过程挖掘算法研究综述
2021-01-13敬思远
敬思远
(1.乐山师范学院 人工智能学院,四川 乐山 614000;2.互联网自然语言智能处理四川省高校重点实验室(乐山师范学院),四川 乐山614000)
0 引言
过程挖掘(Process Mining),也称为工作流挖掘,是数据挖掘领域的一个重要分支。该研究的目的,是从信息系统的事件日志中发现业务流程的真实执行过程,并以可视化的方式提供给用户进行分析和决策[1]。当前,过程挖掘已经被广泛应用于智能制造、流程建模、内部安全检测与审计等诸多领域。举例来说,ASML公司采用过程挖掘技术对其光刻机制造芯片的各个环节进行分析,并提供优化决策[2];飞利浦公司针对其医疗设备,从全球范围采集所有设备的事件日志,并通过过程挖掘技术发现用户的使用习惯,从而优化其产品设计[3];SAP公司将过程挖掘集成到ERP系统中协助用户进行过程建模[4]。
过程挖掘的研究方向主要有三方面:过程发现,符合性检测和过程增强[1]。过程发现(Process discovery)的目的是“重现”业务流程的真实执行过程。该任务的输入是信息系统的历史记录(称为事件日志),输出为算法“观测到”的过程模型。根据不同的应用,该任务可以从控制流、资源分配、组织管理等不同的角度进行挖掘。符合性检测(Conformance checking)用于检测事件日志和过程模型是否一致,并对二者的符合性进行量化。符合性检测常用于评价过程发现算法的性能,以及用于安全审计、内部安全分析等任务。过程增强(Process Enhancement)是对已有的过程模型进行完善和增强,例如过程模型修复,为过程模型增加新的属性等等。本文集中讨论基于控制流的过程发现算法。
过程挖掘领域在近10年里发展迅速,期间涌现出很多高效的算法。遗憾的是,目前还没有研究对这些新算法进行梳理和比较。本文从过程挖掘的一些基本概念出发,对过程模型的表示,过程挖掘中的一些关键问题进行逐一回顾。最后,对当前主流的过程挖掘算法进行分类比较,总结了各自的优势和不足。
1 过程挖掘相关知识
1.1 事件日志
过程感知信息系统能够将业务流程中活动(以下统称为活动)的执行记录持久化到本地文件系统或数据库中,形成事件日志。图1中给出了一个事件日志片段。从图中可以看出,事件日志是一种基于XML的层次化结构。一个事件日志由若干trace(称为“轨迹”或“迹”)组成,而一个trace是由若干event(称为“事件”)组成。Event是活动发生的一个实际案例,其中包含了与活动相关的若干属性,例如事件名(concept:name)、生命周期(lifecycle:transition)、时间戳(time:timestamp),等等。图1中给出的trace是一个关于保险公司理赔流程的实际发生序列,受理→在线审查→票据审查→决策→理赔。IEEE Task Force on Process Mining于2016年正式发布了事件日志的国际标准,称为IEEE 1849-2016 XES Standard[5]。该标准对事件日志的内容和格式进行了规范统一。

图1 事件日志
下面给出事件日志的形式化定义。
定义 1. 设A是业务流程中活动的有限集合,则σ∈A*是活动的有限序列,L∈Β(A*)是事件日志。其中,A*表示集合A的Kleene 闭包。
例如,令A={A=“受理”, B=“在线审查”, C=“线下审查”, D=“票据审查”, E=“决策”, F=“重审”, G=“理赔”, H=“拒绝”},L={
1.2 过程模型表示
常用的过程模型表示方法主要有佩特里网(Petri net)、因果网(Causal net)、过程树(Process tree),等。这些过程模型的表示方法各有优劣。不同的过程挖掘算法采用的模型表示方法也不尽相同。采用不同方法表示的过程模型之间一般可以相互转化,比如可以将一个causal net转换成与其对应的petri net。此外,还有一些语义表示能力更强的过程建模语言,如BPMN、YAWL等。这些语言常作为建模工具提供给用户使用,但是在过程挖掘研究中使用较少,本文不做介绍。接下来,本节对以上三种表示方法进行重点介绍。
首先介绍petri net(也称为Place/Transition Net,简称P/T net)。P/T net是一种数学表示能力非常强的建模语言。通常,P/T net由库所(Place)和变迁(Transition)组成,Place和Transition之间采用有向弧连接。它的形式化定义如下所示。
定义 2[6].P/T net是一个三元组(P,T,F),其中:a)P表示Place的有限集合;b)T表示Transition的有限集合;c)F=(P×T)γ(T×P)表示有向弧的集合。
在P/T net基础上加上一个起始Place和一个终止Place,即得到表示过程模型的工作流网(Workflow Net,简称Wf-net)。图2中是一个与上节给出实例对应的Wf-net,图中圆圈表示Place,方框表示Transition。可以看到,每个Transition上都有一个活动名称,说明Transition和活动是一一对应的。当某个Transition的所有前驱结点(即Place)均处于就绪状态时,该Transition即可触发,并产生一个Event。在P/T net中,一个Place处于就绪状态指的是位于该结点的Token数大于0(即图2中的小黑点)。举例来说,图2中的“开始”结点目前已处于就绪状态,因此它的下一个Transition(受理)可以触发。需要说明的是,图中B和C之间,G和H之间是选择关系(即每次只有一个Transition可以触发),而{B,C}和D之间是并行关系。因此,该过程模型可能产生的trace包括

图 2Wf-netFig 2 Wf-net
定义 3[7].C-net表示为一个四元组CM=(T,C,I,O),其中:a) T表示所有活动的有穷集合;b) C∈T×T是因果关系的有限集;c) I:T→I(T)为输入映射函数,∀t∈T,I(t)={t'|(t',t)∈C};d) O:T→O(T)为输出映射函数,∀t∈T,O(t)={t'|(t,t')∈C}。
表1中给出了由上述Wf-net转化的C-net。其中,T={A,B,C,D,E,F,G,H}。I(A)=表示活动A的输入为空集;O(A)={{B,C},{D}}表示活动A的输出为{B,C}和{D},其中活动B和活动C之间是选择关系,而{B,C}和{D}之间是并列关系。因此,A之后的活动发生序列可能是BD,CD,DB,DC。

表1 C-netTable 1 C-net


图3 P-treeFig 3 P-tree
2 过程挖掘中的关键问题
2.1 一些特殊挖掘任务
在过程挖掘算法中,除了需要发现一些基本的流程结构外(如顺序结构、选择结构、并行结构、循环结构,等等),还需要处理一些特殊问题,例如重名活动、不可见活动、非自由选择结构等等。
重名活动指的是有两个或两个以上的活动具有相同的名字。引起该问题的原因有几方面。一是由事件日志中的Event属性不完备所导致。例如在医院的住院信息管理系统中,护士需要对病人进行术前化验检查和术后化验检查,但由于系统中只有“化验”这一项活动,并没有事件属性对“术前”还是“术后”进行标注,因此事件日志中也不会对其进行区分。二是由活动“粒度”不同引起的重名活动。例如,病人在医院进行化验,可以细分为血常规检查、肝功检查、胃镜检查等不同项目,但是在日志中它们均统称为“化验”,因此算法很难将其进行区分。
不可见活动在流程设计中又称为“skip”模式。该活动并没有实际的意义,仅起到路由的作用。图4中给出了一个不可见活动的例子,其中黑色的方框即表示一个不可见活动。从图中可以看出,当P1处于就绪状态时,既可以触发活动A执行,也可以从不可见活动通过,从而跳过活动A的执行。由于不可见任务并不会出现在事件日志中,因此很难被算法发现。

图4 不可见活动
非自由选择结构是一种同步和选择同时出现的复杂结构。在该结构中,后面的Transition的触发依赖于前面的Transition的选择。图5中给出了一个非选择结构的例子。其中P1是一个选择结构,要么A被触发,要么B被触发。假设触发的是Transition A,接下来出现一个并行结构P2和P3,然后Transition C被触发。注意到,Transition C被触发后又是一个选择结构,若不考虑其他因素,则Transition D和Transition E都可能被触发。但由于Transition D依赖于P3和P5,Transition E依赖于P5和P4,因此最终只能触发Transition D。这种远程的依赖关系在过程挖掘中很难被发现。
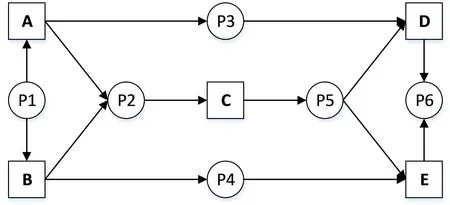
图5 非自由选择结构
2.2 事件日志的噪声和不完备性
所有过程挖掘算法的起点都是事件日志。因此,事件日志的质量会直接影响最后的挖掘结果。事件日志处理中经常会遇到以下两方面的问题。
首先是噪声数据。真实环境下,事件日志中出现噪声是非常常见的。引起噪声的情况非常多,例如事件日志服务器工作异常(断电、宕机、网络拥塞等),分布式环境下某个生产服务器工作异常,等等。噪声数据的特点是出现频率低,因此一般采用数据清洗技术对噪声进行过滤,或者对挖掘得到的过程模型进行剪枝。但是,如何有效区分噪声和低频Trace是一个难点。
其次是日志的完备性。大部分算法在设计时都会假设日志是完备的,即所有可能出现的活动轨迹在事件日志中均是包含的。但是这个假设难以保证一定成立。举例来说,假设一个过程中包含有10个并行的活动,那么这些活动出现在事件日志中有10!种不同的组合,如果只记录1000条Trace,很明显不可能覆盖所有可能出现的情况。此外,在真实环境下,有些Trace可能很长时间都不会出现,但是这些Trace对应的业务过程在信息系统中却是真实存在的。
2.3 如何平衡性能指标
目前常常从四个方面来评价过程挖掘算法的输出结果[9],分别是Fitness、Precision、Generalization以及Simplicity。
Fitness指标用于评价挖掘得到的过程模型能够重现事件日志的能力。过程模型的Fitness值等于1当且仅当事件日志中所有的Trace都能被该模型重现。换句话说,能被模型重现的Trace越多,该模型的Fitness值就越高。Fitness目前是评价过程模型质量最重要的指标。
Precision指标用于评价过程模型的精度。如果一个过程模型能够产生出很多事件日志中不存在的Trace,即可认为该模型的精度较低。在机器学习中该现象也称为“欠拟合”。举例来说,“花”模型能够产生出任意的Trace,但是它的Precision值非常低,对实际应用也毫无价值,这是过程挖掘算法不希望得到的。
Generalization指标用于评价过程模型的泛化度。Generalization与Precision刚好相反,它希望过程模型不仅能反应出事件日志中“观测到的行为”,还希望该模型能够反应出一些在事件日志中观测不到但又是正确的行为。鉴于事件日志的不完备性,因此好的过程模型应该具有一定的“预见性”,这样才能更好地适应真实应用环境。
Simplicity指标用于评价过程模型的结构复杂度。在保证Fitness、Precision和Generalization三个指标的前提下,过程模型的结构复杂度越低越好。一个过程模型结构越简单,越容易被用户理解。
除此之外,还有一个常常被忽略的重要指标Soundness,用于评价一个过程模型是否合理。根据文献[6]中给出的定义,一个合理的过程模型应该满足以下几点:(a) 模型有且仅有一个起始结点和终止结点;(b) 模型中的每一个结点都在从起始结点到终止结点的某条路径上(即每个活动都有可能被触发);(c) 模型中不存在死锁、活锁等不合理结构。
3 过程挖掘算法研究现状

3.1 ɑ系列过程挖掘算法
van der Aalst[6]等于2004年提出的ɑ算法被公认为是过程挖掘领域的一项里程碑式的成果。ɑ算法能够基于事件日志中Event的出现顺序,对Event之间的依赖关系进行推理,从而发现其中顺序、因果、选择、并行四种结构,得到一个合理的Wf-net。但是ɑ算法有很多关键问题没解决,例如不能处理重名活动,不能发现不可见活动,不能挖掘出循环结构和非自由选择结构等等。因此后来涌现出许多以ɑ算法为基础进行的研究。de Medeiros等[10]提出了能进一步发现短循环(长度为1和2的循环)的ɑ+算法;林雷蕾等[11]提出了ɑL+算法,能够从从没有“aba”模式的事件日志中挖掘出长度为2的循环结构;闻立杰等[12]先后提出了能够发现不可见活动的ɑ#算法,以及能进一步发现非自由选择结构的ɑ++算法[13];李嘉菲等先后提出了能解决重名活动的ɑ※算法[14]和ɑ※※算法[15]。更进一步,为了增强算法的推理能力,杜玉越等[16]则提出了基于逻辑petri net的过程挖掘算法;余建波[17]则提出了一种基于统计的ɑ算法,同时解决了重名活动的识别,事件日志中噪声的处理和非自由选择结构识别三个问题,提高了算法的鲁棒性和准确率。
以上所有算法均可归结为ɑ系列过程挖掘算法(因为它们都是从ɑ算法扩展得到的)。ɑ系列算法的特点是它们都是通过扫描事件日志中的Trace,抽象出活动之间的基本关系,进而构造出过程模型。这类算法的优点是时间复杂度低,执行时间短,并且得到的过程模型结构复杂度较低,容易理解。但是ɑ系列算法均没有考虑fitness、precision和generalization三个指标,因此所得模型的综合质量都不高,在实际应用中较少采用。
3.2 启发式过程挖掘算法
Weijters等[18]首次提出了过程挖掘的启发式算法,称为Heuristic Miner(简称HM)。HM算法的原理是通过统计事件日志中一些基本模式的出现频率来计算活动之间的依赖度,以此发现过程模型中的主要行为。由于HM只关注主要行为,对一些异常信息(如噪声)能自动过滤,因此算法具有较强的鲁棒性。HM算法能够发现过程模型中的一些常见结构,如顺序、选择、并行、循环、和非自由选择结构,输出模型为C-net。HM算法包含三个主要步骤。首先,通过公式(1)计算活动之间的依赖度。

(1)
其中,A≻LB表示在Trace中活动A和B相邻出现(即
HM具有较强的抗噪能力和鲁棒性,但是初始版本有很多不足。Weijters等[19]于2012年又进一步提出了Flexible Heuristics Miner(FHM),大幅提升了算法性能。此外,Greco等人基于C-net,在传统方法基础上融入了优先约束,提出了CNMiner算法。鲁法明等[20]则提出了一种并行化的启发式流程挖掘算法,不仅提升了算法的计算性能,还对HM算法中的长距离依赖关系以及2度循环结构的计算进行了优化。
3.3 基于计算智能的过程挖掘算法
计算智能已成为解决数据挖掘、非线性优化等领域问题的一种主流方法。这类方法模拟了生物演化过程,具有非常强的搜索能力和鲁棒性。Alves de Medeiros等[7]首次提出了基于遗传算法的过程挖掘方法,称为Genetic Miner。通过定义良好的适应度函数,以及交叉、变异等过程遗传操作算子,Genetic Miner能够得到与事件日志非常一致的C-net模型。而且,该算法采用一种统一方式解决非自由选择结构、不可见活动、以及重名活动的挖掘。欧阳等[21]发现Genetic Miner不能很好地处理过程模型中的循环结构,提出了一种集成的方法,在遗传算法基础上融合了粒子群算法和差分进化算法,进一步改进了Genetic Miner算法的搜索能力。Vázquez-Barreiros等[22]则对Genetic Miner中的目标函数、初始化方法等进行了改进,提出一种新的遗传算法ProDiGen,从Fitness、Precision和Simplicity三个指标上提升了所得过程模型的质量。此外,李莉等[23]提出了一种基于变异粒子群优化的过程挖掘算法,宋炜等[24]提出了一种基于模拟退火的智能算法,输出模型均为C-net。遗憾的是,以上算法均不能保证过程模型的合理性。

基于计算智能的算法能够采用统一的方式解决多种复杂问题,并且算法的鲁棒性强,挖掘得到的模型质量较高。但是这类方法的计算时间开销较大 ,在应用时需要考虑该问题。
3.4 基于Region的过程挖掘算法
基于Region的过程挖掘算法包括两类:一类是基于状态的Region方法(State-based region),一类是基于语言的Region方法(Language-based region)。它们的区别在于,前者的输入是一个变迁网络(Transition System),而后者的输入是事件日志。基于State-based region的方法对参数的依赖非常大,不同的参数设置可能得到差异非常大的过程模型,在此不再详细介绍。
Bergenthum等人首次提出了基于Language-based region的过程挖掘方法[27]。该方法通过事件日志计算整数点的最小线性基,从而构造过程模型。该方法保证了最优的Fitness值,但是却没有考虑模型的Precision值,并且所提算法的时间复杂度随日志规模呈指数级增长。
在所有基于Language-based region的方法中,目前最有效的是基于整数线性规划的过程挖掘算法(称为ILP Miner)。首次提出过程挖掘的ILP算法的是Werf等人[28]。该方法中提出了整数线性规划的目标函数,并构建了约束条件。该优化模型不仅能够表达对Petri net中特定库所的偏好,而且支持一些高级petri net的发现(例如含有重置弧和约束弧的petri net)。van Zelst等[29]对ILP方法进行了进一步完善,提出了Hybrid ILPMiner。该方法不仅改进了目标函数,而且提出了如何处理低频行为,从而提高了所得模型的Precision指标。由于篇幅问题,在此不再对该方法进行详细介绍。
3.5 基于大数据的过程挖掘算法
目前过程挖掘领域面临的主要问题之一是对过程大数据的挖掘。举例来说,目前的医院管理信息系统中包含了门诊信息管理系统、药品信息管理系统、住院信息管理系统等数十个系统,其中可能涉及上千个活动,每天产生数百兆的事件日志。Philips公司的医疗设备采集分布在全世界各地的设备节点的事件日志进行分析,每天能产生GB级的过程数据。如何在合理的时间内从这类“大数据”中挖掘得到高质量的过程模型是本领域的一个新挑战。
目前基于大数据的过程挖掘方法主要有两大类,一类是基于分治法的算法,另一类是基于新计算范式的方法。首先,基于分治法的算法中最有效的是Leemans等[30-31]提出的Inductive Miner(简称IM)。IM算法采用了一种分治和递归的策略,从单个结点出发,通过不断地递归将相邻的结构化的局部模型组合成更大的“局部”模型,最终得到完整的过程模型。由于在整个计算过程中,IM算法保证每一步得到的局部模型均是结构化的,因此其最终得到的过程模型也是结构化的。IM算法是目前过程挖掘领域最有效的算法之一,其优点是能够挖掘得到质量很高的过程模型,并且计算时间复杂度较低,能在短时间内分析GB级的事件日志。但是它不能发现一些非本地的结构,例如长距离的循环结构、非自由选择结构等等。
Verbeek等[32]则提出了一种普适的分治法框架,称为Divide & Conquer。该方法首先通过聚类算法将活动集合划分成若干子集;基于得到的活动子集,对事件日志进行划分,得到每个活动子集对应的“局部日志”;基于活动子集和局部日志,采用现有算法(如ILP算法、IM算法等)得到局部的过程模型;最后,将得到的局部模型进行融合,得到最终的过程模型。仍然基于3.2节中给出的事件日志L进行解释。假设通过计算得到两个活动子集{A,B,C,D,E,F}和{G,H},则L将被划分为两个局部日志L1={
第二类方法则是采用新的计算范式。例如,Reguieg等[33]提出了一种基于MapReduce的事件相关性计算方法,扩展了现有的过程挖掘算法。Ferreira等[34]则提出了一种基于GPU和CPU协同的事件统计算法,实现了对过程挖掘算法的加速。李龚亮等[35]则提出基于GPU的并行遗传过程挖掘算法,表现出较好的执行时间加速比。在此不再一一介绍。
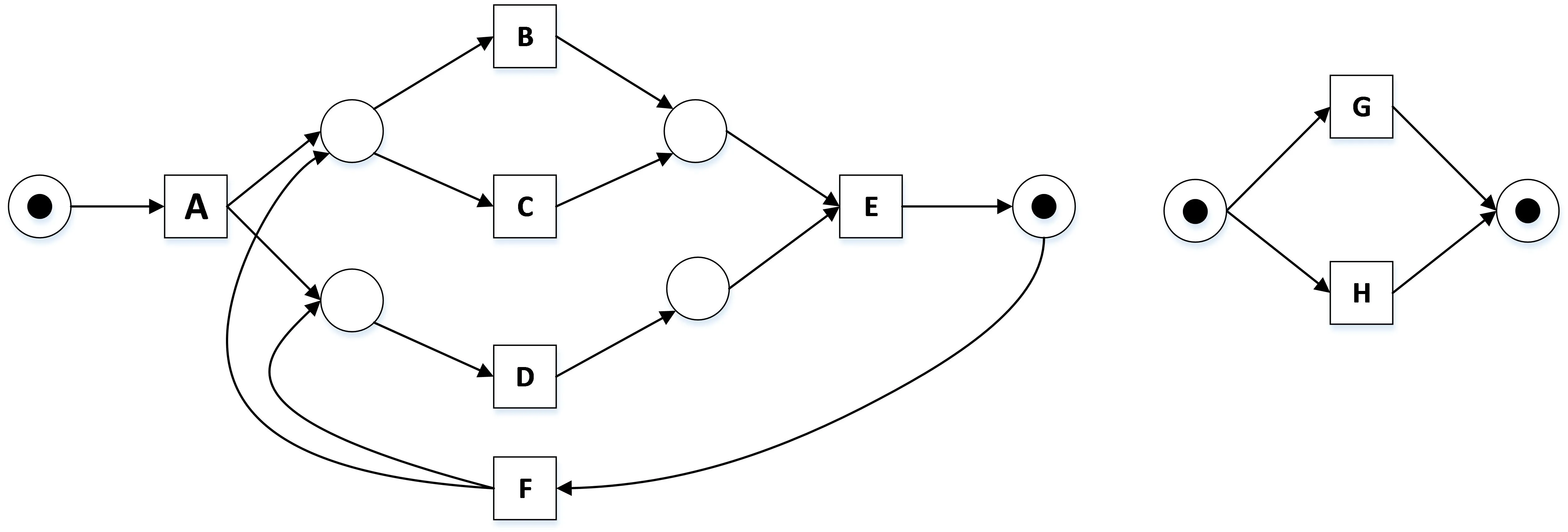
图6 由分治法得到的局部模型
4 算法比较

表2从模型质量和模型结构两个大的方面对三种算法进行了比较。模型质量指的是该算法挖掘得到的过程模型在不同评价指标上的表现;模型结构指的是该算法能够发现的流程结构。首先从模型质量上看,ETM算法的优点是考虑了所有的性能指标,所得到的过程模型质量较高,有较好的抗噪性。但是ETM算法执行时间较慢,这也是所有基于计算智能算法的共同缺点。Hybrid ILP Miner算法在Fitness、Precision和Simplicity三大指标上表现较好,且具有较好的抗噪性,执行之间也很短。但是该算法没有考虑算法的Generalization,换句话说,在一些真实场景下该算法可能表现不佳。此外,Hybrid ILP Miner挖掘得到的过程模型是弱合理的,而不能保证模型的强合理性。IM算法挖掘得到的过程模型则在所有性能指标上均能达到令人满意的效果,而且具有较好的抗噪性,执行时间也非常短。
接下来从模型结构上对三种算法进行分析。ETM算法因为采用的是随机搜索,因此理论上能发现所有的流程结构。Hybrid ILP Miner算法尽管能发现表2中列出的所有流程结构,但是对一些异常复杂的结构,仍然难以发现。IM算法是一种基于分治法的算法,它从单个结点进行递归,通过与相邻结点组合来发现局部的流程结构,因此难以发现一些长距离的依赖关系。最后,表2中还讨论了所得模型的可重现性。ETM由于是随机搜索算法,因此它的挖掘结果难以重现,而IM和Hybrid ILP Miner两种算法的挖掘结果均是可重现的。
综上可以发现,ETM算法能够得到高质量的、强合理的过程模型,理论上能够发现所有可能的模型结构,但是它的执行时间长,且挖掘结果很难重现;IM算法同样可以得到高质量的、强合理的过程模型,并且它的执行时间短,挖掘结果也能重现,但是它只能发现局部模型结构,难以发现一些远距离的依赖关系;Hybrid ILP Miner算法能够发现大部分的模型结构,并且它的执行时间短,挖掘结果能够重现,但是它挖掘到的过程模型泛化性较低,并且是弱合理的。

表2 三种算法的比较
5 总结和展望
本文对当前过程挖掘领域以Petri net、C-net和P-tree为输出的主流算法进行了分类总结。首先,按照过程挖掘算法的基本原理,将其划分为五大类,分别是ɑ系列算法、启发式算法、基于计算智能的算法、基于Region理论的算法,以及基于分治法的算法。其次,对目前最有效的三个算法ETM、IM以及Hybrid ILP Miner,进行了进一步的分析和比较,并给出了相关结论。但需要强调的是,目前该领域的研究还远没有走到终点。首先,当前的算法仍然存在诸多不足,例如ETM算法计算效率较低,且它只是理论上能发现所有的模型结构,而实际应用中仍然不能完全令人满意;IM算法只能发现局部的模型结构,难以发现远距离的依赖关系;Hybrid ILP Miner算法挖掘得到的过程模型泛化性较低,等等。
此外,随着过程挖掘领域的不断研究和发展,目前又涌现出很多新的问题。
a)异源日志的融合问题,即事件日志是来自不同的信息系统。这些信息系统可能是不同时期的,或者是不同企业开发的,它们在活动命名、业务过程设计上均不同。因此,如何将事件日志进行融合是一个关键问题。
b)概念漂移问题,即过程模型中的概念随着时间的迁移发生了变化。举例来说,一些旧的业务过程可能会被简化(也可能变得复杂),一些简单的业务过程可能会被合并,业务过程中的一些活动可能会被删除或修改,等等。
c)大数据处理问题。尽管目前已有一些关于过程大数据处理的研究,例如分治法,或者基于MapReduce,GPU的算法,但是总体来说,该领域还处于起步阶段,仍然有诸多问题臻待解决。
