.4和10-1。 能耗:主机执行负载带来的能耗,单位kW。 由于过量订购原因,主机可能达到满利用率等级100%,此时,这类主机上的虚拟机会表现较差性能,即出现单个活动主机的SLA违例SLATAH,定义为式(14)。进一步,由于虚拟机迁移所带来的虚拟机合并还会带到性能开销。这种虚拟机迁移所带来的性能下降PDM可定义为式(15)。SLA违例:该指标描述由于动态合并带来的性能开销,定义为式(16)。 (14) (15) SLAviolation=SLATAH×PDM (16) 式中:N为主机总量;Tmax为主机经历100%占用时间;Tactive为主机总活跃时间;M为虚拟机总量;pdmj为由于虚拟机j迁移带来的性能下降,实验设置为10%;Cdemandj为虚拟机j在周期内请求的CPU资源总量。总体SLA违例SLAviolation为两个指标的乘积。 热点主机:描述超过阈值温度的主机数量。 活动主机:描述整个实验过程中活跃主机的数量。 峰值温度:描述调度间隔中任意主机的最大温度。 图1是算法的能耗情况,随机算法最高能耗有363 kW·h,RR、PABFD、GRANITE和TAS算法分别达到342、235、265、327 kW·h,本文算法约为250 kW·h,同时还具有95%的置信区域CI,即(247,252)。换言之,本文算法比较随机算法、RR、GRANITE和TAS算法能耗分别降低了31%、27%、23%。比较PABFD,本文算法能耗略高6%,这是由于PABFD算法比较本文算法进行了更积极的虚拟机合并,所使用的主机数量更少。但这种极端合并忽略了潜在的热量约束,可能导致热点。 图1 能耗 图2是算法得到的热点主机情况,尽管PABFD比本文算法的能耗更少,但其创造了大量热点主机。随机算法的随机顺序对于能耗和热点的产生均有较大影响,热点最多。RR算法的均匀分布策略比较随机算法具有一定优势,热点降低至约416台,然而其能耗太高。PABFD约有123台热点主机,本文算法没有产生一台热点主机。本文算法虽然能耗略高于PABFD,但没有产生热点,其优势在于:1) 温度过高可能使服务器失效;2) 热点产生后,数据中心管理员需要进一步降低冷却温度,这会进一步增加冷却系统能耗。 图2 热点主机数量 图3是算法的SLA违例情况。算法的总体SLA违例需要计算出单个活动主机的SLA违例和所有的虚拟机迁移所带来的性能下降。由式(14)可知,实验中通过统计所有主机的总活跃时间和满负载时间两个参数值即可计算出单个活动主机的SLA违例。由式(15)可知,实验中仅仅需要记录虚拟机在周期内请求的CPU资源总量这一个可变参数即可计算出虚拟机迁移所带来的性能下降。结合这两个参数值,即可计算出算法在整个虚拟机部署周期内的SLA违例情况。随机算法、PABFD和TAS的SLA违例较多,其他三种算法较少。尽管RR算法在做出部署决策时没有考虑SLA需求,但其固有的负载均匀分布特征较随机算法、PABFD和TAS算法还是可以降低一定SLA违例的。本文算法在SLA违例上表现得足够优秀,同时还可以降低能耗和避免热点主机产生,综合性能最优。 图3 SLA违例 图4是算法活跃主机数量情况。标记时间是每隔一小时得到的均值结果。PABFD得到更少的活跃主机,而本文算法在PABFD的基础上仍有增加,GRANITE则又高于本文算法,这种结果也可从图1的能耗结果中推断出来。随机算法拥有最多活跃主机数量,TAS的增加幅度最小,并小于RR算法。同时,活跃主机数量、热点主机及能耗之间的关系也可被推断出来,拥有更少活跃主机的算法也倾向于会产生较多热点主机。随机算法显得比较异常,由于它是随机选择主机的。总体来看,活跃主机数量在所有算法间并未表现出很大不同,原因在于算法在超载主机和低载主机发现机制上采用了相同策略。本文算法虽然没有得到最少的活跃主机,但较PABFD能够避免负载过于集中,温度过高并避免热点主机产生。 图4 平均资源利用率 图5是算法主机的峰值温度情况。本文由于利用其热量感知的虚拟机部署机制从未超过红线温度,并接近于红线温度,这样极大提高了资源利用率,降低了冷却代价。TAS总是运行在一个更低的温度等级,而PABFD几乎均运行在红线温度周围,甚至超过红线温度70 ℃。GRANITE的主机峰值温度一直是最低的,由于该算法仅仅考虑了温度阈值,高温度主机上的虚拟机会被迁移出去,从而均衡负载。尽管RR是均匀分配负载,但由于主机性能的差异以及未进行热量感知,部分主机会超过红线温度。同时需要注意,图5中的温度结果并非所有主机的温度均值结果,而是所有主机中最高的温度。 图5 主机的峰值温度 本文提出一种同步优化计算系统和冷却系统能耗的虚拟机合并算法。算法利用贪婪随机自适应搜索机制,可以均衡虚拟机的合并积极度和虚拟机的稀疏分布,并有效避免产生热点主机,导致主机温度过高,使系统失效。大量仿真实验结果证明,本文算法不仅可以节省更多能源,避免热点主机生成,而且在性能保障方面(SLA违例)也表现出很好的性能。下一步的研究可考虑将机房空调系统CRAC的冷气输出温度根据数据中心的运行状况设置为变化的温度,并在此基础上设计虚拟机能效部署与合并算法,更好地节省能耗。3 仿真实验
3.1 实验配置
3.2 对比算法
3.3 参数选择
3.4 性能指标
3.5 结果分析
4 结 语
